導入
現代のエージェントが成功するか失敗するかは、ますます周囲のハーネス に依存するようになっています。これは、多段階の推論、ツールの使用、記憶、委任、そして単一のモデル呼び出しを超えた停止機能を構造化する制御スタックを指します。研究によると、外部化された制御パターンは決定的なものとなり得ます。具体的には、推論-行動ループ (ReAct)、検索拡張生成 (RAG)、および明示的な自己フィードバック (Reflexion) などが挙げられます。最近の研究では、明示的な記憶と自己進化、ワークフロー生成、マルチエージェントオーケストレーション、およびネイティブなツール実行などが検討されています。
しかし、このような重要性が高まっているにもかかわらず、ハーネスのロジックは、ほとんどの場合、一貫性があり、移植可能な形で公開されていません。ほとんどのエージェントシステムにおいて、効果的なハーネスは、コントローラーコード、隠されたフレームワークのデフォルト設定、ツールアダプター、および実行時特有の前提など、さまざまな場所に散在しています 。その結果、ハーネスは異なる実行環境間で転送することが難しく、公平な比較が困難であり、また、完全に分離することが難しいという問題があります。この変化は、「プロンプトエンジニアリング」を、より広範なコンテキストエンジニアリング の実践へと転換させます。具体的には、長時間の実行において、どの指示、証拠、中間的な成果物、および状態が各ステップで利用可能であるかを決定することです。
「ハーネスエンジニアリング」とは?
AIエージェントを熟練した作業員と考えると、「ハーネス 」は、その作業員の周囲にある管理システムです。ハーネスは、どのようなタスクを割り当てるか、どのような順序で実行するか、利用可能なツールは何か、結果をいつ確認するか、そしていつ停止するかなどを決定します。例えば、AIコーディングアシスタントを構築する場合、ハーネスは次のように指示するかもしれません。「まずアプローチを計画し、次にコードを書き、次にテストを実行し、テストが失敗した場合は、デバッグして再試行する。」しかし、今日のところ、このロジックは通常、コードフレームワークの奥深くに埋め込まれており、AIモデル自体とは独立して共有、比較、または改善することが非常に困難です。
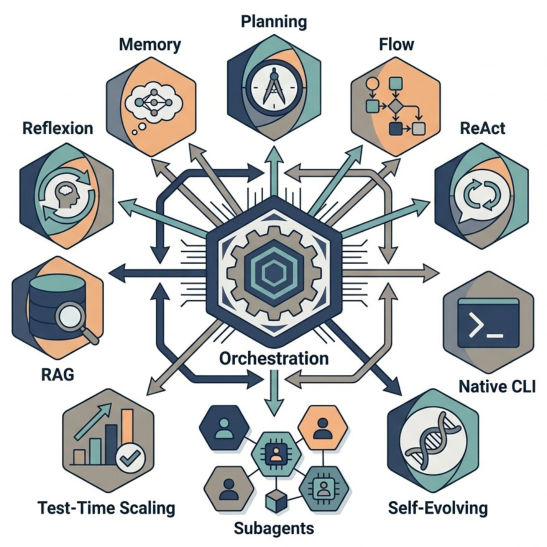
図1: 最新のエージェントで使用されるハーネス設計パターンの一例:プランニング、メモリ、フロー、リフレクション、RAG、ReAct、オーケストレーション、ネイティブCLI、テスト時のスケーリング、自己進化、およびサブエージェント。
自然言語によるドキュメントである AGENTS.md やスキルバンドルは、実用的なシステムが、リポジトリ内の規約や再利用可能な手順を、移植可能なテキスト形式でパッケージ化できることを示しています。しかし、これらのドキュメントは、通常、ローカルな指示や再利用可能なルーチンを記述していますが、システム全体としての契約、役割の境界、状態のセマンティクス、および実行時に使用されるアダプターなどを、最初から第一級の要素として扱い、それらを連携させて実行することを考慮していません。
論文の概要: 本研究では、エージェント制御システム内の設計パターン層を、共有される実行時環境の前提のもとで、実行可能な自然言語オブジェクトとして明示化できるかどうかを検討します。我々は、自然言語エージェント制御システム (NLAH) —構造化された自然言語による制御表現であり、明示的な契約と成果物キャリアに紐づけられている—と、NLAHを直接解釈するインテリジェント制御実行環境 (IHR) を提案します。
方法論
ハーネスとパターンレイヤー
ハーネス とは、タスクファミリーにおける複数のモデルまたはエージェントの呼び出しを統制するオーケストレーション層を指します。ハーネスとランタイムの境界は分析的なものであり、汎用的なサービス(ツールアダプタ、サンドボックス、子プロセスのライフサイクル)はランタイムに存在し、タスクファミリーのポリシー(ステージ、アーティファクト契約、検証器)はハーネスに存在します。この境界は研究のために明確に定義されています。
01
制御
仕事が、複数のステップ、ツール、および担当者間でどのように分解され、スケジュールされるか。
02
契約
どのような成果物が必要で、どのような条件を満たす必要があり、いつ実行を停止すべきか。
03
状態
エージェントの実行中、どの情報がステップ、ブランチ、および委任されたワーカー間で維持されなければならないか。
Harness vs. Context Engineering: コンテキストエンジニアリングとは、単一のAI呼び出しに対して適切なプロンプトを作成することです。一方、Harnessはさらに一歩進んでおり、プロジェクトマネージャーがチームを数日間の作業で調整するように、複数のステップを含むワークフロー全体を管理します。単に1通のメールを書くだけではありません。
インテリジェント・ハーネス・ランタイム (Intelligent Harness Runtime: IHR)
IHRは、NLAHを直接解釈する共有実行環境です。これは、実行環境の役割 (汎用サービス:ツールアダプター、サンドボックス、子プロセスのライフサイクル管理)と、制御ロジック (タスクファミリーポリシー:ステージ、成果物の契約、検証器)を明確に分離しています。計算の約90%は、委譲された子エージェントで行われ、実行環境の親プロセスは、総リソースの10%未満を消費します。
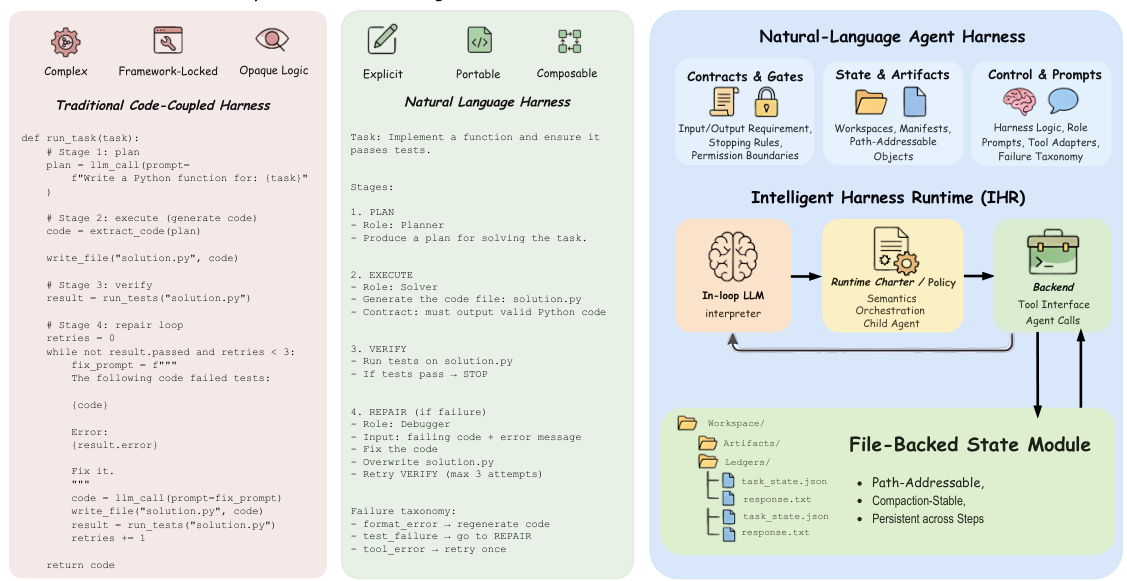
図2: ハーネス設計の比較。 左: Pythonにロジックが埋め込まれた、従来のコード結合型ハーネス。 中央: 明示的な契約、ゲート、ステージを編集可能なテキストで記述した、自然言語ハーネス。 右: 複数のアドレスを持ち、セッションを越えて共有でき、人間が編集可能で、バージョン管理可能な状態を提供する、ファイルバックアップ付きステートモジュール。
IHRの実際の動作
IHRを、AIエージェントのための普遍的なオペレーティングシステム だと考えてください。WindowsやmacOSがどんなアプリケーションでも実行できるのと同じように、IHRは自然言語で記述されたどんな"ハーネス"でも実行できます。重要な点は、分離構造にあります。"ランタイム・チャーター"は基本的なサービスを提供します (OSがファイルシステムやネットワークを提供するように)。一方、"ハーネス・スキル"は、特定のワークフローを定義します (アプリケーションが独自のロジックを定義するように)。つまり、ランタイムを変更せずに、ハーネスの戦略を切り替えることができます。これは、OSを再インストールせずに新しいアプリケーションをインストールするのと似ています。
自然言語エージェント・ハーネス (Natural-Language Agent Harnesses, NLAHs)
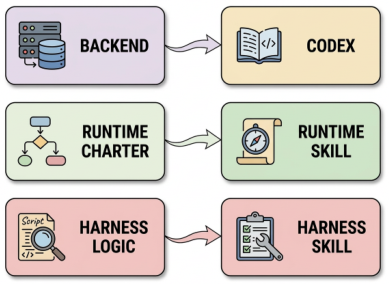
NLAHsは、編集可能な自然言語でハーネスの動作を表現します。この表現には、以下の要素が必須です:契約 (入力/出力要件、停止ルール、アクセス権の範囲)、役割 (プランナー、実行者、検証者)、ステージ構造 (計画 → 実行 → 検証)、アダプター (ツールインターフェース)、スクリプト (再利用可能な参照)、状態のセマンティクス (ワークスペース、マニフェスト、パスでアクセス可能なオブジェクト)、およびエラー分類 。IHRは、以下の3つの入力を変換します:Backend → Codex、Runtime Charter → Runtime Skill、Harness Logic → Harness Skill。
図3: IHRにおける3層の変換。BackendはCodex(実行環境)に対応し、Runtime CharterはRuntime Skill(共有サービス)に対応し、Harness LogicはHarness Skill(タスクファミリー制御)に対応します。
3層の変換: NLAHシステムは、3つの入力を実行可能なコンポーネントに変換します。(1) モデルのバックエンドがCodexの実行環境となり、(2) 実行時の仕様が再利用可能なRuntime Skillsとなり、(3) ハーネスのロジックがHarness Skillsとなります。これらはすべて、コンパイルされたコードではなく、平易で編集可能なテキストファイルで表現されます。
ファイルバックアップ状態
ファイルベースの状態により、テスト環境の状態が永続化され、検査可能になります。標準的なワークスペースには、TASK.md(実行レベルのタスク定義)、SKILL.md(標準化された結果)、harness-skill/ディレクトリ(制御ロジックと再利用可能なスクリプト)、history/(セッションごとの変更履歴)、RESPONSE.md(子タスクの出力)、および最終的な成果物が含まれます。このアプローチにより、不透明なインメモリの状態が、バージョン管理され、人間が編集可能で、セッションをまたいで永続化される成果物へと変換されます。
Multi-Addressable
Cross-Session
Human-Editable
Versionable
実験デザイン
RQ1
行動効果
ランタイムの共有が、ネイティブコードを使用する場合と比較して、エージェントの動作にどのような影響を与えるのか。ここでは、Full IHRと、Runtime Skill (RTS) と Harness Skill (HS) を除去したものを比較します。
RQ2
モジュール除去 (Module Ablation)
個々のハーネスパターンモジュールが組み合わされた場合に、どのように貢献するのでしょうか? 我々は、以下の6つのモジュールについて検証します:ファイルベースの状態管理、証拠に基づく応答、検証器の分離、自己進化、マルチ候補探索、および動的なオーケストレーション。
RQ3
コードからテキストへの移行
コード中心のアプローチに基づくシステムを、忠実にNLH(Natural Language Harness)形式に移行することは可能でしょうか?私たちは、OS-SymphonyをPythonコードから、自然言語ベースのシステムスキルへと変換しています。
ベンチマークとセットアップ
実験では3つのベンチマークを使用:SWE-bench Verified (125サンプルのサブセット、ソフトウェアエンジニアリング)、Live-SWE (実際のGitHub Issue)、OSWorld (36サンプルのサブセット、デスクトップコンピュータ操作)。ハーネスファミリーにはTRAE(コーディング)、Live-SWE(コーディング)、OS-Symphony(コンピュータ操作)が含まれる。全実験でCodex CLI(GPT-5.4) をベースモデルとして使用。
結果
RQ1: 行動への影響
Full IHRは、プロセス指標(トークン数、コール数、実行時間)に大きな変化をもたらす一方で、解決率を同程度に維持します。 トレジェクトリーレベルでの分析結果から、Full IHRはプロンプトラッパーではない ことがわかります。 つまり、利用されるリソースの約90%は、委譲された子エージェントによって消費されます。 追加された予算は、多段階の探索、候補の比較、成果物の受け渡し、および追加の検証に充てられます。 ほとんどのSWEインスタンス(125のうち110以上)は、Full IHRとアブレーションの切り替えを行っておらず、これは、差異がコンポーネントに敏感な少数のケースに集中していることを意味します。
表1:RQ1 – SWE-bench Verified と Live-SWE ベンチマークにおける、パフォーマンスとプロセスに関する指標。
Benchmark Harness Setting Perf.
Prompt Tokens Completion Tokens Tool Calls
LLM Calls Runtime (min)
SWE Verified TRAE Full IHR 74.4 16.3M 211k 642.6 414.3 32.5 w/o RTS 76.0 11.1M 137k 451.9 260.5 16.6 w/o HS 75.2 1.2M 13.6k 51.1 34.0 6.7 Live-SWE Live-SWE Full IHR 72.8 1.4M 17.0k 58.4 41.4 7.6 w/o RTS 76.0 1.1M 11.7k 41.0 28.2 5.5 w/o HS 75.2 1.2M 13.6k 51.1 34.0 6.7
なぜFull IHRはより多くのリソースを消費するにもかかわらず、同様のスコアを達成するのか? その重要な点は、Full IHRが単にオーバーヘッドを増加させるだけでなく、エージェントの動作方法 を再構築することです。これは、候補の比較と検証を含む多段階の探索を行い、まるで完璧主義者が自分の作業を徹底的に確認するのに対し、素早く問題を解決する人とは異なっています。この追加コストは、平均スコアが類似して見えても、難しいケースにおいて品質を向上させます。
実行時のオーバーヘッドは非常に小さいです。ランタイムが所有する親スレッドは、すべての指標において合計リソースの10%未満を消費し、実際のタスク処理を実行する委任された子エージェントが90%以上を占めます。
表4: 実行時オーバーヘッド - 実行時における親エージェントと子エージェント間のリソース配分
Metric Runtime-owned parent Delegated child agents
Prompt tokens 8.5% 91.5% Completion tokens 8.1% 91.9% Tool calls 9.8% 90.2% LLM calls 9.4% 90.6%
RQ2: Harness Pattern Ablations
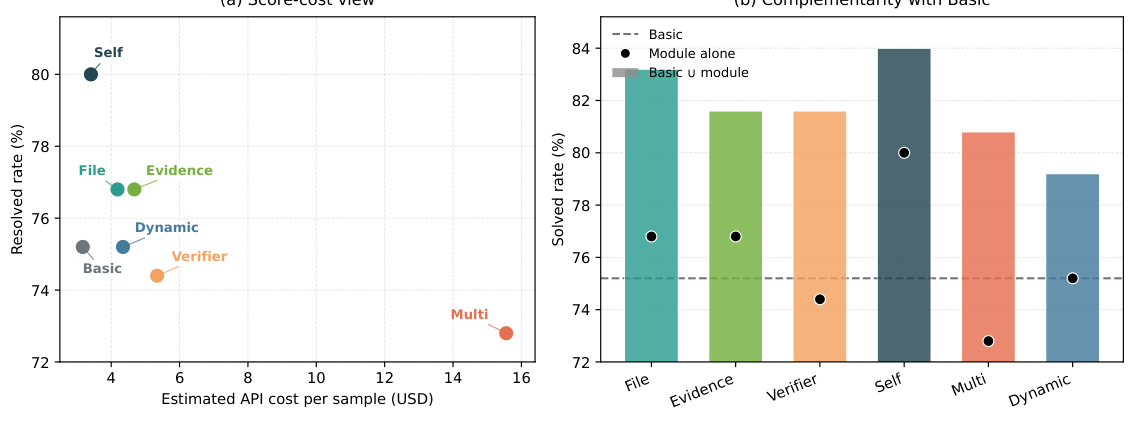
ベンチマーク固有の基本構成から始まり、各モジュールは一つずつ追加されます。Self-Evolution は、SWE Verified で最も高い個別の向上を達成しました (+4.8ポイント、80.0%に到達)。一方、File-Backed State は、OSWorld で最も優れたパフォーマンスを示しました (+5.5ポイント)。マルチ候補検索と検証器は、一部のベンチマークで負の影響を示すため、これらの手法の統合には注意が必要です。コストパフォーマンス分析の結果、Self-Evolution が最も優れたコストパフォーマンス比を提供することがわかりました。
なぜいくつかのモジュールがパフォーマンスに影響を与えるのか?
Verifier (-0.8 on SWE, -8.4 on OSWorld) および Multi-Candidate Search (-2.4 on SWE) の結果がマイナスであることは、実は示唆に富んでいます。Verifier は、検証基準が厳しすぎると、有効な解を却下してしまう追加のチェック機能を持っています。Multi-Candidate Search は、複数の候補解を生成しますが、比較にかかるオーバーヘッドが、そのメリットを上回る可能性があります。これは、チームに例えると、時にはより多くのレビュアーを追加することで、プロジェクトの速度が低下し、品質の向上よりもマイナスの影響を与えることがあります。
表3: RQ2 – モジュールの構成とアブレーション。各モジュールは、個別にBasicを起点として追加されます。
Benchmark Basic File-Backed State
Evidence-Backed Answering Verifier
Self-Evolution Multi-Candidate Search Dynamic Orchestration
SWE Verified 75.2 76.8+1.6 76.8+1.6 74.4-0.8 80.0 +4.8 72.8-2.4 75.20.0 OSWorld 41.7 47.2 +5.5 41.70.0 33.3-8.4 44.4+2.7 36.1-5.6 44.4+2.7
図5: (a) スコア-コストのビュー。各モジュールの解決率と、サンプルあたりの推定APIコストを示しています。Self-Evolutionは、適度なコストで約80%の性能を発揮します。(b) Basicとの相補性。棒グラフはBasic+モジュールの性能、点線はモジュール単体の性能を示しています。File-Backed StateとEvidence-Backed Answeringは、最も相補的なモジュールです。
RQ3: コードからテキストへの移行
OS-SymphonyをPythonコードベースからNLAH形式に移行した結果、劇的な改善が見られました。NLAH版は、元のコードベースと同等であるだけでなく、大幅に優れた パフォーマンスを発揮し、同時に実行時間とエージェントの呼び出し回数を削減しました。これは、自然言語ベースのインターフェースが、LLMが命令をより効果的に活用できるようにする可能性があることを示唆しています。
自然言語版がコード版を上回る理由
これは、おそらくこの論文の中で最も驚くべき発見です。OS-Symphonyのシステムが、Pythonコードから自然言語に書き換えられたとき、パフォーマンスが30.4%から47.2%へと向上しました。これは55%の改善 です。著者らは、LLM(大規模言語モデル)は、厳格なコードベースの制御フローよりも、自然言語による指示をより効果的に活用できると提案しています。これは、熟練した料理人に、詳細なレシピをその母語で与えることと、番号付きステップで構成されたフローチャートを与えることの違いに似ています。自然言語版は意図を伝え、適応的な解釈を可能にします。
0
%
エージェントからの問い合わせが減少しました。
表5: RQ3 — OS-SymphonyのOSWorld上での実装における、コードとNLAHによる実現方法の比較
Benchmark Harness Realization Perf.
Prompt Tokens Completion Tokens Agent Calls
Tool Calls LLM Calls Runtime (min)
OSWorld OS-Symphony Code 30.4 11.4M 147.2k 99 651 1.2k 361.5 NLAH 47.2 15.7M 228.5k 72 683 34 140.8
議論
コードと自然言語
著者は、自然言語がコードの代替になるべきではない と強調しています。代わりに、自然言語は編集可能な高レベルのテストロジックを担い、コードは決定論的な操作、ツールインターフェース、およびサンドボックスの適用を担当します。この科学的な主張は、比較の単位に関するものであり、共有された実行時セマンティクスのもとで、テストパターンロジックを読みやすく実行可能なオブジェクトとして外部化することです。
ハーネスのロジックを自然言語で記述することで、ハーネスを不透明なコードから、検査可能で、編集可能で、科学的に比較可能なオブジェクトへと変えることができます。
自然言語が依然として重要な理由
自然な疑問として、より強力な基盤モデルが、自然言語による制御の価値を低下させるかどうかという点が挙げられます。しかし、その結果は、異なる解釈を示唆しています。自然言語は、ハードウェアレベルの制御 —役割、契約、検証ゲート、永続的な状態のセマンティクス、および委譲の境界—を指定するために使用される場合に、依然として重要であり、単に一度限りのプロンプトの表現にとどまるとは限りません。これは、コンテキストエンジニアリングや長期間にわたるハードウェア設計を重視する実務家の意見と一致しています。
ハーネスの表現の検索
ハーネスが明示的なオブジェクトになったとき、それらは探索空間 となります。明示的なハーネスモジュールは、手動で設計したり、取得したり、移行したり、組み替えたり、そして共有された前提のもとで系統的に除去したりすることができます。将来的には、これはハーネス表現に対する自動的な探索と最適化を示唆しており、ハーネスエンジニアリングがより制御された科学的な対象となる可能性を秘めています。
ハーネス探索空間: これは未来を見据えた洞察です。もしハーネスが明示的なテキストオブジェクトであるならば、それらは潜在的に自動的に最適化 される可能性があります。これは、ニューラルアーキテクチャ探索が最適なモデル構造を見つけ出すのと同様に、最適なハーネス構成を探索することを意味します。これにより、エージェントの設計は、手作業による試行錯誤から、体系的な科学へと移行するでしょう。
制限事項
自然言語は、コードよりも精度が低く、特に隠れたサーバー側の状態や独自のスケジューラに依存する場合には、一部の仕組みをテキストから完全に再現することは困難です。
実行時における混入のリスクは依然として存在します。強力な共有ランタイムの規定は、ハーネステキストに帰属する一部の動作を吸収する可能性があります。
モジュールレベルでのアブレーションは、厳密な因果関係の特定ではありません。テキスト表現は、指示の重要度やプロンプトの長さといった、交絡因子を生じさせる可能性があります。
結論
本論文では、ハーネス設計パターン層を、実行可能で、比較可能で、検証可能なオブジェクトとして外部化できるかどうかを検討しました。自然言語エージェントハーネスとインテリジェントハーネスランタイムを提案し、3つの制御された実験によってその証拠を提供しました。
RQ1: IHRスタックは、運用上実現可能である。フルIHRは、ネイティブコードのハネスと同等のパフォーマンスを発揮し、より高度なマルチステージ探索を可能にする。RQ2: 各モジュールが効果的に連携しており、特に「Self-Evolution」(SWE Verifiedで+4.8)と「File-Backed State」(OSWorldで+5.5)が顕著な貢献を果たしています。RQ3: コードからテキストへの移行は、パフォーマンス(+55%)と効率(実行時間-61%)の両方を向上させ、NL representationの実現可能性を示すものである。
これらの結果は、harness representation science への道筋を示唆しており、ここで「harness」モジュールは、モデルを補完する付随的な要素ではなく、第一級の研究成果として扱われるようになる。