arXiv: 2604.02176 · cs.CL · 2026年4月
LLM (大規模言語モデル) · NLP (自然言語処理) · 頻度則
Adam's Law
大規模言語モデルにおけるテキスト頻度則。
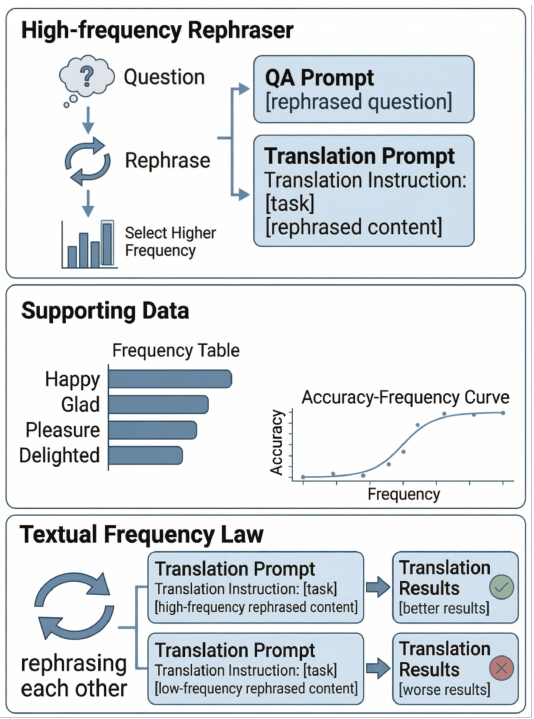
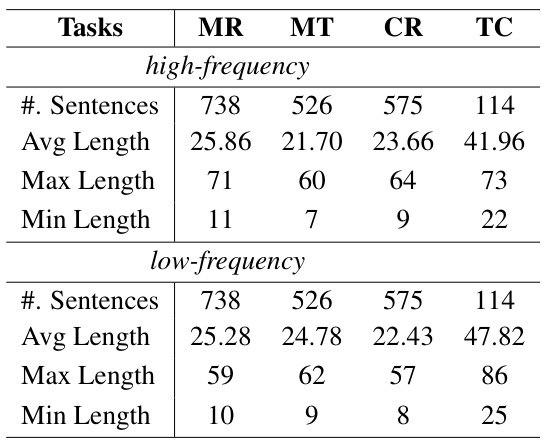
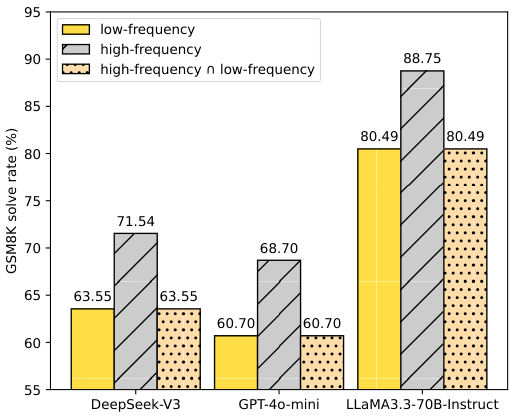
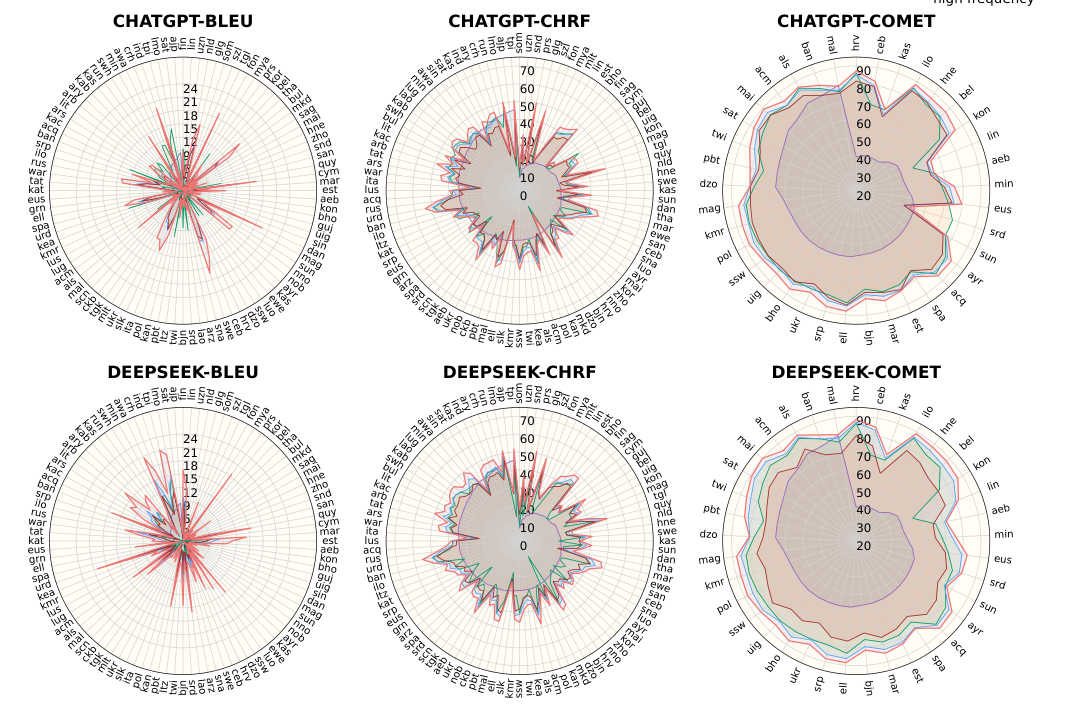
2つの文が同じ意味を持つ場合、LLM(大規模言語モデル)は、より一般的な表現を用いた文の方が常に優れたパフォーマンスを発揮します。本論文では、これを「Textual Frequency Law(テキスト頻度則)」として形式化し、数学的推論、機械翻訳、常識推論、およびツール呼び出しの分野において、その有効性を検証します。
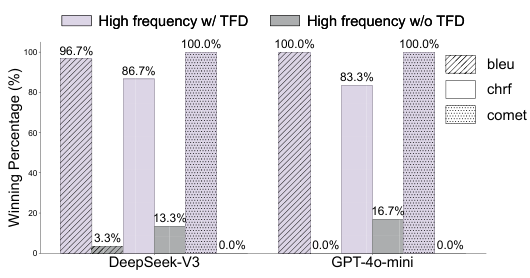
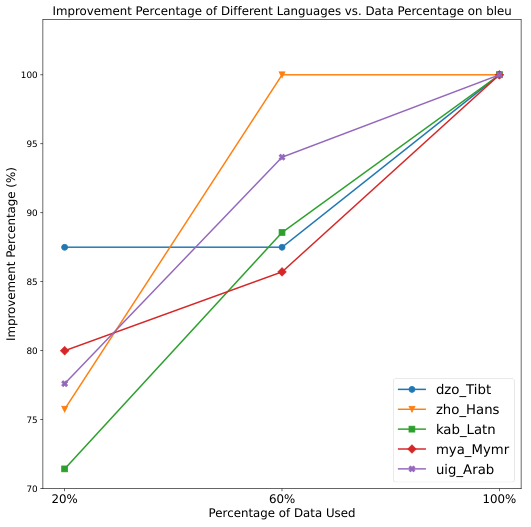
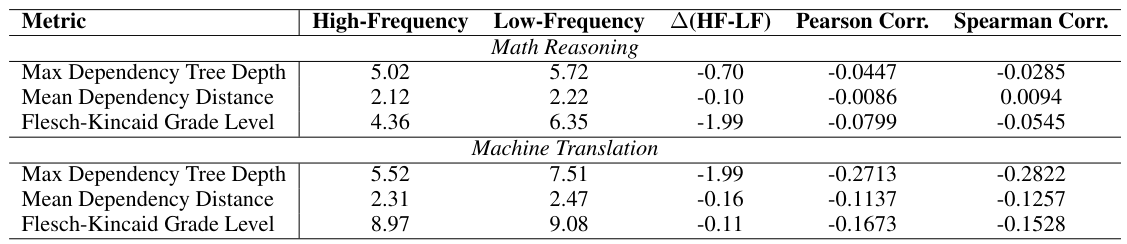
高頻度のプロンプトを使用することで、精度が+8~12%向上します。