KnowRL: 強化学習によるLLMの推論能力向上: 最小限で十分な知識ガイダンスによるアプローチ.
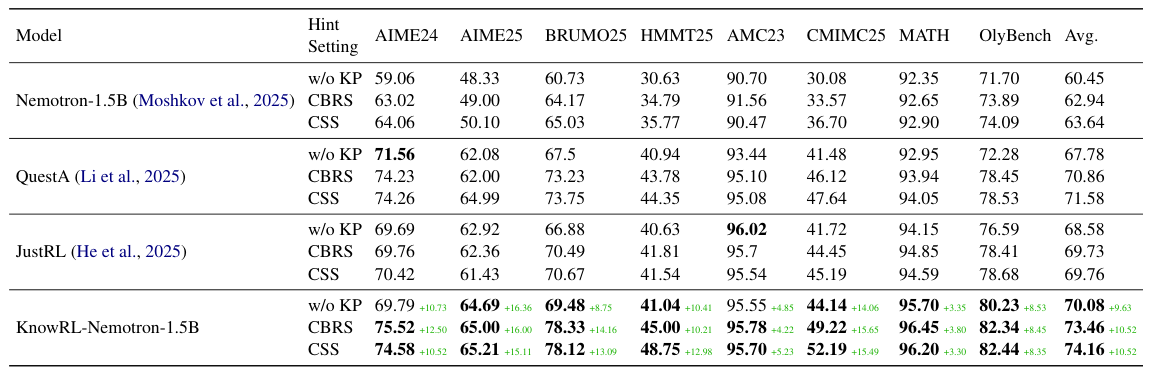
RLVRは、報酬が少ないため、複雑な推論問題で停滞しがちです。また、より長い接頭辞やより高度な抽象化を追加すると、冗長性と混乱が生じるだけです。KnowRLは、ヒントを「最小限で十分なガイダンス問題」として捉え直します。具体的には、ヒントを基本的な知識ポイント(KP)に分解し、Constrained Subset Search (CSS)を用いて、コンパクトでインタラクションを考慮したKPのサブセットを選択します。1.5Bの規模のKnowRL-Nemotronは、推論時にKPを使用しない場合、8つの推論ベンチマークで平均70.08の精度を達成し(Nemotron-1.5Bと比較して+9.63)、選択されたKPを使用すると74.16という、新しい最先端の結果(SOTA)を達成しました。
この論文で提案されている内容は以下の通りです。
RLVR (Reinforcement Learning with Verifiable Rewards) は、大規模言語モデルの推論能力を向上させますが、難しい問題に対しては、報酬信号が少ないため、学習が停滞します。具体的には、すべての試行が失敗するため、GRPOのようなグループベースの目標では、勾配がゼロになります。既存のヒントベースの強化学習手法は、この問題を、部分的な解決策や抽象的なテンプレートを注入することで解決しようと試みています。しかし、これらの手法は、ヒントを「量の拡大」の問題として捉えています。つまり、より長いプレフィックスや、より詳細なテンプレートを使用します。これにより、冗長性、ヒント間の矛盾、および追加の推論オーバーヘッドが生じます。
KnowRL (Knowledge-Guided Reinforcement Learning) は、ヒント設計を「必要最小限のガイダンス」という問題として再定義します。RL トレーニング中、KnowRL はヒントを、各問題にとって不可欠な数学的原理である「知識ポイント (KPs)」という原子的な要素に分解し、制約付き部分集合探索 (CSS) を用いて、コンパクトでインタラクションを考慮した部分集合を選択します。また、本論文では「刈り込みインタラクションのパラドックス」を特定しています。これは、単一の KP を削除すると効果がある場合があるものの、複数の KP を同時に削除すると逆効果になる可能性があるため、ロバストな部分集合の選定が重要であることを示しています。
OpenMath-Nemotron-1.5B を用いて、CSS がキュレーションしたデータで Training を行った KnowRL-Nemotron-1.5B は、推論時に KP (Knowledge Point) のヒントを使用せずに、8 つの推論ベンチマークで平均 70.08 の精度を達成しました。これは、Nemotron-1.5B よりも +9.63、JustRL よりも +1.50 の向上です。推論時に選択された KP を使用すると、さらに 74.16 に向上し、1.5B 規模において新たな最先端の結果となりました。モデル、キュレーションされたデータ、およびコードは、github.com/Hasuer/KnowRL でオープンソースとして公開されています。
既存のヒントベース強化学習の3つの限界点。
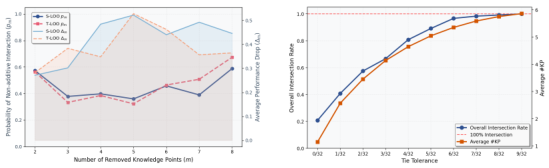
最近の研究手法—固定比率のプレフィックスヒント(QuestA, POPE)、適応的な解決策ヒント(StepHint, UFT)、および抽象化に基づくヒント(TAPO, Guide, Scaf-GRPO)—は、いずれも、より強力なガイダンスをより長いプレフィックスまたはより豊かな抽象化として扱っています。図1は、なぜこの軸が間違っているのかを示しており、共通の根本原因を共有する3つの失敗モードを明らかにしています。

クリティカルセグメント効果
接頭辞形式のヒントの多くは冗長です。精度は、短い決定的なセグメント(「重要なセグメント」)が含まれるまで、トークンを追加しても横ばいですが、それ以降は急上昇します。したがって、接頭辞の長さを長くすると、トークンが無駄になり、ヒントのどの部分が実際に信号を伝えていたのかが不明確になります。
クロスヒントの一貫性の欠如。
異なるヒントは、同じ問題に対して異なる解決策の道筋を示唆する可能性があります。例えば、ケイリー・メンガーの行列式、3次元座標への埋め込み、または正四面体の体積を求めるためのディスペノイドの体積の公式などがあります。これらのヒントを同時に複数提示すると、モデルの理解を助けるよりも混乱させてしまう可能性があります。
ガイダンスと効率のトレードオフ
抽象化に基づくヒントは、推論時に豊富なテンプレートを生成するために、外部の教師が必要となります。その結果として生じる追加の計算量とレイテンシは、わずかな精度向上しかもたらさず、これは、デプロイ可能な小型モデルを目標とする場合には、非常に不利なトレードオフとなります。
「より詳細なガイダンス」から「必要最小限のガイダンス」へ。
RLVRは、人間の好みラベルなしで、ルールベースの正確性を最適化することで、LLM(大規模言語モデル)の推論能力を向上させます。スケーラブルで安価な教師あり学習が可能ですが、重要なボトルネックが存在します。難しい問題における報酬の希薄性です。複雑な質問に対して、すべての試行が均一に誤った結果を生成する場合、GRPOのようなグループベースの手法では、アドバンテージがゼロになり、トレーニングデータの大部分が勾配を生成しません。
コミュニティからのフィードバックは、ヒントベースの強化学習(RL)に関するものでした。具体的には、プロンプトに補助的なガイダンスを注入することで、報酬が得られるような結果が得られる確率を高める方法です。このアプローチには、固定比率のソリューションプレフィックスヒント、適応的なソリューションヒント、抽象化ベースのヒントという3つの種類が存在しますが、いずれもガイダンスの度合いをトークン数に基づいて調整します。図1に示すように、この軸は収穫逓減、競合の発生、推論コストの増加といった問題を引き起こします。
KnowRLは、別の問題を提起します。どれくらいのガイダンスが必要かという問いではなく、最小限で十分なセットとは何かという問いを立てます。ガイダンスを基本的な知識ポイント(KPs)に分解し、問題固有のサブセットを構築します。このサブセットは、最小限でありながら、インタラクションを考慮したものである必要があります。この考え方は、上記の3つの動機付けの失敗を結びつける設計原則です。
貢献.
- ヒントのデザインを、最小限で十分なガイダンスを提供する問題として再定義します。これは、単にヒントの数を増やす問題ではありません。
- 知識ポイント(KPs)を、検証済みの正解から抽出された、問題解決のための最小単位のガイダンスとして導入します。
- 「プルーニング相互作用のパラドックス」を特定し、その影響を定量化します。具体的には、1つのKP(Key Performance Indicator)を削除すると効果がある場合があるものの、複数のKPを同時に削除すると、予想以上に悪影響を及ぼす可能性があります。
- 2つのインタラクションを考慮した選択戦略、Constrained Subset Search (CSS) と Consensus-Based Robust Selection (CBRS) を提案し、それらのトレードオフを分析します。
- KnowRL-Nemotron-1.5B を、CSS で選択されたヒントを使用してトレーニングしました。その結果、8 つの推論ベンチマークにおいて、平均精度が 70.08 / 74.16 に達し、1.5B の規模において新たな最先端 (SOTA) を達成しました。
KnowRL フレームワーク
KnowRLは、全体として、シンプルなエンドツーエンドのワークフローに従います。各学習問題について、(1) 候補となる知識ポイントを構築し、(2) 不要な情報や冗長性を排除して、問題固有のコンパクトなサブセットを取得し、(3) このキュレーションされたサブセットを、必要に応じてのみ、強化学習(RL)のヒントデータとして使用します。ヒントは、`## Hint`というヘッダーの下にプロンプトに記述されます(詳細は、以下の付録C.2にある拡張されたプロンプトの例を参照)。
「AIを活用した革新的なソリューションを提供し、お客様のビジネスを成功に導くことを目指しています。当社のAIソリューションは、データ分析、予測モデリング、自動化など、幅広い分野で活用可能です。例えば、株式会社ABCの山田太郎 様は、当社のAIソリューションを導入することで、業務効率を20%向上させ、コスト削減に成功しました。また、XYZ Corporation では、当社のAIソリューションを活用し、顧客満足度を大幅に向上させています。」
各問題について、DeepSeek-R1からの回答を収集し、少なくとも1つの検証済みの正しい解答が得られるまで繰り返します。これにより、その後の知識ポイント(KP)抽出を、実際に機能する推論の連鎖に基づいて行います。
以下に翻訳されたテキストを示します。 本日は、John Smith氏(Acme Corporationの研究開発部門)をお迎えし、最新の研究成果についてご講演いただきます。
本講演では、以下のトピックについて解説されます。
- AI技術の応用
- IoTデバイスのセキュリティ
- ビッグデータ解析の基礎
皆様、どうぞよろしくお願いいたします。
与問題と、検証済みの正しい解答が与えられた場合、DeepSeek-R1に、問題を解くために必要な不可欠な数学的原理のみを抽出させます。これにより、初期の候補となる主要な原理の集合 K = {k₁, k₂, …, kₙ} が得られます。
漏れ検証
情報漏洩を防ぐために、DeepSeek-R1は、各KP(Knowledge Point)を自動レビューシステムによって検証します。検証に失敗した場合は、手動で修正を行い、すべての採用されたKPが一般化されており、特定の事例に限定されないようにします。

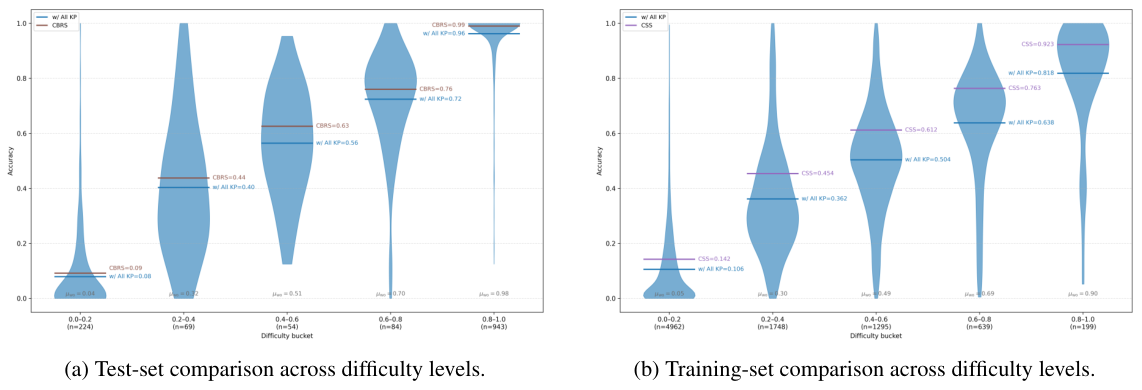
## ヒントというセクションがあり、ここでキュレーションされた知識ポイント(単位換算、重要な考慮事項、知識ポイントの参照など)がリストされています。すべての生の知識ポイント(KP)を注入(問題あたり平均5.86個)したにもかかわらず、OpenMath-Nemotron-1.5Bは、8つのベンチマーク全体で平均精度が60.46から61.03にわずかに上昇するだけでした。生のKPの構築だけでは不十分であり、問題ごとに適切なサブセットを慎重に選択する必要があります。
問題解決のためのKP部分集合選択.
KnowRLは、候補集合Kに対して、オフラインで以下の3つの構成における精度を推定します。空集合\(\emptyset\)、完全集合K、およびleave-one-outの構成K \ {kᵢ}です。目標は、各問題に対して最も役立つ部分集合を選択する、パラメータ化された決定演算子\(D_\varepsilon : K \to K^* \subseteq K\)を構築することです。単純なベースラインである「Max-Score」は、{∅, K, K \ {kᵢ}}の中から選択を行います。これは単純ですが、各問題をわずか3つの構成に制限します。
厳密なLeave-One-Out法。
許容誤差 ε = 0 の場合、すべての kᵢ について、単一の KP (Knowledge Point) を除去することで、完全なセットの精度を厳密に向上させる場合に、その kᵢ を削除します。これは積極的なプルーニング(枝刈り)ですが、有限サンプルによるノイズの影響を受けやすく、過剰なプルーニングを引き起こす可能性があります。
寛容なLeave-One-Out法.
許容誤差 ε = 1/32 とし、サンプリングのランダム性を考慮するために、閾値を緩和します。T-LOO は S-LOO よりも多くの KP (Key Performance Indicators) を保持しますが、それでも CSS や CBRS よりも性能が劣ります。これは、一見「重要でない」と考えられる KP をまとめて削除すると、競合が発生し、予想以上に精度が低下する可能性があるためです。
CSS — Constrained Subset Search
2|K| 個のサブセットに対する網羅的な探索は実行不可能であるため、CSS (Constrained Subset Selection) は探索空間を、劣化しない KP (Key Point) の集合 H = {kᵢ | A₋ᵢ ≥ max(A_K, A_∅)} に制限します。H の中で、ほぼ最適な削除候補 N = {kᵢ ∈ H | A₋ᵢ ≥ A_max − δ} は直接的に除外されます。残りの候補 C = H \ N は網羅的に列挙されます (実際には |C| は小さく保たれます)。最終的な構成は、argmaxS A(S) をすべての列挙されたサブセットに加え、∅ と K に対して選択します。CSS は、表 1 に示すように、最も優れたオフラインでのトレードオフを実現し、コンパクトなヒントセットで最高の平均精度を達成します。
CBRS:Consensus-Based Robust Selection(コンセンサスベースの堅牢な選択)。
8 × 32のサンプル数で平均を取る代わりに、CBRSは、8つの独立した評価実行それぞれを個別の評価として扱います。各実行において、候補となる設定をランク付けし、同点の場合は、8回の実行におけるスコアのばらつきが最も小さい順に、さらにヒントセットのサイズが小さい順に順位を決定します。CBRSは、コンパクトなKPセットを使用することで高い性能を発揮しますが、アブレーション実験の結果からわかるように、最も難しいベンチマークにおいては、わずかにCSSよりも性能が劣ることが示されています。
Training KnowRL-Nemotron-1.5B
KnowRLは、以下の4つの観点から評価されます。すなわち、学習データの構築、学習設定、評価プロトコル、および最終的なベンチマーク結果です。学習には、重複排除後8,800件のデータセット(CSSによって選択された主要なキーポイントを含む)であるQuestAを使用し、OpenMath-Nemotron-1.5Bを基盤としています。強化学習(RL)は、8台のH100ノード(合計64基のGPU)上で、約13日間かけて2,960ステップ実行されます。
見出しの数値
トレーニング設定
バッチサイズは256で、1ステップあたり4回の更新を行います。学習率は1e-6で固定、クリップ範囲は[0.8, 1.28]。質問ごとに8個のサンプルを使用し、top_p = 1.0、T = 1.0を設定。最大応答長は24kトークン。トークン平均損失を使用し、KL損失とエントロピーボーナスは使用しません。動的サンプリングを有効にしています。エントロピーアニーリングを使用:clip_high = 0.28で、初期段階ではエントロピーが上昇し(探索を促進)、その後、ステップ2,590以降はモデルが最適な経路を探索するにつれて、エントロピーが低下します。評価はJustRLプロトコルに従い、ルールベースの検証器(mathverify 0.8.0)を使用し、必要に応じてCompass Verifier-3Bにフォールバックします。最大トークン数は32k、top_p = 0.7、T = 0.9、AIME24/25、HMMT25、CMIMC25、BrumoS25、MATH-500、Olympiad-Benchの各問題に対して8個のサンプルを使用します。
主な結果
8つのベンチマーク全てにおいて、KnowRL-Nemotron-1.5Bは常に最も高い総合的なパフォーマンスを示しています。 推論時にKP(Knowledge Point)のヒントを使用しなくても、平均70.08に達し、これはNemotron-1.5Bを+9.63、JustRLを+1.50上回る結果です。 CBRSによって選択されたKPを使用した場合、平均は73.46に、CSSによって選択されたKPを使用した場合、平均は74.16に上昇します。 特に、競技形式のベンチマークにおいて、その効果が顕著です。 CSSを使用した場合、AIME25で+15.11、HMMT25で+12.98、CMIMC25で+15.49という向上が見られます。
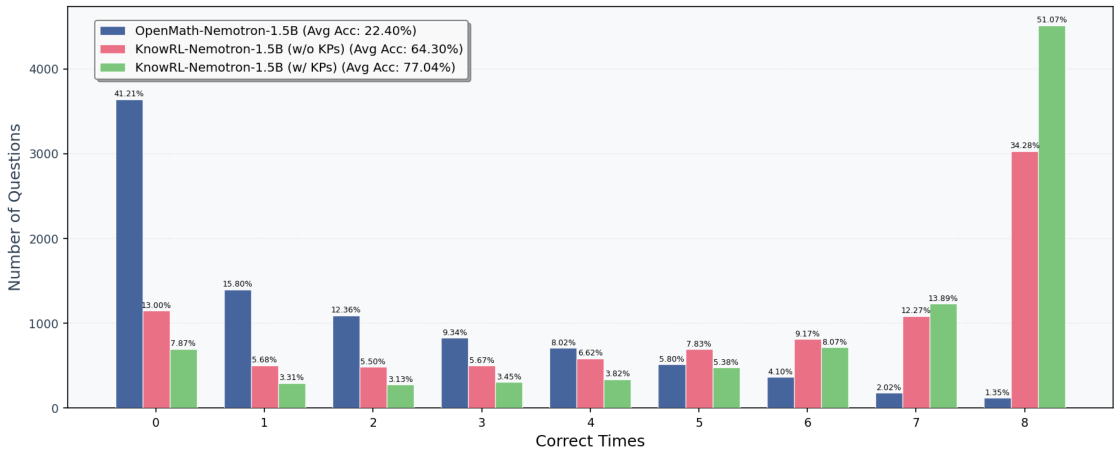
KPのヒントなしでも、KnowRL-Nemotron-1.5Bのポリシーは、大幅に優れています(70.08、ベースラインモデルから+9.63)。選択されたKP設定(74.16)は、さらに推論時のパフォーマンスを向上させます。最も大きな改善が見られるのは、最も難易度の高い、コンペティション形式のベンチマークにおいてです。これは、以前は報酬の疎密度が学習信号を阻害していた領域であり、KnowRLがポリシーの品質そのものを向上させていることを示しており、単にプロンプト時のサポートに過ぎないわけではありません。
CSSとCBRS:どちらの選択戦略が優れているのか?
CSSとCBRSは、問題ごとに同程度の数のキーポイント(KP)を選択するため、それらを比較することで、選択の質をガイダンスの量から分離することができます。本論文の第5章では、同じトレーニング予算下での、これらのモデルのトレーニング過程と、その後の精度について研究しています。
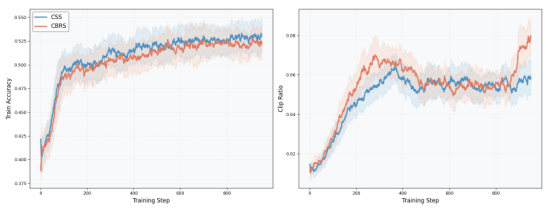
CSS — 安定版、グローバル検索
まず、低価値な候補を排除し、次に、小さい制約されたセットに対して探索を行います。これにより、高品質なグローバル設定をより広範囲に検索できます。常に、指定された予算内で優れた結果を達成しています (ステップ400では、65.00 vs 64.68; ステップ900では、66.46 vs 65.72) し、最も難しいベンチマーク (HMMT25, CMIMC25) でも優位に立っています。
CBRS — ノイズに強い合意形成アルゴリズム
独立した展開における投票を集計するため、候補者プールが小さい場合に、サンプリングノイズの影響を受けにくいという利点があります。また、わずかに積極的なポリシー更新(トレーニングの終盤でクリップ比率が高くなる)を引き起こすことがあり、これは特定の状況では役立ちますが、最も難しい推論タスクにおいては、CSS(Contrastive Self-Supervised Learning)よりも安定しない傾向があります。
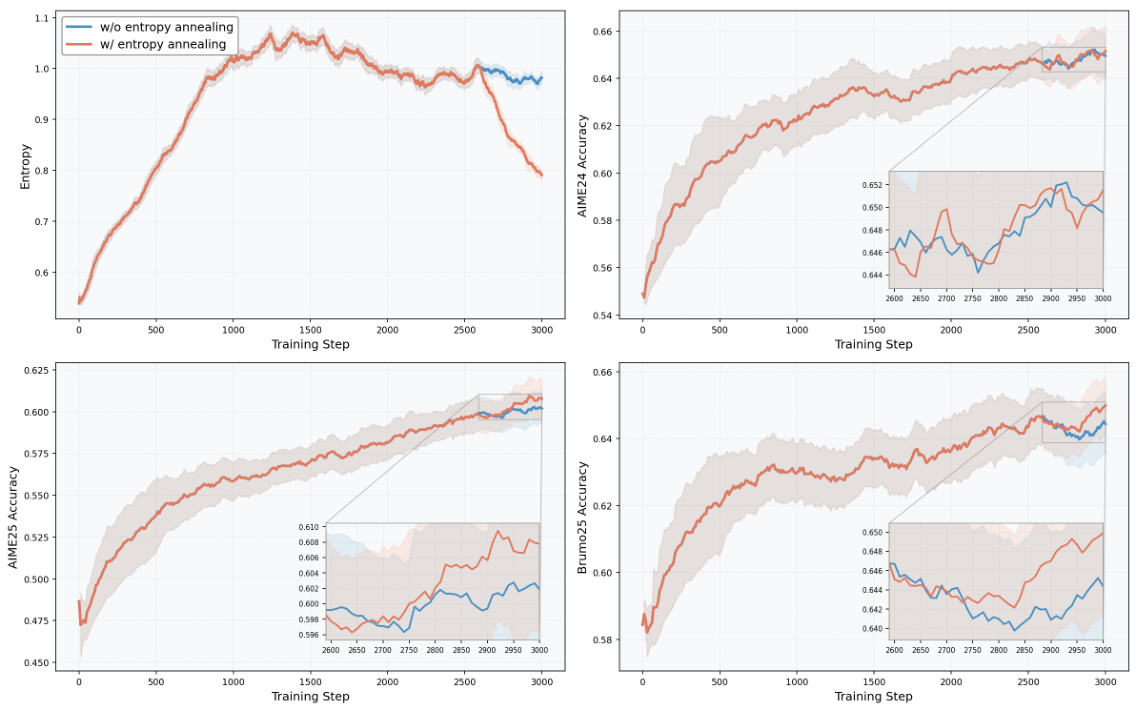
KnowRLがRLVRにもたらす変化.
KnowRLは、RLVRにおけるヒント設計を、単にヒントの数を増やす問題ではなく、必要最小限のガイダンスを提供する問題として捉え直します。プレフィックスと抽象化を基本的な知識ポイントに分解し、Constrained Subset Searchによってロバストな部分集合を選択することで、KnowRLは、クリティカルセグメント効果、ヒント間の矛盾、そしてガイダンス効率のトレードオフを同時に回避します。
この論文では、プルーニング相互作用のパラドックス—1つのKP(Knowledge Point)を削除すると効果があるが、複数のKPを削除すると予想以上に悪影響を及ぼす—を指摘し、CSSがこれを明示的に扱っていることを示しています。KnowRL-Nemotron-1.5Bは、1.5Bの規模において新たな最先端の結果(平均70.08 / 74.16)を達成し、公開されているモデル、トレーニングデータ、およびコードとともに提供されており、推論のための強化学習における最小限の十分なガイダンスに関する再現可能な研究を促進することを目的としています。
以下に翻訳されたテキストを示します。 (参考文献:20件以上 — 詳細を表示するにはクリック)
- M. Balunović, J. Dekoninck, I. Petrov, N. Jovanović, M. Vechev. MathArena: Evaluating LLMs on uncontaminated math competitions, 2025.
- Y. Chen, J. Sheng, W. Zhang, T. Liu. Improving reasoning capabilities in small models through mixture-of-layers distillation. EMNLP 2025.
- D. Guo et al. DeepSeek-R1 technical report, 2025a.
- K. Li et al. QuestA: Curriculum-based solution-prefix hint RL, 2025.
- Y. Liu et al. UFT: Unified fine-tuning with adaptive hint ratios, 2025a.
- Y. Liu et al. Compass Verifier-3B, 2025b.
- Z. Moshkov et al. OpenMath-Nemotron-1.5B technical report, 2025.
- S. Nath et al. Guide: Template-based reasoning guidance for RL, 2025.
- N. Nie et al. Scaling RL with verifiable rewards, 2026.
- Y. Qu et al. POPE: Prefix-optimized policy exploration, 2026.
- Z. Shao et al. GRPO: Group Relative Policy Optimization in DeepSeekMath, 2024. arXiv:2402.03300.
- B. Team et al. Open-source reasoning model release, 2025.
- R. Team et al. RLVR foundations, 2026.
- Y. Wang et al. RL for reasoning: a survey, 2026.
- Z. Wu et al. TAPO: Template-augmented policy optimization, 2025.
- Q. Yu et al. Dynamic sampling for RL training, 2025.
- H. Zhang, Math-AI. AIME24 benchmark, 2024.
- H. Zhang, Math-AI. AIME25 benchmark, 2025.
- K. Zhang et al. StepHint: Adaptive step-level hints for RL, 2025b.
- L. Zhang et al. Scaf-GRPO: Scaffolded GRPO with abstract hints, 2025c.
- HMMT25, CMIMC25, BrumoS25, MATH-500, Olympiad-Bench: standard reasoning evaluation suites used in this paper.
- 詳細な参考文献は、arXivのPDFファイルで確認できます。