MemTensor (Shanghai) Technology Co., Ltd. · Institute for Advanced Algorithms Research, Shanghai · Research Institute of China Telecom · Tongji University · Zhejiang University
LLMs lack well-defined memory management systems, limiting long-context reasoning and continual personalization. We propose MemOS, a memory operating system that treats memory as a first-class resource — unifying plaintext, activation-based, and parameter-level memories under a single hierarchical framework called MemCube.
What does 'memory as a first-class resource' mean? In traditional OS design, the CPU, RAM, and storage are managed as first-class resources — the OS controls allocation, scheduling, and lifecycle. MemOS applies this same principle to LLM memory: rather than treating memory as an afterthought (like RAG bolted onto a stateless model), MemOS gives memory the same systematic management primitives that OSes give to hardware.
Benchmark Results
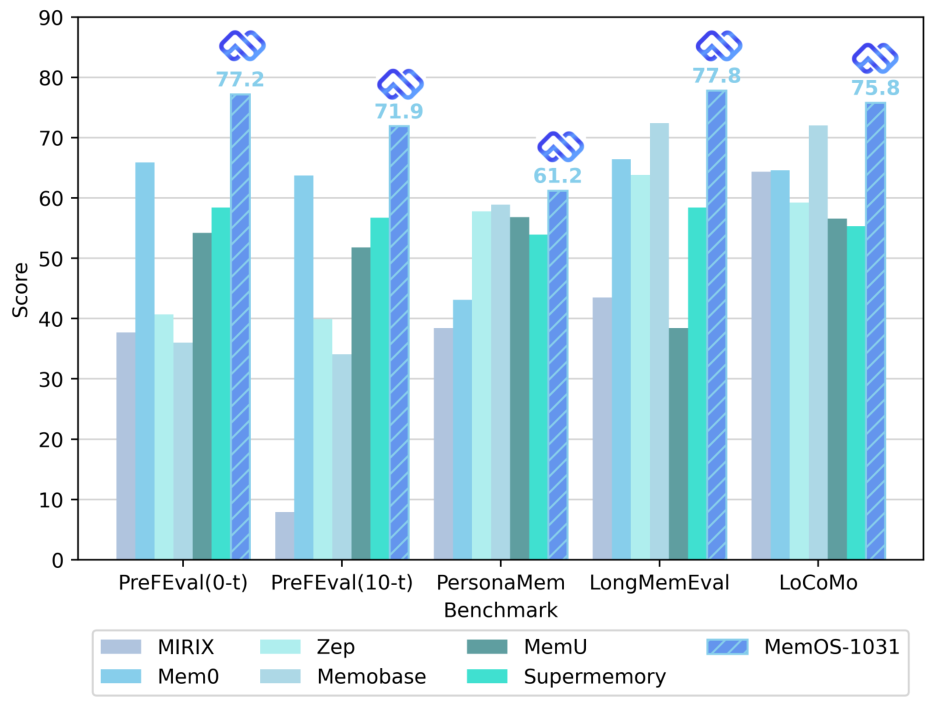
MemOS achieves state-of-the-art performance across all major memory benchmarks (PrefEval-0t, PrefEval-10t, PersonaMem, LongMemEval, LoCoMo), outperforming Mem0, Zep, MemBase, MIRIX, and Supermemory.
6
Benchmarks — #1 on all
Figure 1: MemOS achieves state-of-the-art performance across PrefEval, PersonaMem, LongMemEval, and LoCoMo benchmarks, consistently outperforming all baselines.
PrefEval-0t#1
PersonaMem#1
LongMemEval#1
LoCoMo#1
1. Introduction
With the advent of the Transformer architecture and the maturation of self-supervised pretraining, Large Language Models (LLMs) have become the cornerstone of modern AI. Trained on massive corpora, these models encode vast amounts of world knowledge in their parameters and demonstrate remarkable cross-task generalization.
However, a fundamental challenge remains: LLMs are inherently stateless. Each session starts from scratch, without persistent memory of past interactions, user preferences, or evolving knowledge. As LLMs transition from tools to persistent agents operating across time and space, this limitation becomes a critical bottleneck.
Existing approaches like Retrieval-Augmented Generation (RAG) treat memory as an afterthought — a stateless workaround without lifecycle control or integration with persistent representations. While RAG introduces external knowledge in plain text, it cannot unify heterogeneous memory types or manage memory evolution over time.
To address this, we propose MemOS: a Memory Operating System for AI systems. MemOS unifies the representation, scheduling, and evolution of plaintext, activation-based, and parameter-level memories, enabling cost-efficient storage and retrieval. The core unit — MemCube — encapsulates both memory content and metadata such as provenance and versioning.
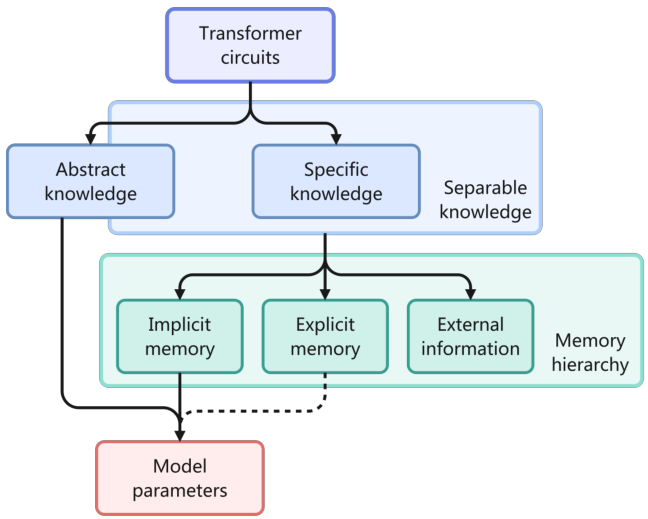
Figure 2: Categorization of LLM knowledge — Transformer circuits generate abstract and specific knowledge, which maps to the memory hierarchy (implicit, explicit, and external information). Abstract knowledge eventually flows back to model parameters.
2. Memory in Large Language Models
Research on LLM memory has progressed through four key stages — from early definitions of implicit and explicit memory, through human-like memory architectures, to the current era of systematic memory operating systems.
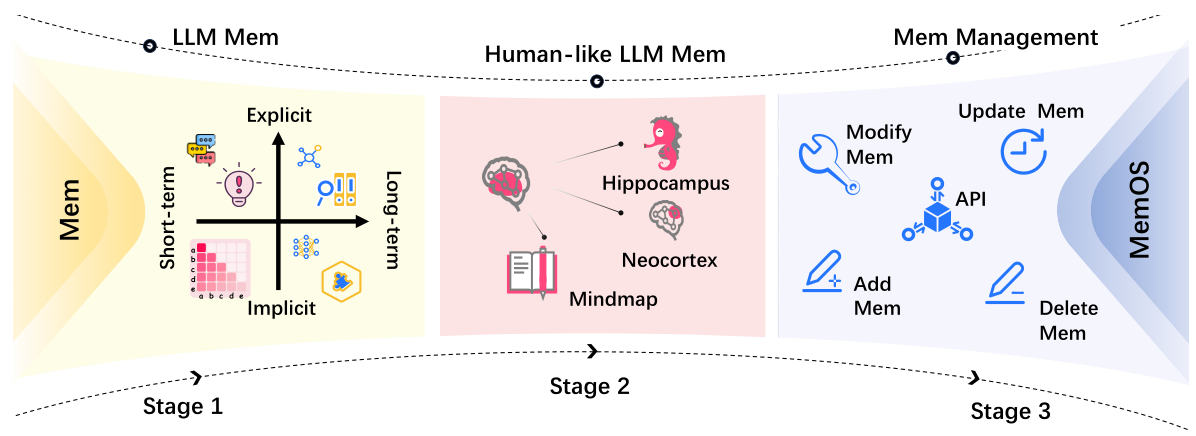
Figure 3: Evolution of memory systems in LLMs — Stage 1 (Memory Definition), Stage 2 (Human-like Memory), Stage 3 (Tool-based Memory Management), leading to MemOS (Stage 4: Systematic Memory Governance).
Stage 1
Memory Definition & Exploration
Early work explored the distinction between implicit memory (encoded in model weights via pretraining) and explicit memory (stored externally as text or key-value pairs). Representative systems: RAG, kNN-LMs, prefix tuning.
Stage 2
Human-like Memory Systems
Inspired by the hippocampus (short-term recall) and neocortex (long-term consolidation), researchers developed multi-component memory architectures with mind-map-like structures for persistent knowledge storage.
Stage 3
Tool-based Memory Management
Systems like Mem0 and Zep introduced explicit APIs for memory operations (Add, Modify, Update, Delete). However, these remain siloed — unable to unify heterogeneous memory types under a single framework.
Stage 4
Systematic Memory Governance (MemOS)
MemOS introduces OS-level resource management principles to LLM memory — unified scheduling, lifecycle control, governance policies, and cross-type memory migration. This is the first system to treat memory as a first-class OS resource.
3. MemOS Design Philosophy
3.1 Vision: Mem-training as the Next Scaling Law
As AGI advances toward increasingly complex systems involving multiple tasks, roles, and modalities, LLMs must go beyond merely "understanding the world" — they must also accumulate experience, retain preferences, and evolve over time.
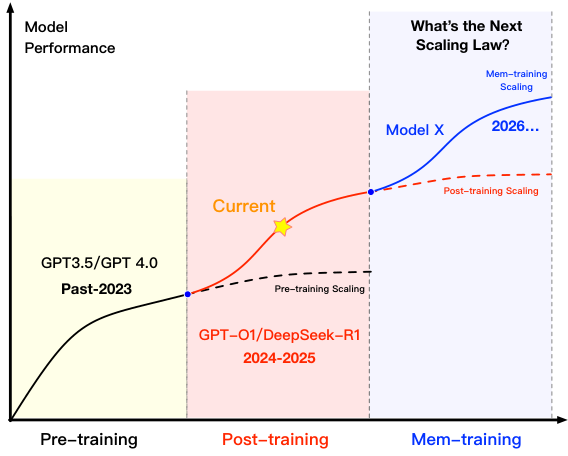
Model performance is approaching the upper limits predicted by traditional scaling laws. The prevailing research paradigm is transitioning from data- and parameter-centric pretraining to reinforcement alignment (post-training, e.g., GPT-O1, DeepSeek-R1). Yet this shift faces diminishing returns.
MemOS proposes Mem-training Scaling as the next frontier: by continuously accumulating and refining memory across deployments, LLMs can break through post-training performance ceilings. Thousands of heterogeneously deployed model instances can gather experience in situ and exchange it via MemOS infrastructure.
Figure 4: Phased transitions in model performance scaling. Pre-training (GPT-3.5/4.0) → Post-training (GPT-O1/DeepSeek-R1) → Mem-training Scaling (MemOS, 2026+). Each phase unlocks new performance gains after the previous plateaus.
3.2 From Computer OS to Memory OS
In traditional computing systems, the OS centrally manages hardware resources (CPU, memory, storage) to support efficient application execution. MemOS applies this same principle to LLM memory resources.
The table below maps traditional OS components to their MemOS counterparts. Just as an OS abstracts hardware for applications, MemOS abstracts heterogeneous memory types (parameter, activation, plaintext) for LLM applications:
Traditional OS
MemOS Module
Function
Registers / Microcode
Parameter Memory
Long-term ability
Cache / I/O Buffer
Activation Memory
Fast working state
Main Memory
Plaintext Memory
External episodes
Scheduler
MemScheduler
Prioritise ops
File System
MemVault
Versioned store
System Call
Memory API
Unified access
Device Driver
MemLoader / Dumper
Move memories
Package Manager
MemStore
Share bundles
Auth / ACLs
MemGovernance
Access control
Syslog
Audit Log
Audit trail
4. Memory Modeling in MemOS
4.1 Three Types of Memory
MemOS systematizes LLM memory into three core types that together reflect a full spectrum of knowledge representation — from volatile inference state to durable parameter knowledge:
📄
Plaintext Memory
Explicitly stored, structured/unstructured text — conversation histories, user preferences, episodic notes. Highest interpretability, lowest integration cost. Analogous to main RAM for fast access.
⚡
Activation Memory
Inference-coupled activation states — KV cache, hidden state steering vectors. Bridges plaintext and parameter memory. Enables fast working state injection without full fine-tuning.
🧠
Parameter Memory
Implicitly embedded knowledge in model weights — LoRA adapters, weight patches, fine-tuned modules. Highest integration depth and durability. Used for long-term skill and knowledge consolidation.
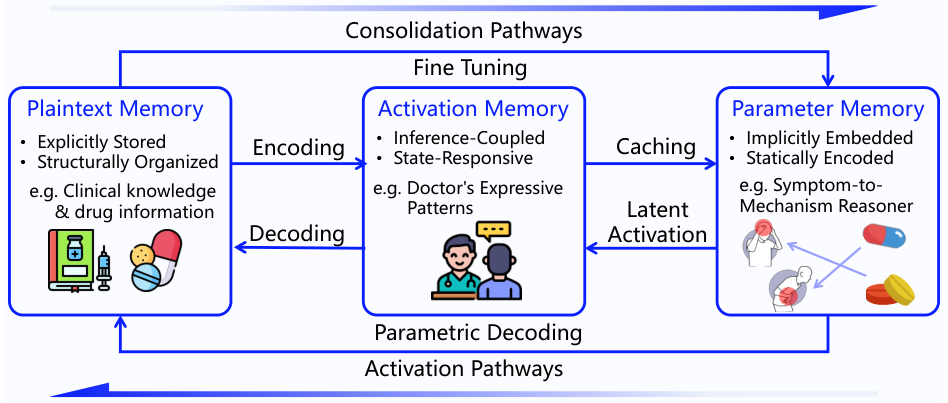
The three memory types explained simply: Think of an AI assistant as a computer. Plaintext Memory is like a text file — easy to read, easy to update. Activation Memory is like RAM — fast to access but requires the computer to be running. Parameter Memory is like firmware — deeply embedded, takes effort to change, but persists forever. MemOS manages all three in a unified way.
Figure 5: Transformation paths among three memory types. Consolidation pathways (top): Fine-tuning encodes plaintext into parameters; Caching converts to activation. Activation pathways (bottom): Parametric decoding retrieves knowledge as plaintext or activation states.
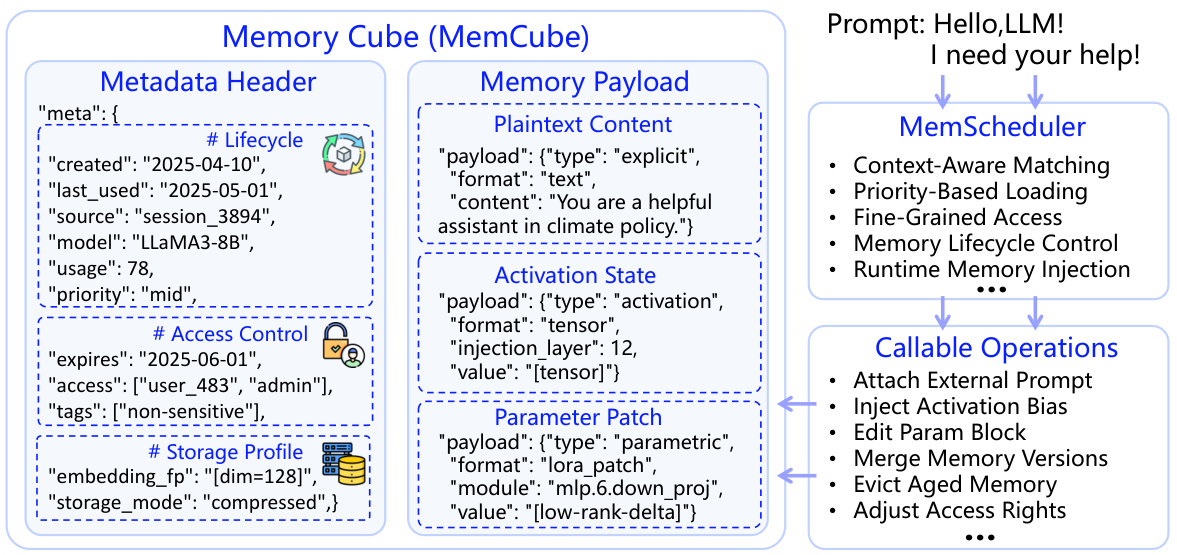
Why MemCube is important: Different types of memory (text, activation, weights) have completely different data formats. Normally, you'd need separate systems to manage each. MemCube is like a standardized shipping container — no matter what's inside (plaintext, KV tensor, LoRA weights), the outside interface is the same: lifecycle timestamps, access control, priority, storage mode. This makes scheduling, migration, and composition of heterogeneous memory possible.
4.2 MemCube: The Core Memory Unit
MemCube is the unified abstraction that standardizes memory representation, lifecycle management, and scheduling across all three memory types.
Each MemCube consists of a Metadata Header (lifecycle timestamps, access control lists, storage profile) and a Memory Payload (plaintext content, activation state, or parameter patch). MemCubes can be composed, migrated, and fused over time.
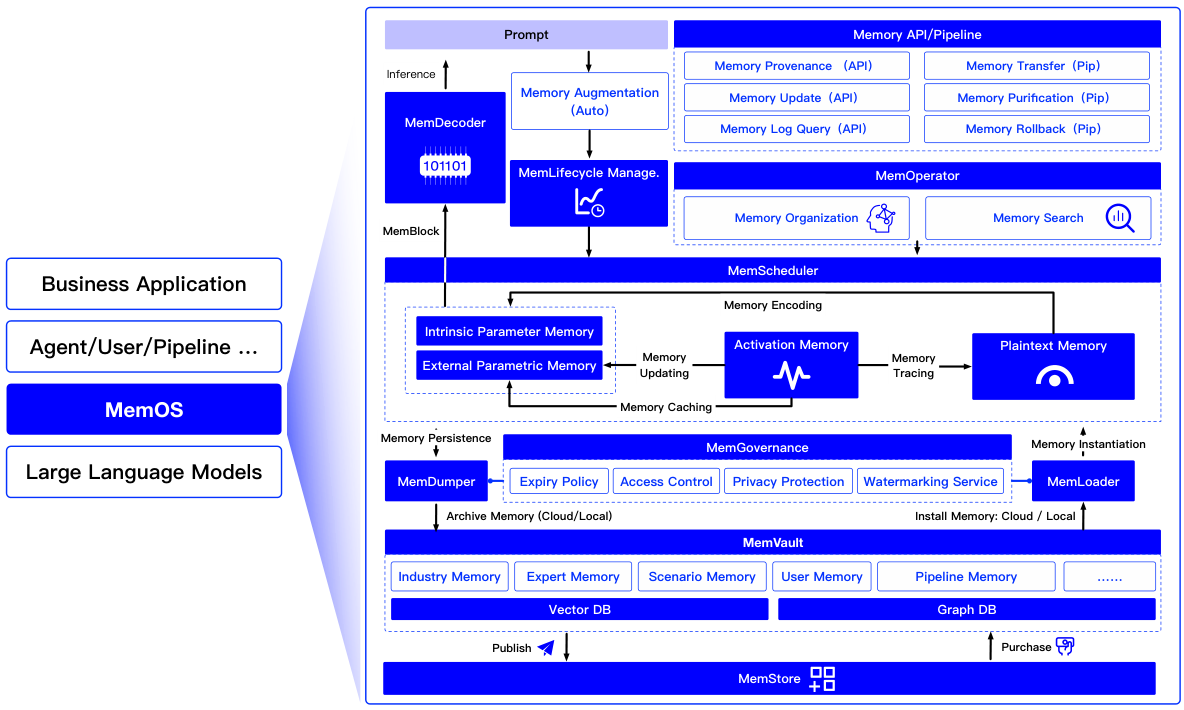
The MemScheduler handles context-aware matching, priority-based loading, memory lifecycle control, and runtime memory injection — routing the right MemCubes to the right LLM at the right time:
MemGovernance — Access control lists, privacy protection, compliance policies across all memory operations
MemVault — Versioned persistent storage with provenance tracking and rollback support
MemStore — Shareable memory bundle marketplace — enables memory transfer across model instances
MemScheduler: the dispatcher analogy. In an OS, the process scheduler decides which process gets CPU time. MemScheduler does the same for memory: it decides which MemCubes to load into the LLM context at inference time, based on semantic relevance to the current query, priority scores, access permissions, and available context window budget. This is why MemOS can serve thousands of concurrent users with personalized memory without loading everyone's memories all at once.
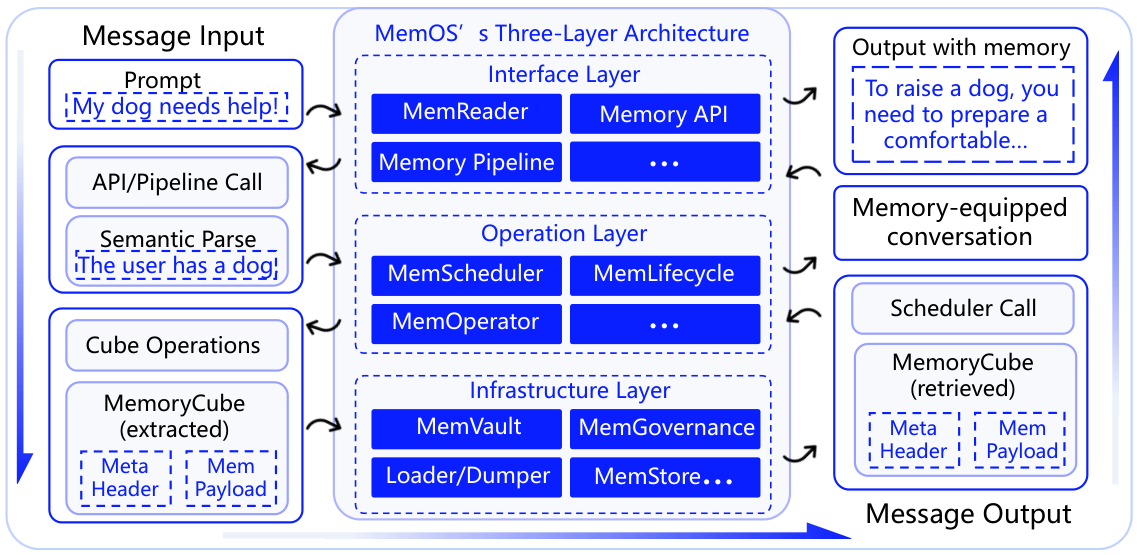
Figure 7: Overview of the MemOS framework — full 3-layer architecture showing Memory API Plane, MemOperator, MemScheduler, MemLifecycle, and Infrastructure (MemGovernance, MemVault, MemStore, MemLoader/Dumper).Figure 8: MemOS architecture and memory interaction flow. Input → Semantic Parse → MemCube extraction → 3-layer processing → Memory-augmented output.
5.2 Execution Path and Interaction Flow
When a user sends a message, MemReader parses the intent and formulates a MemoryQuery. The MemOperator retrieves matching MemCubes from MemVault, the MemScheduler injects relevant memory into the LLM context (as plaintext, activation bias, or parameter patch), and the model generates a memory-augmented response. The full interaction is logged to the Audit Log via MemGovernance.
6. Evaluation
We systematically evaluate MemOS capabilities through holistic and component-level experiments — benchmarking full system performance on long-context memory, personalization understanding, chunk size sensitivity, retrieval robustness, and KV-based acceleration.
6.1 End-to-End Evaluation on Long Context Memory
MemOS is benchmarked against MIRIX, Zep, MemBase, Mem0, and Supermemory on the LoCoMo and LongMemEval benchmarks. MemOS-1031 achieves the highest average score (75.80) — a 5% improvement over the previous best (MemBase: 72.01):
Method
Memory Size
LiftAge ↑
F1 ↑
ROUGE-L ↑
BLEU ↑
Avg ↑
LoCoMo ↑
No Memory
—
68.22
54.26
68.54
46.88
64.33
28.10
MIRIX
1,172
73.33
58.75
52.34
45.83
64.57
43.46
Zep
2,701
66.23
52.12
54.82
33.33
59.22
41.23
MemBase
2,102
73.12
64.65
81.20
53.12
72.01
50.18
Mem0
617
66.34
63.12
27.10
50.01
56.55
35.15
Supermemory
500
67.30
51.12
31.77
42.67
55.34
34.87
MemOS-1031
1,589
81.09
67.49
75.18
55.90
75.80
45.27
6.2 Evaluation on Personalization and Preference Understanding
MemOS is evaluated on the PrefEval and PersonaMem benchmarks to assess personalization quality. MemOS achieves the best Personalized Response performance in both zero-turn and 10-irrelevant-turn settings, while recording the lowest Preference Unaware Rate — indicating that MemOS consistently recalls and applies user preferences without being misled by irrelevant context.
For the PersonaMem benchmark, MemOS achieved the best precision while maintaining acceptable context length control, validating its superior capability in handling dynamic user preference evolution across extended interaction histories.
What is LiftAge? LiftAge measures how well a memory system can retrieve relevant past information across different temporal distances (how 'old' the memory is). A high LiftAge score means the system correctly recalls aging memories — not just recent ones. It's a key metric for long-horizon personalization. MemOS-1031 achieves 81.09 LiftAge vs. the no-memory baseline of 68.22, a significant improvement.
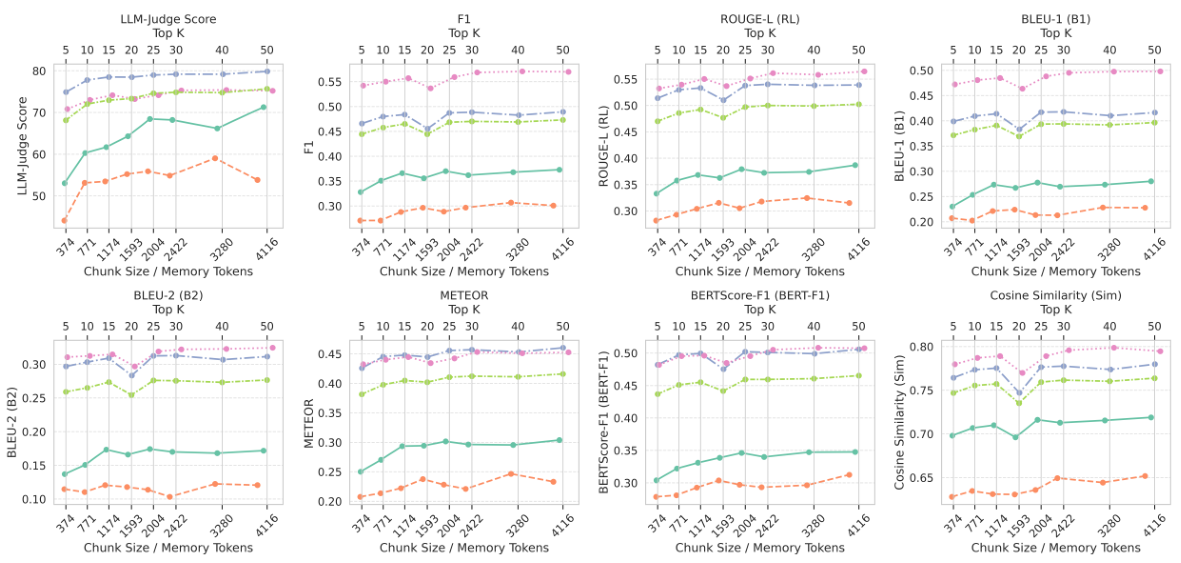
6.3 Chunk Size and Top-K Sensitivity
We analyze the impact of retrieved memory chunk count (Top-K) and chunk size on MemOS performance across multiple metrics. Performance stabilizes at Top-K=3 and chunk size ~512 tokens, providing the optimal tradeoff between context window usage and recall quality:
Figure 9: Performance trends of MemOS across memory configurations. Top-K=3 and chunk size ≈512 provides optimal performance across LiftAge, F1, ROUGE-L, BLEU, METEOR, BERTScore, and Tracing Similarity metrics.
6.4 Evaluation of Memory Retrieval Robustness
We conduct a focused evaluation analyzing the efficiency and robustness of memory retrieval via network API under varying query-per-second (QPS) pressure. Metrics include P99, P90, and mean latency for both memory insertion (add) and retrieval (search) operations, as well as success rate.
MemOS achieved 100% success rate across all QPS levels while maintaining the lowest latency — demonstrating robust production-grade memory retrieval performance even under high concurrency pressure.
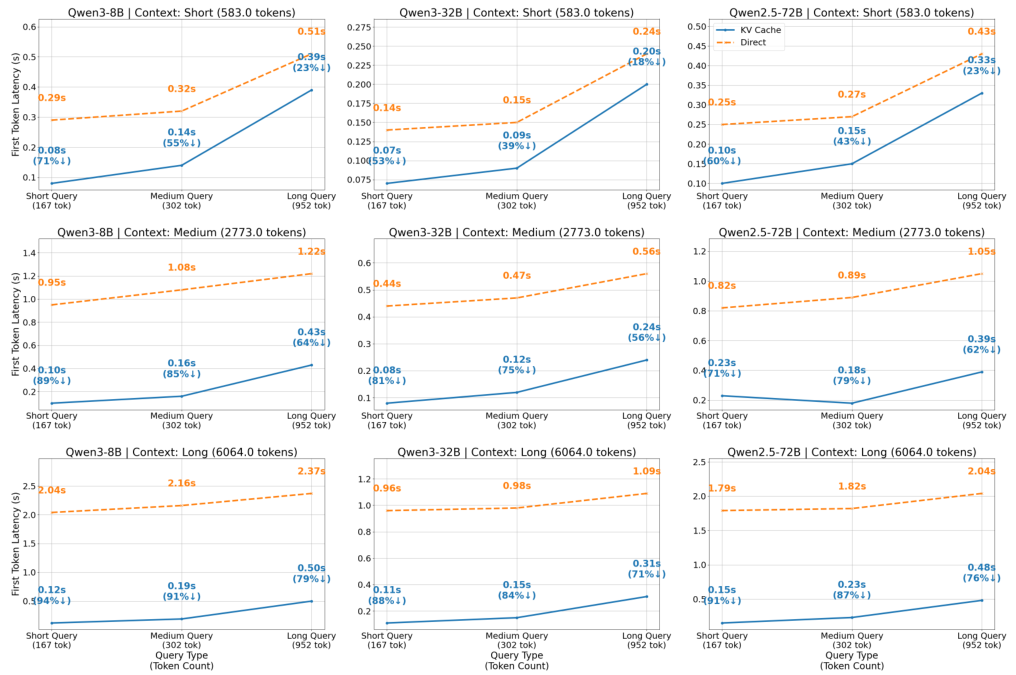
What is TTFT (Time to First Token)? TTFT measures how long it takes for a language model to generate the first token of its response. With long memory contexts (thousands of tokens), the attention computation grows quadratically — making TTFT very slow. KV-based memory injection bypasses this by pre-computing the attention key-value pairs for memory content and injecting them directly into the KV cache, skipping the quadratic attention cost at inference time.
6.5 KV-Based Memory Acceleration
KV-based memory injection pre-computes key-value cache from memory content, bypassing repeated attention computation at inference time. We compare Time to First Token (TTFT) across model sizes (3B, 7B, 72B), context lengths (short/medium/long), and query lengths against standard attention:
Figure 10: TTFT comparison across model sizes and context lengths. KV-based memory injection (green) significantly reduces TTFT vs. standard attention (blue), with the largest gains on long contexts and large models (72B).
7. Applications and Architecture Innovations
MemOS enables a new paradigm for AI applications where persistent memory is a modular, manageable resource. Key application scenarios:
7.1 Architectural Innovations Enabled by MemOS
MemOS treats memory as a first-class system resource, enabling unified lifecycle management and orchestration of memory in multiple forms. This abstraction supports two key architectural innovations:
💎
Paid Memory as Modular Installables
Domain experts can publish structured experiential memories via MemStore — like a knowledge plugin. Consumers (students, enterprise agents, assistant models) can subscribe, download, and activate these memory modules to immediately acquire domain-specific expertise without fine-tuning.
🔧
Painless Memory Management
Users and developers access memory through standardized task-level Memory API calls — without handling low-level vector indexing, KV-caching, or context orchestration. Memory is a universal, long-lived, shareable infrastructure resource, analogous to storage subsystems in traditional OS.
7.2 Application Scenarios
💬
Multi-Turn Dialogue & Cross-Task Continuity
MemOS maintains conversation history, user preferences, and task context across sessions and modalities — enabling seamless long-horizon interactions without context window limitations.
🔄
Knowledge Evolution & Continuous Update
Domain knowledge can be continuously updated via MemCube injection without full retraining. New information is integrated at the plaintext or activation level, then consolidated into parameter memory over time.
👤
Personalization & Multi-Role Modeling
User-specific preferences, communication styles, and role definitions are stored as MemCubes and injected at inference time — enabling genuine personalization across diverse user profiles.
🌐
Cross-Platform Memory Migration
MemCubes can be exported, imported, and transferred across model instances and platforms via MemStore — enabling a decentralized memory marketplace where users own their AI memory.
8. Conclusion
We introduce MemOS, a memory operating system designed for Large Language Models, aimed at collaboratively building foundational memory infrastructure for next-generation LLMs. MemOS provides a unified abstraction and integrated management framework for heterogeneous memory types — parameter memory, activation memory, and explicit plaintext memory.
The MemCube abstraction enables controllable, plastic, and evolvable memory management — laying the foundation for continual learning and personalized modeling at scale. MemOS achieves state-of-the-art performance across all evaluated benchmarks while significantly reducing Time to First Token via KV-based memory acceleration.
Looking ahead, we envision a future intelligent ecosystem centered on modular memory resources and supported by a decentralized memory marketplace. This paradigm shift — from stateless tools to memory-rich persistent agents — represents the next frontier in AI system design.
References (click to expand)
Li, Z. et al. (2025). Memory3: Language Modeling with Explicit Memory. arXiv:2407.01178
Vaswani, A. et al. (2017). Attention Is All You Need. NeurIPS 2017
Brown, T. et al. (2020). Language Models are Few-Shot Learners (GPT-3). NeurIPS 2020
Ouyang, L. et al. (2022). Training language models to follow instructions with human feedback (InstructGPT). NeurIPS 2022
Kwon, W. et al. (2023). Efficient Memory Management for Large Language Model Serving with PagedAttention (vLLM). SOSP 2023
Edge, D. et al. (2024). From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv:2404.16130
Hu, E. et al. (2022). LoRA: Low-Rank Adaptation of Large Language Models. ICLR 2022
Meng, K. et al. (2022). Locating and Editing Factual Associations in GPT (ROME). NeurIPS 2022
B2B Content
Any content, beautifully transformed for your organization
PDFs, videos, web pages — we turn any source material into production-quality content. Rich HTML · Custom slides · Animated video.