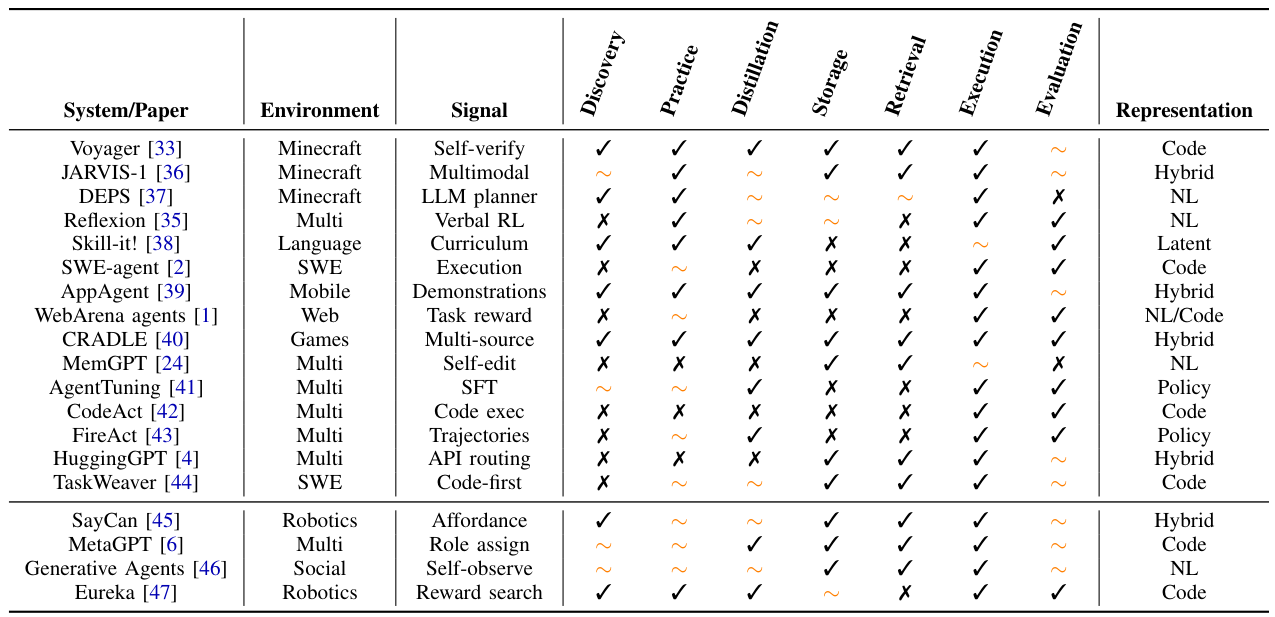
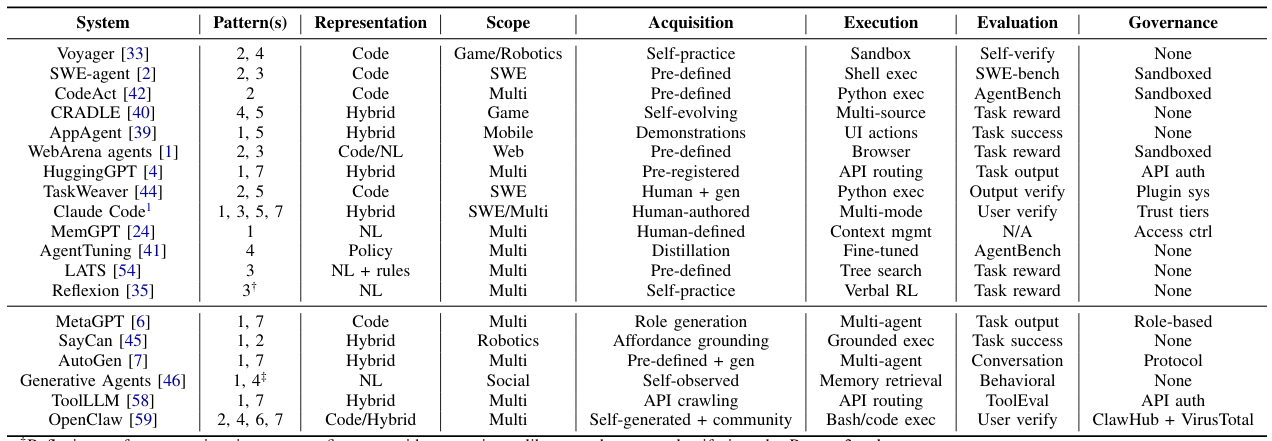
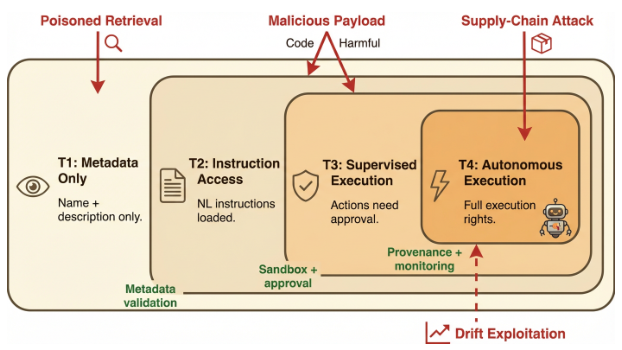
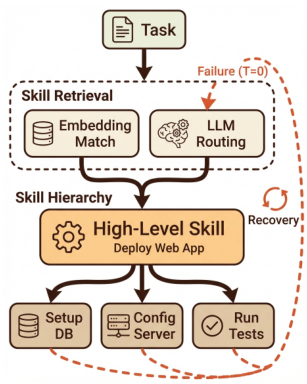
What Is an Agentic Skill?
A skill is more than a tool call or a prompt. It is a reusable, callable module that encapsulates a sequence of actions or policies enabling an agent to achieve a class of goals under recurring conditions — complete with its own applicability logic, execution policy, termination criteria, and callable interface.
2.1 Formal Definition
An agentic skill is formalized as a four-tuple that captures the essential properties distinguishing it from related abstractions. Let an agent interact with environment E via action space A, observation space O, and goal space G:
Definition 1 (Agentic Skills)
Each component plays a distinct role in making skills simultaneously executable, reusable, and governable — the three properties that no other existing abstraction fully provides.
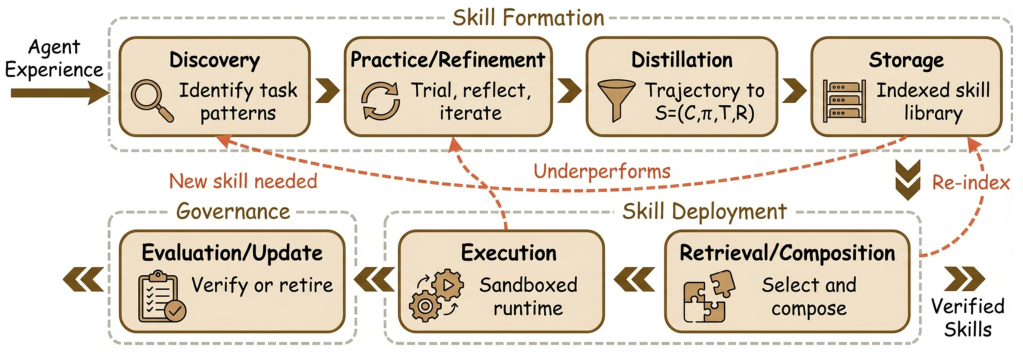
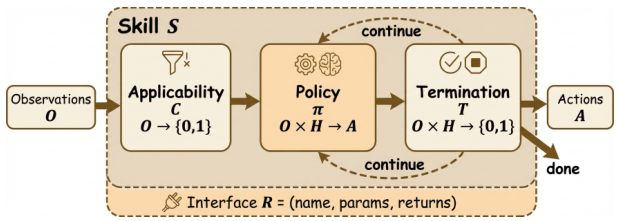
Breaking Down S = (C, π, T, R)
This four-tuple is the paper's core claim: a skill is not just a callable function — it's a contract. Think of it like a microservice with a service-level agreement:
- C (Condition) — When can this skill be invoked? e.g., "I can navigate websites, but not if the page requires authentication"
- π (Policy) — How does it execute? This is the actual behavior — code, NL instructions, or a learned policy
- T (Termination) — When does it stop? Success, failure, or timeout conditions — not just "run until done"
- R (Interface) — What do other skills or the agent see? Inputs, outputs, side effects — the API boundary
Without T and C, a "skill" is just a function call. The contract is what makes it composable and safe to reuse across contexts.
Applicability Condition
Maps observations and goals to {0,1}: determines whether this skill is appropriate for the current context. Acts as a gating function — skills only activate when their conditions are met. Think of it as the skill's 'when to use me' knowledge.
Executable Policy
Maps observations and history to actions: the core logic of the skill. Can be a prompt template, Python function, RL policy, or hybrid. When π selects another skill from library Σ instead of a primitive action, hierarchical composition arises.
Termination Condition
Specifies when the skill has completed — successfully or not — relative to the current goal. This is what enables composability: callers know exactly when control returns to them. Without T, skills cannot be safely chained.
Callable Interface
Defines the skill's programmatic boundary: name, parameter schema, and return type. Enables the agent, other skills, and external orchestrators to invoke the skill reliably. Without R, internal knowledge cannot be used programmatically.
2.2 Skills vs. Related Abstractions
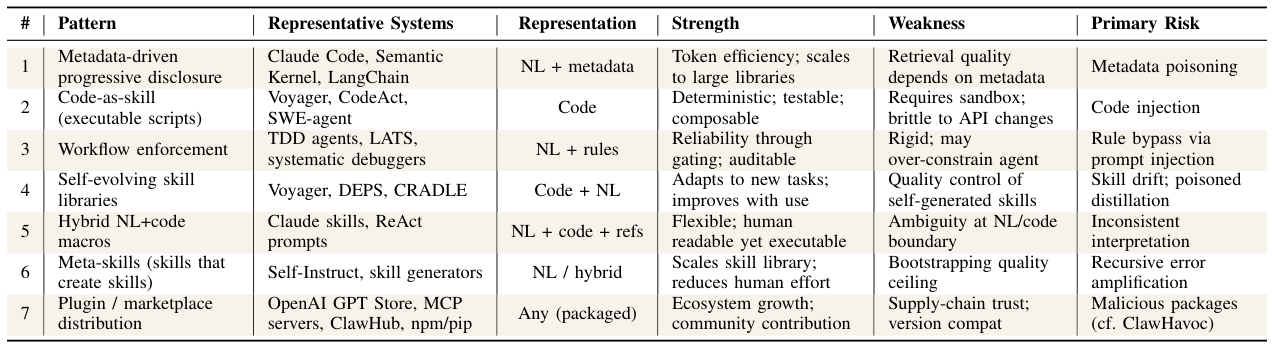
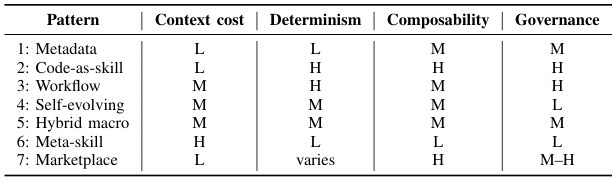
Agentic skills occupy a distinct position in the design space — they are not just tools, plans, or memories. The table below compares them across five key dimensions:
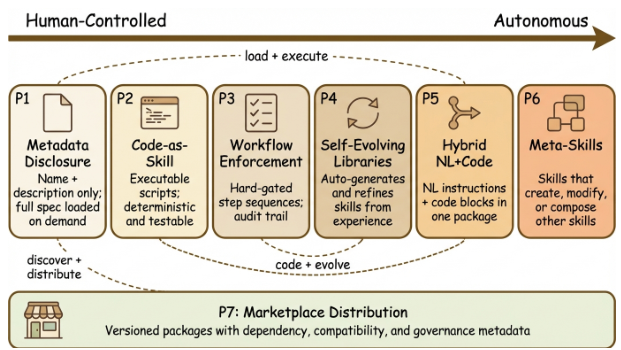
The key distinction: a tool answers "what can I call?" — a skill answers "what do I know how to do, and when?" Tools are atomic API endpoints. Skills are reusable workflows that include the judgment about when and how to use those tools. A skill can call multiple tools, maintain state, handle failures, and return structured results — all defined in advance and reusable across different tasks.

vs. Tools
A tool is an atomic primitive (e.g., a web-search API) with a fixed interface and no internal decision-making. A skill may invoke tools, but extends them with applicability logic, multi-step sequencing, and explicit termination criteria. The distinction is like a system call vs. a library routine.
vs. Plans
A plan is a one-time reasoning artifact that decomposes a task into sub-goals. Plans are session-scoped and not directly executable without further interpretation. Skills persist across sessions, carry executable policies, and expose callable interfaces.
vs. Memory
Episodic and semantic memory stores observations and facts. Skills are procedural memory: they encode how to act, not what happened. This mirrors the cognitive psychology distinction between knowing-that (declarative) and knowing-how (procedural).
vs. Prompt Templates
Prompt templates are text fragments injected into the context window with no applicability conditions or termination logic. They cannot self-select, compose hierarchically, or be governed independently. Skills subsume and formalize the best patterns from prompt engineering.