Why agents keep reinventing the wheel
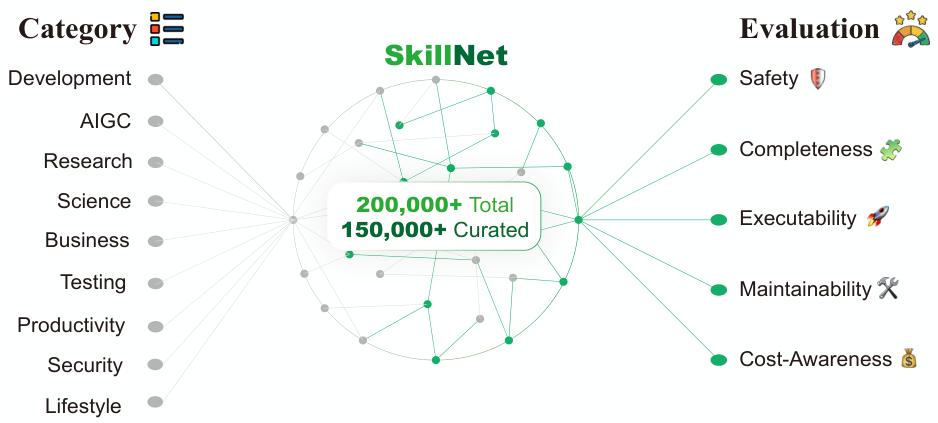
Today's AI agents can fluently invoke tools and complete complex tasks, yet their long-term growth is limited by the absence of a unified way to accumulate and transfer the capabilities they discover. Without a mechanism for skill consolidation, agents constantly rediscover the same solutions in isolation. SkillNet is an open infrastructure for creating, evaluating, and organizing AI skills at scale. It introduces a three-layer Skill Ontology — a taxonomy, a relation graph, and a package library — and transforms fragmented experience from execution trajectories, open-source repositories, and documents into a structured network of more than 200,000 candidate skills, curated down to 150,000+ high-quality entries. Every skill is scored along five dimensions: Safety, Completeness, Executability, Maintainability, and Cost-Awareness. On three benchmarks — ALFWorld, WebShop, and ScienceWorld — agents augmented with SkillNet improve average reward by +40% and cut interaction steps by −30% across DeepSeek V3.2, Gemini 2.5 Pro, and o4 Mini.
Why Skills, Why Now
Richard Sutton has argued that we are now in the era of experience. Intelligence is grounded less in static knowledge acquisition and more in the efficient retrieval and adaptive reuse of heuristics distilled from prior runs. That shift marks the arrival of the agent era, where AI moves beyond static question answering to orchestrate long-horizon, executable tasks.
But current systems lean on manual engineering or transient in-context learning. Humans routinely consolidate episodic experience into reusable schemas — a programmer internalizes an algorithm's logic rather than memorizing its syntax — yet contemporary AI struggles to bridge the gap between fleeting context and durable capability. The central challenge is no longer learning from experience, but turning fragmented experience into composable skill units.
The Symbolic Era
Rigid symbolic logic was interpretable but brittle and did not scale.
The Deep Learning Era
Knowledge became parametric and powerful, but opaque and hard to modularize or reuse.
The Agentic Era
Skills emerge as simple, transferable capability units that separate intelligence from monolithic parameter spaces.
A unified skill framework
SkillNet turns fragmented agent experience into a structured network of modular, composable skills with rich relational modeling, giving teams a scalable foundation for actionable knowledge engineering.
A rigorous 5-axis evaluation protocol
Every skill is quantitatively measured along Safety, Completeness, Executability, Maintainability, and Cost-Awareness — ensuring the repository remains reliable as it scales.
An open ecosystem
A 200k+ candidate / 150k+ curated skill repository, a Python toolkit (
skillnet-ai), and benchmarks that demonstrate significant gains in agent planning and execution.
What Is an Agent Skill?
A skill is a lightweight, modular, reusable abstraction for extending an agent's capabilities. Functionally, a skill is a structured folder containing a central SKILL.md file that defines metadata — name, a short description, and usage conditions — alongside step-by-step instructions, and optionally bundled code, templates, or reference assets.
Skills give agents on-demand access to reusable procedural knowledge: automating a data analysis pipeline, performing domain reasoning, or generating structured reports. The self-documenting nature of skills makes each capability easy to audit and iterate on — they become the interface through which business logic gets institutionalized.
Think of a skill as a Claude Code "skill folder"
If you use Claude Code or similar frameworks, an "agent skill" looks exactly like the skill folders you already know: a directory with a SKILL.md that tells the agent when to activate ("use this for Postgres migrations"), and how to run ("1. dump schema 2. diff 3. run migration"). The agent only loads the full instructions when the task matches. That's why this paper treats skills as modular units — they're literally copy-pasteable between projects.
Discovery
The agent loads minimal metadata — name and description — to decide which skills are potentially relevant for the task at hand.
Activation
When a task matches a skill's description, the agent reads the full SKILL.md instructions and prepares any bundled resources.
Execution
The agent follows the instructions step-by-step, optionally invoking bundled code or consuming referenced assets to complete the task.
SkillNet Overview
SkillNet systematically creates, evaluates, and organizes high-quality skills for agent systems. Its goal is to transform fragmented agent experience and human knowledge into reusable and verifiable skill entities, enabling scalable and reliable capability growth.
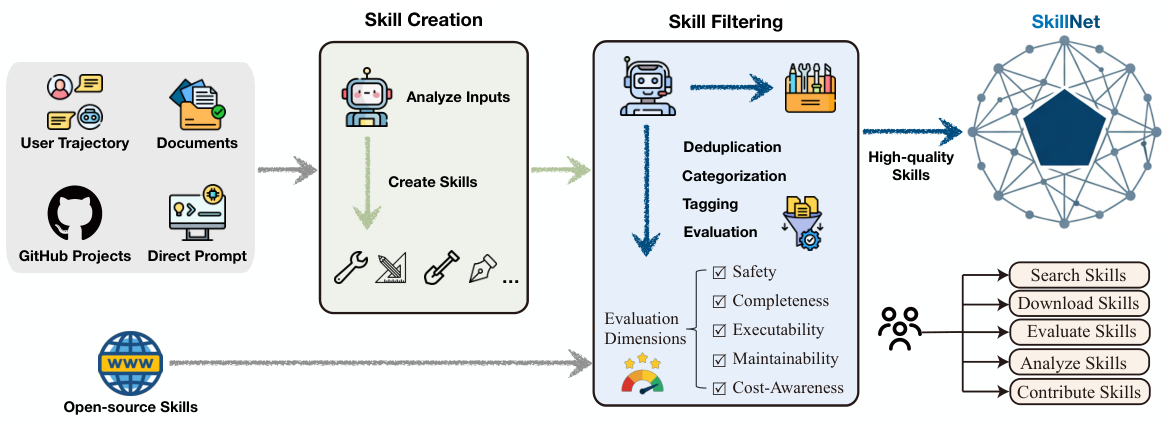
Skill Creation
Analyzes diverse inputs — user trajectories, office documents, GitHub projects, direct prompts, and open internet resources — and generates new skills by extracting executable patterns and structuring them as reusable capabilities.
Skill Evaluation
Filters and grades candidate skills along five dimensions — Safety, Completeness, Executability, Maintainability, and Cost-Awareness — ensuring only high-quality skills enter the repository.
Skill Analysis
Automatically mines structural and functional relationships among skills, building a large-scale typed graph that captures similarity, hierarchy, composition, and dependency for global reasoning and composition.
Open Resources
A curated repository, a front-end website, an open API, and the skillnet-ai Python toolkit — one ecosystem for skill management, search, evaluation, and contribution.
The Skill Ontology
The Skill Ontology organizes individual skills into a structured, composable network. The architecture stacks three progressive layers: a taxonomy, a relation graph, and a package library. Taken together, they transform a flat bag of skills into a navigable knowledge structure.
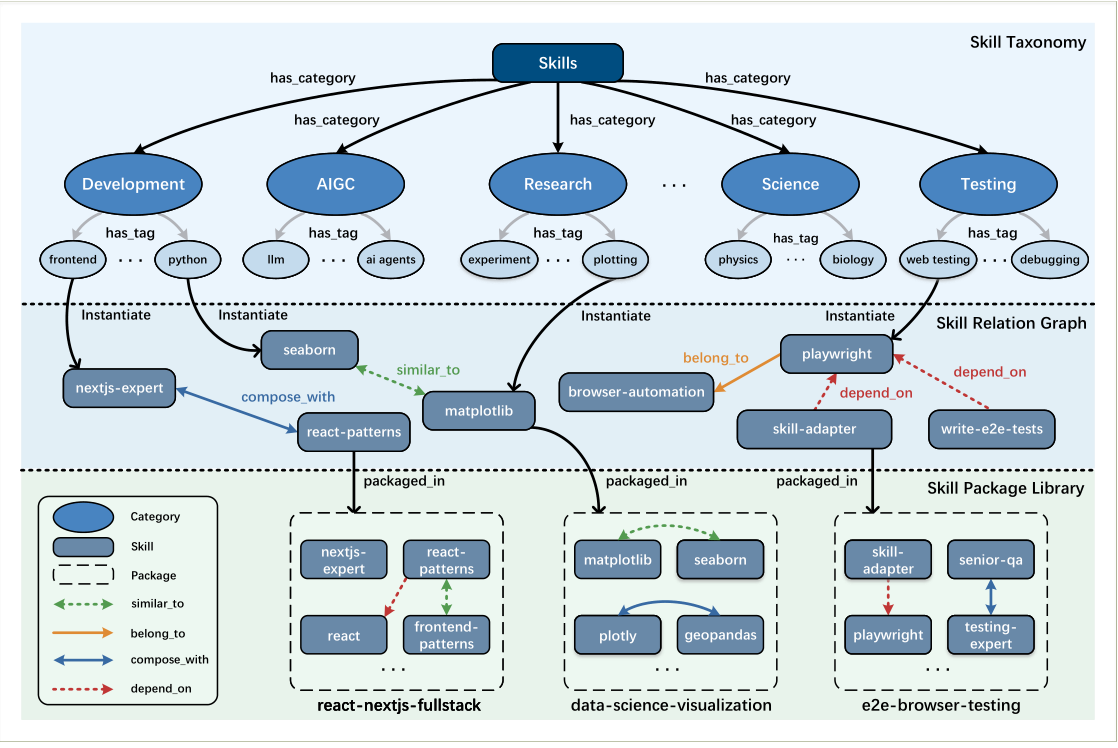
similar_to, belong_to, compose_with, depend_on). The Skill Package Library bundles skills into modular packages such as data-science-visualization or e2e-browser-testing.Skill Taxonomy
A multi-level hierarchy built from category and tag relations. Broad domains (Development, AIGC, Research, Science, Testing, …) are refined into fine-grained tags (frontend, llm, physics), providing a high-level semantic skeleton.
Skill Relation Graph
Instantiates abstract tags into concrete Skill Entities (e.g. matplotlib, playwright) and connects them with typed edges: similar_to, compose_with, belong_to, depend_on. This is the backbone for reasoning and planning.
Why four relation edges matter
A flat list of 150,000 skills is unsearchable. The relation graph is what turns the repository into something an agent can reason over:
similar_tolets the agent swap one skill for another when the first fails (redundancy).compose_withtells the agent which skills feed each other (automatic pipelines).depend_onprevents broken runs by surfacing prerequisites.belong_toenables zoom-out planning by grouping atomic skills into larger workflows.
Concretely: if an agent wants to "build a Next.js landing page", it can discover react-patterns via belong_to nextjs-expert, verify it depend_on react, and swap it out for frontend-patterns if needed.
Skill Package Library
Physical organization of skills. Individual skills are encapsulated into Skill Packages via the packaged_in relation (e.g. react-nextjs-fullstack, data-science-visualization), enabling modular release and deployment.
How New Skills Enter the Network
SkillNet treats skills as intermediate capability units that bridge declarative knowledge and concrete, executable programs. An automated creation pipeline turns four kinds of input into standardized skills: execution trajectories and conversational logs, open-source GitHub repositories, semi-structured documents (PDF, PowerPoint, Word), and direct natural-language prompts from users.
Automatic construction does not mean indiscriminate accumulation. A data-driven filtering and consolidation pipeline deduplicates, validates, classifies, scores, and finally selects each candidate, so the repository grows as a self-evolving skill ecosystem rather than a static collection.
- Deduplication — jointly compare directory structure and MD5 hashes of skill Markdown files.
- Filtering — rule-based validation plus model-based checking to eliminate low-quality or semantically empty skills.
- Categorization & Tagging — classify each skill into one of 10 functional categories and attach fine-grained tags.
- Evaluation — grade along Safety, Completeness, Executability, Maintainability, Cost-Awareness.
- Selective Consolidation — keep only skills that survive all previous stages.
A self-evolving skill ecosystem, not a static collection.
Multi-Dimensional Skill Evaluation
Although skill creation matters, the usefulness of a repository ultimately depends on its reliability. SkillNet bridges the gap left by existing repositories — which rarely have standardized assessment — with a five-axis rubric plus sandboxed execution checks for runtime correctness.
Safety
Hazardous system operations (e.g. unauthorized file deletion) and robustness against prompt injection or adversarial manipulation.
Completeness
Whether all critical procedural steps are captured and prerequisites, dependencies, and execution constraints are explicit.
Executability
Agents can actually run the skill in a sandboxed environment, with hallucinated tool calls and ambiguous instructions flagged.
Maintainability
Modularity and composability: can the skill be updated locally without breaking global dependencies or backward compatibility?
Cost-Awareness
Time latency, compute, and API cost awareness, to support efficiency optimization in production.
The 5 axes, translated for practitioners
Think of a skill as a library your team ships: these five axes mirror the same quality gates you already use in code review.
- Safety ≈ "does it have dangerous side effects?" (like a migration that drops tables without a prompt)
- Completeness ≈ "does the README actually explain every step?" (prerequisites + edge cases)
- Executability ≈ "does it run green on CI?" (actual sandbox execution, not just LLM opinion)
- Maintainability ≈ "can I fork it without breaking downstream?" (modularity)
- Cost-Awareness ≈ "what's the p99 latency and the API bill?" (production operability)
That analogy is why the next figure matters: the automated evaluator agrees with PhD human reviewers on every axis — it's essentially an automated code reviewer for agent skills.
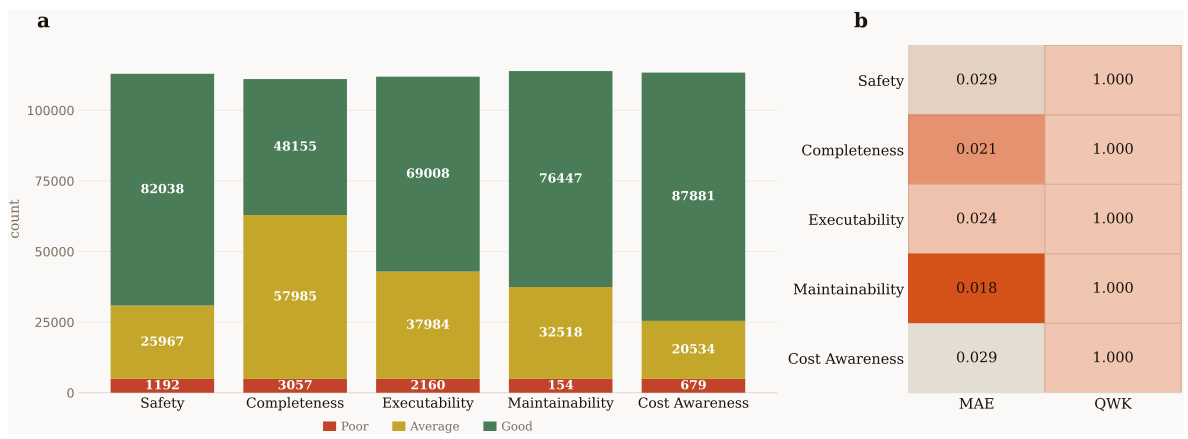
Across 200 randomly sampled skills reviewed blind by three PhD-level computer science annotators, the LLM-based evaluator achieved Mean Absolute Error under 0.03 and near-perfect Quadratic Weighted Kappa (1.000) on every dimension — strong evidence that SkillNet's automated quality gate is trustworthy at scale.
Mining the Skill Relation Graph
Beyond isolated skill creation and evaluation, large-scale repositories introduce a new challenge: systematically understanding, organizing, and exploiting relations between skills. SkillNet formulates skill analysis as a structured relation discovery problem and automatically annotates four core relation types between skills.
similar_to
Functionally equivalent skills — enables redundancy detection and substitution.
belong_to
One skill is a sub-component of a larger workflow, capturing hierarchy.
compose_with
Two skills are frequently co-invoked; one consumes the other's output.
depend_on
A skill cannot execute without a prerequisite (e.g. environment setup).
How the graph is actually built (without manual labeling)
Hand-labeling relations between 150,000 skills is impossible. SkillNet's trick is a three-stage pipeline: (1) embedding similarity proposes candidate similar_to edges; (2) static analysis of code and execution traces proposes depend_on and compose_with edges; (3) an LLM reasoner reviews the candidates and labels the edge type. This is the same recipe modern knowledge-graph construction uses, applied to executable code instead of Wikipedia text.
SkillNet builds these relations through a hybrid pipeline: semantic embedding similarity, dependency extraction, and execution-trace alignment generate candidate edges, then LLM reasoning refines them into a directed, typed, multi-relational graph. The result is a living skill graph that supports global reasoning, workflow composition, and task-oriented skill collection releases.
Repository, API, and Python Toolkit
SkillNet ships as a full open infrastructure: a large-scale curated skill repository, a front-end website at skillnet.openkg.cn, an open access API with both keyword and vector search, and a versatile Python library plus CLI tool skillnet-ai.
Through this ecosystem, users can browse skills by category, view API documentation, contribute new skills, search and download skills directly into local workspaces, create structured skills from trajectories or codebases, evaluate across the five quality dimensions, and analyze relations between skills at scale.

skillnet-ai. The package offers a unified functional experience through both a command-line interface (left) for interactive usage and a Python library (right) for seamless integration into AI development pipelines.Benchmarks: +40% Reward, −30% Steps
SkillNet is evaluated on three text-based simulated environments. ALFWorld is an embodied household benchmark where agents navigate and manipulate objects for daily tasks. WebShop simulates realistic online shopping with product search, comparison, and constrained purchasing. ScienceWorld presents a virtual scientific laboratory in which agents perform experiments and reason about results.
Baselines are ReAct, ExpeL, and a standard Few-Shot approach. The SkillNet variant is augmented with task-specific skill collections; during evaluation agents dynamically select, activate, and execute the most relevant skills. Backbones: DeepSeek V3.2, Gemini 2.5 Pro, and o4 Mini. Seen and unseen test splits have no overlap, preventing data leakage.
ReAct and ExpeL — the baselines to beat
ReAct interleaves Reasoning (think step) and Acting (tool call) in a loop — the most widely used baseline for LLM agents. ExpeL (Experiential Learner) adds a memory of past successful trajectories and retrieves them as few-shot examples at inference time. Both treat experience as in-context prompting. SkillNet goes further: it turns experience into named, versioned, evaluated capability units that any agent can install. That's why the gains hold across three different backbone models — the improvement isn't coming from better prompting, it's coming from giving the agent executable tools that survive between tasks.
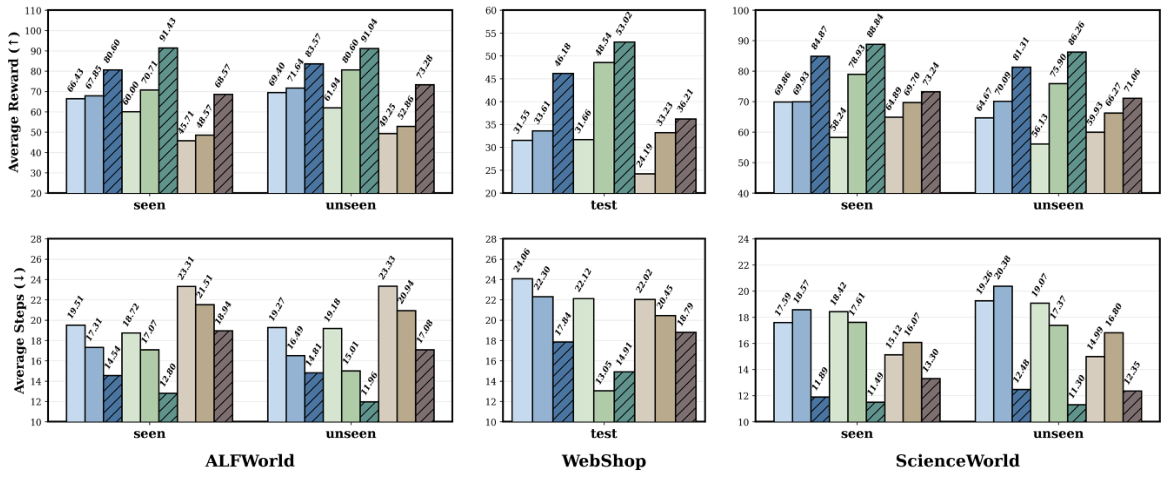
| Model | Method | ALFWorld Seen | ALFWorld Unseen | WebShop | ScienceWorld Seen | ScienceWorld Unseen | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R↑ | S↓ | R↑ | S↓ | R↑ | S↓ | R↑ | S↓ | R↑ | S↓ | ||
| DeepSeek V3.2 | ReAct | 66.43 | 19.51 | 69.40 | 19.27 | 31.55 | 24.06 | 69.86 | 17.59 | 64.67 | 19.26 |
| ExpeL | 67.86 | 18.86 | 76.12 | 17.41 | 29.23 | 24.00 | 74.91 | 15.98 | 74.09 | 17.53 | |
| + SkillNet | 80.60 | 14.54 | 83.57 | 14.81 | 46.18 | 17.84 | 84.87 | 11.89 | 81.31 | 12.48 | |
| Gemini 2.5 Pro | ReAct | 60.00 | 18.72 | 61.94 | 19.18 | 31.66 | 22.12 | 58.24 | 18.42 | 56.13 | 19.07 |
| ExpeL | 68.57 | 17.88 | 70.15 | 17.04 | 33.12 | 19.31 | 72.76 | 15.01 | 67.37 | 14.91 | |
| + SkillNet | 91.43 | 12.80 | 91.04 | 11.96 | 53.02 | 14.91 | 88.84 | 11.49 | 86.26 | 11.30 | |
| o4 Mini | ReAct | 45.71 | 23.31 | 49.25 | 23.33 | 24.19 | 22.02 | 64.89 | 15.12 | 59.93 | 14.99 |
| ExpeL | 56.43 | 21.35 | 58.96 | 21.85 | 26.71 | 21.91 | 67.95 | 13.65 | 65.68 | 13.95 | |
| + SkillNet | 68.57 | 18.94 | 73.28 | 17.08 | 36.21 | 18.79 | 73.24 | 13.30 | 71.06 | 12.35 | |
R denotes average reward (↑ higher is better); S denotes average steps (↓ lower is better). Best +SkillNet numbers are highlighted in bold. Results are reproduced from the paper.
Read rows as: Model × Method. R↑ is the benchmark reward (higher is better) and S↓ is the number of steps to completion (lower is better). The + SkillNet row in each model block is the headline result — compare it against its ReAct row to see the raw lift.
Integrating SkillNet improves average reward by 40% and reduces interaction steps by 30% relative to ReAct. Gains scale with backbone size: +15.7 R for o4 Mini, +28.5 R for Gemini 2.5 Pro. Improvements hold under both seen and unseen splits, evidence that SkillNet adds capability on top of parametric knowledge rather than memorization.
Autonomous Science & Coding Agents
SkillNet bridges high-level user intentions and executable agent actions by organizing specialized skills into coherent, evaluable workflows. The three scenarios below illustrate its utility in scientific discovery, coding, and integration with a general-purpose personal agent.
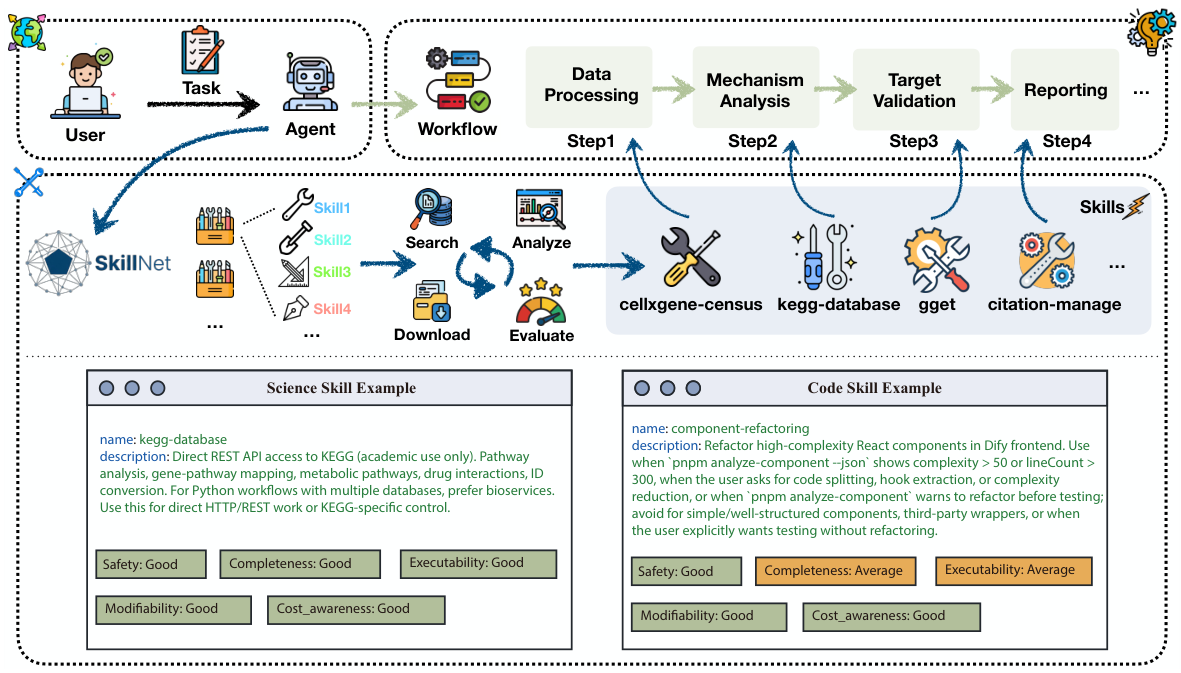
cellxgene-census, kegg-database, gget, and citation-manage. The bottom shows representative skill cards for Science and Coding scenarios with multi-dimensional evaluations.Autonomous Scientific Discovery
SkillNet chains data processing, mechanism analysis, target validation, and report generation skills. It can, for example, take raw single-cell RNA-seq data, cluster it, map key genes onto biological pathways, cross-validate their clinical significance, and synthesize the results into a citation-grade scientific report.
Autonomous Coding Agent
For large-scale software engineering tasks, SkillNet schedules code analysis skills to build a structured view of the system, decomposes requirements, assesses regression risks, and runs a closed-loop implementation → testing → validation pipeline backed by real-time observability.
OpenClaw Integration
OpenClaw, a customizable open-source personal agent framework, loads SkillNet as a skill. With lazy-loading metadata, it performs pre-task search against the repository, installs matched skills on demand, and periodically analyzes the local workspace — turning a general-purpose agent into a continuously self-improving system.
Why OpenClaw integration is the real test
Benchmarks like ALFWorld live in controlled sandboxes. The OpenClaw scenario is different: a real, production, installable personal agent. When SkillNet works here — with lazy skill loading, pre-task search against a 150k repository, on-demand install from GitHub URLs, and periodic self-analysis — it stops being a paper and becomes an ecosystem: community skills feed tasks, successful tasks get consolidated into new skills, and the agent improves for everyone who shares the same SkillNet. That flywheel is why the authors call it the "primary unit of knowledge integration".
Skills as the Bridge Between Memory and Workflows
SkillNet is grounded in a unified view of three complementary constraints on an agent's generative capability. Workflows impose explicit procedural structure — reliable but rigid. Memory accumulates contextual experience — adaptive but unbounded. Skills bridge these extremes by packaging reusable capability units that both constrain generation and organize memory into actionable patterns.
Looking ahead, the emerging "one-person lab" envisions a single expert orchestrating a society of agents. SkillNet makes skills the primary unit of knowledge integration and delegation: individuals curate skill repositories, agents compose them into workflows, and memory continuously refines them through experience — transforming isolated automation into cumulative machine expertise.
Open-World Skill Evolution
Automatic skill discovery, abstraction, and cross-domain transfer remain challenging in open-world settings. Industry-specific, privately curated SkillNets may themselves become foundational components of future agent infrastructure.
Model-Skill Synergy
How to leverage neuro-symbolic integration and memory mechanisms so that skill structures guide model decision paths — and how skill hierarchies should restructure as model capabilities evolve — is still an open question.
Multi-Agent Collaboration
In multi-agent environments, SkillNet can serve as a shared representation and exchange layer, supporting collaborative planning, knowledge transfer, and cumulative cross-agent experience.
Digital Avatars & Cumulative Expertise
Continuously consolidating agent behaviors into reusable skills opens a path toward digital avatars whose capabilities are progressively distilled from accumulated skills.
Limitations
Two honest caveats. First, skill coverage is inevitably incomplete: many private or highly specialized capabilities cannot be captured, and low-frequency tacit abilities resist explicit linguistic description. Second, the quality of self-constructed skills cannot be fully guaranteed — the evaluation pipeline filters obvious problems but subtle errors may remain.
References (showing a curated subset)
- Richard S. Sutton. The Era of Experience. 2024.
- OpenAI. GPT-4 Technical Report. 2023.
- Noah Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS 2023.
- Andrew Zhao et al. ExpeL: LLM Agents Are Experiential Learners. AAAI 2024.
- Shunyu Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023.
- Shunyu Yao et al. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. NeurIPS 2022.
- Mohit Shridhar et al. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. ICLR 2021.
- Ruoyao Wang et al. ScienceWorld: Is your Agent Smarter than a 5th Grader? EMNLP 2022.
- Guanzhi Wang et al. Voyager: An Open-Ended Embodied Agent with Large Language Models. 2023.
- Anthropic. Introducing Claude Code. 2024.
- Tao Yu et al. Towards Unified Skill Hubs for Autonomous Agents. 2025.
- DeepSeek-AI. DeepSeek V3.2 Technical Report. 2025.
- Google. Gemini 2.5 Pro Report. 2025.
- OpenAI. o4 Mini Model Card. 2025.
The full reference list (50+ entries) is available in the arXiv PDF. The items above are a curated subset of the most directly cited works.