arXiv: 2604.02176 · cs.CL · April 2026
LLM · NLP · Frequency Law
Adam's Law
Textual Frequency Law on Large Language Models
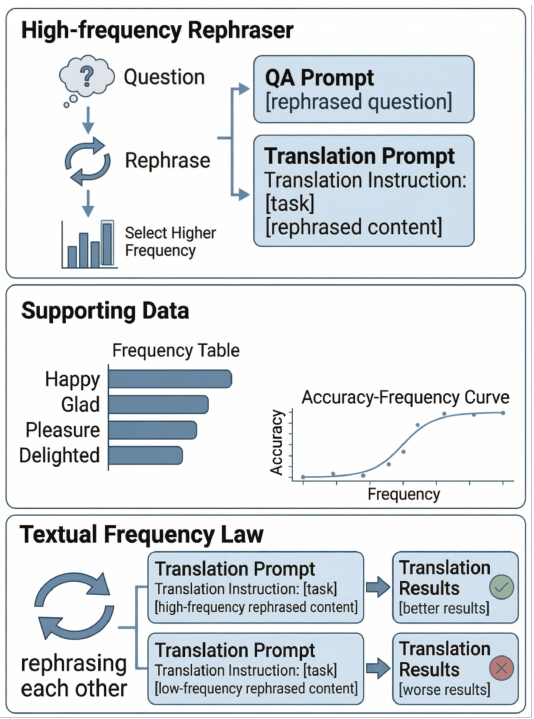
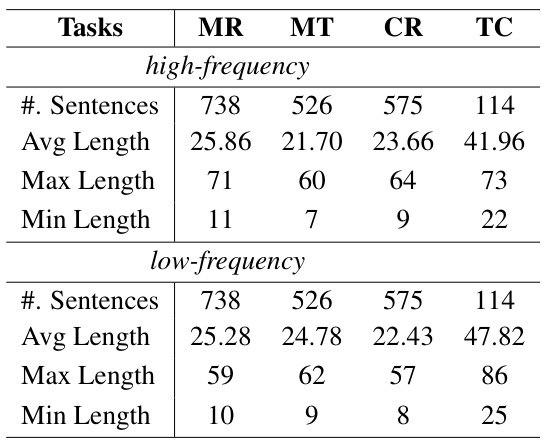
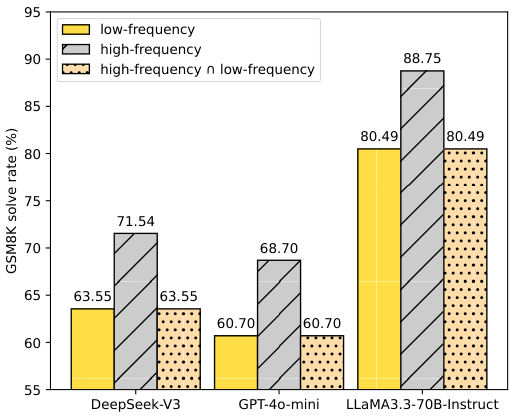
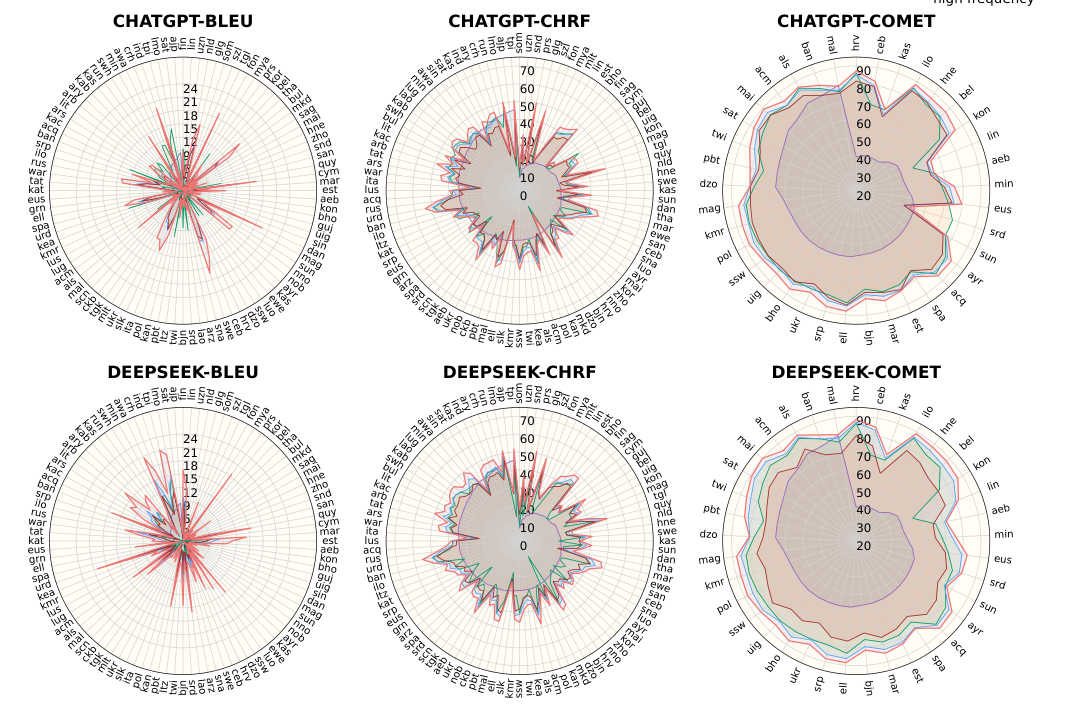
When two sentences have the same meaning, LLMs consistently perform better with the more common phrasing. This paper formalizes this as the Textual Frequency Law and validates it across math reasoning, machine translation, commonsense reasoning, and tool calling.
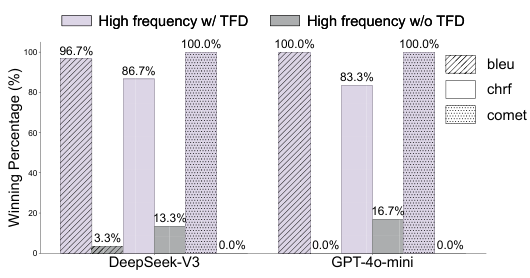
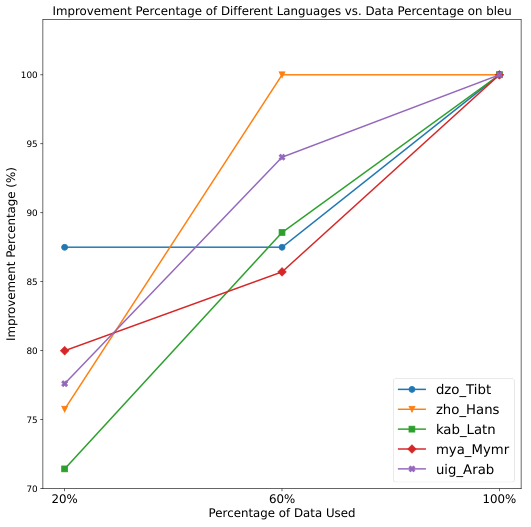
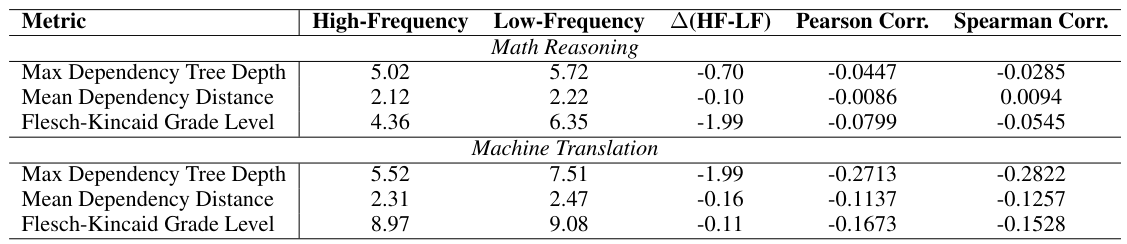
+8–12% accuracy gain with high-frequency prompting