Abstract
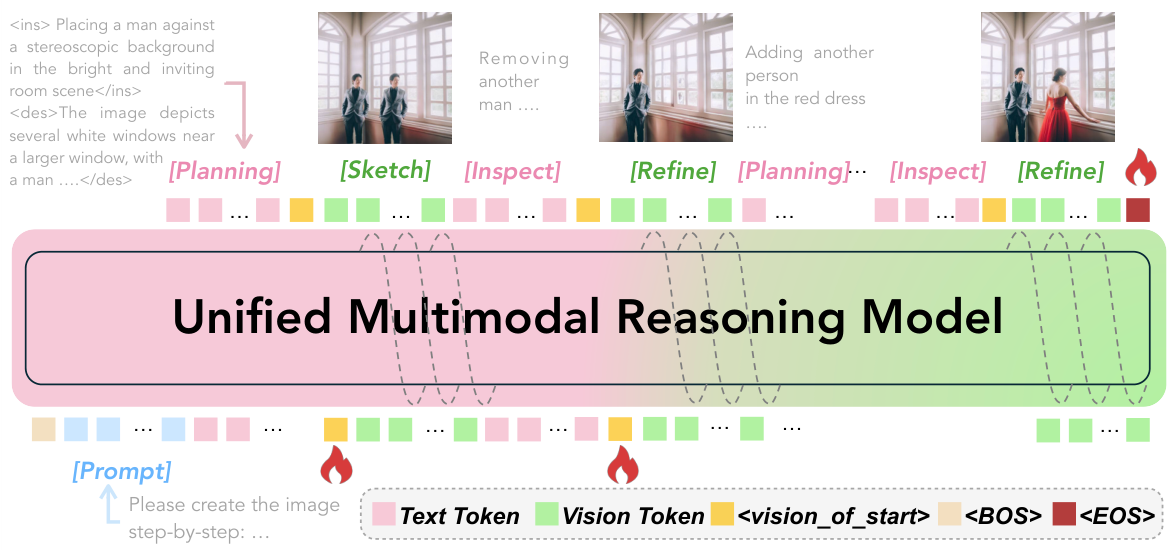
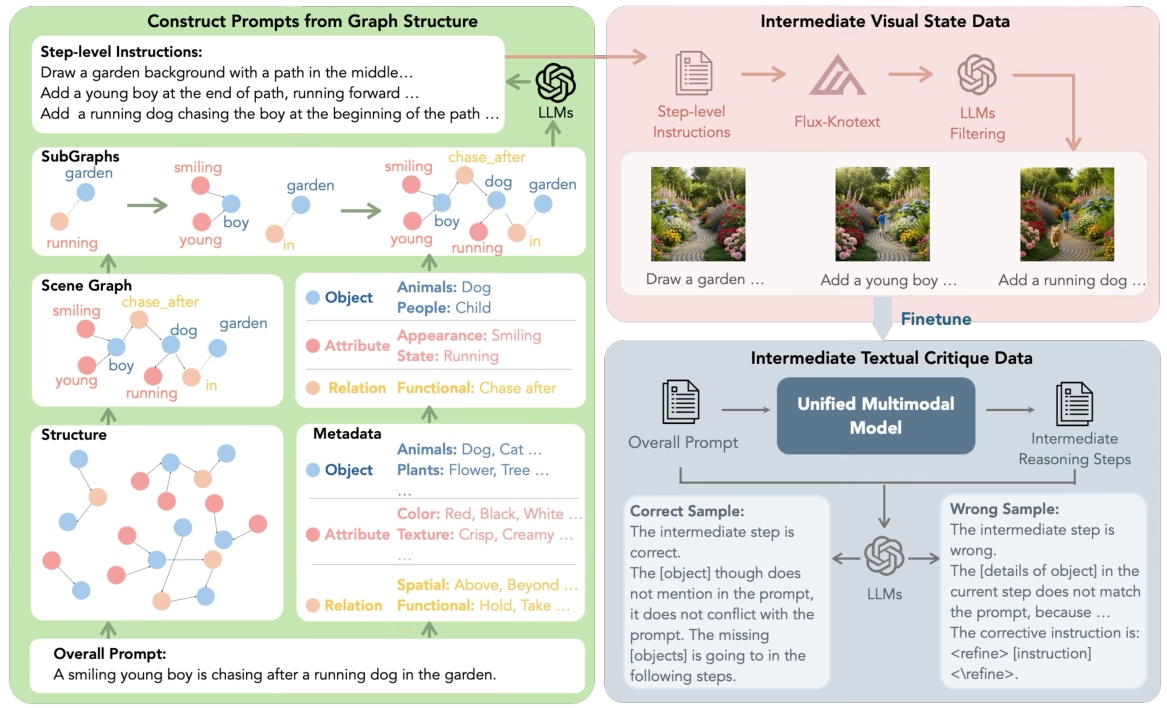
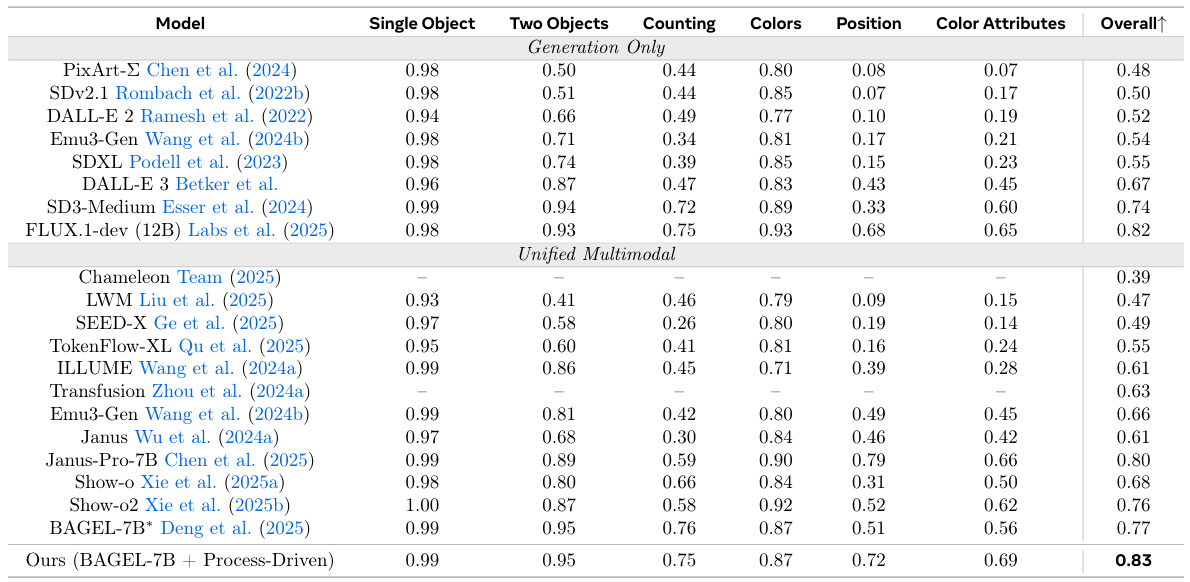
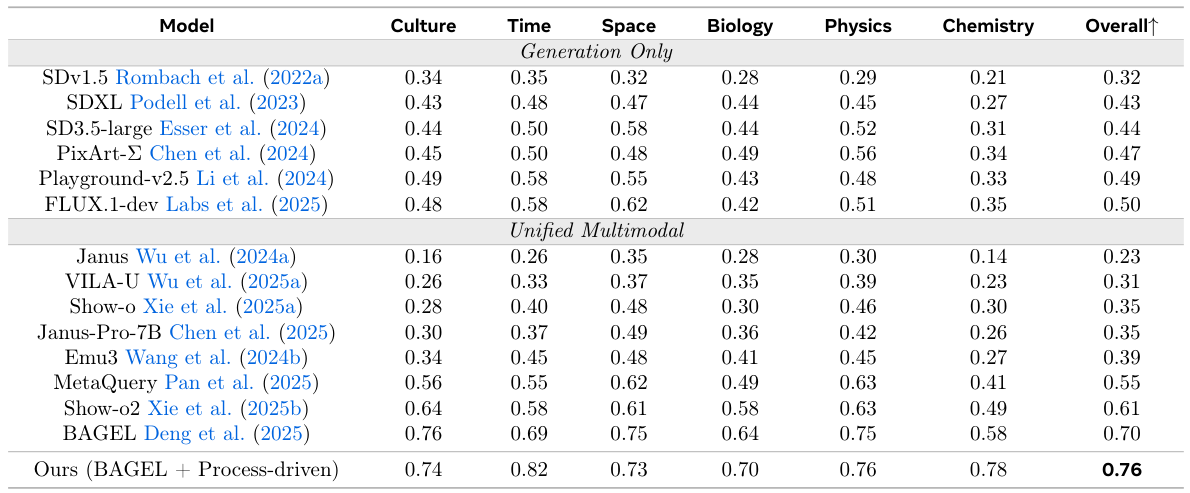
Humans paint images incrementally: they plan a global layout, sketch a coarse draft, inspect, and refine details, and most importantly, each step is grounded in the evolving visual states. In this paper, we introduce process-driven image generation, a multi-step paradigm that decomposes synthesis into an interleaved reasoning trajectory of thoughts and actions. Rather than generating images in a single step, our approach unfolds across multiple iterations, each consisting of 4 stages: textual planning, visual drafting, textual reflection, and visual refinement. The textual reasoning explicitly conditions how the visual state should evolve, while the generated visual intermediate in turn constrains and grounds the next round of textual reasoning. A core challenge of process-driven generation stems from the ambiguity of intermediate states: how can models evaluate each partially-complete image? We address this through dense, step-wise supervision that maintains two complementary constraints: for the visual intermediate states, we enforce the spatial and semantic consistency; for the textual intermediate states, we preserve the prior visual knowledge while enabling the model to identify and correct prompt-violating elements. This makes the generation process explicit, interpretable, and directly supervisable. To validate our method, we conduct experiments under various text-to-image generation benchmarks.
What is 'Interleaved Reasoning'?
In standard image generation, the model receives a text prompt and outputs the final image in one step — like writing an essay without drafting or revising. Interleaved reasoning means alternating between text thoughts and image outputs: the model plans in text, produces a partial image, looks at it, thinks again, and refines. This is analogous to a human artist sketching, stepping back, and making corrections — except here both the planning and the painting are done by the same AI model.