Yuqi Zhou, Sunhao Dai, Changle Qu, Liang Pang, Jun Xu, Ji-Rong Wen — Renmin University of China & Chinese Academy of Sciences
Published: March 30, 2026
Retrieval systems have been designed for humans, but LLM-powered search agents are changing the game. This paper introduces LRAT, a framework that trains retrieval models directly from agent interaction trajectories rather than human click logs, achieving consistent improvements across diverse agent architectures.
For decades, information retrieval (IR) systems have been designed and trained for human users. The dominant learning-to-rank methods rely on large-scale human interaction logs—clicks, dwell time, scrolling patterns—to understand what makes a search result relevant. This human-centric paradigm has powered everything from web search engines to recommendation systems.
But a fundamental shift is underway. With the rapid rise of LLM-powered search agents, retrieval is increasingly consumed by AI agents rather than human beings. These agents issue queries, browse documents, reason about content, and make decisions in multi-turn loops. They don't click like humans, they don't skim like humans, and they don't get distracted by position bias. Yet the retrieval models they depend on are still trained on human behavior—a fundamental mismatch.
What is Position Bias?
When you search Google, you probably click on the first few results more often than results on page 2, even if they're equally good. This is position bias—humans tend to interact with higher-ranked results simply because they appear first, not necessarily because they're more relevant.
This creates a big problem for training search systems: if you learn from human clicks, you'll think top-ranked results are always better, which isn't true. It's like judging restaurants only by the ones on the main street—you miss great places on side streets.
AI search agents don't have this problem. They evaluate documents based on content, not position, which makes their behavior a much cleaner training signal.
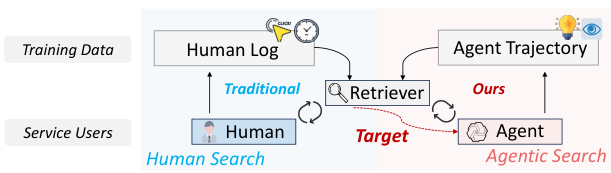
Figure 2: Traditional human-centric retrieval (left) trains on human logs. The proposed approach (right) trains directly from agent trajectories—the multi-step interaction records of LLM search agents.
This mismatch motivates a rethinking of retrieval training for the agent era. Rather than repurposing human-trained retrievers, the authors argue that retrieval models should be trained directly from agent interaction data. Just as learning-to-rank was revolutionized by human click logs, the next revolution may come from agent trajectories.
Agent trajectories record the complete sequence of intermediate queries, retrieved documents, browsing decisions, and reasoning traces generated during multi-turn search sessions. These trajectories contain rich signals about document utility that are fundamentally different from human feedback.
Three Key Discoveries from Agent Trajectories
Through systematic analysis of deep research agent trajectories, the authors identify three behavioral signals that reveal document utility—each addressing a limitation of traditional human feedback:
🔍
Browsing Is a Success Signal
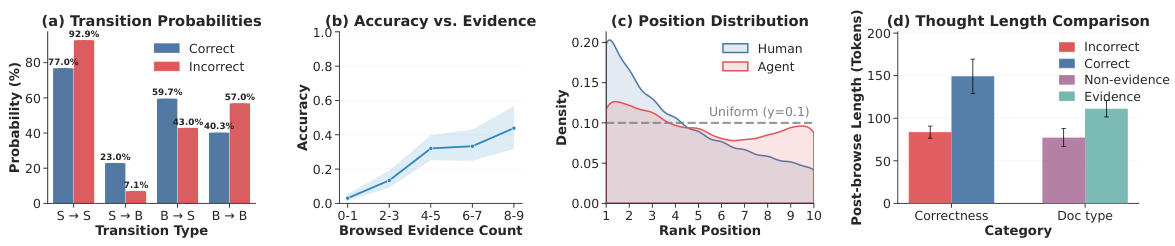
When an agent decides to browse a document, it's a strong indicator that the document is potentially useful. Analysis shows that browsing is a necessary condition for task success—successful trajectories always involve browsing relevant documents. This makes browsed documents natural candidates for positive training signals.
⛔
Unbrowsed = Reliable Negatives
Unlike human search where users tend to click on top-ranked results regardless of relevance (position bias), agents show weak position dependence in their browsing decisions. This means unbrowsed documents in agent trajectories are genuine rejections rather than simply unseen results, making them reliable negative training signals without the need for complex debiasing.
🧠
Reasoning Traces Reveal Intensity
After browsing a document, agents generate reasoning traces—internal monologues where they evaluate what they read. The length of these reasoning traces strongly correlates with document utility: longer reasoning means the agent found more useful information. This is analogous to human dwell time, but far richer and more reliable as a relevance signal.
Figure 4: Analysis of agent trajectories: (a) transition probabilities in correct vs. incorrect trajectories, (b) accuracy vs. browsed evidence count, (c) position distribution comparison between humans and agents, (d) post-browse thought length by document category.
How a Search Agent Thinks
To understand why agent trajectories are so valuable, let's look at how a deep research agent actually works. When given a question, the agent doesn't just fire off a single search query. Instead, it engages in a multi-step process of thinking, searching, browsing, and reasoning:
Figure 3: A trajectory example showing the agent's step-by-step process: Think → Search → Information → Browse → Information → Answer. The Reasoning Length after browsing indicates how deeply the agent processed the document content.
Each trajectory captures the full decision-making process: which documents the agent chose to browse, which it rejected, and how much reasoning it dedicated to each. These rich behavioral signals form the foundation of the LRAT training paradigm.
The LRAT Framework
LRAT (Learning to Retrieve from Agent Trajectories) is a framework that progressively mines high-quality retrieval supervision from agent interactions and trains retrievers with utility-aware weighting. The framework has four key components:
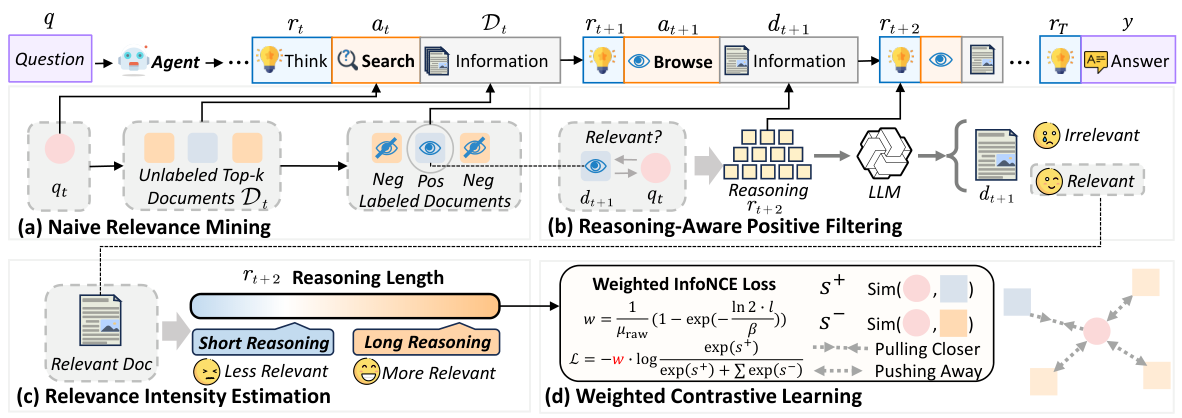
Figure 5: Overview of the LRAT framework showing the progressive pipeline from naive relevance mining through reasoning-aware filtering, intensity estimation, and weighted contrastive learning.
1. Naive Relevance Mining
The first step extracts coarse supervision from the agent's Search → Browse transitions. When an agent issues a search query and then browses one of the returned documents, that document becomes a naive positive. All other documents in the same search result that were not browsed become naive negatives. Because agents show minimal position bias, these negatives are far more reliable than human click-log negatives.
Positive and Negative Training Pairs
Training a search model is like teaching someone to sort photos into "relevant" and "not relevant" piles:
Positive samples = photos that should go in the "relevant" pile (documents the agent browsed and found useful)
Negative samples = photos that should go in the "not relevant" pile (documents the agent saw but skipped)
The quality of training depends heavily on getting these labels right. If you put a useful document in the "not relevant" pile (a false negative), the model learns the wrong thing. Traditional approaches using human clicks suffer from noisy labels because humans click for many reasons unrelated to relevance. Agent trajectories produce cleaner labels because agents make more deliberate browsing decisions.
2. Reasoning-Aware Positive Filtering
Not every browsed document is truly useful—agents sometimes browse a document and then realize it's not helpful. LRAT uses an LLM-as-judge to examine the agent's post-browse reasoning trace and determine whether the document actually contributed to task progress. This filtering step removes noise while preserving 97.2% of ground-truth evidence documents.
LLM-as-Judge is a technique where a separate language model evaluates the output of another system. Think of it like having a supervisor review an employee's work notes. Here, the judge LLM (Qwen3-30B) reads the agent's post-browse reasoning and decides: "Did this agent actually learn something useful from this document, or did it just skim and move on?" This second opinion removes noisy positives that would otherwise pollute the training data.
3. Relevance Intensity Estimation
Not all relevant documents are equally useful. LRAT models relevance as a continuous quantity derived from the agent's post-browse reasoning length. Longer reasoning chains indicate deeper engagement with the document and higher utility. This is mapped to a bounded utility score using an exponential saturation function, capturing the diminishing returns of increasingly detailed reasoning.
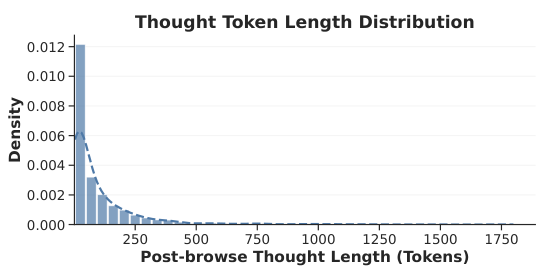
Figure 6: Distribution of post-browse thought token lengths. The exponential decay pattern motivates the saturation function used for relevance intensity estimation.
The relevance intensity weight \(w\) is computed as: \(w = \frac{1 - e^{-l \cdot \ln 2 / B}}{H_{\text{raw}}}\), where \(l\) is the reasoning length, \(B\) is the median reasoning length (half-life), and \(H_{\text{raw}}\) is a normalization constant ensuring \(\mathbb{E}[w] \approx 1\).
Breaking Down the Relevance Intensity Formula
The core idea is simple: longer reasoning = more useful document. But you can't just use raw reasoning length directly because:
A document that triggers 100 tokens of reasoning is much more useful than one that triggers 10
But the difference between 900 and 1000 tokens is much less meaningful
This is diminishing returns—the same pattern as reading a textbook. The first chapter teaches you a lot, but by chapter 20, each new chapter adds less new knowledge.
The formula uses an exponential saturation function (like a battery charging curve) that rises quickly at first and then levels off. The half-life parameter B (set to the median reasoning length) controls how quickly this leveling happens. The normalization ensures the average weight is 1, so the overall training process stays balanced.
4. Weighted Contrastive Learning
Finally, LRAT trains a dense bi-encoder retriever using a weighted InfoNCE loss. The relevance intensity weights scale the gradient contribution of each training instance, allowing documents that triggered deeper agent reasoning to have a stronger influence during training. Negatives come from both unbrowsed trajectory documents and in-batch negatives for improved discriminative power.
InfoNCE Loss is the standard training objective for contrastive learning. It works like a multiple-choice test: given a query, the model must pick the correct document from a set of candidates. The "weighted" version in LRAT makes some correct answers count more than others—documents that triggered deeper agent reasoning get higher weight, pushing the model to prioritize truly valuable results.
Experimental Results
Setup
LRAT was evaluated on two benchmarks: InfoSeek-Eval (300 multi-hop queries, in-domain) and BrowseComp-Plus (830 complex questions, out-of-domain). Two retriever backbones were tested: Qwen3-Embedding-0.6B (decoder-based) and Multilingual-E5-Large-Instruct (encoder-based). These were integrated into six diverse agent architectures spanning 4B to 358B parameters, including both task-optimized search agents and generalist agentic foundation models.
Understanding the Evaluation Setup
The experiments test LRAT in two scenarios:
In-domain (InfoSeek-Eval): The test questions are similar to the training data. This checks if the approach works at all. Like testing a student on material they studied.
Out-of-domain (BrowseComp-Plus): Completely different questions from a different dataset. This is the harder test—like giving a student an exam from a different course. Strong performance here means LRAT learns general retrieval skills, not just patterns specific to one dataset.
Testing across 6 different agent architectures (from 4B to 358B parameters) further validates that LRAT's improvements aren't tied to a specific model—they generalize across scales and designs.
A bi-encoder dense retriever converts both the search query and each document into fixed-length vectors (embeddings), then measures similarity using dot product. It's called "bi-encoder" because query and document go through separate encoders. This is the architecture used in most modern semantic search systems because it allows pre-computing document embeddings for fast retrieval at scale.
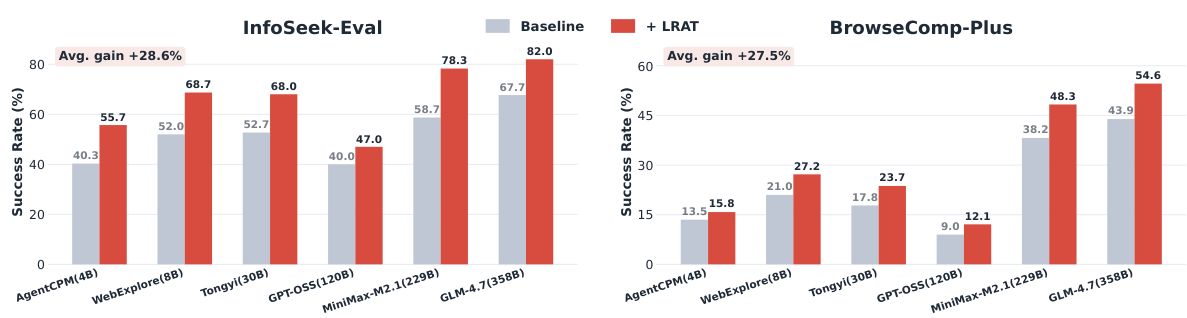
Figure 1: LRAT consistently improves success rates across all agent backbones. Average gains of +28.6% on InfoSeek-Eval and +27.5% on BrowseComp-Plus.
Key Findings
Improved Evidence Retrieval
LRAT significantly boosts the retriever's ability to find annotated evidence documents. On BrowseComp-Plus, evidence recall improved by 7% to over 37% across all agent-retriever combinations, demonstrating that agent-trajectory supervision effectively aligns retrievers with agent information needs.
End-to-End Task Success
Better retrieval translates directly to better task outcomes. Agents equipped with LRAT-trained retrievers achieve substantially higher success rates across both in-domain and out-of-domain settings. These gains are consistent across all agent architectures and scales, from 4B to 358B parameters.
More Efficient Execution
LRAT doesn't just improve accuracy—it makes agents faster. Average interaction steps were reduced by up to ~30% on InfoSeek-Eval. Better retrieval means agents find what they need sooner, reducing costly exploratory interactions and saving compute resources.
Detailed Results
Agent Backbone
Retriever
SR (ID)
SR (OOD)
Recall (OOD)
AgentCPM (4B)
Qwen3-Emb
40.3
13.5
23.2
Qwen3-Emb + LRAT
55.7
15.8
32.0
E5-Large
49.7
15.9
26.5
E5-Large + LRAT
47.3
15.9
32.1
Tongyi (30B)
Qwen3-Emb
52.0
21.0
47.7
Qwen3-Emb + LRAT
68.7
27.2
55.9
E5-Large
63.3
29.0
50.4
E5-Large + LRAT
60.0
25.4
56.1
GLM-4.7 (358B)
Qwen3-Emb
67.7
43.9
66.6
Qwen3-Emb + LRAT
82.0
54.6
77.8
E5-Large
73.7
46.4
68.7
E5-Large + LRAT
81.7
50.6
76.3
Table 2 (simplified): Results across agent backbones. SR = Success Rate (%), ID = InfoSeek-Eval (in-domain), OOD = BrowseComp-Plus (out-of-domain). LRAT rows show consistent improvements.
Ablation Study & Deeper Analysis
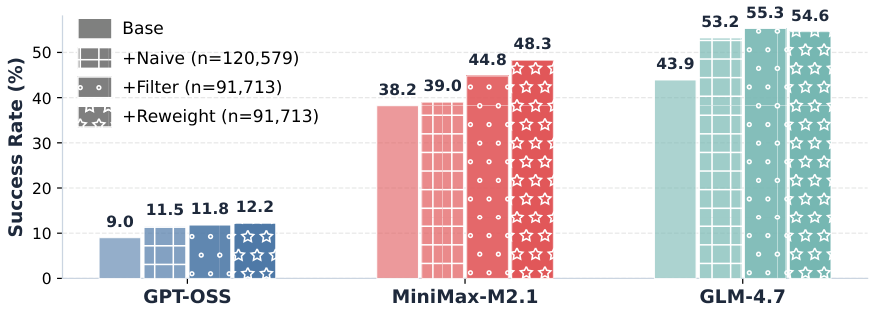
Component-by-Component Ablation
To understand which parts of LRAT matter most, an ablation study was conducted on BrowseComp-Plus using Qwen3-Embedding-0.6B. Components were added incrementally to a base retriever:
Figure 7: Ablation study results showing the incremental contribution of each LRAT component across three agent backbones.
+Naive: Using browsed/unbrowsed signals alone yields substantial gains, confirming that agent browsing decisions lack position bias and provide reliable training signal.
+Filter: LLM-based filtering of browsed documents further improves performance, demonstrating that post-browse reasoning traces effectively identify false positives.
+Reweight: Incorporating relevance intensity estimation through reasoning length provides additional gains, validating the value of fine-grained document utility modeling.
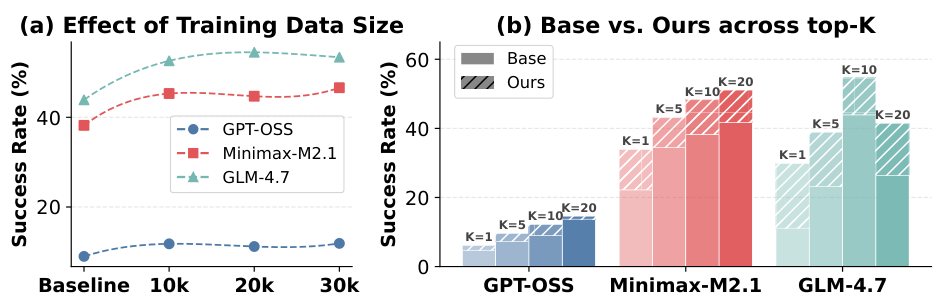
Scalability & Robustness
LRAT scales well with more data: training on progressively larger subsets (1K to 30K trajectories) shows consistent improvement in agent success rates. At inference time, LRAT-trained retrievers consistently outperform baselines across different top-K retrieval budgets, even when larger K introduces noise.
Figure 8: (a) Training data scalability—performance improves with more agent trajectories. (b) Robustness across top-K settings—LRAT maintains advantages regardless of retrieval budget.
The Data Flywheel Effect
Perhaps the most exciting finding: LRAT can create a self-sustaining data flywheel analogous to human click-log improvement cycles. In a simulated iterative deployment, the retriever is updated with fresh agent trajectories at each step. Results show steady improvements in both success rate and evidence recall across iterations—even when using imperfect trajectories from real-world-like open-ended queries.
Why the Data Flywheel Matters
A data flywheel is a self-reinforcing improvement cycle. In traditional web search, it works like this: more users → more click data → better search model → more users. Google's dominance partly comes from this flywheel.
LRAT shows the same pattern can work with AI agents instead of humans. As agents interact with the improved retriever, they generate better trajectories, which in turn further improve the retriever. This is significant because it means you don't need human feedback at all—the system can improve itself through agent interactions alone, making it practical for deployment in production search systems where agents are the primary consumers.
Figure 9: Data flywheel simulation. Left: the iterative retriever-agent update loop. Right: both agent success rate and retriever recall improve steadily across loop iterations.
Conclusion & Future Directions
This paper identifies a fundamental misalignment between human-centric retrieval training and the needs of agentic search, and formalizes learning to retrieve from agent trajectories as a new retrieval paradigm. LRAT demonstrates that agent interaction data contains rich, reliable supervision signals that can substantially improve retrieval quality, task success, and execution efficiency across diverse agent architectures.
Key Contributions
New paradigm: Formalized learning to retrieve from agent trajectories, shifting the training signal source from human interaction logs to agent interaction data.
Behavioral insights: Identified three key agent signals—browsing as necessary condition, unbrowsed documents as reliable negatives, and reasoning traces as relevance intensity indicators.
Practical framework: Proposed LRAT with progressive signal mining and weighted contrastive learning, achieving consistent improvements (+28.6% on InfoSeek-Eval, +27.5% on BrowseComp-Plus) across six diverse agent architectures.
References (click to expand)
Agichtein, E., Brill, E., & Dumais, S. (2006). Improving web search ranking by incorporating user behavior information. SIGIR.
Baeza-Yates, R. et al. (1999). Modern Information Retrieval. ACM Press.
Burges, C. et al. (2005). Learning to rank using gradient descent. ICML.
Cao, Y. et al. (2006). Adapting ranking SVM to document retrieval. SIGIR.
Chen, H. et al. (2026). AgentCPM-Explore: An end-to-end infrastructure for deep research agents.
Chen, Z. et al. (2025). BrowseComp-Plus: A reproducible benchmark for deep research agents.
Dai, S. et al. (2025). Next-Search: Rebuilding user feedback ecosystem for generative AI search. SIGIR.
Gutmann, M. & Hyvärinen, A. (2010). Noise-contrastive estimation. AISTATS.
Jin, B. et al. (2025). Search-R1: Training LLMs to reason and leverage search engines with RL.
Joachims, T. (2002). Optimizing search engines using clickthrough data. KDD.
Kelly, D. & Belkin, N. (2004). Display time as implicit feedback. SIGIR.
Kim, Y. et al. (2014). Modeling dwell time to predict click-level satisfaction. WSDM.
Liu, T.-Y. (2009). Learning to rank for information retrieval. FTIR.
Liu, Y. et al. (2016). Time-aware click model. TOIS.
Liu, J. et al. (2025). WebExplorer: Explore and evolve for training long-horizon web agents.
Luo, C. et al. (2025). InfoSeek-Eval benchmark for information-seeking agents.
OpenAI (2025). GPT-OSS-120B.
Song, Y. et al. (2025). R1-searcher: Incentivizing the search capability in LLMs.
Team, MiniMax (2025). MiniMax-M2.1-229B.
Team, GLM (2025). GLM-4.7-358B.
Team, Tongyi (2025). Tongyi-DeepResearch-30B.
Wang, L. et al. (2024). Multilingual-E5-Large-Instruct. ACL.
Zhang, P. et al. (2025). Qwen3-Embedding-0.6B.
Information RetrievalAgent TrajectoriesLLM AgentsDeep ResearchContrastive LearningAgentic SearchLRAT
B2B Content
Any content, beautifully transformed for your organization
PDFs, videos, web pages — we turn any source material into production-quality content. Rich HTML · Custom slides · Animated video.