Dataset
Dataset: Diverse, Fresh, and Rigorously Annotated
5
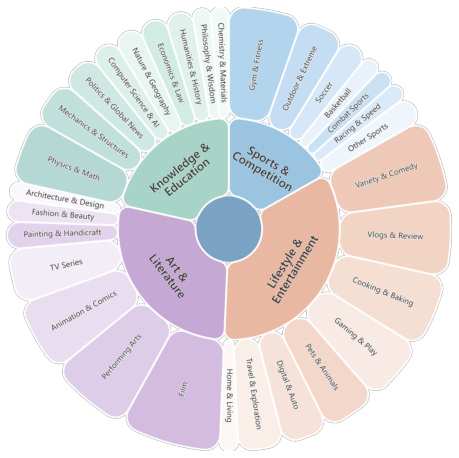
Major Categories
800
Videos
3,300+
Human Hours
5
QA Rounds
Rigorous Annotation Pipeline
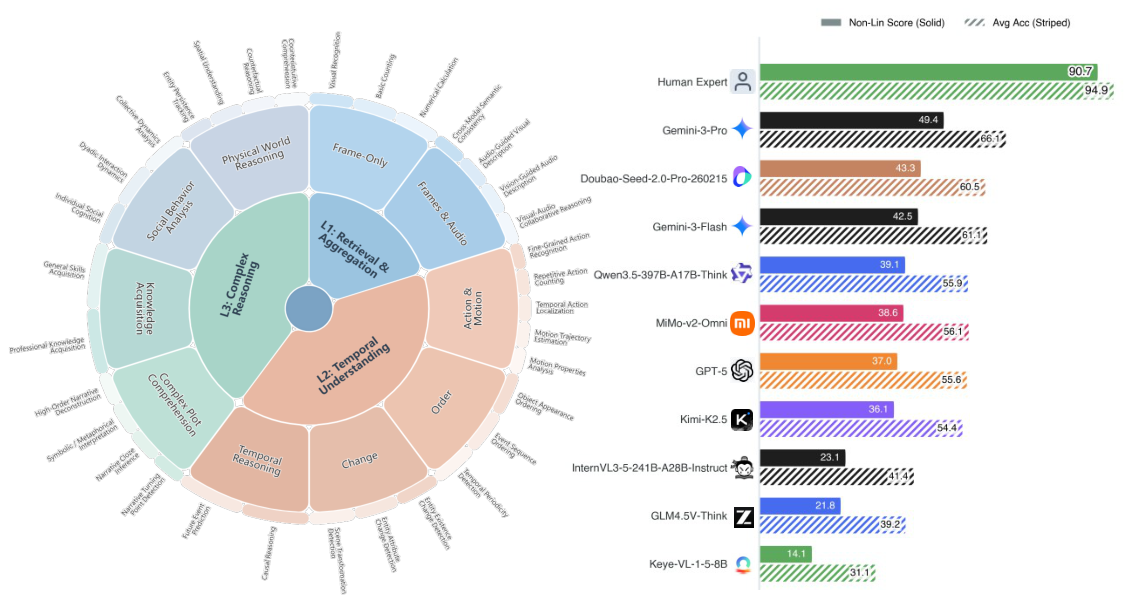
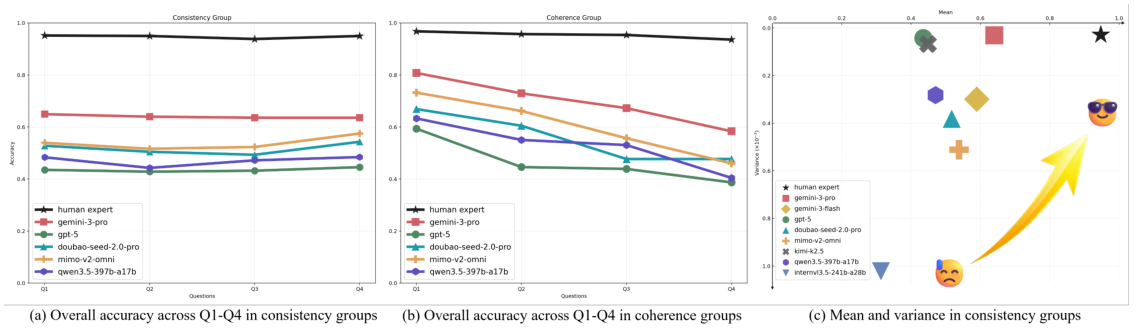
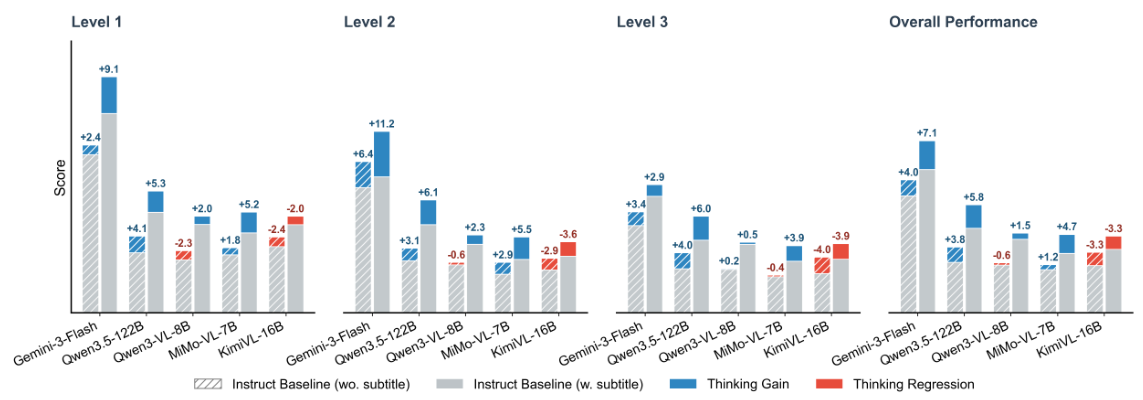
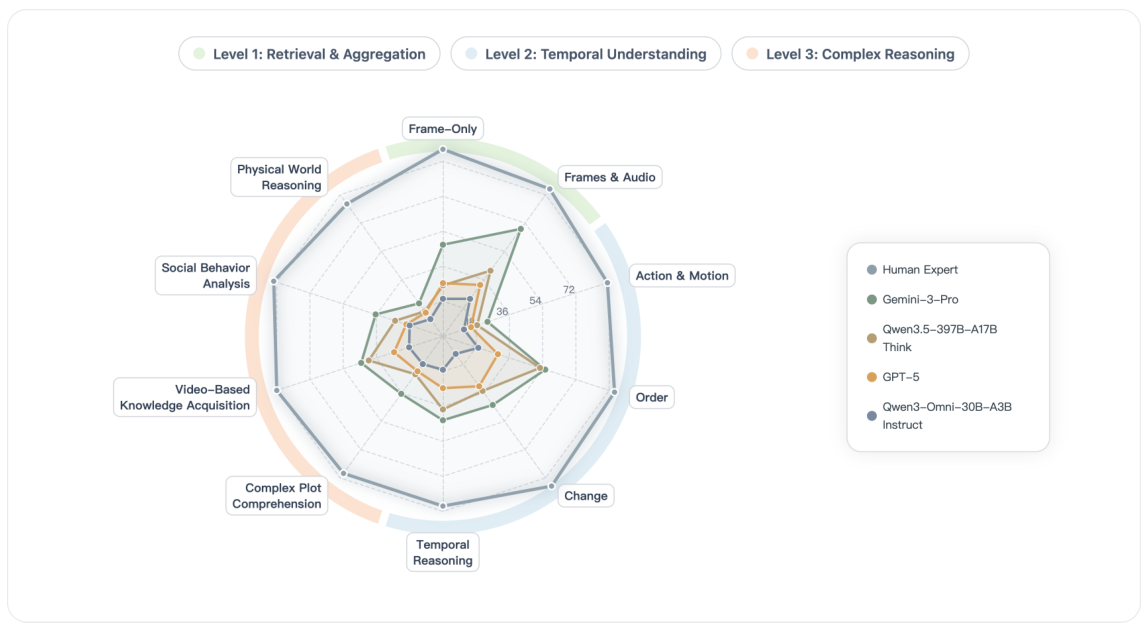
Data quality is ensured through a controlled annotation pipeline: 12 annotators created the questions and ground truth answers, while 50 independent reviewers verified the content across up to 5 rounds of quality assurance. This process ensures Video-MME-v2 contains only unambiguous, high-quality benchmark items that genuinely test video understanding rather than surface pattern matching.
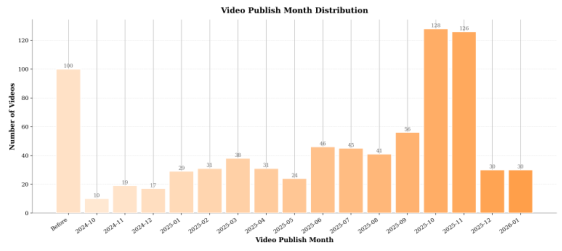
Why 3,300 hours? At an average of 30 minutes per video annotation (watching, writing questions, verifying answers), annotating 800+ videos requires enormous effort. The 5-round QA process means each item was reviewed approximately 50 times before inclusion. This contrasts with many benchmarks that use automated or crowd-sourced annotation with far less rigorous verification.