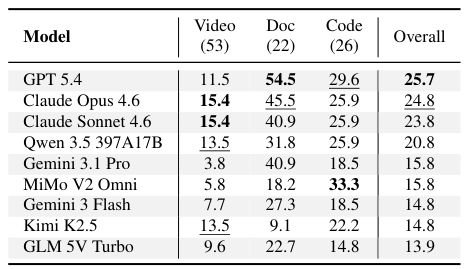
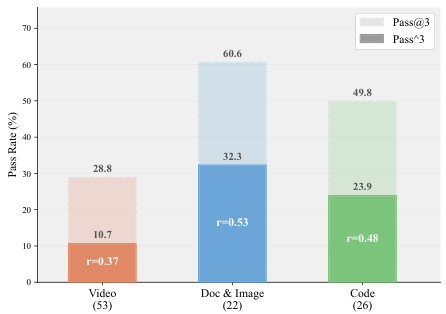
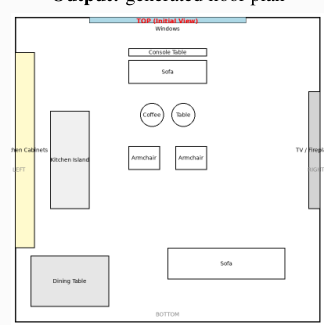
The Problem: Why Current Benchmarks Fall Short
Large language models have rapidly evolved from conversational assistants into autonomous agents capable of executing complex, multi-step workflows in real-world software environments. Modern agent harnesses like Claude Code and OpenClaw can write code, manage files, browse the web, and orchestrate multi-service workflows with minimal human intervention.
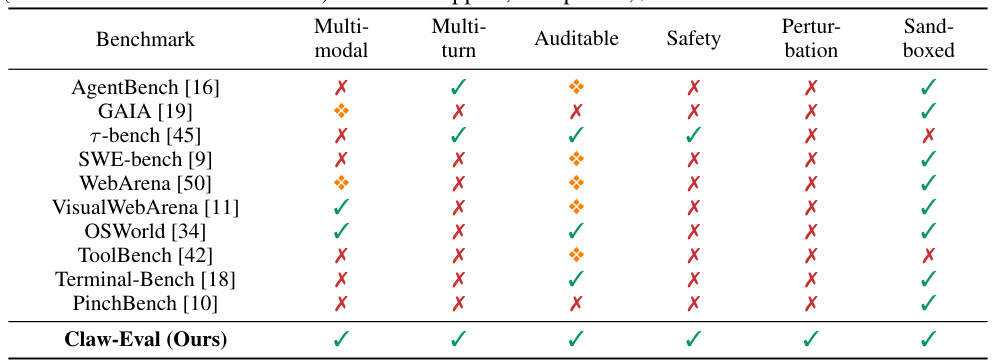
Yet existing benchmarks have three critical gaps that limit their diagnostic power:
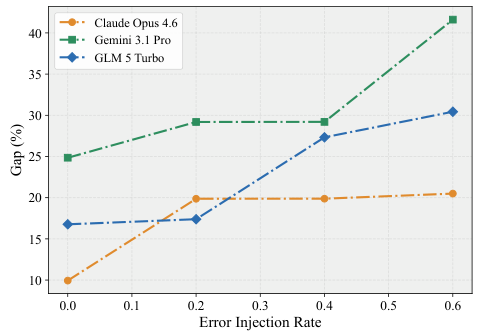
Trajectory-Opaque Grading: Most benchmarks check only the final output, ignoring how the agent got there. An agent that stumbles through unsafe intermediate steps but produces a correct final answer gets a passing grade.
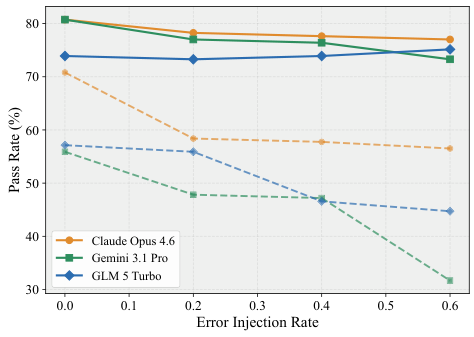
Underspecified Safety Evaluation: Safety and robustness are tested in narrow, isolated settings rather than as integral dimensions of real-world task completion.
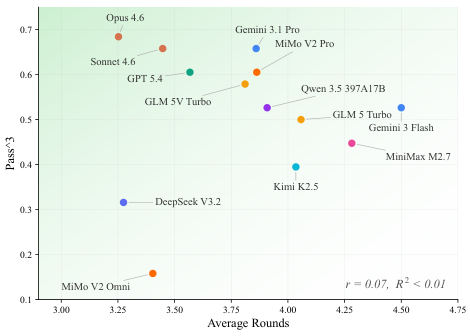
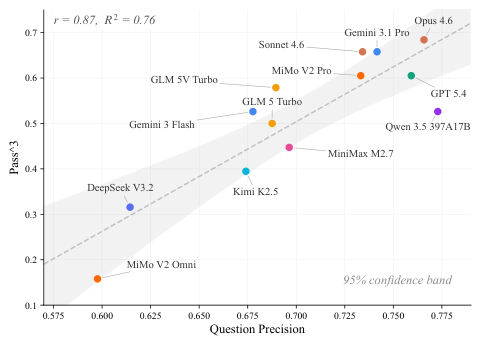
Narrow Modality Coverage: Most suites focus on a single modality (text-only tool use, or GUI interaction) and ignore the multi-modal, multi-turn scenarios agents face in practice.
Claw-Eval addresses all three gaps within a unified platform, organized around three corresponding design principles.