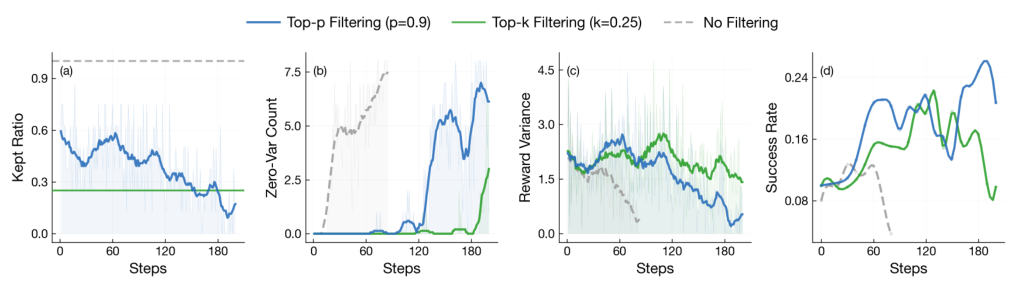
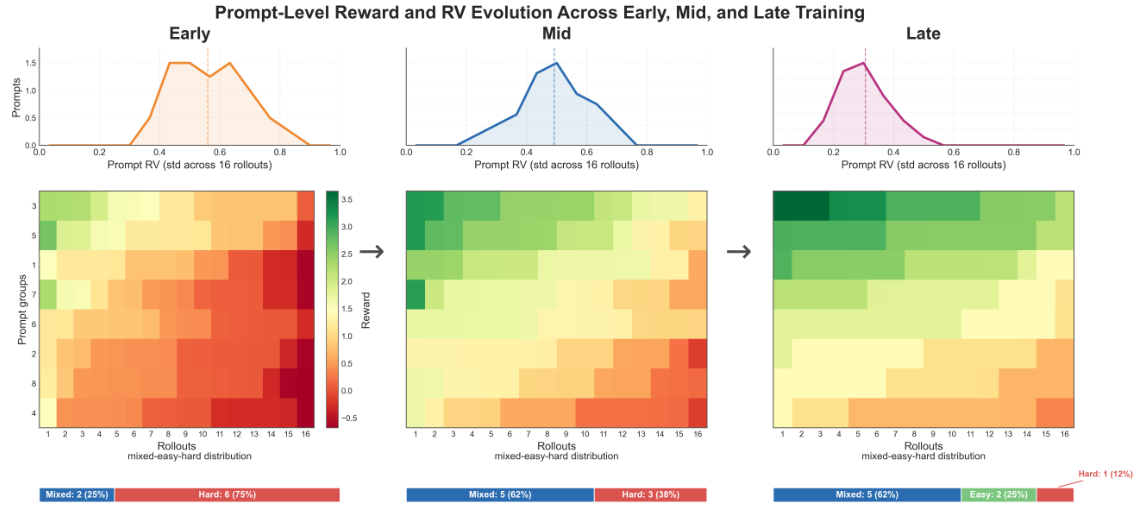
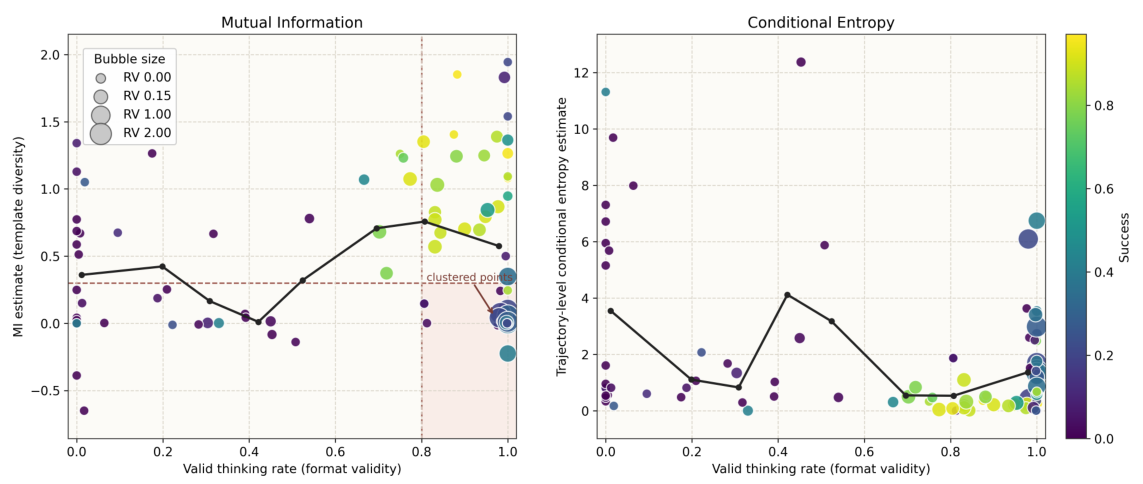
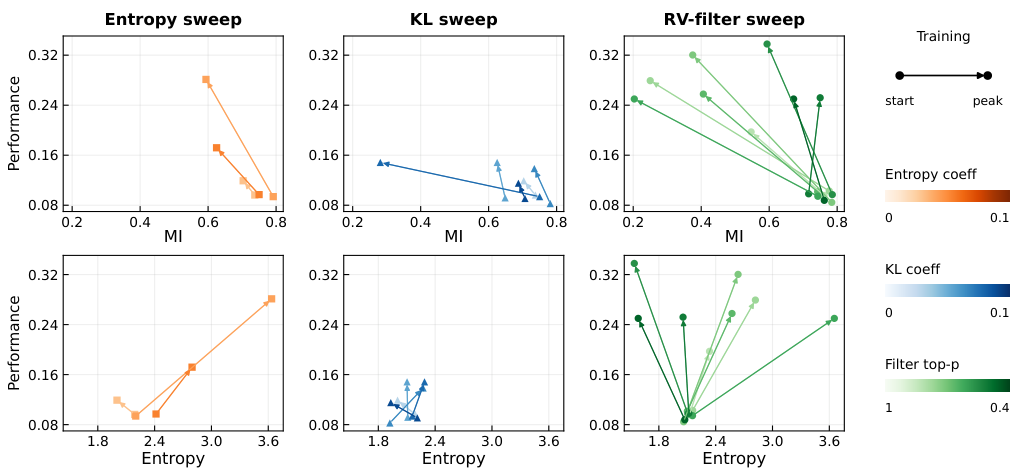
Template Collapse — The Failure Mode
2.1 What is Template Collapse?
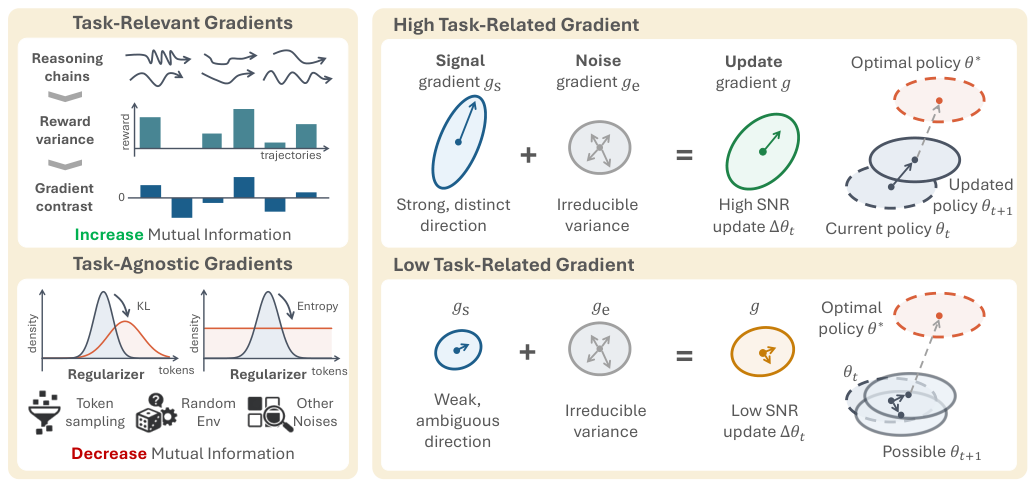
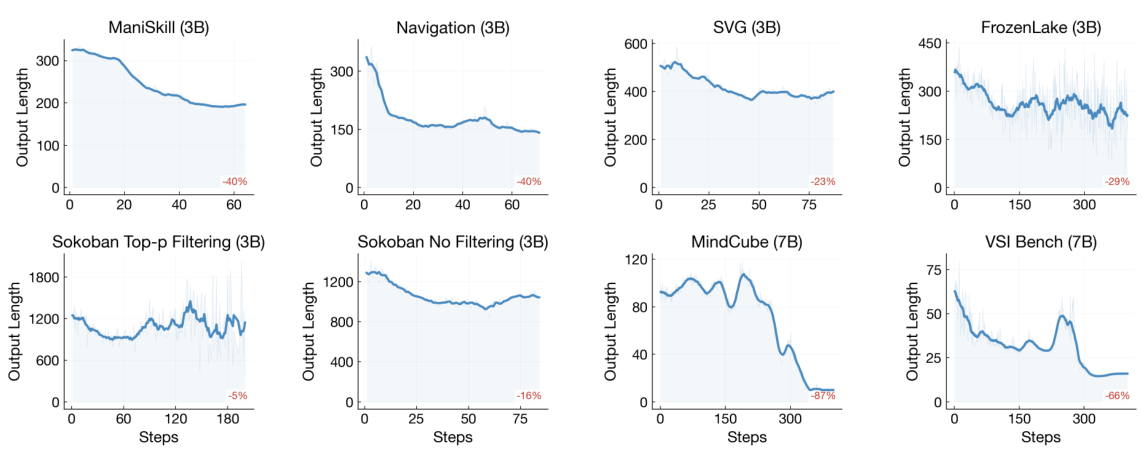
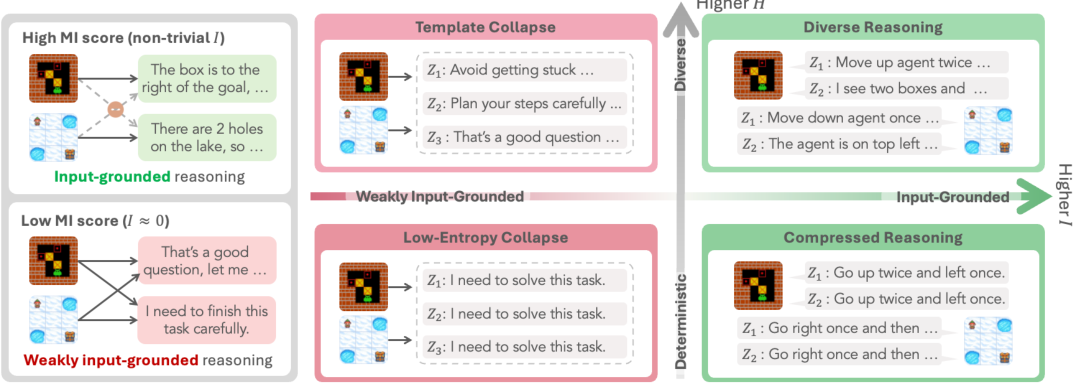
Template collapse occurs when an RL-trained LLM agent converges to a fixed set of response templates that are applied regardless of the actual input. The model learns to output phrases like "I need to solve the task step by step" or "Let me think about this carefully" as boilerplate preambles that precede any reasoning, effectively ignoring input-specific information.
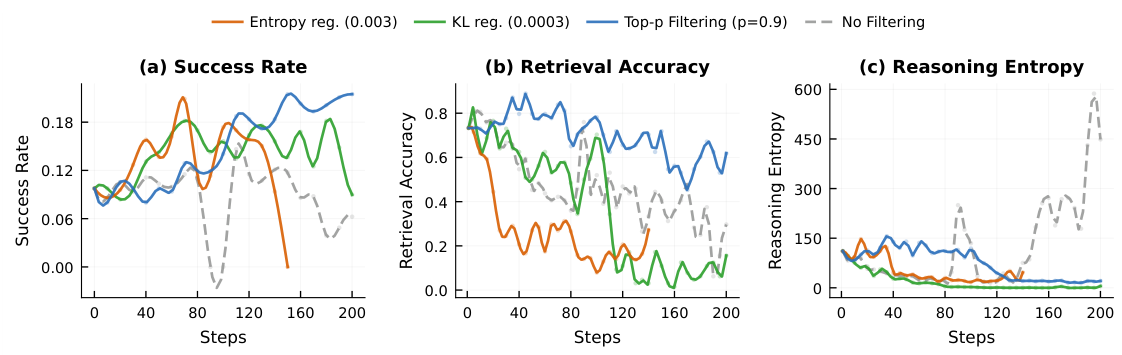
What makes this insidious is that standard entropy metrics fail to detect it. Because the templates themselves may vary superficially (the model selects from a pool of template phrases), the overall token distribution can appear diverse. Only when you ask whether the output depends on the input does the collapse become visible.
2.2 Mutual Information vs Entropy
The key insight is the distinction between two related but different quantities: entropy H(Y) measures the diversity of outputs within a single input (how variable are the N samples for prompt x?), while mutual information MI(X;Y) measures whether outputs change across inputs (do different prompts produce meaningfully different responses?).
Mutual information between input X and output Y quantifies how much knowing the input reduces uncertainty about the output:
Equivalently, MI = H(Y) − H(Y|X). When MI is high, different inputs lead to genuinely different outputs. When MI is low despite high H(Y), the model has collapsed into input-agnostic behavior — template collapse.
This distinction is crucial: entropy measures within-input diversity (variance across rollouts of the same prompt), while MI measures cross-input discriminability (whether the agent responds differently to different situations). Template collapse exhibits high H(Y) but low MI — the agent is "creative" within a fixed template space but not actually responsive to the task.
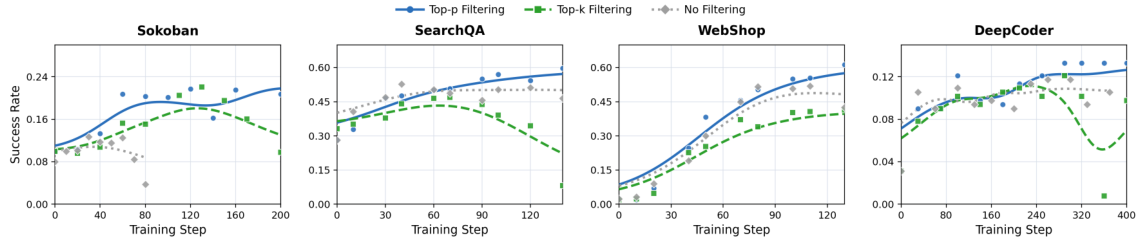
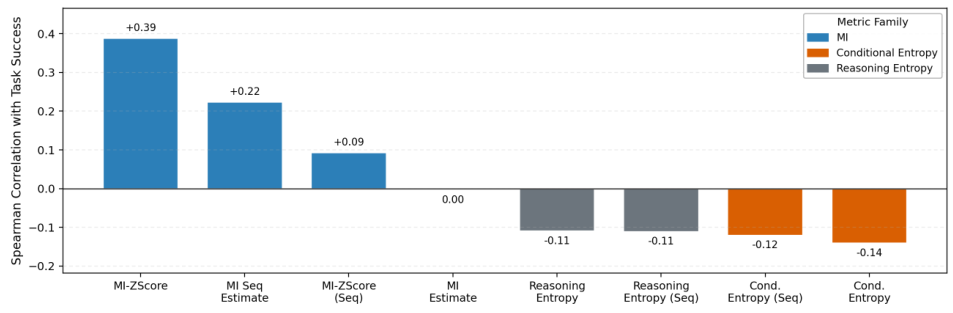
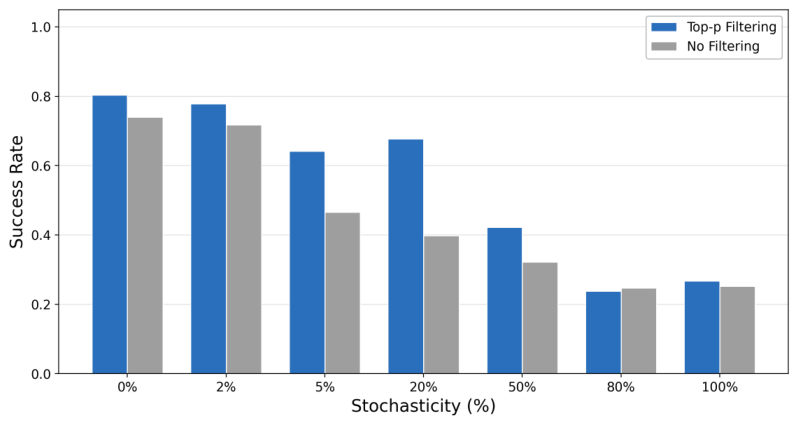
2.3 Online MI Proxy Metrics
Since exact MI computation is expensive, RAGEN-2 proposes a family of online MI proxies that can be computed efficiently during training:
MI-ZScore
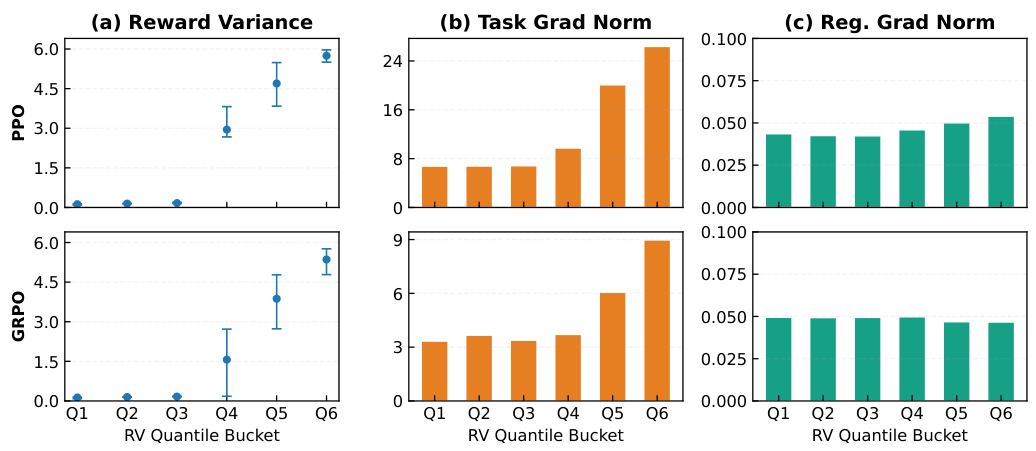
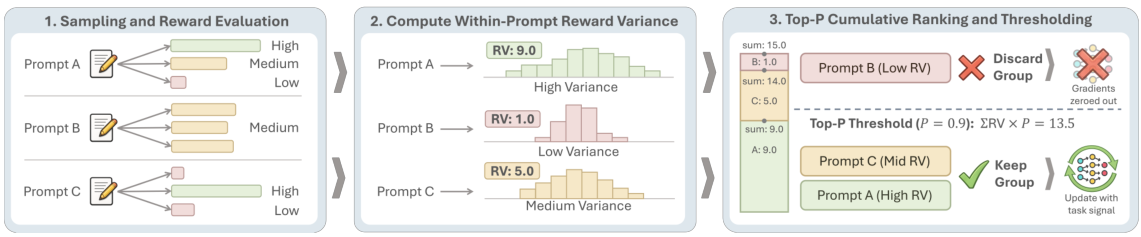
Standardizes the mean reward across prompts using a Z-score. High cross-prompt variance in reward signal indicates input-dependent behavior (high MI). The simplest and most effective proxy.
MI Seq Estimate
Estimates MI directly from the sequential structure of outputs, using the frequency of distinct response prefixes across different prompts as an information-theoretic estimate.
MI-ZScore (Seq)
Combines the Z-score approach with sequence-level estimation for a more robust proxy that handles variable-length responses and noisy reward signals.