RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
Abstract
Abstract
Modern image generation models frequently suffer from local detail collapse — when the model encodes an image at fixed resolution, small regions lose critical information that cannot be recovered during decoding. The result: distorted text, blurry faces, and misrendered logos in otherwise good AI-generated images.
RefineAnything formalizes region-specific image refinement as a dedicated problem: given an input image and a user-specified region (scribble mask or bounding box), restore fine-grained details in that region while keeping all non-edited pixels strictly unchanged. The system uses a frozen Qwen2.5-VL multimodal encoder, a novel Focus-and-Refine crop-upsample-denoise strategy, and a Boundary Consistency Loss to achieve seamless integration. Training uses Refine-30K, a 30K-sample dataset (20K reference-based, 10K reference-free). Evaluation uses RefineEval, the first benchmark for this task.
- Region-specific refinement as a dedicated problem setting
- Focus-and-Refine: crop → upsample → denoise → paste-back
- Boundary Consistency Loss for seamless integration
- Refine-30K: 30K training samples (reference-based + reference-free)
- RefineEval: first benchmark for region-specific refinement

Section 1
1. Introduction
Image generation has advanced dramatically, but a fundamental bottleneck persists: VAE information loss. When a diffusion model encodes an image, small regions occupy only a few latent tokens. The encoder compresses them aggressively, and the fine detail — readable text, recognizable logos, sharp facial features — simply cannot be recovered at decode time.
Existing editing models like InstructPix2Pix and SDEdit can modify image regions, but they don't preserve the surrounding context — edits bleed into the surrounding pixels. FLUX Kontext improves context preservation but isn't designed for surgical local detail recovery. RefineAnything is the first system dedicated to this exact problem.
New Problem Setting
Region-specific image refinement defined formally: given an image + user-specified region, restore detail while preserving all other pixels exactly.
RefineAnything System
Focus-and-Refine strategy addresses the VAE resolution bottleneck; Boundary Consistency Loss ensures seamless paste-back; multimodal VLM conditioning guides the refinement.
Refine-30K + RefineEval
30K training samples covering reference-based and reference-free modes, plus the first dedicated benchmark for evaluating region-specific refinement.
Section 3
3. Method
RefineAnything builds on a diffusion backbone conditioned by Qwen2.5-VL. The system takes as input: (1) an input image with a degraded region, (2) an optional reference image showing what the region should look like, (3) a region cue (scribble mask or bounding box), and (4) a text instruction. It produces a refined output image identical to the input except in the specified region.
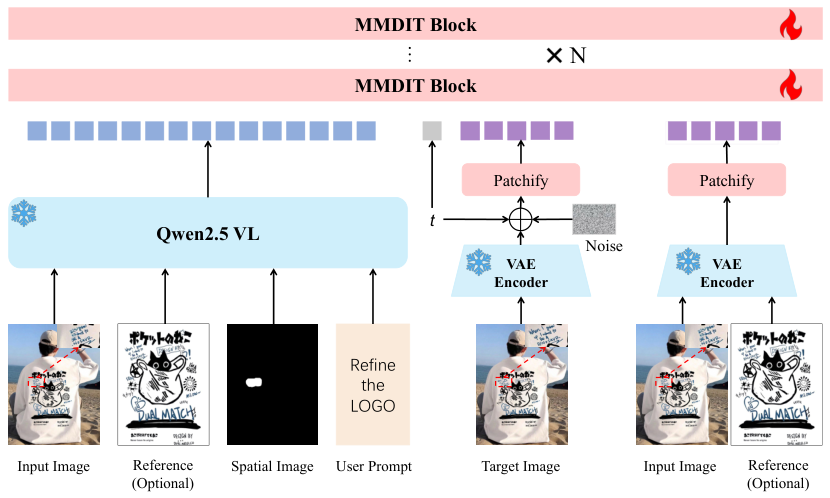
The Three-Step Pipeline
Multimodal Encoding
Qwen2.5-VL (frozen) encodes the full input image, optional reference image, region cue, and text instruction into multimodal conditioning tokens. These tokens carry semantic guidance — what the region should look like — into the diffusion backbone.
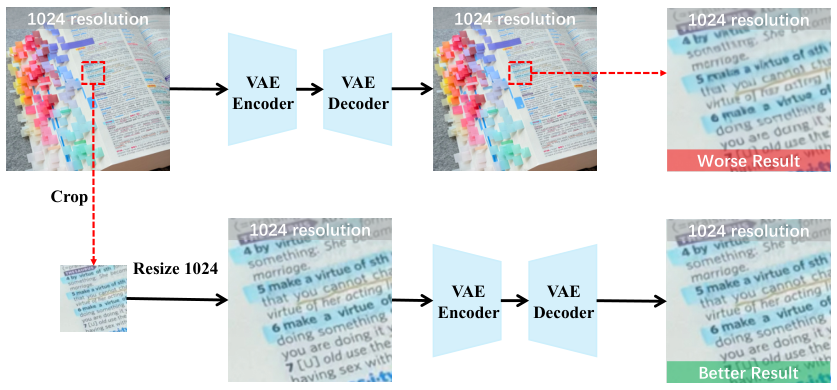
Focus-and-Refine
The specified region is cropped and upsampled to full resolution. Diffusion denoising runs in this high-resolution space, solving the VAE information loss problem by giving the encoder a full-resolution view of the small target region. This is the key insight that enables fine-grained detail recovery.
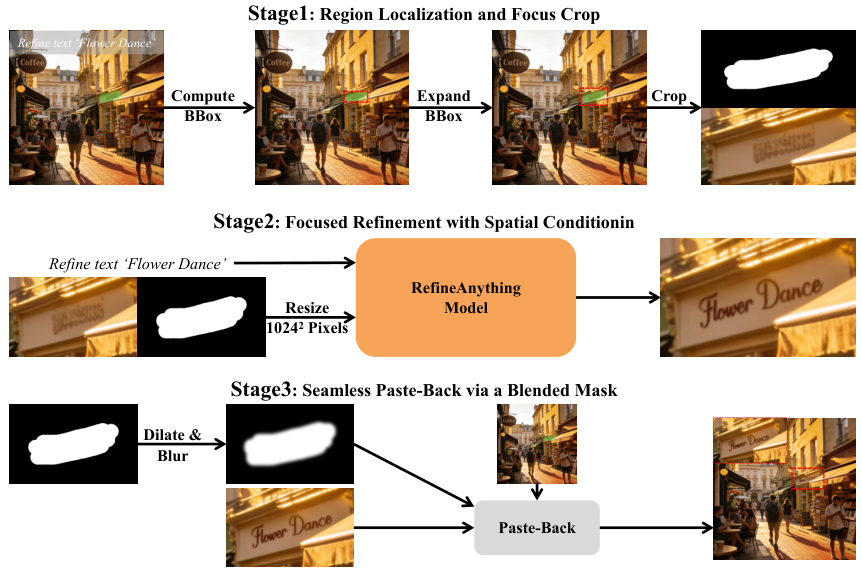
Seamless Paste-Back
The refined region is pasted back into the original image. Boundary Consistency Loss, applied during training, penalizes any visible discontinuity at the region boundary. The result is a seamless composite — the refined region integrates naturally, with no seam or halo artifact.
Refine-30K Dataset
To train RefineAnything, the authors created Refine-30K — the first training dataset specifically designed for region-specific image refinement. It was built using an automated degradation + ground truth restoration pipeline, covering text on products, logos, faces, and textures.
30,000 training samples across two refinement modes:
Input image + reference image of the target object/text/face → restore the region to match the reference.
Input image + text prompt only → restore the region based on textual description alone.
Sections 4 – 5
4–5. Experiments
RefineAnything is evaluated on RefineEval, the first dedicated benchmark for region-specific image refinement. It is compared against state-of-the-art baselines including FLUX Kontext, SDEdit, and InstructPix2Pix on both reference-based and reference-free settings.
Reference-Based Refinement
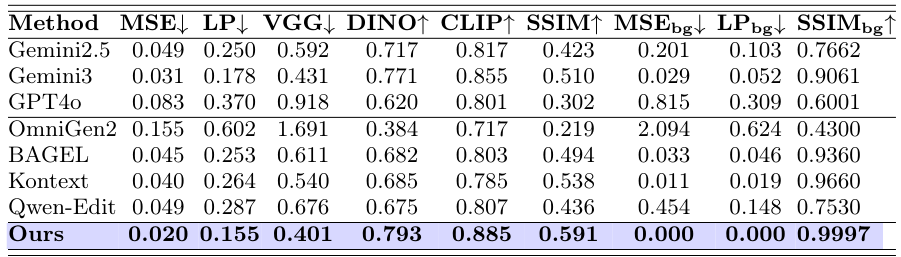
Table 1: Quantitative results on RefineEval (reference-based setting). Metrics: CLIP-I (reference fidelity), PSNR and SSIM (boundary preservation), and a composite fidelity score. RefineAnything achieves best scores across all metrics.
In addition to quantitative gains, the qualitative comparisons below show RefineAnything's superiority in restoring fine-grained local details. Baseline models either fail to render readable text, produce blurry logos, or distort facial features. RefineAnything recovers crisp detail while seamlessly integrating into the surrounding image.
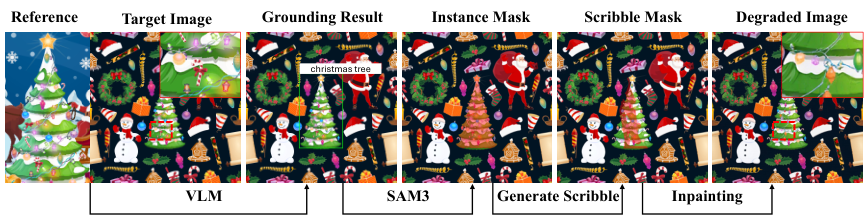
Reference-Free Refinement
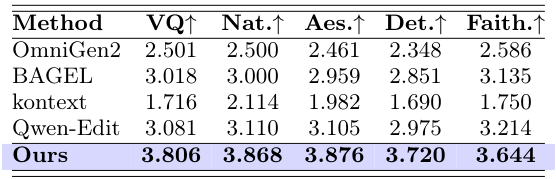
Table 2: Quantitative results on RefineEval (reference-free setting). Metrics cover instruction following, region quality, and background preservation. RefineAnything outperforms all prompt-driven baselines.

Real-World Application Results
To demonstrate practical utility, RefineAnything is applied to images generated by frontier models (GPT-Image, Gemini). These images contain typical local detail issues — misrendered text on products, blurry faces, unclear logos. RefineAnything fixes these issues in the specified regions without altering the surrounding image.

Section 5.6
5.6 Ablation Study
The ablation study validates each design choice by removing one component at a time and measuring the performance drop on RefineEval.
Resolves the VAE Bottleneck
Removing the crop-and-upsample step causes blurry output. Without a full-resolution view, the VAE encoder loses the fine detail in small regions — exactly the problem RefineAnything was built to solve.
Enables Seamless Integration
Removing BCL produces a visible seam at the region boundary — the refined content fails to blend into the surrounding image. BCL is essential for making the paste-back imperceptible.
Provides Semantic Guidance
Removing the Qwen2.5-VL conditioning tokens causes wrong content to appear in the refined region. The VLM encodes what the region should look like — without it, the diffusion model has no semantic anchor.

Table 3: Ablation study quantitative results. Removing each component (Focus-and-Refine, Boundary Consistency Loss, VLM conditioning) causes a measurable drop in performance, validating all three design choices.


Section 6
6. Conclusion
RefineAnything introduces region-specific image refinement as a dedicated research problem and delivers the first practical system for it. The Focus-and-Refine strategy resolves the VAE resolution bottleneck that causes local detail collapse. The Boundary Consistency Loss enables seamless integration of the refined region. Refine-30K and RefineEval provide the training and evaluation infrastructure needed for the research community.
Results on RefineEval consistently outperform all baselines in both reference-based and reference-free settings, across text, logo, and face detail recovery. As frontier image generation models (GPT-Image, Gemini) improve overall quality, region-specific refinement fills the gap for local detail — enabling truly production-ready AI-generated images.
References (click to expand)
- Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022.
- Black Forest Labs. FLUX. 2024. https://blackforestlabs.ai/
- OpenAI. GPT-Image-1. 2025.
- Google DeepMind. Gemini Image Generation. 2025.
- Brooks et al. InstructPix2Pix: Learning to Follow Image Editing Instructions. CVPR 2023.
- Meng et al. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. ICLR 2022.
- Bai et al. Qwen2.5-VL Technical Report. 2025.
- Zhou et al. RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details. arXiv:2604.06870, 2026.