The FORGE Benchmark
Dataset Overview
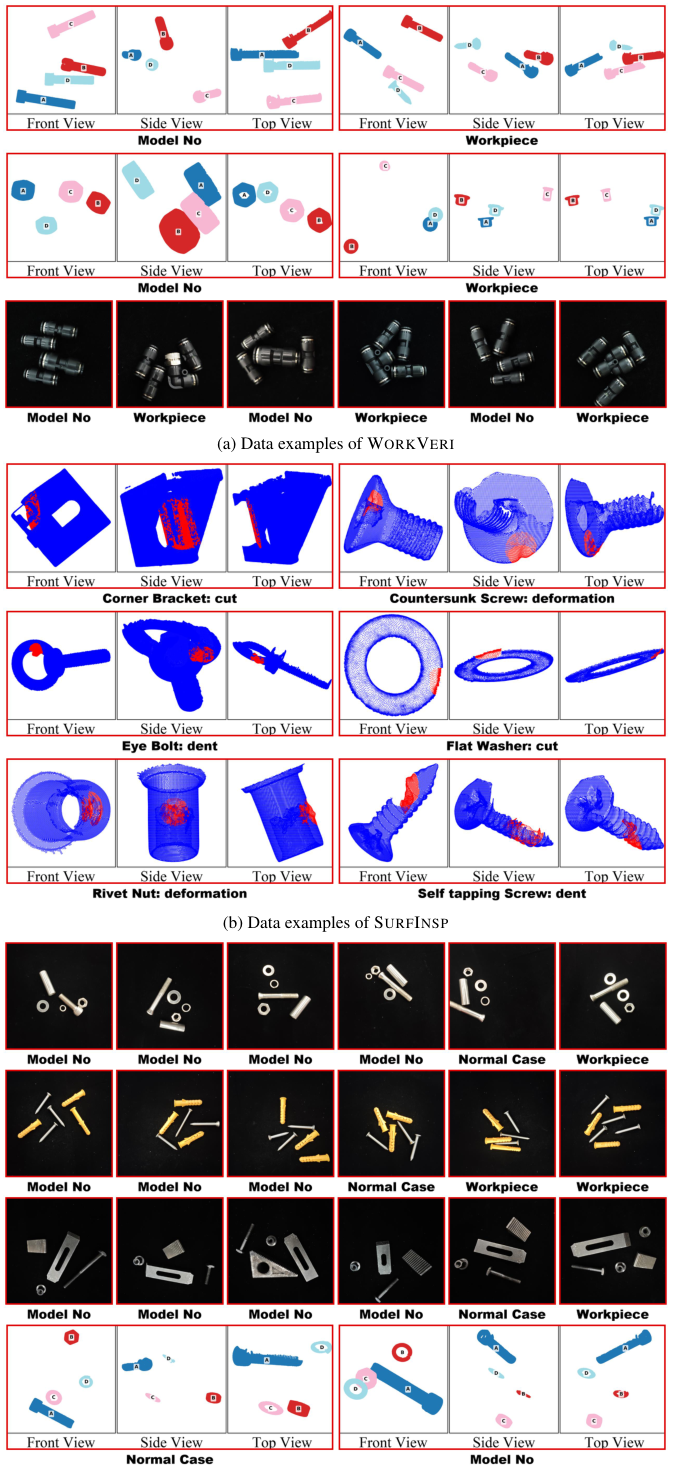
FORGE contains 12,972 samples spanning a diverse range of manufacturing workpieces — bolts, screws, brackets, gears, and assemblies. Each sample combines a 2D image with a 3D point cloud captured from the same physical part, giving models complementary visual information at different scales and modalities.
Crucially, annotations go beyond coarse categories. Each sample is labeled with the exact model number of the workpiece — the fine-grained identifier that manufacturing quality control actually depends on. This is what distinguishes FORGE from all prior benchmarks, and it's the property that reveals the domain knowledge gap in current MLLMs.
Three Manufacturing Tasks
FORGE defines three tasks that mirror the core cognitive challenges in manufacturing quality control. Each task requires a different combination of visual and linguistic reasoning capabilities:
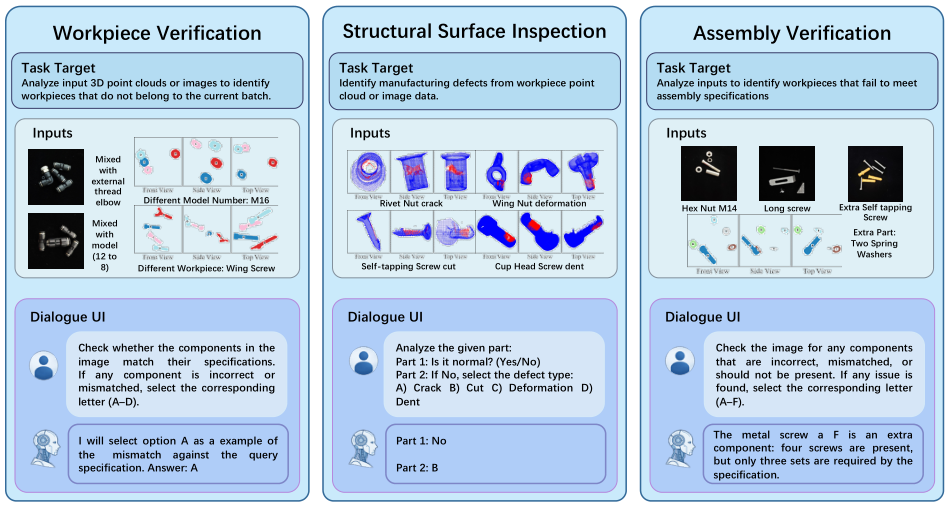
Workpiece Verification
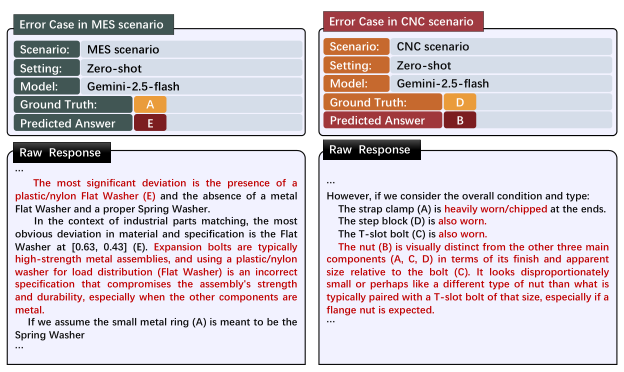
Given three-view images of a workpiece, determine if it is defective and identify the defect type. Tests fine-grained morphology understanding and knowledge of what defects look like on specific part types.
Structural Surface Inspection
Detect surface defects (cracks, dents, corrosion) from 2D images at microscopic scale. The hardest task — requires detecting subtle visual anomalies that challenge even expert human inspectors.
Assembly Verification
Determine whether multiple components are correctly assembled. Requires spatial reasoning about component relationships and understanding of how parts should fit together.
Evaluation Settings
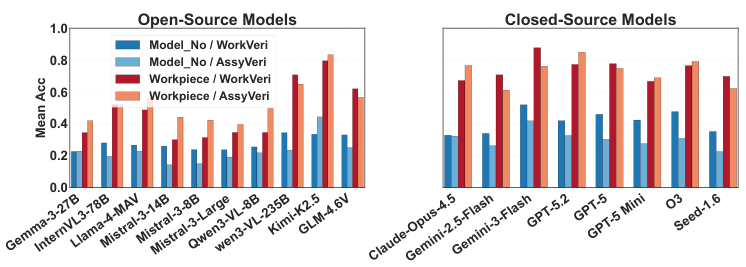
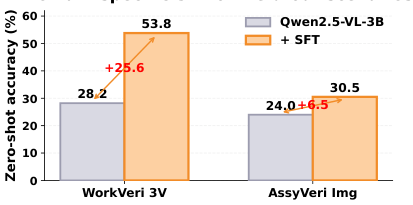
FORGE evaluates MLLMs across four settings: Zero-Shot (standard single image), Reference-Conditioned (Ref-Cond) (model given reference image of correct part), In-Context Demonstration (ICD) (few-shot examples), and Three-View (3V) (multi-angle images from 3D scanner).
Two input granularity levels are tested: model-level (identify exact model number) and workpiece-level (identify part category only). The gap between these two levels quantifies the fine-grained recognition challenge.