Game Agent Interfaces
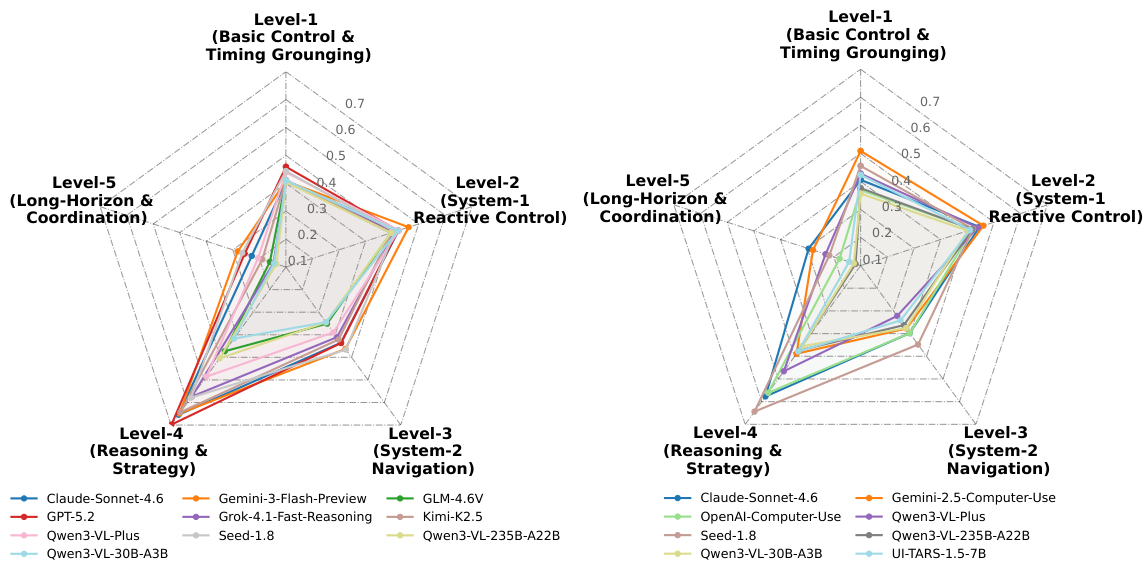
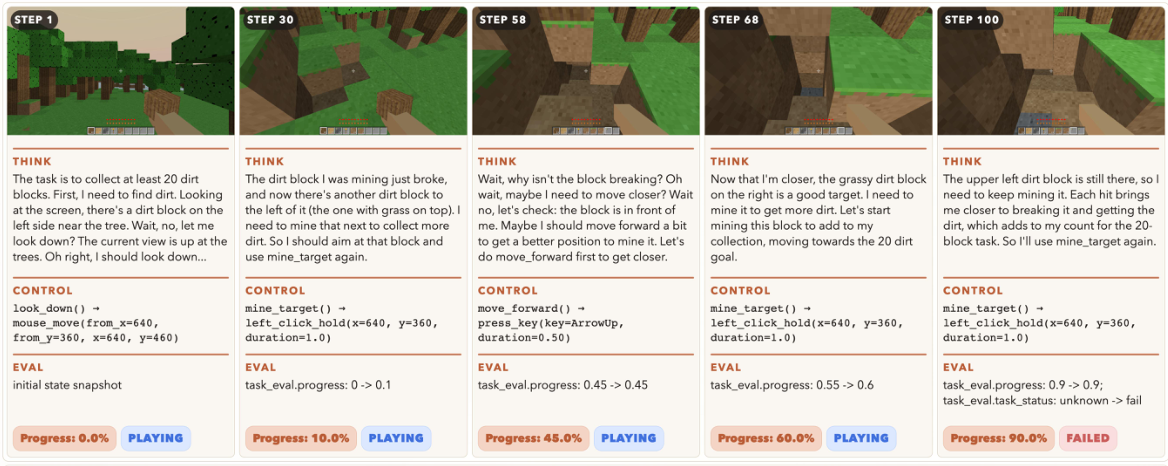
GameWorld studies two distinct approaches to controlling game agents. At each step, the agent observes a screenshot of the current game state, produces an action through the model, and the environment executes it. A verifiable evaluator then checks the resulting state against the task objective.
Computer-Use Agent (CUA)
Directly emits low-level keyboard and mouse controls, acting like a human operating a computer. The model must translate its game understanding into precise physical inputs.
- Actions: mouse click, scroll, key press, drag, text entry
- Requires pixel-level understanding of UI elements
- More general but less precise for game-specific tasks
Generalist Agent (GEN)
Uses semantic, game-specific function calls (e.g., move_forward(), action_jump()). Actions are deterministically parsed into low-level controls via Semantic Action Parsing.
- Actions: game-specific semantic functions like
move_right(),weapon_fire() - Semantic actions are deterministically mapped to controls
- More precise for game tasks, but requires action space definition