2 Method: How SkillClaw Works
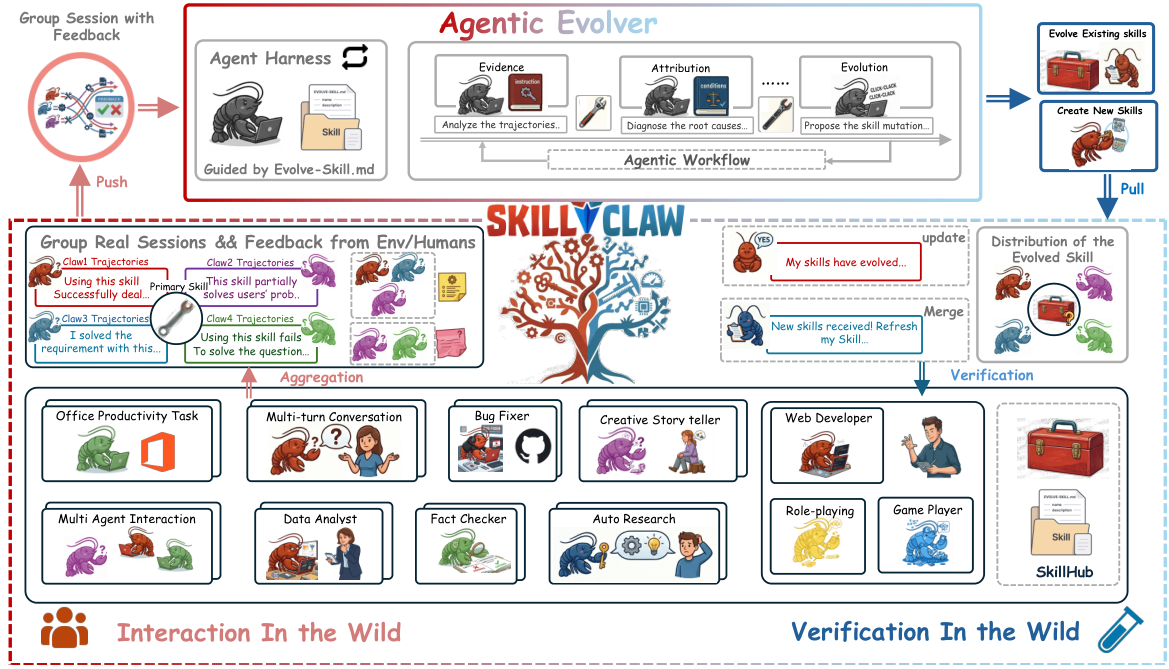
The Three-Stage Evolution Pipeline
Evidence Collection
Multi-user agents generate session trajectories during real-world tasks. Each trajectory captures full action-feedback causal chains. These are continuously aggregated from all users into a shared evidence pool that feeds the Evolver.
Agentic Evolver
Three-stage autonomous pipeline: Evidence (analyze trajectories for recurring patterns and failures) → Attribution (diagnose root causes: skill problem vs. agent problem) → Evolution (propose targeted skill updates). Operates with no human intervention.
Skill Synchronization
Updated skills are stored in the shared SkillHub repository and automatically synchronized to all agents. Improvements discovered from one user's context propagate system-wide. The evolution loop runs continuously as new sessions accumulate.
2.1 From Isolated Sessions to Shared Evidence
Traditional agent systems treat each user session as isolated — the insights from one user's successful or failed interactions never reach other users. SkillClaw transforms this by maintaining a centralized session evidence store. Each time an agent executes a skill, it produces a structured trajectory capturing the full action-observation chain. These trajectories are tagged with the skill that was active and the outcome (success, partial, failure). When enough evidence accumulates about a particular skill, the Agentic Evolver is triggered to analyze the pattern.
What is a "session trajectory"?
A session trajectory is a structured record of everything that happened during one user's interaction with the agent — not just the final result, but the full sequence of: (1) what the agent decided to do, (2) what tool it called with what arguments, (3) what the environment returned (success, error, partial result), and (4) how the agent responded to each feedback signal. Imagine it like a flight data recorder for the agent. This causal chain of action → feedback → next action is crucial because it reveals exactly where and why a skill failed, not just that it failed. SkillClaw aggregates these trajectories across all users to find recurring patterns.
- Example: Agent calls Slack API at port 9100 → Connection refused (error) → Agent retries with heuristic workaround → Partial success. The trajectory reveals that the port in the skill spec is wrong.
- Why cross-user aggregation? One user's trajectory might be noisy or misleading. But if 50 users all show the same failure at the same step, that's a strong signal of a systematic skill bug.
2.2 The Agentic Skill Evolution Algorithm
Input: Skill set S = {s1,...,sn}, Session history H, SkillHub K
Repeat — runs continuously as new sessions arrive:
1. Extract trajectory batch B from session history H
2. Summarize sessions using LLM evolver → extract evidence signals
3. For each skill si ∈ S:
a. Analyze trajectories involving si (Evidence stage)
b. Attribute failures: skill-caused vs. agent-caused (Attribution stage)
c. If skill is the cause: propose update δ(si) (Evolution stage)
d. Apply update: si' = si + δ(si) [if improvement confirmed]
4. Push si' to SkillHub K; broadcast to all agents
Until terminated
Attribution: How does the Evolver tell skill failures from agent failures?
This is the hardest part of the system — and arguably the most important. Not every failure is the skill's fault. Sometimes the agent just reasons poorly, misinterprets the task, or makes a bad decision even with a perfectly good skill. The Attribution stage addresses this by asking: "Was this failure reproducible across multiple users with the same skill, or was it a one-off from this particular agent's reasoning?"
The Evolver uses signals like: (1) Did multiple users fail at the same step in the skill? (2) Did the agent's reasoning deviate from the skill's intended path? (3) Does changing the skill spec fix the failure, or does it persist? If the failure pattern is consistent across users and tied to a specific skill action, it's attributed to the skill. If it varies widely across agents or depends on the specific task context, it's attributed to agent reasoning — and SkillClaw leaves it alone.
2.3 Skill Synchronization and the Evolution Loop
Once the Agentic Evolver proposes a skill update, it is committed to the SkillHub and pushed to all active agent instances. SkillClaw uses a fresh-mode synchronization strategy: agents can opt to receive updates immediately (fresh) or at a stable checkpoint. This design ensures that collectively learned improvements reach all users without disrupting ongoing sessions. The evolution loop is designed to be always-on, meaning SkillClaw continues improving skills as long as agents are being used.

