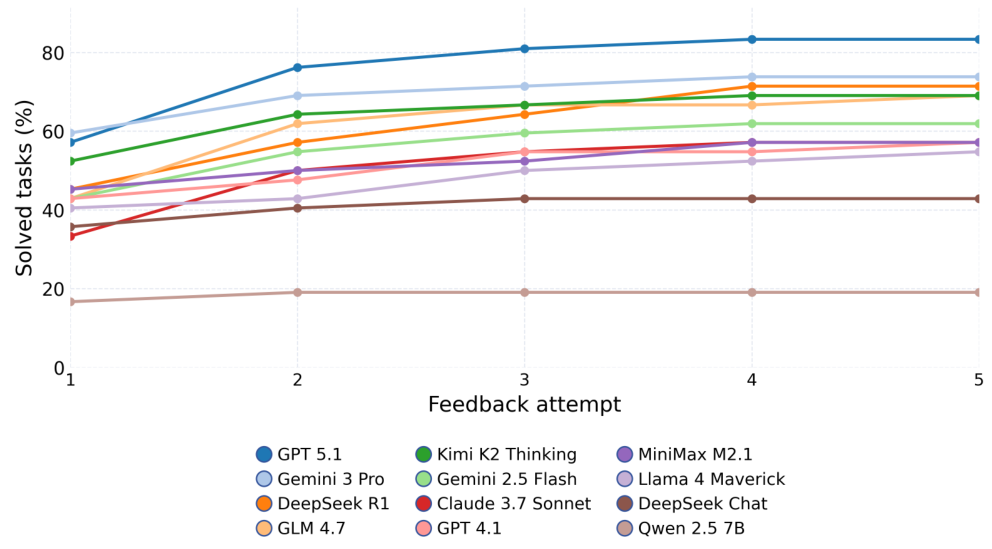
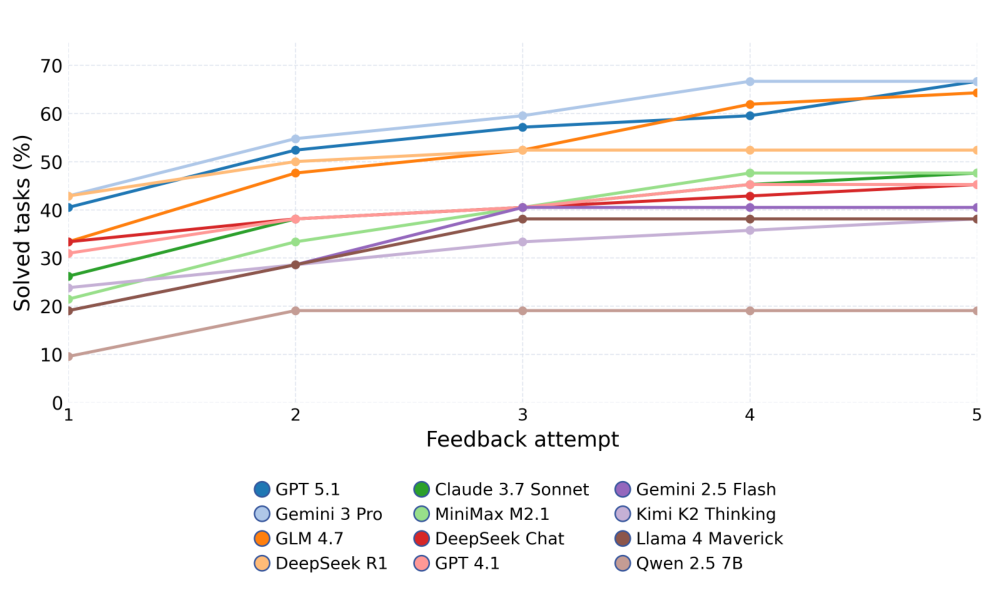
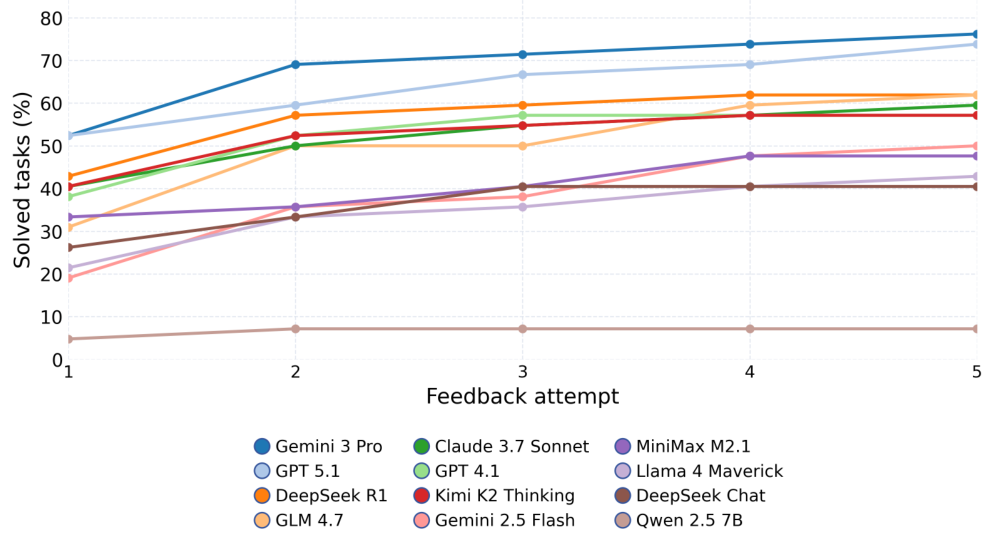
Methodology
Correctness Metrics
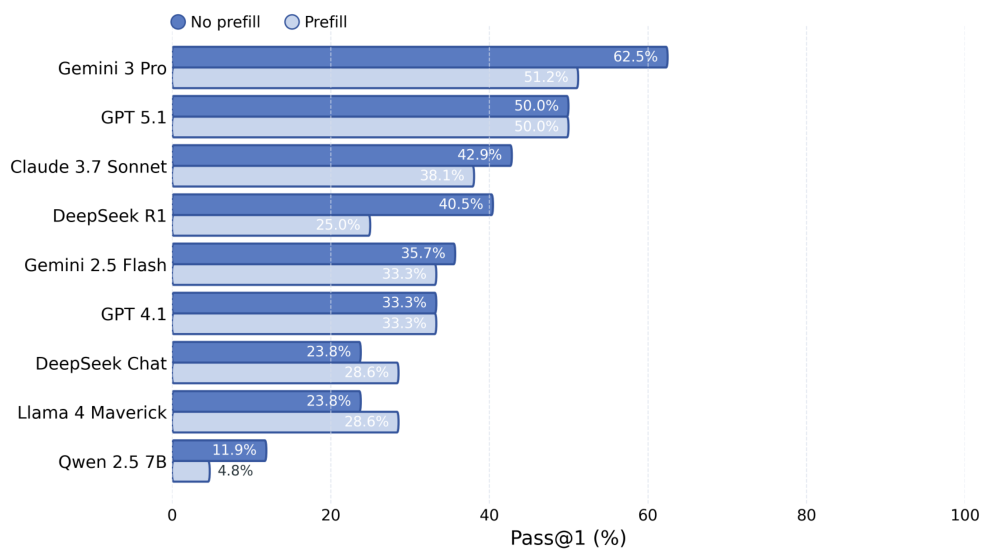
Pass@k measures functional correctness: the model generates k code samples and passes if at least one produces the correct output. Pass@1 tests single-shot accuracy while Pass@5 allows the model five attempts.
KL-Divergence Acceptance handles probabilistic quantum outputs. Since quantum measurements are inherently stochastic, exact output matching doesn't work. Instead, QuanBench+ computes the KL divergence \(D_{KL}(P_{\text{ref}} \| P)\) between the reference distribution and the model's output distribution. If the divergence falls below a threshold \(\tau = 0.05\) (calibrated at the 0.997-quantile of a null distribution), the output is accepted.
KL-Divergence in plain terms
KL-divergence measures how different two probability distributions are. Imagine you have a reference coin that lands heads 60% of the time. If a model's quantum program produces heads 58% of the time, the KL-divergence would be very small (close match). But if it produces heads 90% of the time, the KL-divergence would be large (poor match). QuanBench+ uses a threshold of 0.05 nats — if the difference is below this level, the output is considered correct. This threshold was carefully calibrated: even running the exact same correct program twice produces slight differences due to sampling noise, and the threshold sits just above that natural variation.
Why not fidelity? State fidelity requires access to the full quantum state vector, which is unavailable on real quantum hardware. QuanBench+ deliberately uses measurement-based correctness criteria that would work on actual quantum devices.

Task Categories
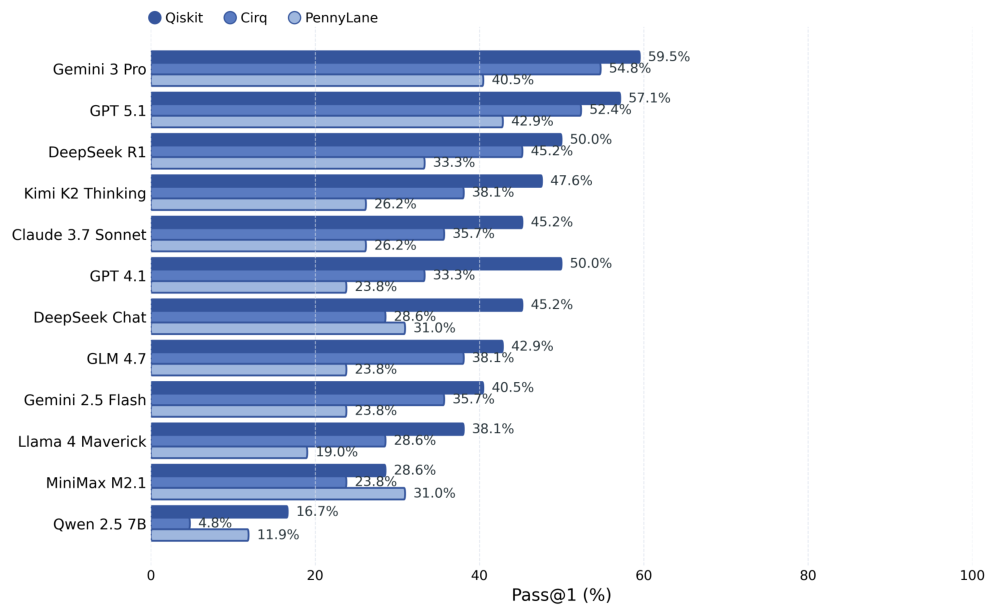
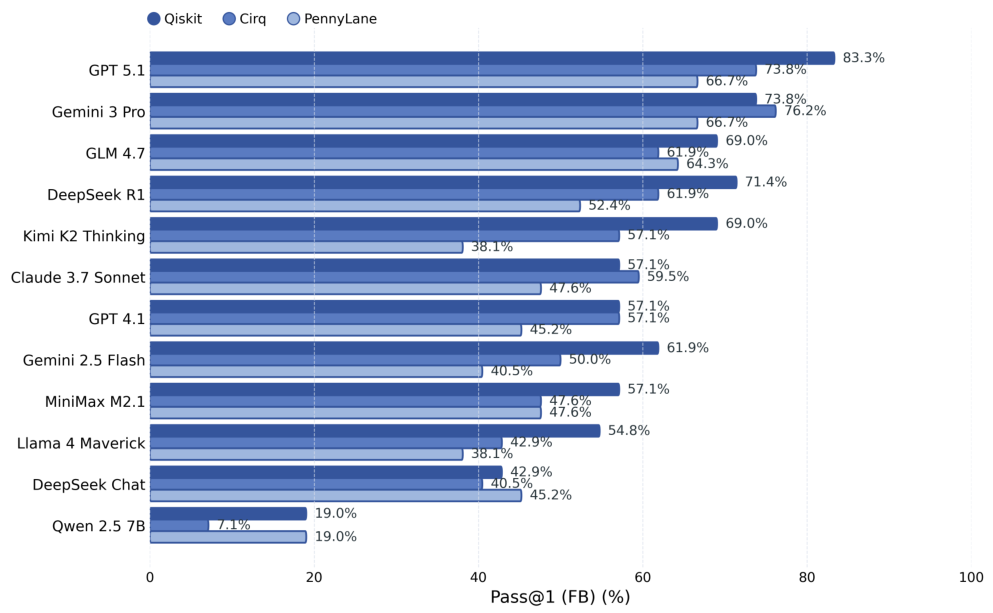
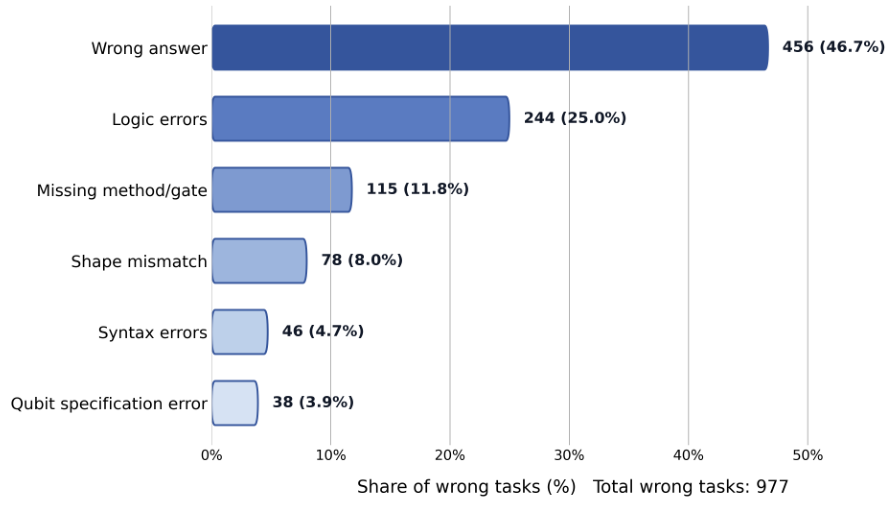
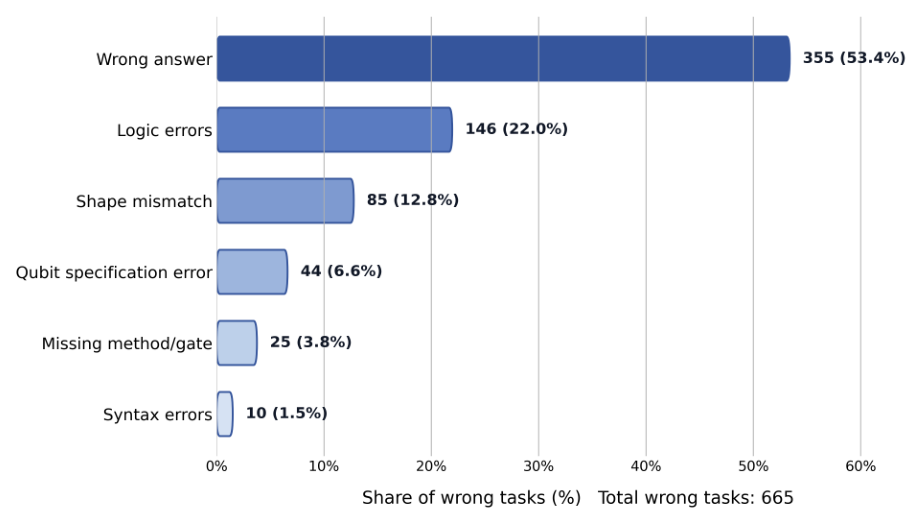
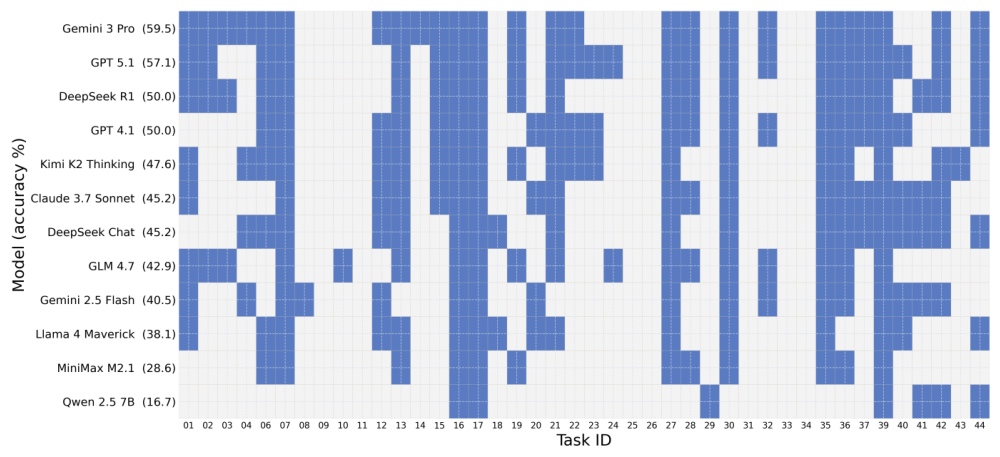
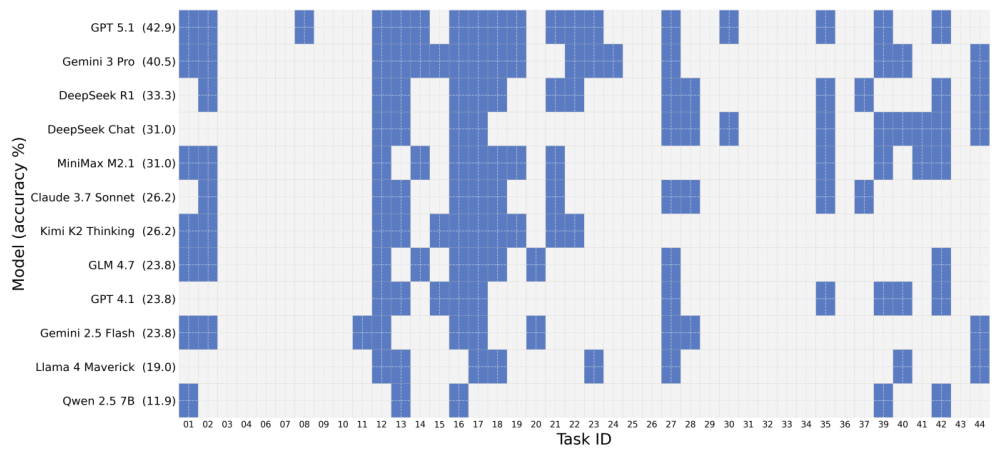
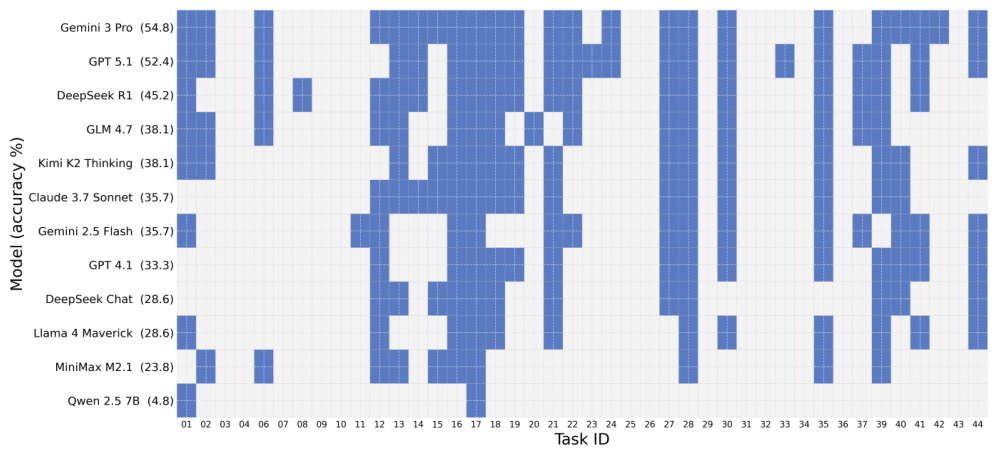
All 42 tasks are aligned across Qiskit, PennyLane, and Cirq with standardized prompts and output normalization. Tasks include classic algorithms like Grover's search, Shor's algorithm, Quantum Fourier Transform, and VQE, as well as gate decomposition challenges and quantum state preparation problems. Each task is evaluated in an isolated sandbox environment with deterministic seed control.