WildDet3D: Scaling Promptable 3D Detection in the Wild
A unified open-vocabulary monocular 3D object detector that accepts any image, any prompt — text, point, or bounding box — and outputs precise 3D bounding boxes, enabling spatial intelligence in the wild.
Allen Institute for AI · University of Washington · Cornell University · UNC-Chapel Hill · Johns Hopkins University
Understanding objects in 3D from a single image is a cornerstone of spatial intelligence. A key step toward this goal is monocular 3D object detection — recovering the extent, location, and orientation of objects from an input RGB image. To be practical in the open world, such a detector must generalize beyond closed-set categories, support diverse prompt modalities, and leverage geometric cues when available. We introduce WildDet3D, a state-of-the-art open-vocabulary monocular 3D detector that unifies text, point, and box prompts in a single geometry-aware architecture. We also introduce WildDet3D-Data, a large-scale in-the-wild dataset with ~1M images across 13.5K categories built via an automated 2D-to-3D pipeline with human and VLM verification. WildDet3D achieves 22.6 AP3D on WildDet3D-Bench — a 10× improvement over the prior best method — and demonstrates strong performance on Omni3D, zero-shot transfer, and real-world deployment on mobile, robotics, and AR/VR platforms.
What is monocular 3D detection? Normally, knowing how far away an object is (depth) requires two cameras (like human eyes) or a depth sensor. Monocular means using just one camera — much harder, since a flat photo loses 3D information. WildDet3D trains on a huge variety of images and learns depth clues from appearance, shadows, and object size to reconstruct 3D bounding boxes (width × height × depth + orientation) from a single photo.
01
Introduction
Understanding objects in 3D is fundamental to spatial intelligence. An agent cannot reliably navigate, manipulate, or reason about the physical world by knowing what objects are alone — it must also understand where they are, how large they are, and how they are oriented in 3D space. This capability lies at the core of robotics, embodied AI, autonomous driving, and AR/VR, where success depends on precise spatial awareness.
Three Requirements for a General-Purpose Monocular 3D Detector
Generalize in the wild — object categories are long-tailed, open-ended, and frequently unseen during training.
Support multiple prompt modalities — text queries, 2D point clicks, 2D bounding boxes, and visual exemplars.
Leverage optional depth cues — incorporate partial or full depth maps from LiDAR, stereo, or ToF sensors when available.
Existing methods fail to satisfy all three requirements simultaneously — they operate on closed-set categories, support only a single prompt type, or ignore depth signals. WildDet3D addresses all three with a unified geometry-aware architecture and a large-scale in-the-wild dataset.
On WildDet3D-Bench — our in-the-wild benchmark spanning 700+ open-vocabulary categories — WildDet3D achieves 22.6 AP3D with text prompts and 24.8 AP3D with box prompts, compared to 2.3 AP for the prior best method (3D-MOOD) — a 10× improvement.
Fig. 1: WildDet3D accepts any image and any prompt (text, point, box) and outputs 3D bounding boxes, enabling deployment on mobile devices, robotics, and AR/VR.
02
WildDet3D Architecture
Given a single RGB image I, optional camera intrinsics K, optional depth map D, and a user prompt P, WildDet3D predicts a set of 3D bounding boxes {Bi} where each box encodes 3D center (metric space), physical dimensions, and orientation. The architecture has three main components.
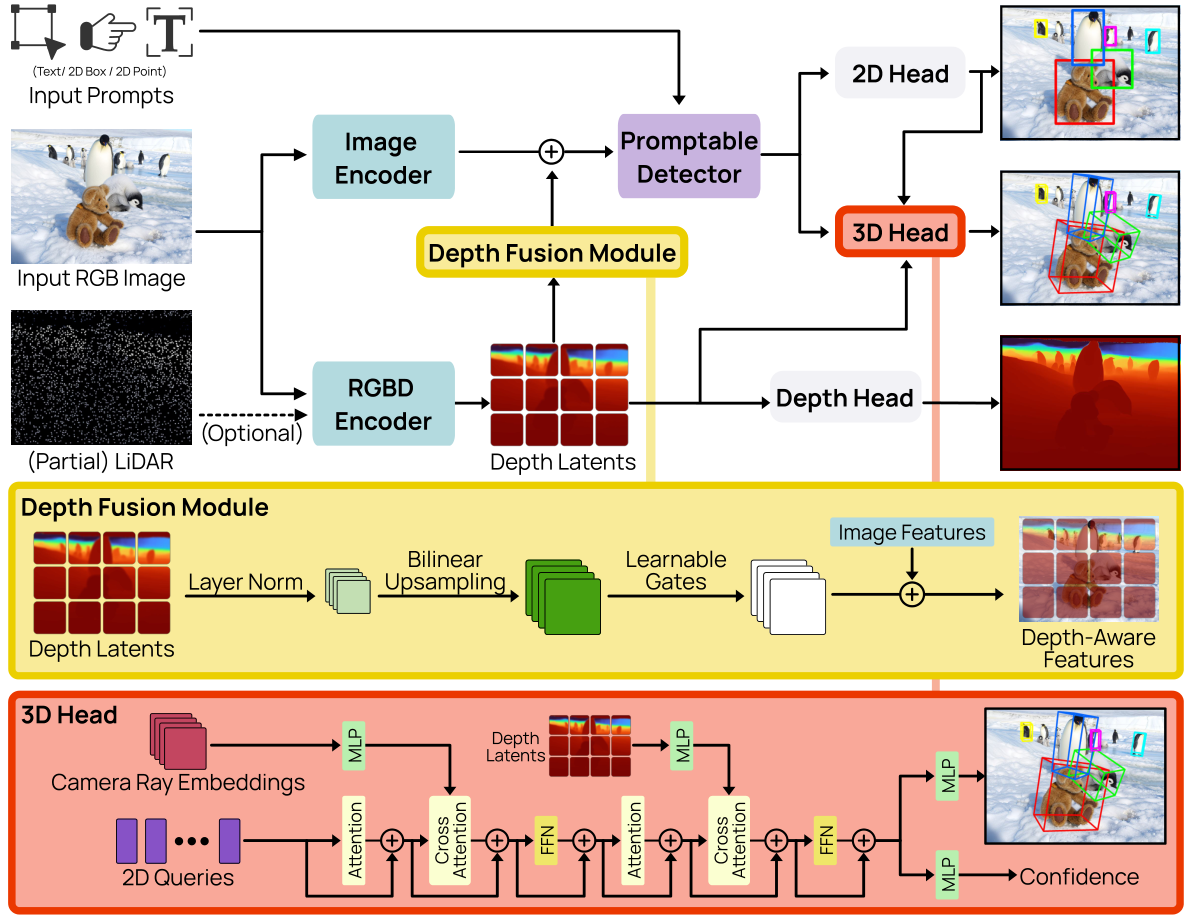
Fig. 3: WildDet3D architecture. (Blue) Dual-vision encoders process RGB and optional RGBD inputs. (Yellow) Depth Fusion Module injects depth latents into image features. (Red) 3D detection head with camera ray embeddings lifts 2D queries to 3D bounding boxes.
Why use two vision encoders? WildDet3D runs two separate neural networks on the same image: a semantic encoder (DINOv2 ViT-L) that recognizes what things are, and a depth encoder (ViT-H) that understands how far they are. Their features are merged via a ControlNet-style "depth fusion" layer. This split lets the model use the best of both worlds — rich object semantics plus geometric depth cues — rather than forcing a single network to handle both tasks.
2.1 Dual-Vision Encoder
🔍
Image Encoder
ViT-H backbone with SimpleFPN neck. Initialized from a segmentation-pretrained checkpoint providing strong dense prediction features. Generates 256-channel P2 feature maps for downstream detection.
📐
RGBD Encoder
DINOv2 ViT-L/14 backbone accepting 4-channel RGBD input at 686×686 resolution. When no depth is available, a zero-filled depth channel is used. Produces depth latents through a ConvStack neck.
⚡
Depth Fusion Module
ControlNet-style residual design that injects depth latents into image features. Zero-initialized so training starts from identity, and depth contribution is gradually learned without disrupting pretrained representations.
Fig. 2: Input modality comparison. LiDAR lacks height/6DoF cues. RGB-only has scale and occlusion ambiguity. RGB + optional Depth provides dense features with accurate metric scale.
2.2 Promptable Detector
The promptable detector conditions depth-aware visual features on user-supplied prompts to produce per-object predictions. It accepts four complementary prompt types, all trained jointly to ensure balanced learning across modalities.
🔤
Text Prompt
A category name (e.g., "car") — selects all instances of that category across the image.
📍
Point Prompt
One or more 2D pixel coordinates (u, v) labeled positive/negative — selects the single object at that location.
⬜
Box Prompt
A 2D bounding box (x1, y1, x2, y2) — selects the single object within the specified 2D region.
🖼️
Exemplar Prompt
A 2D bounding box as a visual reference — detects all visually similar objects across the scene.
2.3 Deeply-Supervised 3D Detection Head
The 3D detection head lifts 2D query features into 3D bounding-box predictions via L Transformer decoder layers. Each layer applies deep supervision — losses are computed at every layer — encouraging early convergence and better feature utilization.
12-Dimensional 3D Box Encoding
Each predicted 3D box is parameterized as a 12D vector:
Components: (Δc_x, Δc_y) center offset; (d̃) log-depth; (w̃, h̃, l̃) log-dimensions; (r1…r6) 6D rotation (Gram-Schmidt orthogonalized). An unambiguous rotation normalization resolves the inherent 4-fold symmetry of oriented 3D boxes. A separate 3D confidence branch predicts a quality score combining depth accuracy and 3D IoU.
2.4 Multi-Task Learning
Training aggregates four loss components. One-to-many matching (k=4) provides dense supervision. An ignore-region mechanism handles non-exhaustive 3D annotations gracefully.
\(\mathcal{L}_{3D}\)3D regression (L1)
\(\mathcal{L}_{conf}\)3D confidence (focal BCE)
\(\mathcal{L}_{geom}\)Depth & camera estimation
\(\mathcal{L}_{2D}\)2D detection (IoU + L1)
03
WildDet3D-Data — 1M+ In-the-Wild 3D Annotations
Existing 3D detection datasets cover fewer than 100 categories and narrow domains. WildDet3D-Data breaks this ceiling: over 1M images across 22 scene categories, 3.7M valid 3D annotations, and 13.5K object categories — a 138× increase in category coverage over Omni3D. Built via an automated 2D-to-3D pipeline with both human and VLM verification.
1,003,886Training Images
3.7M+3D Annotations
13,499Object Categories
22Scene Categories
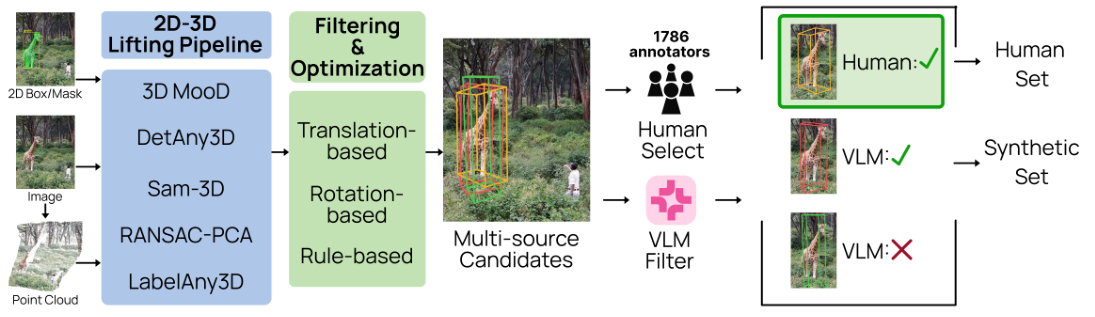
Fig. 4: WildDet3D-Data construction pipeline. Five complementary models generate candidate 3D boxes from 2D annotations, followed by rule-based filtering and dual-path selection (human annotation + VLM-based automatic).
Three-Stage Construction Pipeline
1
Candidate Generation
Five complementary methods (3D-MOOD, DetAny3D, SAM-3D, RANSAC-PCA, LabelAny3D) generate candidate 3D boxes from 2D annotations. MoGe-2 estimates metric depth; PerspectiveFields and WildCamera estimate camera pose and intrinsics.
→
2
Rule-Based & VLM Filtering
Edge contact, occlusion, and projection ratio filters. VLM-based (Qwen3.5-9B) depicted object and composite image filters. LLM-estimated (GPT-4.1-mini) size and geometry plausibility filters.
→
3
Candidate Selection
Human Set (~100K, Prolific annotators): crowdsourced annotators select best candidate from 4 viewpoints. Synthetic Set (~896K): Qwen3.5-9B VLM auto-selects valid annotations, verified by GPT-4.1-mini size checks.
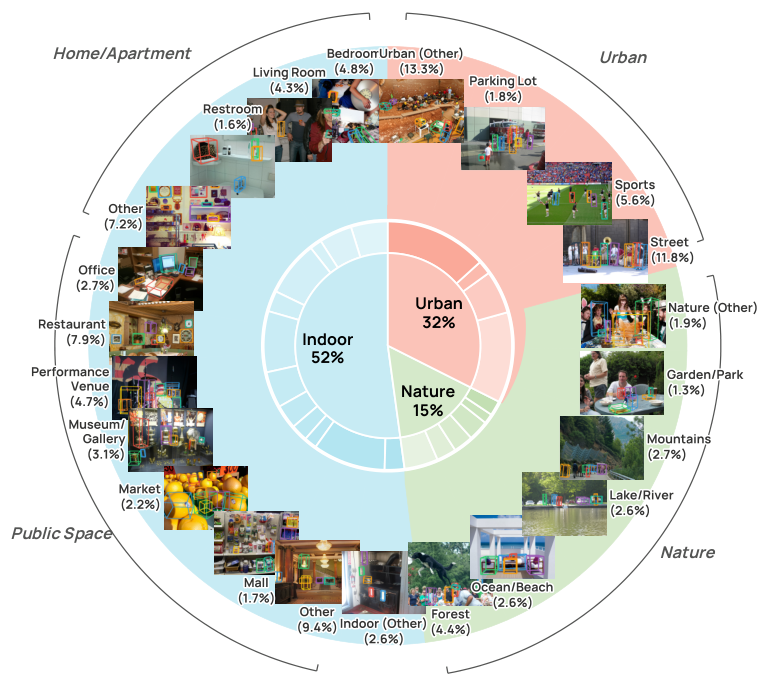
Fig. 6: Scene distribution in WildDet3D-Data. Indoor (52%), Urban (32%), Nature (15%), and Public Space, spanning 22 fine-grained scene categories.
Broad Scene Coverage
The dataset spans unprecedented visual diversity across four major scene domains:
Indoor (52%) — homes, kitchens, offices, gyms
Urban (32%) — streets, markets, landmarks, construction sites
Nature (15%) — wildlife, landscapes, forests
Public Space — parks, sports venues, transportation hubs
Fig. 5: Qualitative examples from WildDet3D-Data showing diverse scenes — indoor environments, outdoor markets, animal wildlife, street sports — each with 3D bounding box annotations (category labels in pink/green).
04
Experiments
What is AP3D? AP3D (Average Precision for 3D detection) measures how accurately a model predicts 3D bounding boxes. Unlike standard 2D AP, it requires the predicted box to match the ground truth in all six dimensions — position (x, y, z), size (width, height, depth), and orientation — before counting as a correct detection. A score of 22.6 AP3D vs. the previous best of 2.3 AP3D represents roughly a 10× improvement in genuine spatial understanding.
WildDet3D achieves a 10× improvement over the prior state-of-the-art 3D-MOOD on the WildDet3D-Bench benchmark, with the largest gains on rare categories (APrare = 47.4 vs 2.4 for 3D-MOOD), demonstrating strong generalization to novel object classes.
4.2 WildDet3D-Bench — In-the-Wild Evaluation
WildDet3D-Bench is our proposed in-the-wild benchmark covering 700+ open-vocabulary categories with human-verified 3D annotations. Categories are split by frequency into rare, common, and frequent splits. Providing GT depth at test time dramatically improves performance (22.6 → 41.6 AP3D).
Method
Training Data
APrare
APcommon
APfreq
AP3D
3D-MOOD
Omni3D
2.4
2.1
2.6
2.3
WildDet3D (text)
Omni3D
9.0
6.5
5.2
6.8
WildDet3D (text, +GT depth)
Omni3D
23.0
21.5
16.1
20.7
WildDet3D (text)
Omni3D + Others + WildDet3D-Data
28.3
21.6
18.7
22.6
WildDet3D (text, +GT depth)
Omni3D + Others + WildDet3D-Data
47.4
40.7
37.2
41.6
WildDet3D (box)
Omni3D + Others + WildDet3D-Data
30.0
24.2
20.3
24.8
WildDet3D (box, +GT depth)
Omni3D + Others + WildDet3D-Data
53.7
46.1
42.5
47.2
Table: WildDet3D-Bench evaluation. WildDet3D trained on the full dataset achieves 22.6 AP3D (text), 24.8 AP3D (box), and 41.6/47.2 with GT depth — dramatically surpassing prior methods.
4.3 Omni3D Standard Benchmark
On the standard Omni3D benchmark (6 datasets: KITTI, nuScenes, SUNRGBD, Hypersim, ARKitScenes, Objectron), WildDet3D achieves 34.2 AP3D with text prompts and 36.4 AP3D with box prompts — surpassing 3D-MOOD (28.4 AP) by +5.8 AP using 10× fewer training epochs (12 vs. 120 epochs). With real depth, oracle performance reaches 45.8 AP3D.
4.4 Zero-Shot Generalization
Trained on Omni3D and tested zero-shot on Argoverse 2 (outdoor, 26 classes) and ScanNet (indoor, 18 classes), WildDet3D achieves 40.3 ODS on AV2 and 48.9 ODS on ScanNet — outperforming 3D-MOOD Swin-B by +16.5 and +17.4 ODS respectively. The model also achieves best orientation estimation, showing strong 3D understanding of novel domains.
Fig. 8: Zero-shot comparison between WildDet3D and 3D-MOOD on unseen categories (Car/SUV, Frog, Stapler, Bear). WildDet3D correctly localizes diverse 3D objects across varied viewpoints.
4.5 Evaluation with Real Depth Sensors
Fig. 10: WildDet3D with real depth sensor input on indoor scenes. Yellow 3D bounding boxes accurately localize furniture and equipment with precise metric extent.
4.7 Qualitative Results
Fig. 7: Qualitative comparison — WildDet3D (orange) vs OVMono3D (green) vs DetAny3D (orange/green) on four diverse scenes. WildDet3D produces tighter, more accurate 3D bounding boxes that better match ground truth (purple).
05
Applications
WildDet3D serves as a general-purpose 3D perception module deployable across diverse real-world platforms — from smartphones to robots to AR headsets.
📱
iPhone App
WildDet3D runs on iPhone via a client-server architecture, enabling real-time in-the-wild 3D detection from the camera. Users draw a 2D box or use text to detect any object in 3D. Available on the App Store.
🤖
Robotic Manipulation
WildDet3D provides precise 3D bounding boxes that robotic controllers use for spatial grounding and grasping. The model acts as a universal perception frontend for robot manipulation tasks.
🥽
AR/VR & Real Depth
Integration with Meta Quest and Meta Glasses for AR spatial anchoring. WildDet3D maps detected objects to 3D space, enabling accurate AR overlay alignment and scene understanding.
Note: The applications shown here (iPhone app, robotics, AR/VR, and language agent) are research prototypes demonstrating the versatility of open-vocabulary 3D detection. They are not production-ready systems. Predictions may contain errors in depth, dimensions, or missed detections. WildDet3D is not intended for safety-critical applications.
WildDet3D-Agent: Language-Guided 3D Detection
By integrating WildDet3D with a vision-language model (Qwen3-VL), we create WildDet3D-Agent — a system that answers natural language queries about 3D spatial content. Given queries like "Find the closest person" or "Which food has the highest calories?", the agent reasons about 3D spatial relationships and highlights the target object.
Fig. 12: WildDet3D-Agent comparison. WildDet3D-Agent (right) correctly grounds language queries into precise 3D localizations — e.g., identifying the closest person, the highest-calorie food, or the most expensive object — outperforming VST and Qwen3-VL baselines.
07
Limitations
Camera Intrinsics:Predicted intrinsics are less accurate than ground-truth calibration, degrading 3D localization especially for absolute depth and physical size estimation in uncalibrated settings.
Monocular Depth Ambiguity:A single image cannot fully resolve metric depth without additional cues. Performance on distant or heavily occluded objects remains limited despite learned depth priors.
Rotation Estimation:Rotation prediction is the weakest component. Objects with near-symmetric geometry (e.g., round tables, square boxes) or limited visible surface area pose particular challenges for orientation estimation.
Intended Use & Safety:The demonstrated applications (iPhone, AR/VR, robotics, language agents) are research prototypes, not production-ready systems. WildDet3D is not intended for safety-critical applications such as autonomous navigation, surgical planning, or structural assessment.
08
Conclusion
We presented WildDet3D — an open-vocabulary monocular 3D object detector that unifies text, point, and box prompts within a single geometry-aware architecture — and WildDet3D-Data, a large-scale in-the-wild dataset spanning 1M images and 13.5K categories with human-verified 3D annotations.
WildDet3D achieves state-of-the-art results across all benchmarks with 6–10× fewer training epochs than prior methods. The combination of dual-vision encoders, flexible prompt support, and large-scale diverse training data enables strong zero-shot generalization to novel domains, objects, and deployment platforms — mobile, robotics, AR/VR, and language agents.
34.2AP3D on Omni3D
10×Fewer Training Epochs
700+In-the-Wild Categories
References
Aichner, R. et al. "nuScenes: A multimodal dataset for autonomous driving." CVPR, 2020.
Bai, J. et al. "Qwen: Technical Report." arXiv:2309.16609, 2023.
Bolya, D. et al. "YOLACT: Real-time Instance Segmentation." ICCV, 2019.
Caesar, H. et al. "nuScenes: A multimodal dataset for autonomous driving." CVPR, 2020.
Cheng, B. et al. "Masked-attention mask transformer for universal image segmentation." CVPR, 2022.
Brazil, G. et al. "Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild." CVPR, 2023.
... (additional references)
B2B Content
Any content, beautifully transformed for your organization
PDFs, videos, web pages — we turn any source material into production-quality content. Rich HTML · Custom slides · Animated video.