Model Architecture & Training
Model Configuration
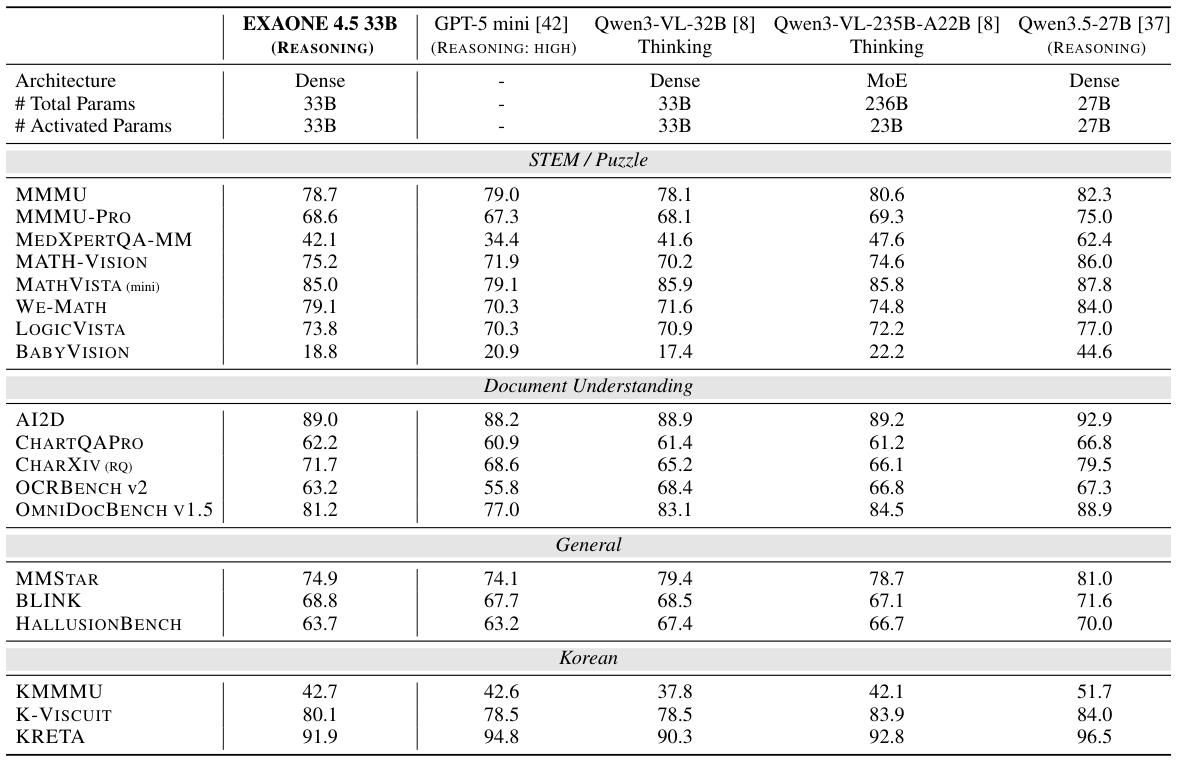
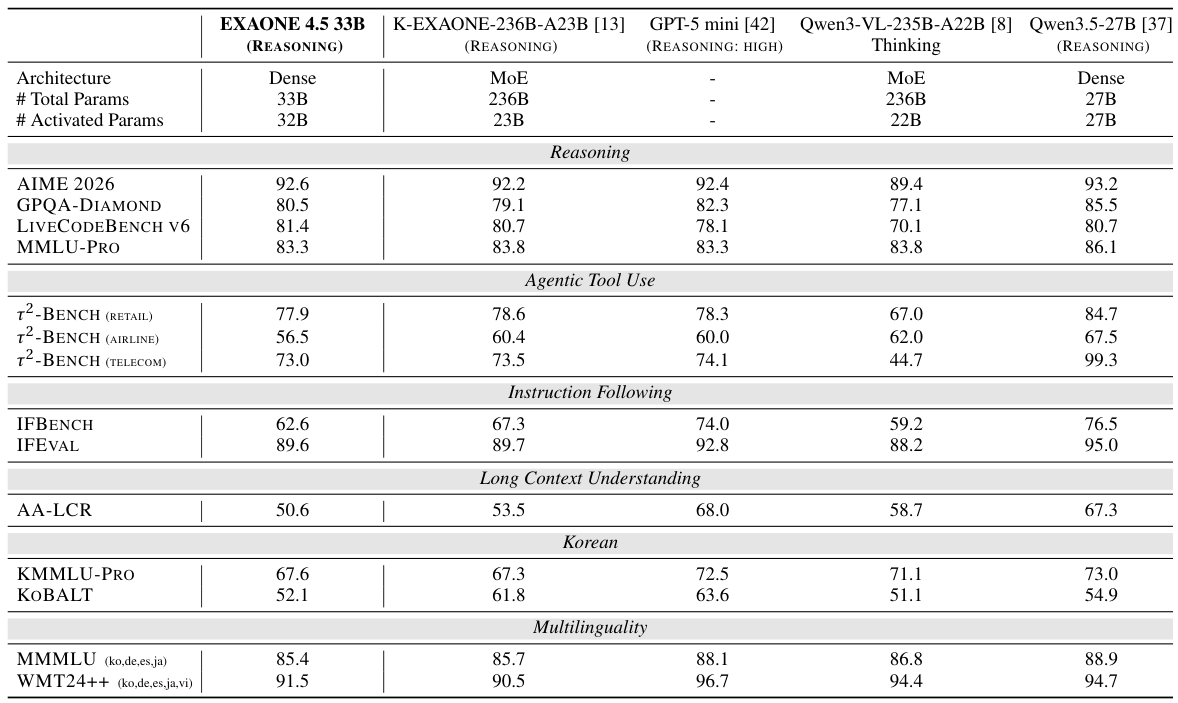
EXAONE 4.5 addresses a core challenge in vision-language models: efficiently processing large numbers of visual tokens alongside text. To maintain computational efficiency, the team adopted hybrid attention mechanisms and Grouped Query Attention (GQA) applied within the vision encoder itself — an innovative choice that substantially reduces the KV-cache memory footprint during inference. The visual encoder was trained from scratch as a 1.2B-parameter model, since existing encoders did not meet LG's requirements for scalability and efficiency. It uses 2D Rotary Position Embedding (2D RoPE) to handle images at their native resolution without resizing, preserving spatial relationships critical for document understanding.
What is GQA (Grouped Query Attention)?
Standard Transformer attention requires storing a separate Key-Value (KV) cache for every attention head — this becomes enormous for large models. Grouped Query Attention (GQA) groups multiple query heads to share one KV cache pair, dramatically reducing memory usage with minimal accuracy loss.
Why does this matter for EXAONE 4.5? Applying GQA to the vision encoder is unusual and innovative. Images generate thousands of visual tokens, so keeping KV-cache small is critical for running the model efficiently on real hardware.
Pre-training
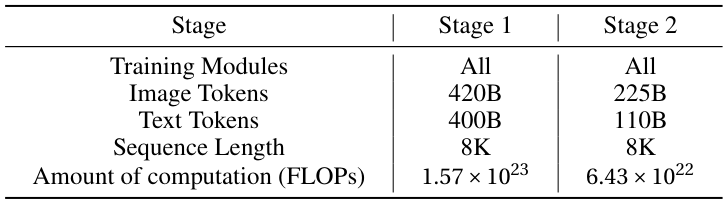
Multimodal pre-training proceeds in two stages. Stage 1 focuses on large-scale visual-linguistic alignment, training on 420B image tokens and 400B text tokens at 8K sequence length. Stage 2 refines with higher-quality data at a reduced scale (225B image tokens, 110B text tokens), using FLOPs of 6.43×10²² compared to Stage 1's 1.57×10²³. The pre-training data spans image captions (Korean-English bilingual), interleaved image-text documents, OCR/document corpora (critical for LG's document-centric focus), and video data for temporal understanding.
Understanding FLOPs in Training Scale
FLOPs (Floating Point Operations) measure the total computation used during training. Stage 1 required 1.57×10²³ FLOPs — roughly equivalent to what a single high-end GPU would need ~5,000 years to compute. This is why LLM training requires hundreds of GPUs running in parallel for weeks.
Stage 2's reduced scale (6.43×10²² FLOPs) reflects that refining a good base model requires far less compute than building it from scratch.
Context Length Extension
EXAONE 4.5 extends context to 256K tokens by integrating length extension directly into the supervised fine-tuning stage rather than as a separate pre-training phase. Starting from a base model already capable of 128K tokens provides stability and fast convergence. Context Parallelism distributes the 256K-length sequences across multiple GPUs, keeping memory requirements manageable. This is especially important for industrial use cases involving long legal documents, technical manuals, or multi-page financial reports.
Why is 256K Context Window Significant?
Most language models cap at 4K–32K tokens. A 256K context window means the model can process roughly 200,000 words in one pass — equivalent to 3–4 full-length novels, or a lengthy legal contract with all its appendices.
For enterprise document AI, this is transformative: financial analysts can feed entire quarterly reports (with footnotes), legal teams can process complete contracts, and engineers can reason over multi-chapter technical manuals — all without chunking or losing context.
Post-training
Supervised Fine-Tuning (SFT)
Rather than relying solely on public datasets, the team constructed a high-quality SFT dataset spanning multiple domains and modalities. This includes domain-specific instruction data for finance, law, science, and Korean-language tasks, as well as multimodal instruction data for document Q&A, chart understanding, and OCR tasks.
Offline Preference Optimization
Offline preference optimization is applied in a multi-stage framework using Direct Preference Optimization (DPO). Each phase targets a specific capability: instruction following, document understanding, and multilingual alignment. The DPO loss encourages the model to prefer higher-quality responses over lower-quality alternatives from a reference model.
Direct Preference Optimization (DPO) Explained
The DPO formula in the paper looks complex, but the core idea is simple: teach the model to prefer better answers by comparing pairs of responses.
For each training example, the model sees a prompt x, a good answer y⁺ (preferred by human raters), and a bad answer y⁻ (rejected). The model learns to increase the probability of generating y⁺ and decrease y⁻, compared to a reference model — without needing a separate reward model like traditional RLHF. This makes training more stable and efficient.
Reinforcement Learning (RL)
Joint multimodal reinforcement learning is applied across both text and vision modalities. Text data covers mathematical reasoning, coding, and science problems. Vision data focuses on diagram understanding, chart Q&A, and document interpretation. RL helps the model develop robust reasoning that generalizes across input types.