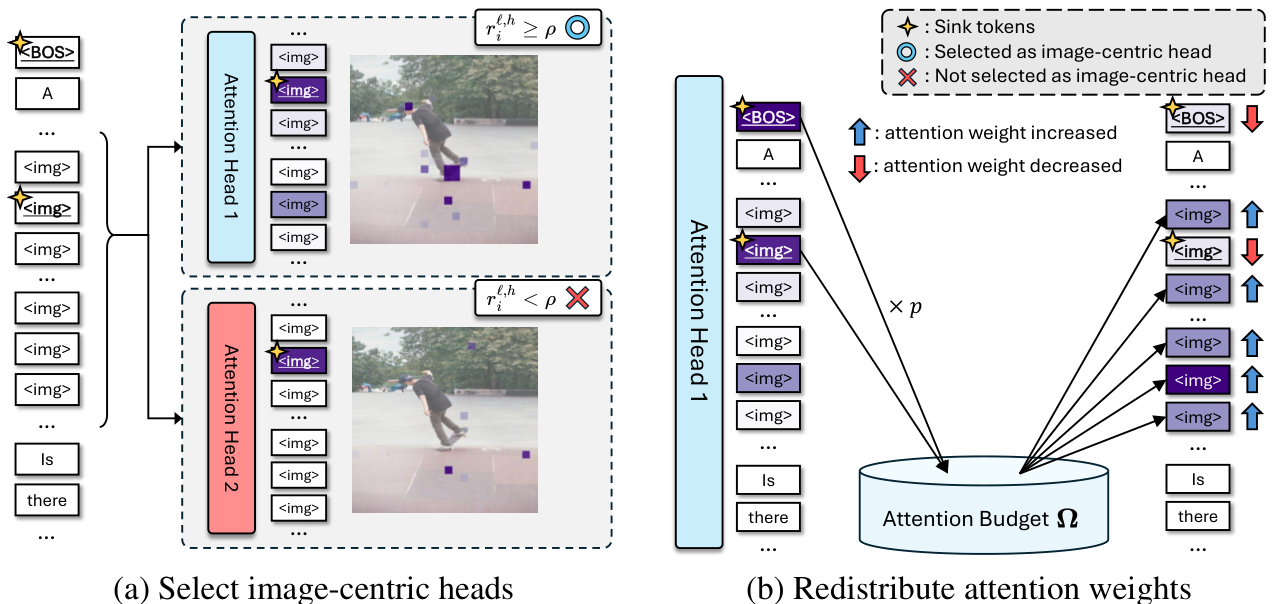
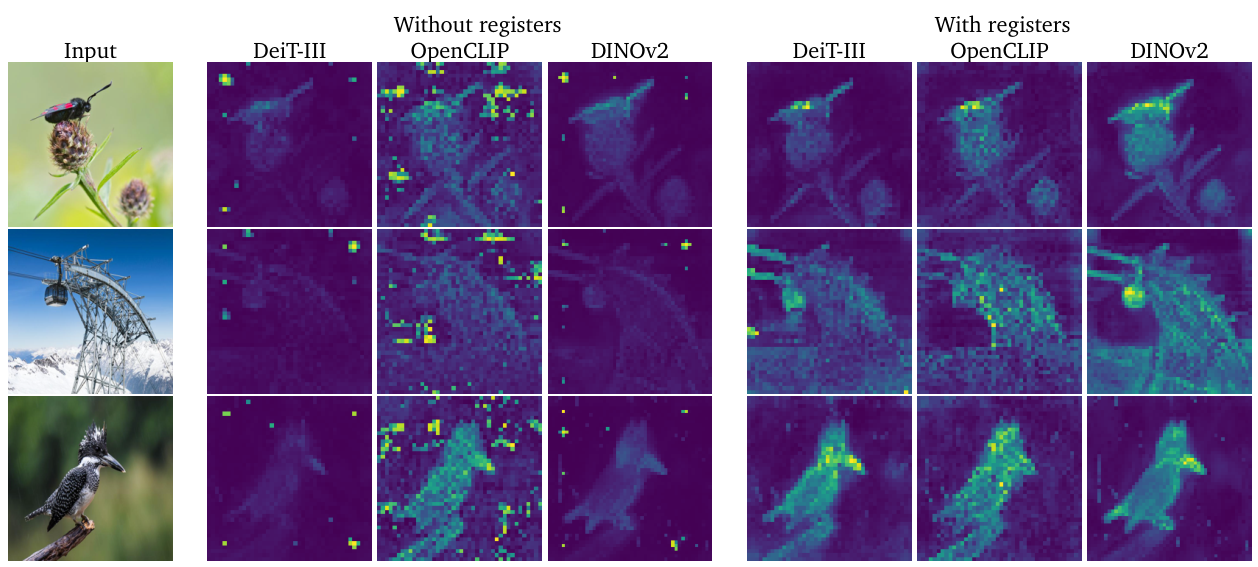
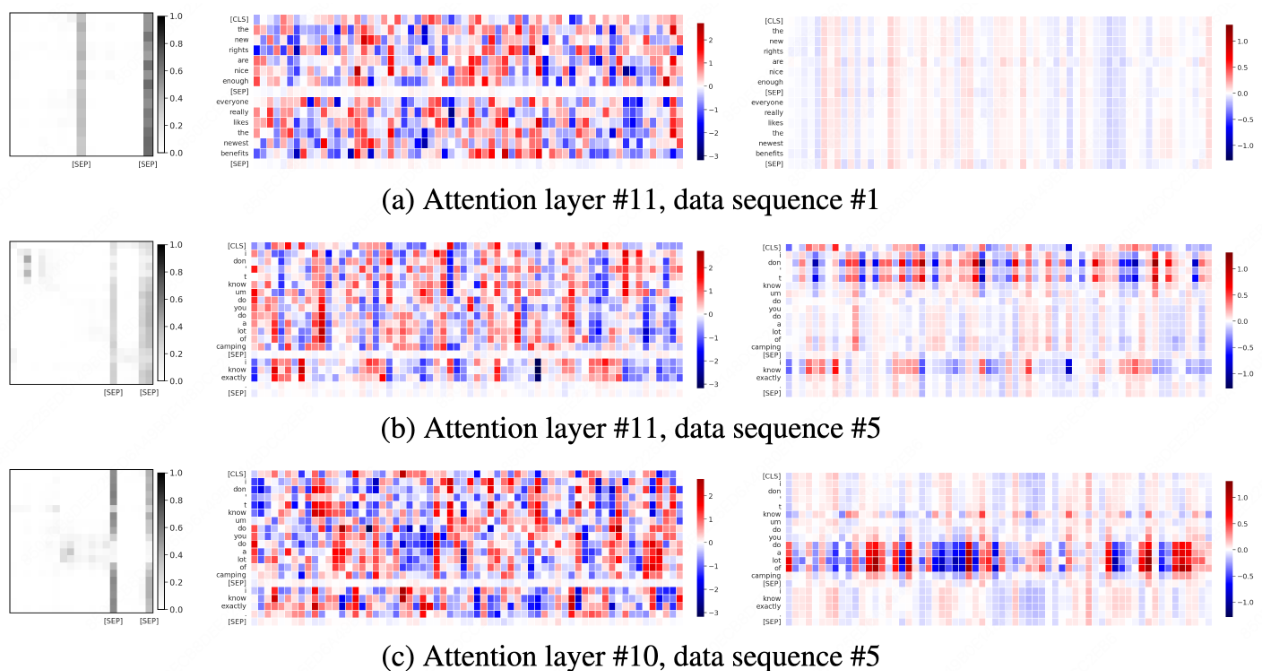
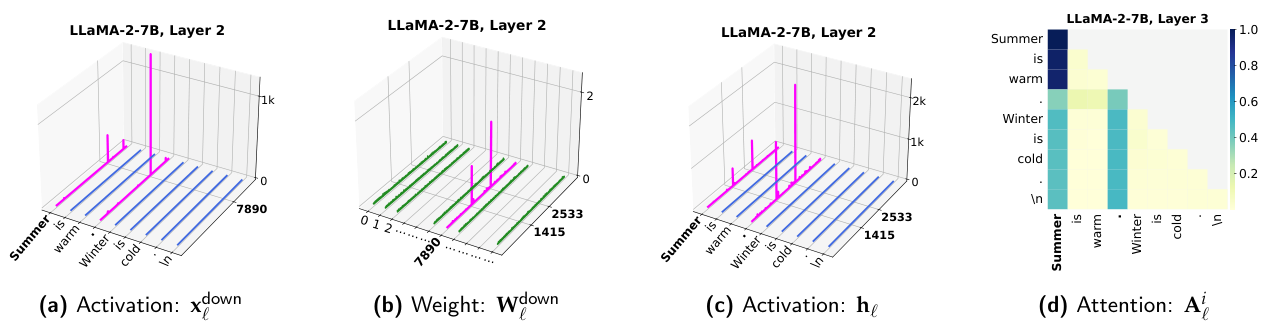
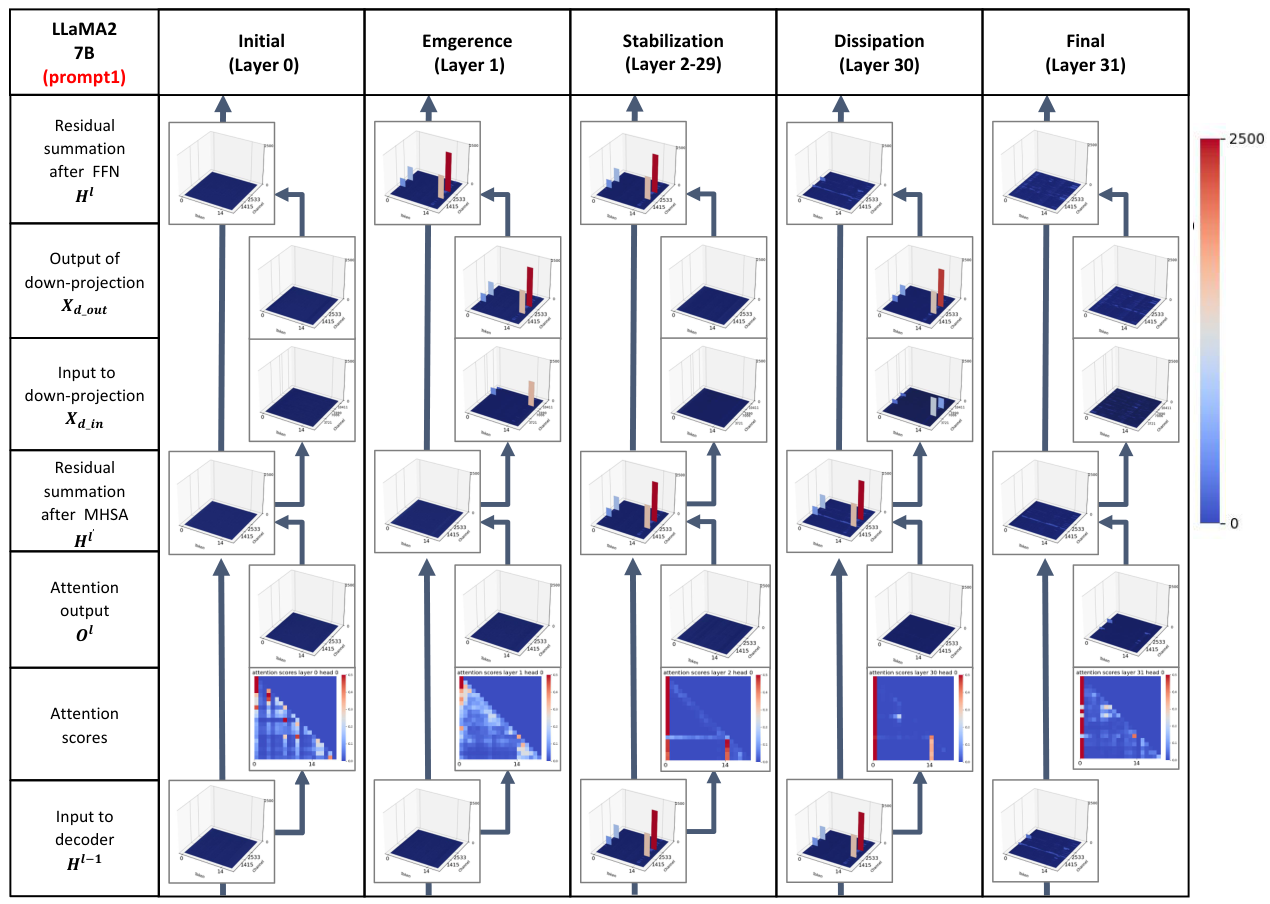
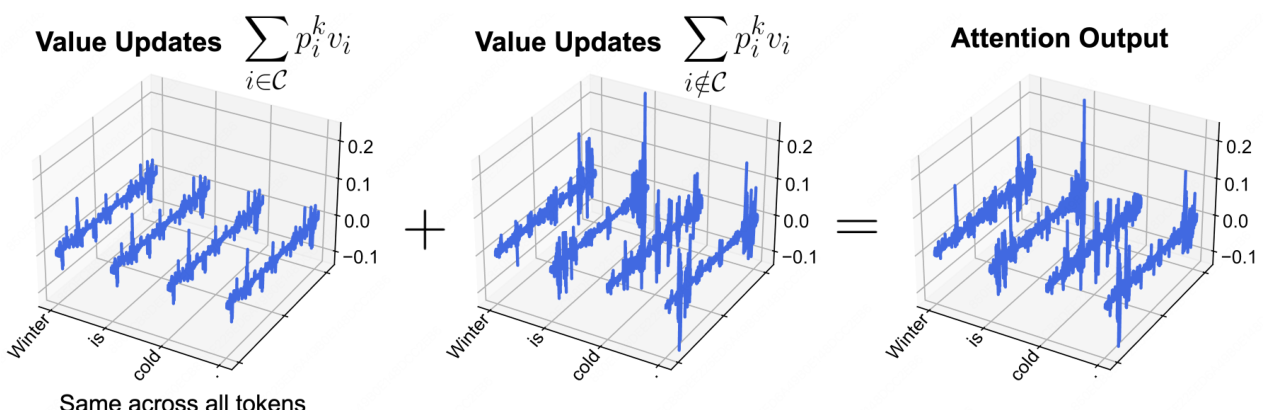
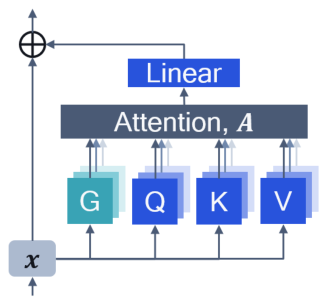
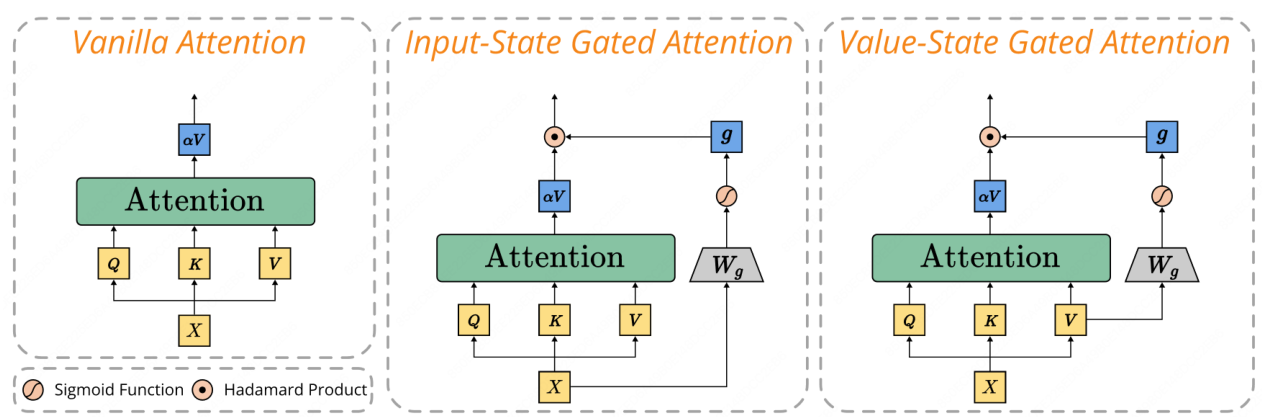
Survey Overview
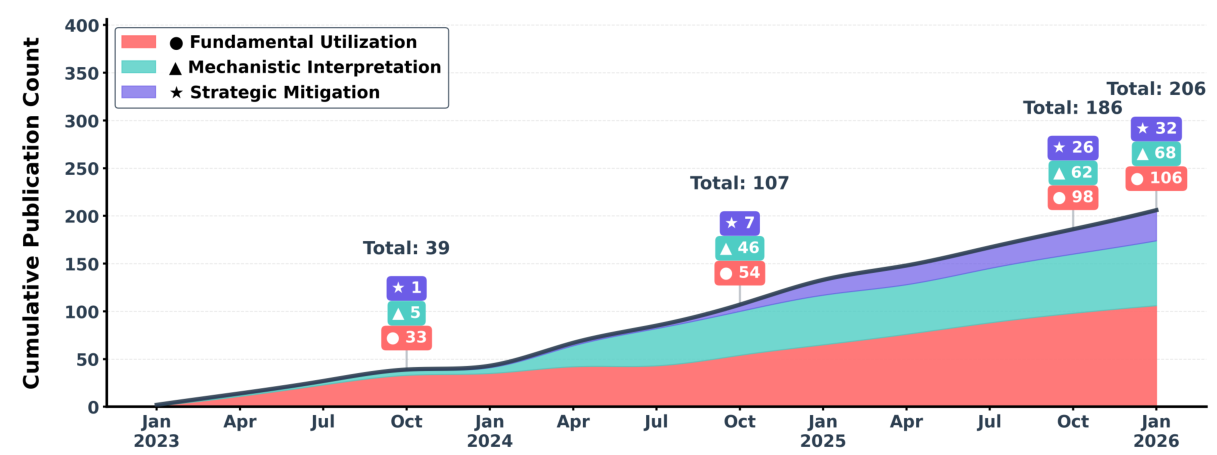
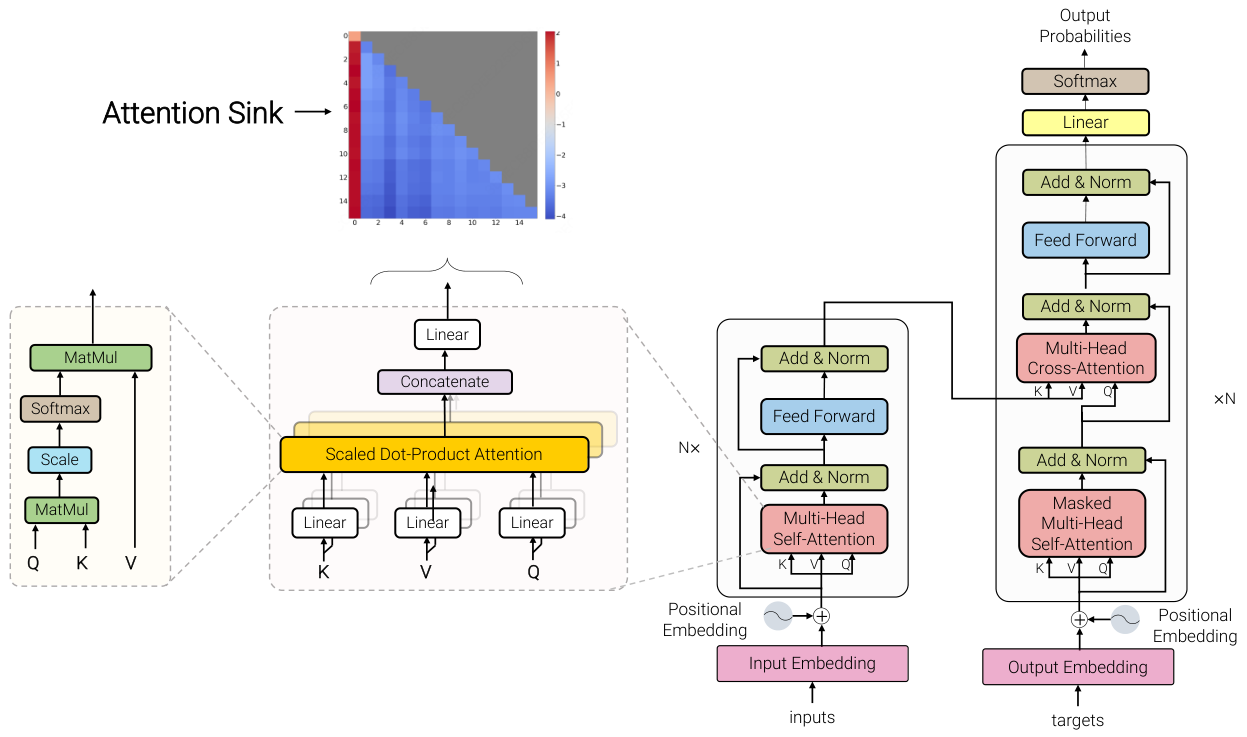
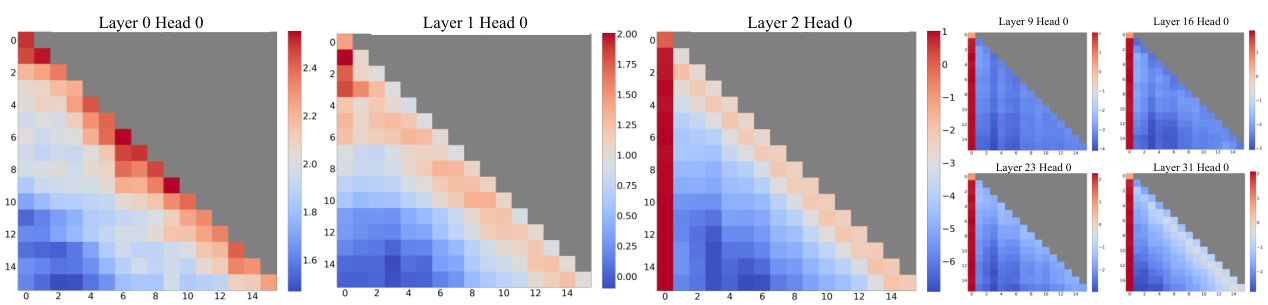
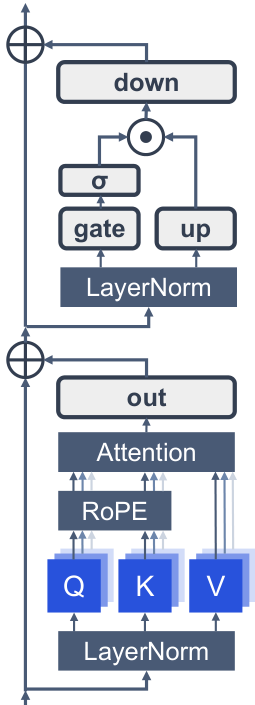
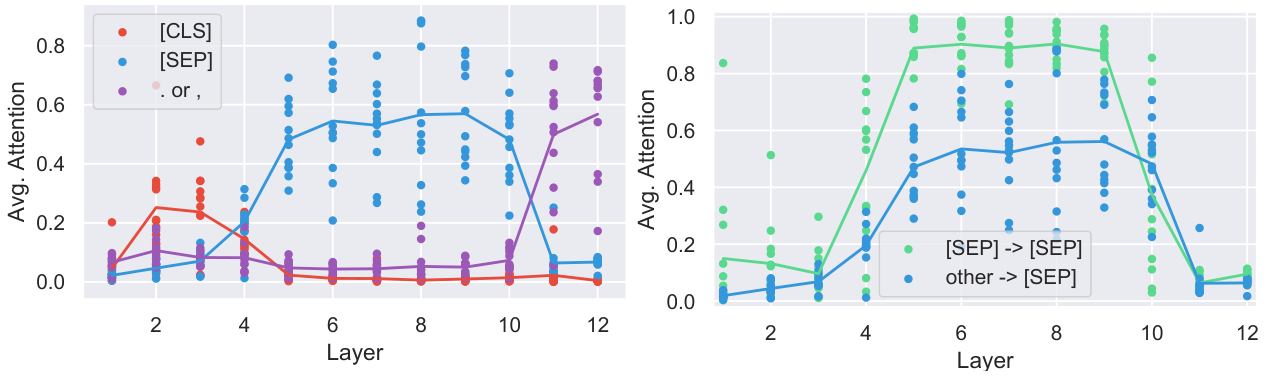
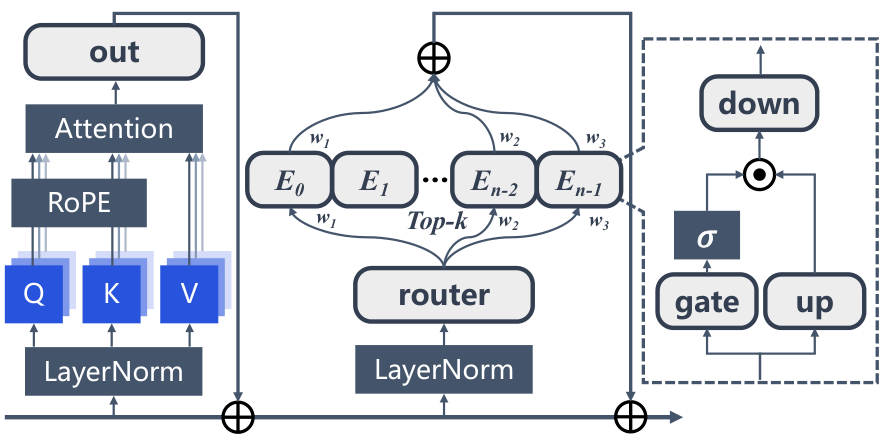
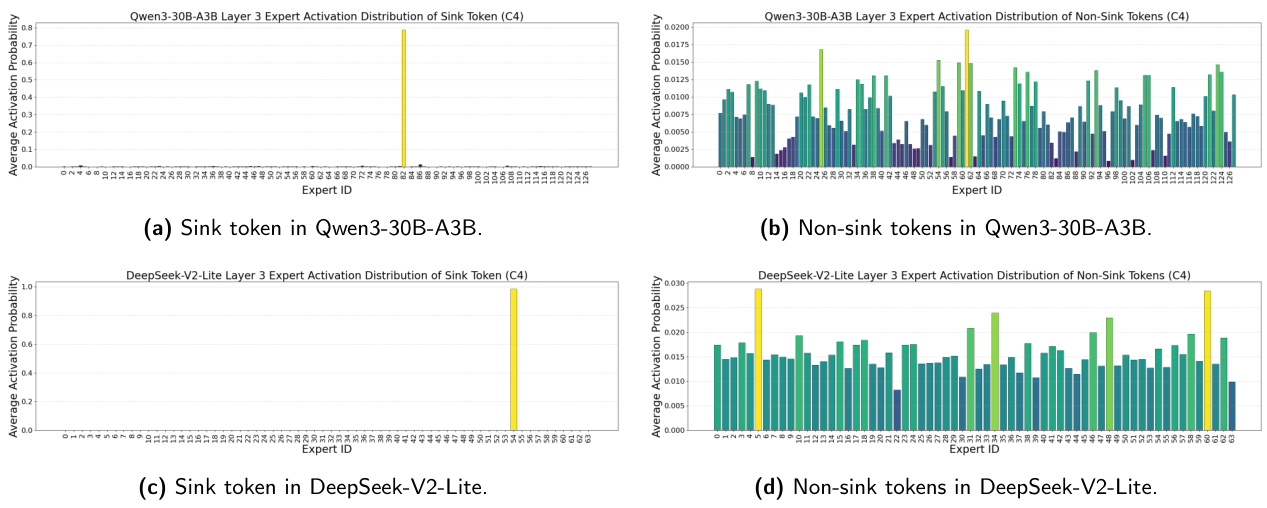
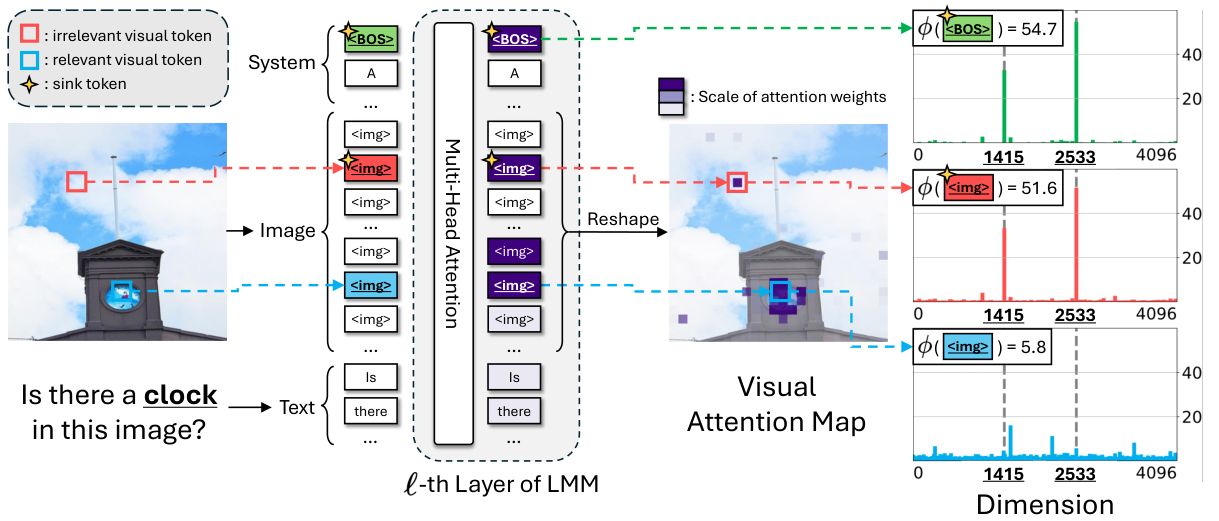
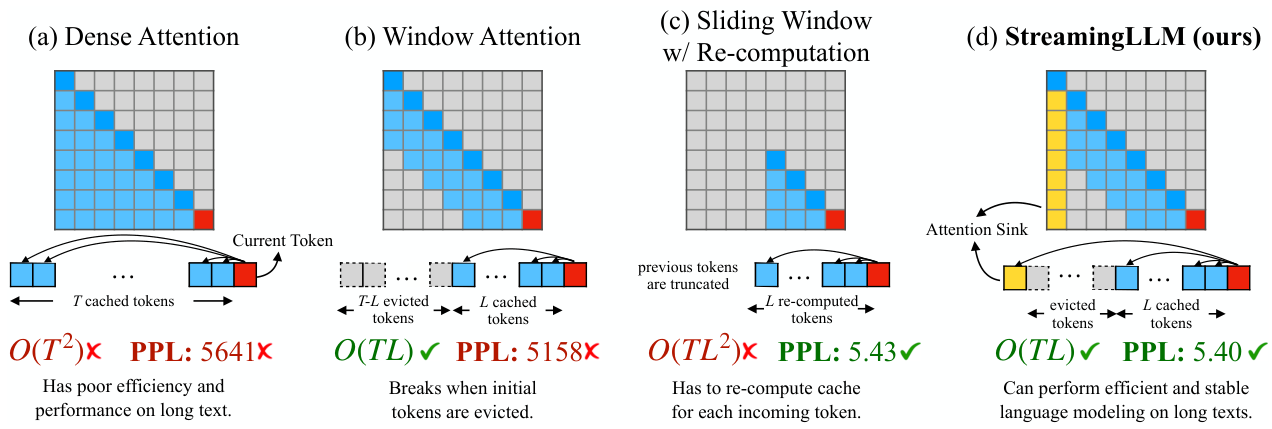
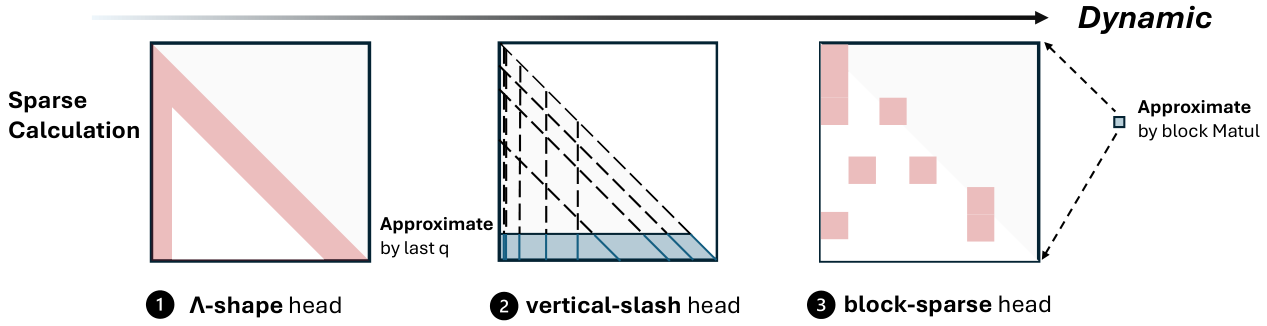
This survey organizes the attention sink literature into a clear three-pillar framework. Fundamental Utilization covers how practitioners leverage attention sink patterns for efficient inference (KV cache compression, sparse attention). Mechanistic Interpretation explores why attention sink emerges through theories about softmax constraints, outlier circuits, and geometric properties. Strategic Mitigation presents architectural modifications to reduce or eliminate unwanted attention concentration.