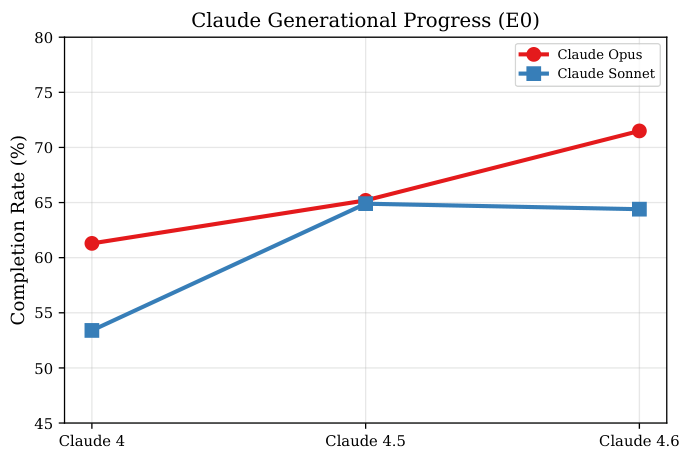
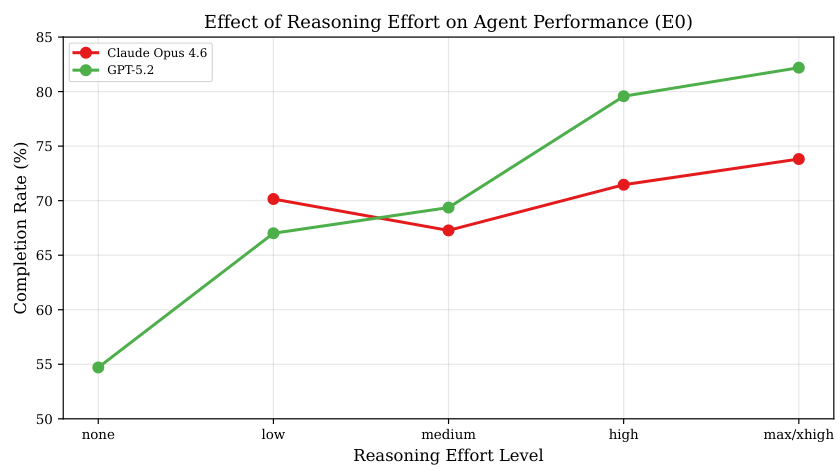
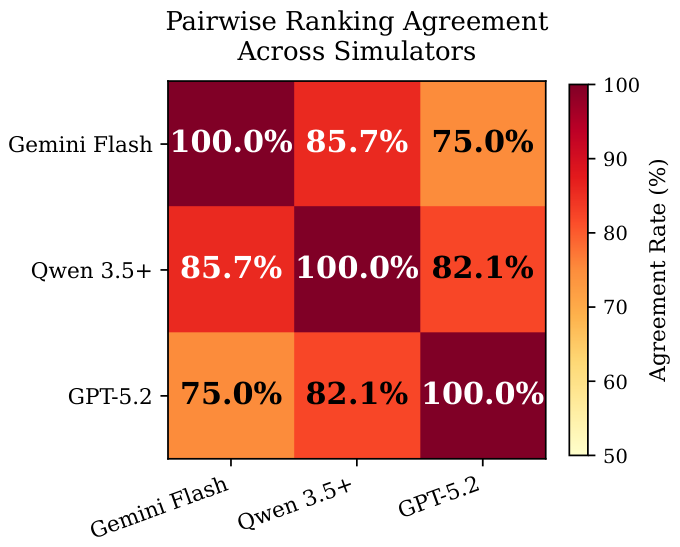
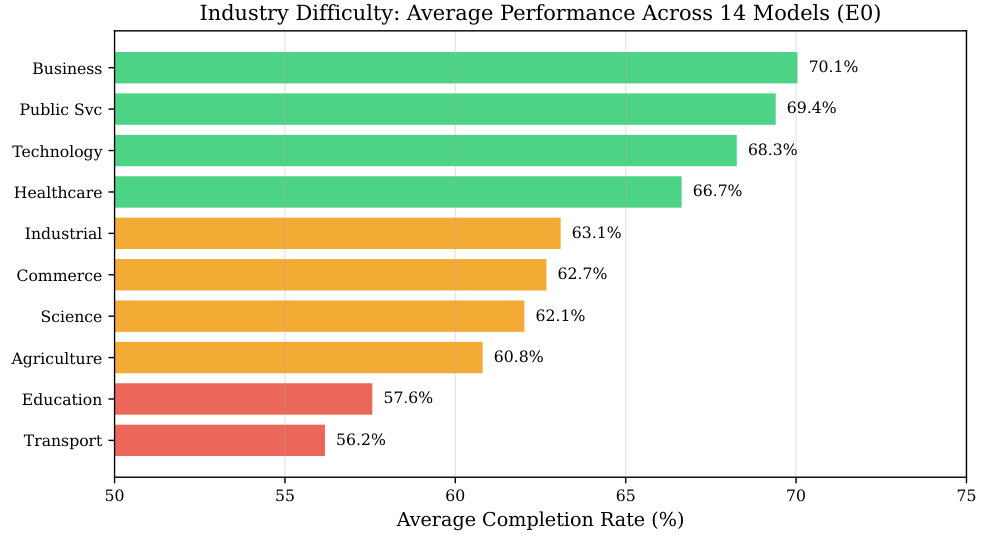
Language Environment Simulator
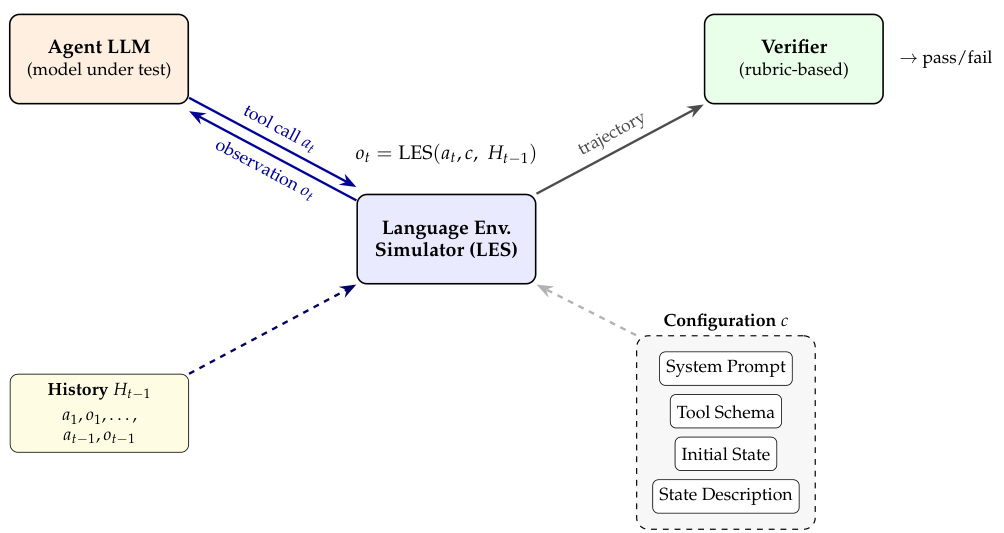
The core innovation of OccuBench is the Language Environment Simulator (LES)—a function that simulates domain-specific environments through LLM-driven tool response generation. The LES is formally defined as:
get_patient_vitals(room_2), the LES generates a plausible JSON response with heart rate, blood pressure, etc., following the rules defined in the configuration c.Here, c is the environment configuration (system prompt, tool schema, initial state, state description), st is the latent environment state maintained implicitly through the LLM's context window, at is the agent's action (a tool call), and ot+1 is the observation returned to the agent. Unlike traditional world models that learn from data, LESs leverage pre-trained knowledge of domain-specific operational logic.
Environment Configuration
System Prompt
Defines the environment's behavioral rules, simulation logic, error handling protocols, and output format constraints. For example, a hotel revenue management environment specifies pricing rules, occupancy calculations, and metrics relationships.
Tool Schema
Defines the agent's action space as a set of callable functions with typed parameters and example outputs. Each environment contains 2–10 tools (median 5) reflecting realistic operational interfaces.
Initial State
A structured JSON object specifying the environment's starting conditions—for example, room inventory, patient queue, or network topology.
State Description
Semantic annotations for each state field, guiding the LLM to maintain causal consistency (e.g., “remaining inventory decreases after each booking”).
Why LLMs Work as Simulators
LLMs are effective environment simulators because: (1) Format priors—pre-training on API documentation provides strong priors for well-formatted tool responses. (2) Domain knowledge—LLMs encode operational logic for hundreds of professions. (3) Constraint enforcement—system prompts can impose state transition rules that maintain causal consistency.
Why is this approach powerful?
Traditional benchmarks for AI agents require building actual software environments—a real hospital management system, a real factory scheduling tool, a real customs processing API. This is why only a handful of domains (web browsing, coding) have proper benchmarks. The LES approach flips this: instead of engineering environments, you describe them in natural language. The LLM's pre-training on documentation for hundreds of industries means it already "knows" how an emergency department system should respond to a triage query, or how a logistics API should handle route optimization. This makes it possible to benchmark agents across 100 different professional domains—something that would cost millions of dollars with traditional approaches.