The Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
Yang Liu, Enxi Wang, Yufei Gao, Weixin Zhang, Bo Wang, Zhiyuan Zeng, Yikai Zhang, Yining Zheng, Xipeng Qiu
Fudan University · Shanghai Innovation Institute · OpenMOSS
Despite the success of reinforcement learning for large language models, a common failure mode is reduced sampling diversity, where the policy repeatedly generates similar erroneous behaviors. Classical entropy regularization encourages randomness but does not explicitly discourage recurrent failure patterns across rollouts. We propose MEDS, a Memory-Enhanced Dynamic reward Shaping framework that incorporates historical behavioral signals into reward design. By storing and leveraging intermediate model representations, we capture features of past rollouts and use density-based clustering to identify frequently recurring error patterns. Rollouts assigned to more prevalent error clusters are penalized more heavily, encouraging broader exploration while reducing repeated mistakes.
With the advancement of the fundamental capabilities of Large Language Models (LLMs), reinforcement learning has achieved significant success across various domains. By incorporating reward signals—whether derived from rule-based evaluation or proxy models—LLMs iteratively alternate between a sampling phase and a gradient-based optimization phase. As the model's performance is optimized toward maximizing expected return, designing the reward scoring structure becomes the primary way to guide the model's behavior.
The Core Problem: As RL training progresses, the policy often collapses into a narrow, stereotyped set of behaviors. This degeneration produces highly repetitive responses that waste on-policy samples and entrench the model in self-reinforcing erroneous reasoning trajectories. Classical entropy regularization promotes randomness at the distribution level, but fails to address the fundamental issue of recurring behavioral patterns across rollouts.
What is entropy regularization?
In reinforcement learning, entropy regularization is a technique that adds a bonus reward for being "random." Think of it like a teacher giving extra credit to a student who tries different approaches to solving a math problem, instead of always using the same method. The problem? This randomness is at the word level—the model might vary which words it picks, but still follow the same flawed reasoning strategy underneath. It's like a student who rearranges the words in their wrong answer instead of actually trying a different solving method.
The challenge is that distribution-level stochastic exploration often cannot disambiguate between the randomness that discovers genuinely novel strategies and the randomness that merely shuffles between the same set of failed approaches. A model may sample diverse tokens yet still follow identical flawed reasoning paths—for instance, repeatedly misreading the problem setup or applying an incorrect formula, even as the surface-level text varies.
MEDS addresses this gap by operating at the behavioral pattern level rather than the token distribution level. Instead of encouraging generic randomness, it identifies and penalizes the specific error patterns that recur across rollouts, directly incentivizing the model to explore genuinely different reasoning strategies.
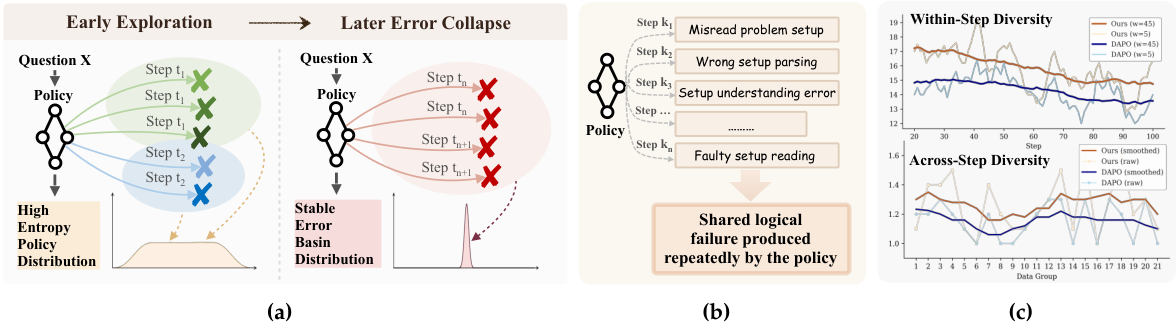
Figure 1: (a) During RL training, early exploration produces diverse responses, but later steps collapse into repetitive error patterns. (b) MEDS uses memory-based clustering to identify shared latent productions and applies reward shaping penalties. (c) Within-step diversity metrics show MEDS consistently improves sampling diversity compared to DAPO.
Related Work
RL with Verifiable Rewards
Reinforcement Learning with Verifiable Rewards (RLVR) relies on rule-based evaluation for reward signals, enabling iterative policy optimization. DeepSeekMath and related works pioneered this approach using outcome-based rewards for mathematical reasoning. The key advantage is that verification is deterministic—a math answer is either correct or incorrect—eliminating the noise of learned reward models.
Reward Shaping for Diversity
During RLVR training, policy updates tend to over-optimize dominant solution patterns, leading to collapse of reasoning diversity. Traditional approaches include entropy regularization (SAC, A3C) and dynamic sampling strategies like DAPO. However, these methods operate at the token distribution level and cannot specifically target recurring behavioral patterns that indicate repeated reasoning errors.
Inner Thoughts of LLMs
Research on interpreting how LLMs reason internally—including logit-based analysis, probing techniques, and mechanistic interpretability—provides a key inspiration for MEDS. Works on locating factual associations (ROME), scaling monosemanticity, and in-context learning heads demonstrate that intermediate model representations encode rich semantic information about the reasoning process.
Method
The MEDS framework augments standard reinforcement learning with a memory-based penalty that targets frequently recurring error patterns. Given an input \(x \sim \mathcal{D}\), the LLM policy \(\pi_\theta\) generates a response \(y \sim \pi_\theta(y|x)\). The standard RL objective maximizes the expected reward \(\mathbb{E}[r(x,y)]\). MEDS modifies this by introducing a shaped reward: \(r_s(x,y) = r(x,y) - \text{penalty}(c_i)\), where \(c_i\) is the cluster assignment based on the response's behavioral pattern.
Why use the model's own internal signals?
When an LLM generates text, it doesn't just produce words—internally, it computes probability distributions over all possible next tokens at every step. These internal signals (logits) are like the model's "thought process." MEDS uses these signals as a fingerprint for each response's reasoning strategy. Imagine two students solving a math problem: even if their written answers look different on the surface, if they're both making the same conceptual mistake, their internal reasoning patterns would be similar. MEDS captures exactly this—grouping responses by how the model thinks, not just what it writes.
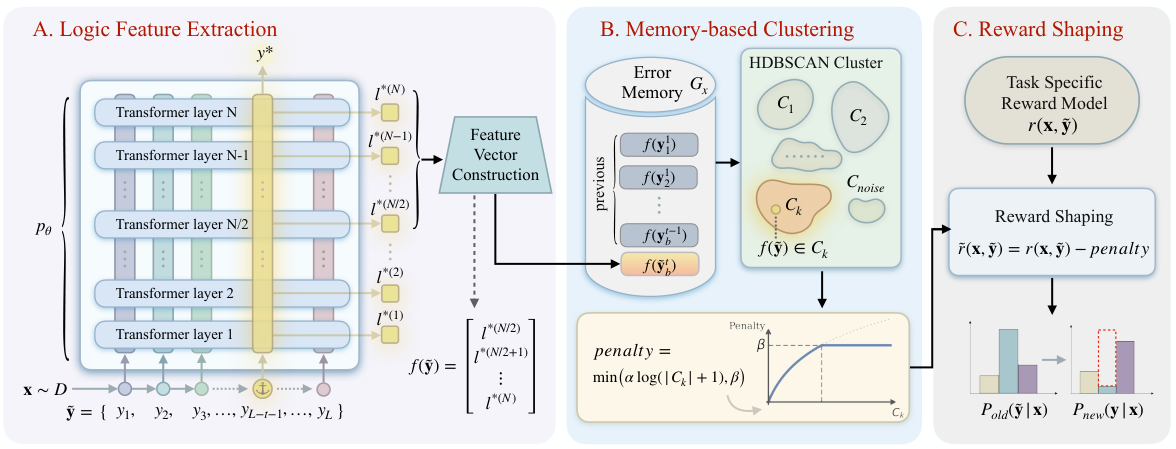
Figure 2: The MEDS framework consists of three modules: (A) Logic Feature Extraction extracts reasoning features from intermediate model representations. (B) Memory-based Clustering uses HDBSCAN to group similar error patterns from a memory buffer. (C) Reward Shaping applies cluster-size-based penalties to discourage repetitive errors.
Theoretical Benefits of Penalizing Repeated Errors
With the standard reward \(r(x,y)\), the updated policy \(q_1\) converges toward patterns that maximize return. By introducing an error-cluster penalty \(r(x,y) - \lambda c(y)\), the modified policy \(q_2\) is provably encouraged to distribute probability mass away from large error clusters.
The key theoretical result (Theorem 2) shows that under the shaped reward, the updated policy \(q_2\) achieves higher entropy \(H(q_2) \geq H(q_1)\) while maintaining expected performance. This means MEDS provably increases exploration diversity without sacrificing quality.
Theorem 2 (Informal): Let \(q_1\) and \(q_2\) be the updated policies under the original reward \(r(x,y)\) and the shaped reward \(r(x,y) - \lambda c(y)\) respectively. Then \(H(q_2) \geq H(q_1)\), meaning the shaped reward provably increases output diversity.
What does the theorem actually mean in practice?
Theorem 2 provides a mathematical guarantee that MEDS works as intended. In plain terms: if you penalize the most common error patterns, the model is provably forced to explore more diverse strategies. The key insight is that this happens without sacrificing quality—the model doesn't become more random in a harmful way. Instead, it specifically avoids repeating the same mistakes, which naturally leads it to discover new and potentially correct approaches. Think of it as: rather than randomly trying doors in a maze, the model remembers which doors led to dead ends and avoids them, guaranteeing it explores more of the maze.
Logic Feature Extraction
To implement the indicator function \(c(y)\), MEDS directly leverages the model's own intermediate representations. For each response \(y\) generated by the policy, the method collects logit vectors from a specific intermediate layer. These vectors are pooled (e.g., via mean pooling over sequence positions) to form a fixed-dimensional feature vector that captures the response's reasoning logic. This approach is computationally efficient since the representations are already computed during the standard forward pass—no additional inference is needed.
What are logit vectors?
Logits are the raw scores that a language model computes before converting them into probabilities for the next token. For example, if the model is deciding what word comes next, it might assign a score of 5.2 to "the," 3.1 to "and," and -1.7 to "banana." These scores (logits) reveal the model's internal preferences. MEDS collects these from an intermediate layer—not the final output layer—to capture the underlying reasoning logic rather than just the surface-level word choices.
Cluster-based Reward Shaping
Based on the constructed response representations, MEDS computes cluster assignments using HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise). A memory buffer stores feature vectors from past rollouts. For each new batch, the method:
Extracts logit features for all responses in the current batch
Combines current features with stored features from the memory buffer
Runs HDBSCAN to identify clusters of similar error patterns
Computes a penalty proportional to cluster size—larger clusters (more frequent error patterns) receive higher penalties
The final shaped reward is: \(r_s(x,y) = r(x,y) - \text{penalty}(c_i)\), where the penalty function increases with the size of the assigned cluster, creating a direct pressure against the most common failure modes.
What is HDBSCAN and why use it?
HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise) is a clustering algorithm that groups data points by how densely they're packed together. Unlike K-means, which requires you to specify the number of clusters in advance, HDBSCAN discovers clusters automatically and can handle "noise" (responses that don't fit any pattern). This is ideal for MEDS because: (1) We don't know how many error patterns exist in advance, (2) Some responses might be genuinely unique and shouldn't be forced into a cluster, and (3) Error patterns can have irregular shapes in the feature space.
Experimental Setup
Base Models
Qwen3-1.7B
Qwen3-8B
Qwen2.5-Math-7B
Benchmarks
AIME24 (30)
AMC23 (40)
MATH500
Minerva
OlympiadBench
Baselines
GRPO
DAPO
GRPO w/ Entropy Adj.
Training Details
Adam optimizer, learning rate 1e-6
Weight decay 0.1, gradient clipping 1.0
10 warmup steps, batch-level reward shaping
Main Results
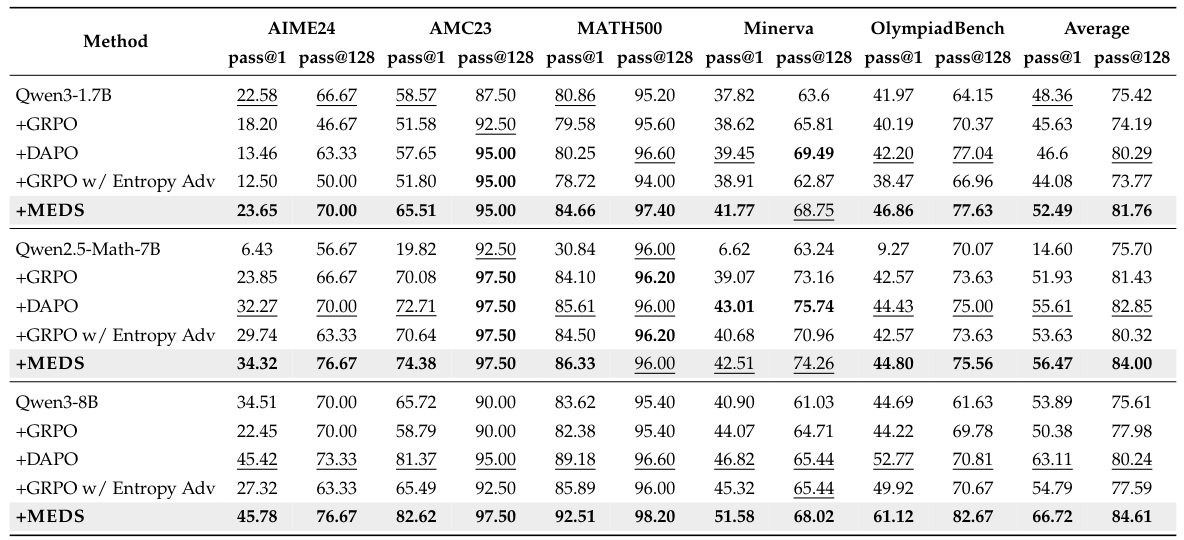
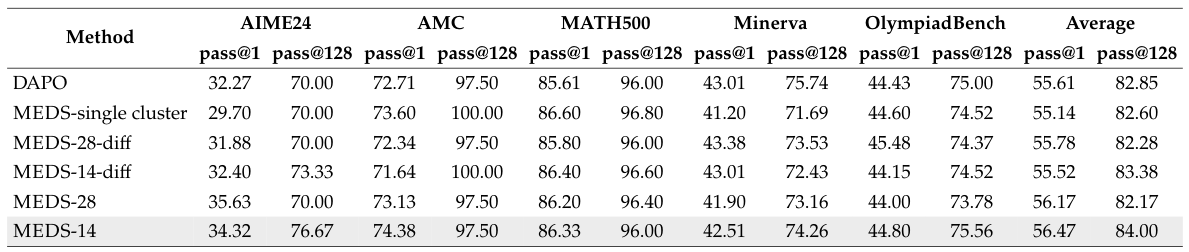
Table 1 summarizes the performance across three base models and five mathematical reasoning benchmarks. MEDS consistently achieves the best overall average performance, demonstrating strong generalization across models with different levels of prior mathematical training.
Table 1: Pass@1 and pass@128 scores across five benchmarks. MEDS achieves the best average scores across all base models, with gains of up to +4.13 pass@1 and +4.37 pass@128 over the strongest baselines.
Across all configurations, MEDS delivers the highest average pass@1 and pass@128 scores. The improvements are most pronounced on challenging benchmarks like AIME24 and OlympiadBench, where the diversity of explored reasoning strategies matters most. Notably, the gains hold for both pass@1 (best single attempt) and pass@128 (best of 128 attempts), indicating that MEDS improves both the quality and breadth of generated solutions.
What do pass@1 and pass@128 mean?
pass@k measures the probability that at least one of k generated solutions is correct. pass@1 is the accuracy of a single attempt—like getting one shot at an exam question. pass@128 gives the model 128 attempts and checks if any one is correct. Improving pass@1 means the model's best guess is better; improving pass@128 means it explores a wider range of strategies. MEDS improves both, showing it makes the model both smarter and more creative in its problem-solving.
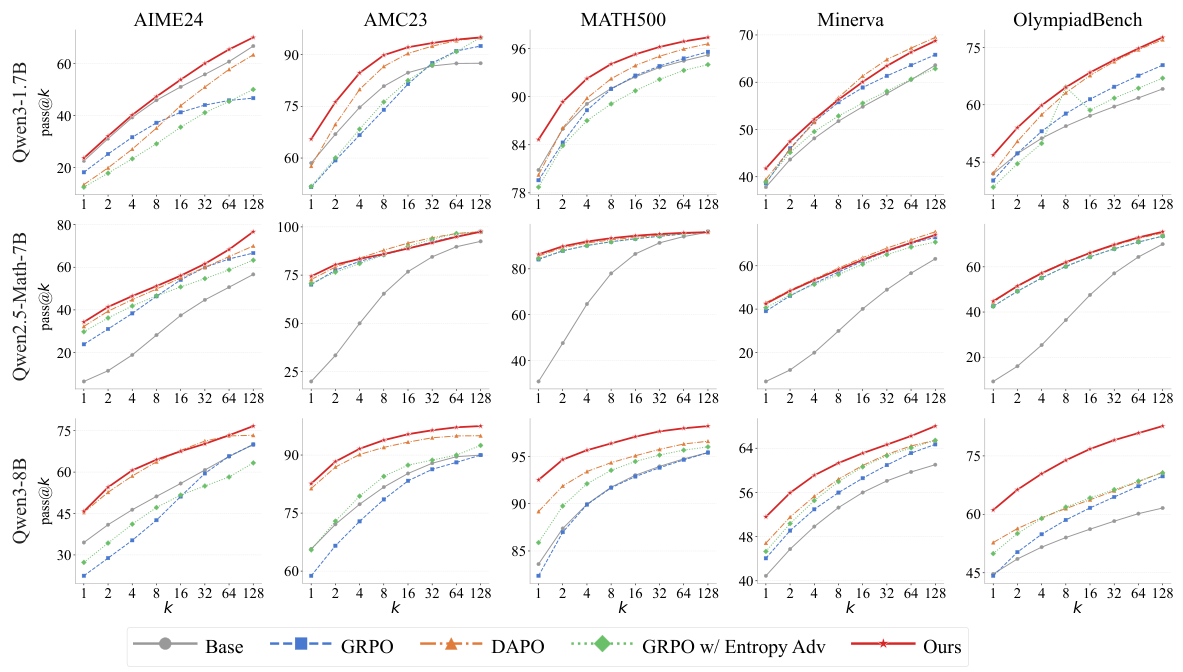
Figure 4: Pass@k performance curves across five benchmarks and three base models. MEDS (red) consistently outperforms all baselines across the full range of k values, with the largest improvements at lower k values where sampling diversity is most critical.
Impact on Exploration Behavior
To understand how MEDS influences the model's exploration during reasoning, we conducted a detailed analysis from both behavioral and representational perspectives. Using Claude-Haiku-4.5 as a proxy annotator, we evaluated the semantic diversity of sampled responses. MEDS achieves a diversity score of 61.2, substantially higher than DAPO (45.16) and GRPO w/ Entropy Adj. (52.52).
Method
Diversity Score
DAPO
45.16
GRPO w/ Entropy Adj.
52.52
MEDS-v1
54.71
MEDS-v2
53.87
MEDS (Full)
61.2
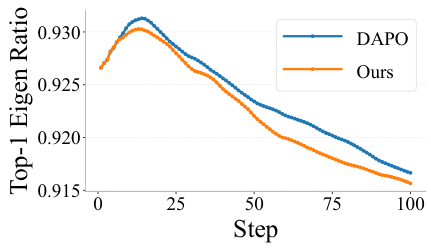
From a representational perspective, we analyze the Top-1 Eigen Ratio—a measure of representation collapse in the output space. A higher ratio indicates that the model's outputs are concentrating in fewer dimensions, signaling reduced diversity. MEDS maintains a consistently lower eigen ratio throughout training, confirming that it preserves representational diversity at a fundamental level.
Understanding the Top-1 Eigen Ratio
The Top-1 Eigen Ratio measures how much the model's outputs concentrate in a single direction in the representation space. Imagine the model's outputs as arrows in a high-dimensional space. If all arrows point roughly the same way, the eigen ratio is high (close to 1.0)—this signals representation collapse, where the model has lost diversity. A lower ratio means the arrows spread out in many directions, indicating diverse reasoning strategies. MEDS keeps this ratio lower than DAPO throughout training, meaning it better preserves the model's ability to think in varied ways.
Figure 5: Top-1 Eigen Ratio during training. Lower values indicate less representation collapse. MEDS (orange) consistently maintains a lower eigen ratio than DAPO (blue), demonstrating better preservation of representational diversity throughout training.
Logits Reflect Reasoning Patterns
A fundamental premise of MEDS is that logit vectors from intermediate layers capture the underlying logical reasoning structure—not just surface-level token predictions. We validate this through both qualitative case studies and quantitative analysis at scale. The logit representations of different responses to the same problem form distinct clusters that correspond to semantically meaningful reasoning strategies (correct vs. incorrect approaches).
What is t-SNE visualization?
t-SNE (t-distributed Stochastic Neighbor Embedding) is a technique for visualizing high-dimensional data in 2D. Think of it as taking a complex 3D sculpture and photographing it from the angle that best shows its structure. Each dot in the figure represents one model response, and responses with similar internal reasoning patterns appear close together. The fact that distinct clusters emerge shows that logit features genuinely capture different reasoning strategies—they're not just random noise.
Figure 3: t-SNE visualization of response representations in logit space for three math problems. Different reasoning patterns form distinct clusters. Larger circles indicate more frequent patterns (potential error clusters that MEDS would penalize). The clear separation demonstrates that logit features effectively capture reasoning logic.
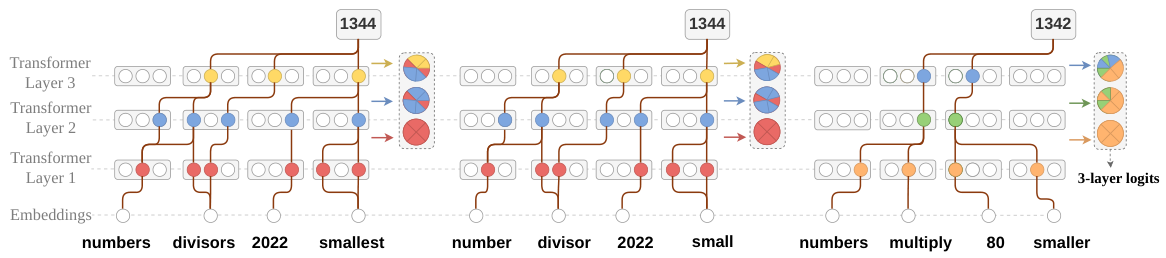
Logits Provide Correct Clustering Signals
To validate at scale, we used Claude-Haiku-4.5 as a proxy annotator to label the reasoning strategy of randomly selected responses. The annotation procedure confirmed that logit-based clusters correspond to semantically coherent reasoning patterns: responses in the same cluster tend to follow the same reasoning approach (e.g., attempting prime factorization vs. trial division), regardless of whether they reach the correct answer.
Figure 6: Case study on a number theory problem (finding the smallest integer with three distinct divisors summing to 2022). Cluster A contains responses with a common error pattern (misunderstanding divisor structure), while Cluster B contains correct reasoning using prime factorization. The logit-based clustering successfully separates these distinct strategies.
Ablation Study
We investigate how different feature construction and clustering methods affect performance. The ablation compares: random cluster assignments (control), semantic features (from the model's text output), and logit features with various clustering algorithms. Results demonstrate that clustering quality matters significantly—logit-based features with HDBSCAN provide the best performance, while random clustering and semantic features are notably inferior.
Why does clustering quality matter so much?
If MEDS clusters responses randomly (assigning penalties without regard to actual reasoning patterns), the penalties become meaningless noise—hurting good responses as often as bad ones. If it uses only surface-level text features (semantic clustering), it might group responses that look similar but actually use different reasoning strategies. Only logit-based features capture the underlying reasoning logic, enabling HDBSCAN to form clusters that correspond to genuinely shared error patterns. This is why the full MEDS configuration significantly outperforms both random and semantic baselines.
Table 3: Ablation study results comparing different feature extraction methods and clustering algorithms. The full MEDS configuration (logit features + HDBSCAN) achieves the best performance, validating the importance of both components.
Conclusion
MEDS demonstrates that incorporating historical behavioral signals into reward design can effectively combat the recurring error patterns that plague reinforcement learning for LLM reasoning. The key contributions of this work are:
Memory-aware reward shaping: A framework that captures features of past rollouts via intermediate model representations (logits) and uses them to shape the reward signal dynamically
Dynamic penalization: Penalties proportional to cluster prevalence create direct pressure against the most common failure modes
Consistent improvements: Gains of up to +4.13 pass@1 and +4.37 pass@128 across 5 benchmarks and 3 base models
Increased diversity: Both LLM-based annotations and quantitative metrics (Top-1 Eigen Ratio) confirm that MEDS significantly increases behavioral diversity during sampling
Limitations
The main limitation is that the methods explored for utilizing logits are relatively simple and do not incorporate more sophisticated aggregation techniques. Future work could explore more advanced feature extraction from intermediate representations, different clustering algorithms, and application to non-mathematical reasoning tasks such as code generation, multi-step planning, and open-ended creative writing.