
cs.AI
RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time
HKUST
University of Waterloo
Alibaba
Published April 13, 2026
Published April 13, 2026
Most reward models for visual generation compress complex human preferences into a single opaque score, discarding the reasoning behind those preferences. RationalRewards changes this by teaching reward models to produce explicit, multi-dimensional critiques before scoring. Using a novel framework called PARROT (Preference-Anchored Rationalization), the model treats rationales as latent variables inferred from pairwise preference data. This transforms the reward model from a passive evaluator into an active optimization tool that enables two complementary strategies: RL-based fine-tuning in parameter space and Generate-Critique-Refine loops in prompt space. Remarkably, the test-time prompt tuning approach matches or exceeds RL fine-tuning on several benchmarks, without any parameter updates.
Multi-dimensional structured critiques replace opaque scalar scores, providing explainable evaluation across text faithfulness, image faithfulness, visual quality, and text rendering.
A variational framework that trains reward models using preference data by treating rationales as latent variables, decomposing the ELBO into three interpretable phases.
Enables both parameter-space tuning via RL (training time) and prompt-space tuning via Generate-Critique-Refine loops (test time), trading compute for quality without parameter updates.
As visual generation advances toward photorealistic, instruction-following outputs, reward models that evaluate these outputs have become the binding constraint on further progress. Yet most reward models remain scalar black boxes: they compress multi-dimensional human judgments into a single number. This opacity causes two critical problems.
First, reward hacking: models learn to exploit biases in the scalar signal to inflate scores without genuine quality improvement. Second, scalar scores provide no actionable feedback — they tell the generator that something is wrong, but not what or how to fix it. RationalRewards addresses both problems by generating structured, multi-dimensional critiques before deriving scores, enabling the reward model to serve as both evaluator and optimizer.
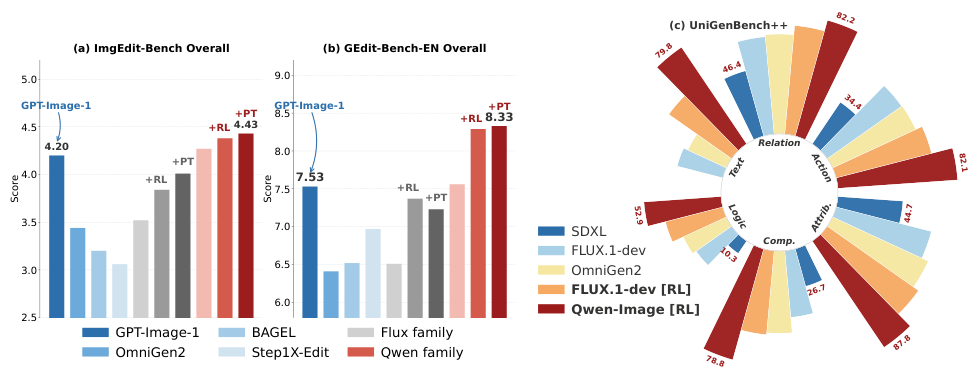
Instantiated via PARROT on a Qwen3-VL-Instruct-8B backbone, RationalRewards achieves state-of-the-art preference prediction among open-source reward models, competitive with Gemini-2.5-Pro. As an RL reward, it consistently improves Qwen-Image and Flux-Kontext generators, rivaling GPT-Image-1. The test-time prompt tuning approach matches or exceeds computationally expensive RL fine-tuning on several benchmarks — without any parameter updates.
PARROT trains reward models to produce explicit, multi-dimensional rationales before scores. Assessment dimensions include text faithfulness, physical and visual quality, image faithfulness, and text rendering quality. Since ground-truth rationales are prohibitively expensive to annotate at scale, PARROT formulates rationales as latent variables inferred from pairwise preference data via a variational objective. The resulting ELBO decomposes into three terms, each corresponding to a training phase.
The ELBO (Evidence Lower BOund) is a mathematical tool from variational inference. Think of it like this: imagine you want to understand why humans prefer one image over another, but you can't directly observe their reasoning process. The ELBO gives you a way to learn those hidden reasons (rationales) from the data you can observe (which image was preferred).
PARROT decomposes this into three intuitive terms: (1) Do the rationales actually explain the preferences? (2) How different are our inferred rationales from what we'd generate without knowing the answer? (3) Can a student model learn to produce these rationales on its own?
A latent variable is something you believe exists but can't directly observe. Here, the "rationale" (the reasoning behind why one image is better) is latent — humans express preferences but rarely write down their full reasoning process. PARROT's insight is to treat these unobserved rationales as latent variables and learn them from preference data, rather than requiring expensive human annotation of reasoning.
Real-world analogy: It's like learning what makes a good restaurant review by only seeing star ratings (preferences), then training a model to write the detailed review (rationale) that would lead to that rating.

A Teacher VLM is prompted with a comparison tuple (two images + user request) and the ground-truth preference label. This label acts as a preference anchor that steers the teacher’s analysis toward the correct judgment, yielding higher-quality posterior samples than unconditioned generation. The teacher produces structured critiques across four quality dimensions with scores and justifications.
While Phase 1 produces linguistically plausible rationales, plausibility alone doesn’t guarantee usefulness. Phase 2 enforces predictive sufficiency: the Teacher is re-queried with the rationale without the preference label, and must correctly predict the original preference. Only rationales that pass this consistency check are retained, filtering out hallucinated or insufficiently informative ones.
A smaller Student VLM (8B parameters) is trained via supervised fine-tuning on the filtered rationales to generate critiques without the preference label. This minimizes the KL divergence between posterior and prior, enabling the student to produce scoring rationales at inference time from images alone. The student is trained jointly on pairwise and pointwise data.
Scalar reward models compress evaluation into a single number that can be inflated by exploiting biases. Multi-dimensional structured rationales provide an internal consistency mechanism: justifications must align with scores, and scores must be consistent across dimensions. If a model tries to inflate one dimension, the rationale’s justification must explain why — making gaming detectable and penalizable. This structural transparency is what gives reasoning rewards their robustness.
Reward hacking occurs when an AI model finds shortcuts to maximize its reward score without actually improving quality. For example, a scalar reward model might give higher scores to images with high color saturation, so the generator learns to oversaturate all images — inflating scores while degrading visual quality.
RationalRewards prevents this because its multi-dimensional scoring creates checks and balances: if "text faithfulness" is high but "visual quality" is low, the discrepancy is visible and penalizable.

RationalRewards is not just an evaluator — it functions as an active optimization tool across two complementary spaces. This dual formulation connects to test-time compute scaling: prompt-space optimization offers an axis for improving generation quality orthogonal to parameter-space training, applicable to any frozen generator without risk of catastrophic forgetting.
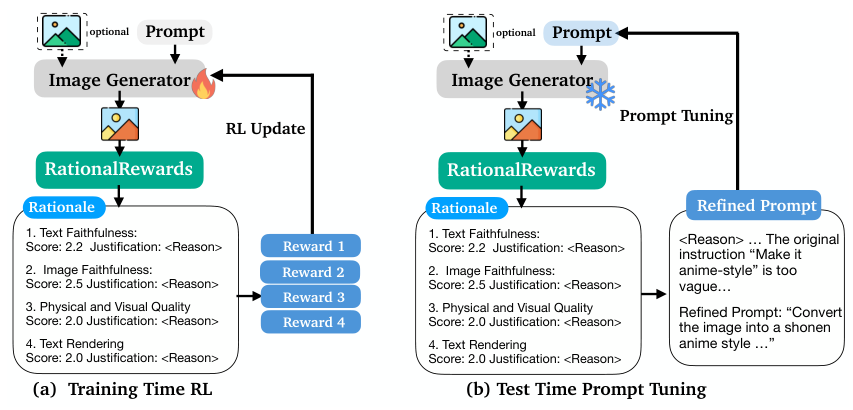
Parameter-space optimization (RL) changes the model's internal weights — like retraining a chef's skills. Prompt-space optimization (GCR) rewrites the instructions given to the model — like giving that same chef a better recipe.
These are orthogonal, meaning they work on different dimensions and can be combined. A key finding: prompt refinement alone sometimes matches or beats RL, suggesting that current generators are more capable than their default prompts reveal.
Business implication: Companies can improve image generation quality at inference time without expensive retraining — just by adding a critique-and-refine step to their existing pipeline.
Multi-dimensional scores provide semantically decomposed reward signals for reinforcement learning. Each quality dimension (text faithfulness, image faithfulness, visual quality, text rendering) provides targeted gradient information, enabling fine-grained optimization rather than chasing a single opaque scalar. This dense feedback helps the generator understand what to improve and why.
Natural-language rationales identify concrete deficiencies in generated images — for example, “the instruction says no umbrellas but the image contains one.” These critiques are translated into targeted prompt revisions in a Generate-Critique-Refine (GCR) loop. This purely test-time intervention requires no parameter updates and can be applied to any frozen generator, trading compute for quality.
Why not just use a capable generic VLM (like Qwen3-VL-32B) as a judge? Beyond the practical advantage of a smaller 8B model, there’s a fundamental reason: structured training on preference data teaches calibrated judgment norms that generic VLMs lack. Generic models can articulate critiques but fail to calibrate severity — they often over-penalize minor issues while under-weighting critical failures. PARROT’s preference-anchored training addresses this by grounding judgments in actual human preferences.
The Generate-Critique-Refine (GCR) loop provides test-time compute scaling for image generation. After initial generation, RationalRewards critiques the output, identifying specific deficiencies with detailed reasoning. These critiques are translated into prompt revisions, and the generator re-generates. This purely test-time intervention requires no parameter updates and can be applied to any frozen generator, demonstrating that current generators harbor latent capabilities that suboptimal prompts fail to elicit.

Generators often possess latent capacity for high-quality outputs that is under-elicited by suboptimal prompts. RationalRewards unlocks this capacity without weight modification through actionable critiques. Scalar rewards cannot identify what went wrong, only that something did. Structured reasoning pinpoints the specific deficiency and prescribes concrete prompt corrections — enabling effective test-time compute scaling.
RationalRewards is evaluated across both image editing and text-to-image generation tasks. Training data includes 30K query-preference pairs from EditReward (image editing) and 50K pairs from ImageRewardDB (text-to-image). The Teacher is Qwen3-VL-32B-Instruct and the Student backbone is Qwen3-VL-8B-Instruct.
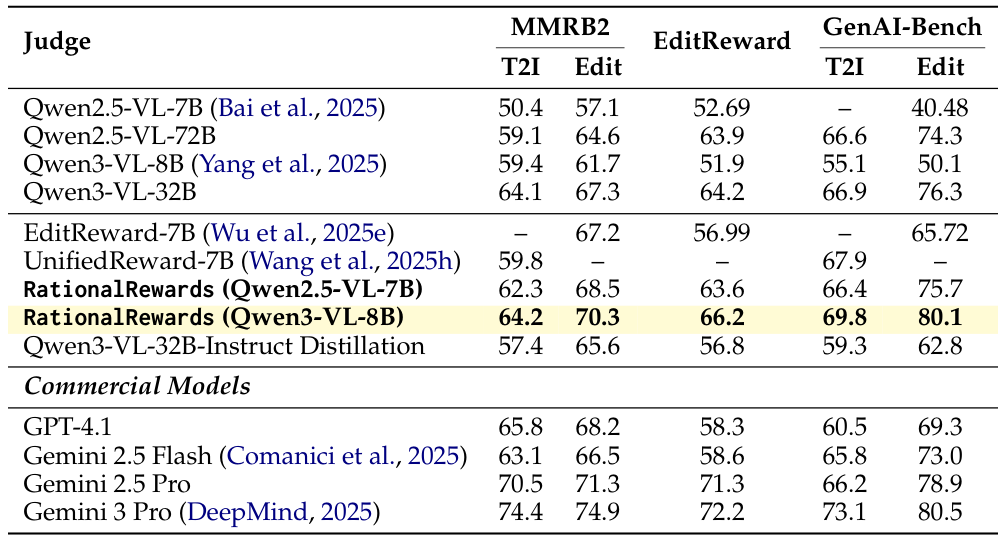
The 8B-parameter RationalRewards surpasses all open-source scalar reward models by a substantial margin across all three benchmarks (MMRB2, EditReward-Bench, GenAI-Bench), without requiring complex loss designs to handle label noise. It is competitive with Gemini-2.5-Pro, a much larger proprietary model. Ablation shows that PARROT’s variational framework outperforms direct SFT distillation from the same 32B teacher, confirming that the structured training pipeline — not just model capacity — drives the improvement.
RL with RationalRewards yields consistent improvements across both image editing and text-to-image generation. A striking finding: inference-time prompt tuning frequently matches or exceeds computationally expensive RL. On ImgEdit-Bench, prompt tuning boosts the RL-tuned Flux model from 3.84 to 4.01. This supports the hypothesis that prompt-space optimization offers an orthogonal and complementary axis to parameter-space training.
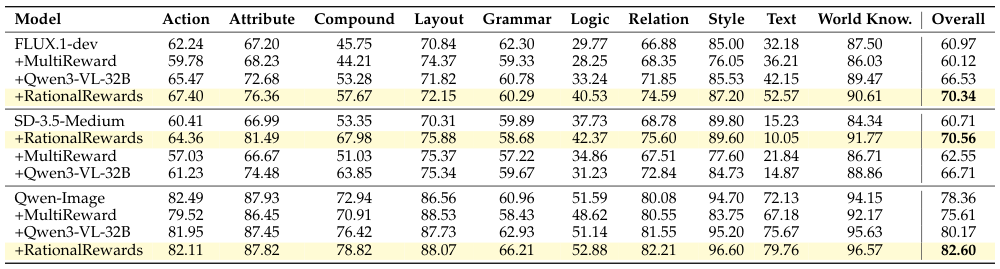
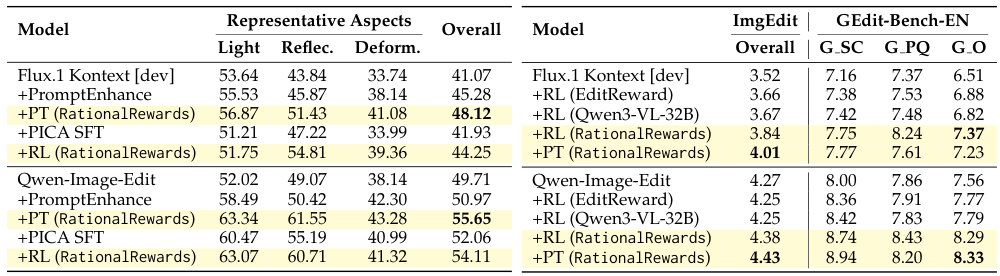
One of the paper's most striking results is that test-time prompt tuning frequently matches or exceeds expensive RL training. This is counterintuitive — you'd expect changing model weights (RL) to be more powerful than just rewriting prompts.
The explanation: RL with LoRA has limited update capacity and may not cover the full evaluation distribution. Prompt tuning performs per-instance optimization without risking catastrophic forgetting. Moreover, it suggests that current generators already have the capability to produce great outputs — they just need better instructions.
Practical takeaway: Before investing in expensive RL retraining, try improving your prompts with structured critique feedback. You might get similar results at a fraction of the cost.


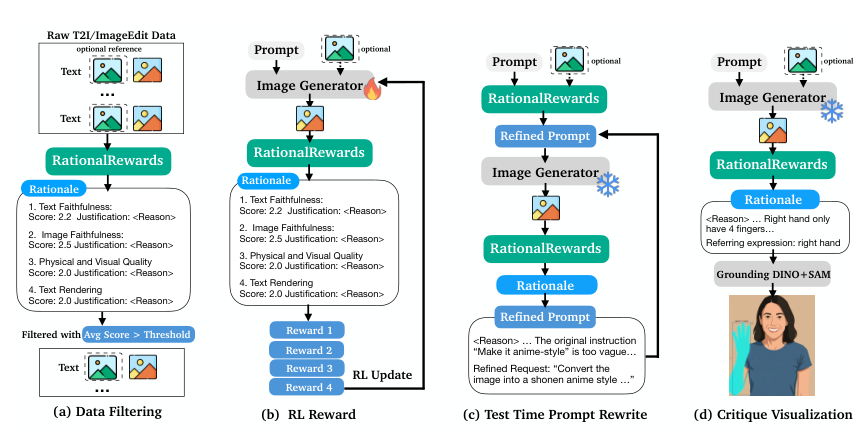
Automated quality control for data curation using multi-dimensional scores and explainable rationales. Low-quality training examples are identified and filtered with transparency.
Dense, semantically decomposed reward signals drive fine-grained RL optimization. Each quality dimension provides targeted gradient information instead of a single opaque scalar.
The GCR loop trades test-time compute for generation quality. Applicable to any frozen generator without parameter updates or risk of catastrophic forgetting.
Integration with Grounding DINO+SAM localizes identified defects in generated images, providing visual evidence that grounds each critique in specific image regions.
RationalRewards replaces opaque scalar scoring with structured, multi-dimensional chain-of-thought critiques. The PARROT framework makes this tractable by treating rationales as latent variables recoverable from readily available pairwise preference data.
An 8B-parameter model achieves state-of-the-art preference prediction among open-source reward models, competitive with much larger proprietary models. Multi-dimensional rewards resist reward hacking through internal consistency mechanisms that scalar models cannot provide.
Perhaps most remarkably, the Generate-Critique-Refine loop — a purely test-time intervention requiring no parameter updates — matches or exceeds RL-based fine-tuning on several benchmarks. This lends strong empirical support to the hypothesis that current generators harbor latent capabilities that suboptimal prompts fail to elicit, and that structured reasoning is the key to unlocking them.
B2B Content
Any content, beautifully transformed for your organization
PDFs, videos, web pages — we turn any source material into production-quality content. Rich HTML · Custom slides · Animated video.