ClawGUI: A Unified Framework for Training, Evaluating, and Deploying GUI Agents
GUI agents can, in principle, operate any app on any device through taps, swipes, and keystrokes. In practice, progress is bottlenecked not by modeling but by missing full-stack infrastructure: closed RL training codebases, silently drifting evaluation protocols, and a broken path from research to real users. ClawGUI closes all three gaps — scalable online RL on emulators and real devices, reproducible evaluation across 6 benchmarks and 11+ models, and real-device deployment through 12+ chat platforms — inside a single open-source pipeline.
Abstract
GUI agents drive applications through their visual interfaces instead of programmatic APIs, interacting with arbitrary software via taps, swipes, and keystrokes — reaching the long tail of applications that CLI-based agents cannot. Yet progress is bottlenecked less by modeling capacity than by the absence of a coherent full-stack infrastructure: online RL training suffers from environment instability and closed pipelines, evaluation protocols drift silently across works, and trained agents rarely reach real users on real devices.
We present ClawGUI, an open-source framework addressing these three gaps within a single harness. ClawGUI-RL is the first open-source GUI agent RL infrastructure with validated support for both parallel virtual environments and real physical devices, integrating GiGPO with a Process Reward Model for dense step-level supervision. ClawGUI-Eval enforces a fully standardized evaluation pipeline across 6 benchmarks and 11+ models, achieving 95.8% reproduction against official baselines. ClawGUI-Agent brings trained agents to Android, HarmonyOS, and iOS through 12+ chat platforms with hybrid CLI-GUI control and persistent personalized memory.
Trained end-to-end within this pipeline, ClawGUI-2B reaches 17.1% Success Rate on MobileWorld GUI-Only, outperforming the same-scale MAI-UI-2B baseline by 6.0 absolute points and surpassing larger untrained models including Qwen3-VL-32B (11.9%) and UI-Venus-72B (16.4%).
One framework, three tightly-integrated modules
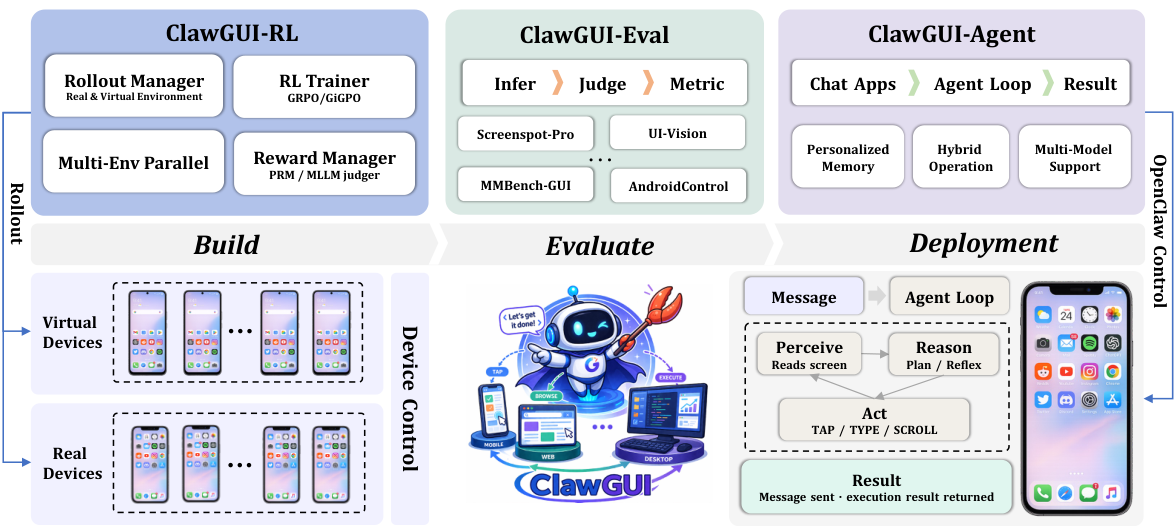
ClawGUI-RL
Scalable online RL training across parallel Docker-based Android emulators and real physical devices. Integrates GiGPO with a Process Reward Model for dense step-level supervision that counteracts long-horizon reward sparsity.
ClawGUI-Eval
Strict three-stage pipeline (Infer → Judge → Metric) pinning every evaluation choice per model. 6 benchmarks, 11+ models, 95.8% reproduction rate against official published baselines.
ClawGUI-Agent
Production-ready deployment on Android, HarmonyOS, and iOS through 12+ chat platforms, with hybrid CLI+GUI control and a persistent personalized memory system that adapts to individual users over time.
Why GUI agents are stuck on infrastructure
Graphical User Interfaces are the universal substrate through which humans interact with modern computing devices. An agent that can perceive screen state and execute low-level actions — tapping, swiping, typing — is, in principle, capable of operating any application on any device without requiring dedicated APIs or backend access. This generality has made GUI agents one of the most actively pursued directions toward end-to-end digital automation.
Building a capable GUI agent, however, is not a single modeling problem but a full-stack engineering problem. A useful agent must be trained against realistic environments, evaluated under comparable conditions, and ultimately deployed to real devices where real users can benefit. Existing research has made meaningful progress on each of these fronts in isolation, but when one assembles the pieces into a working pipeline, the cracks between them become apparent.
We identify three concrete gaps that together define this bottleneck.
The training ecosystem is closed
Recent systems report strong results from online RL in virtual environments but rarely release the underlying infrastructure. Available code is tied exclusively to emulator sandboxes; training on physical devices — where agents must ultimately perform — remains essentially unexplored in the open literature. The engineering blocker is not the RL algorithm itself but environment management: emulators drift out of healthy states during long runs, real devices cannot expose system-level verification signals, and reward signals in long-horizon GUI tasks are sparse almost by construction.
Evaluation is badly misaligned
GUI benchmarks look straightforward, yet reported numbers across papers are rarely directly comparable. Prompt formatting, coordinate normalization, image resolution, and sampling configuration each shift reported accuracy by several points, and these choices are often undocumented. A 2% improvement on ScreenSpot-Pro may reflect a genuine advance, a favorable prompt, or simply a different resolution — and today a reader has no way to tell.
The deployment loop is broken
Agents trained in research pipelines almost never reach end users. Recent work on CLI-based harnesses offers precise control through structured commands but covers only a narrow slice of real applications. Systems that connect a trained GUI policy to real hardware, expose it through interfaces users already use in daily life, and maintain persistent personalization over time remain largely absent from the open ecosystem.
Building on these insights, we present ClawGUI, an open-source framework designed to close all three gaps within a single coherent system. ClawGUI consists of three tightly integrated modules: ClawGUI-RL for scalable online RL on both emulators and real devices with GiGPO + a Process Reward Model; ClawGUI-Eval for strict three-stage standardized evaluation across 6 benchmarks and 11+ models; and ClawGUI-Agent for hybrid CLI-GUI deployment across 12+ chat platforms with persistent personalized memory.
Main contributions
- We release ClawGUI, a unified open-source framework integrating online RL training, standardized evaluation, and real-device deployment into a single pipeline for GUI agents.
- We release ClawGUI-RL, the first open-source GUI-agent RL infrastructure with validated support for both large-scale parallel virtual environments and real physical devices, integrating GiGPO with a Process Reward Model for dense step-level supervision.
- We release ClawGUI-Eval with all inference code and pre-computed predictions across 6 benchmarks and 11+ models, achieving a 95.8% reproduction rate against official baselines and enabling reliable cross-paper comparison.
- We release ClawGUI-Agent, a production-ready deployment system connecting trained agents to real Android, HarmonyOS, and iOS devices through 12+ chat platforms with persistent personalized memory.
- We release ClawGUI-2B, trained end-to-end within ClawGUI-RL, which reaches 17.1% on MobileWorld GUI-Only and outperforms the same-scale MAI-UI-2B baseline by 6.0 absolute points, validating the framework end to end.
Scalable online RL on emulators and real devices
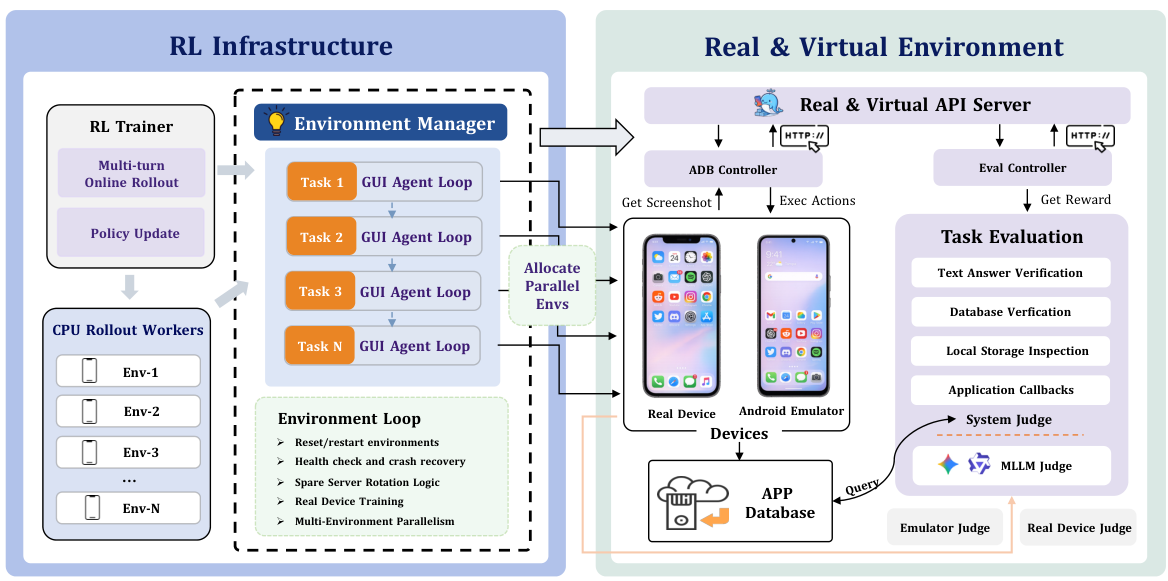
Environment Manager
Stable and scalable environment management is the real prerequisite for online RL training on GUI tasks. The Environment Manager handles task reset, system-level task evaluation on virtual sandboxes, health-checking and spare-server rotation (unhealthy containers are swapped out without killing the run), periodic teardown, and real-device training where only MLLM-as-judge evaluation is available. This layer is what lets training runs last hours instead of minutes.
Two-Level Reward Design
Reward combines two layers. A binary outcome reward (1 for success, 0 for failure at episode end) is robust but very sparse on long-horizon tasks. A dense step-level reward from a Process Reward Model fires every step: given the previous screenshot, current screenshot, and action, the PRM scores whether the step is productive. Together they give the optimizer fine-grained credit assignment that pure outcome rewards cannot.
RL Trainer: GRPO and GiGPO
ClawGUI-RL builds on verl and verl-agent and supports Reinforce++, PPO, GRPO, GSPO, and GiGPO out of the box. GRPO assigns a single advantage score per episode, which is too coarse for long trajectories where success hinges on a few pivotal steps. GiGPO adds an inner step-level grouping so that per-step advantages are estimated by anchor-state clustering — steps that reach the same intermediate state share a sub-group and get relative advantages. This gives the policy dense per-step credit while keeping the macro episode-level signal.
Reproducible GUI evaluation, pinned per model
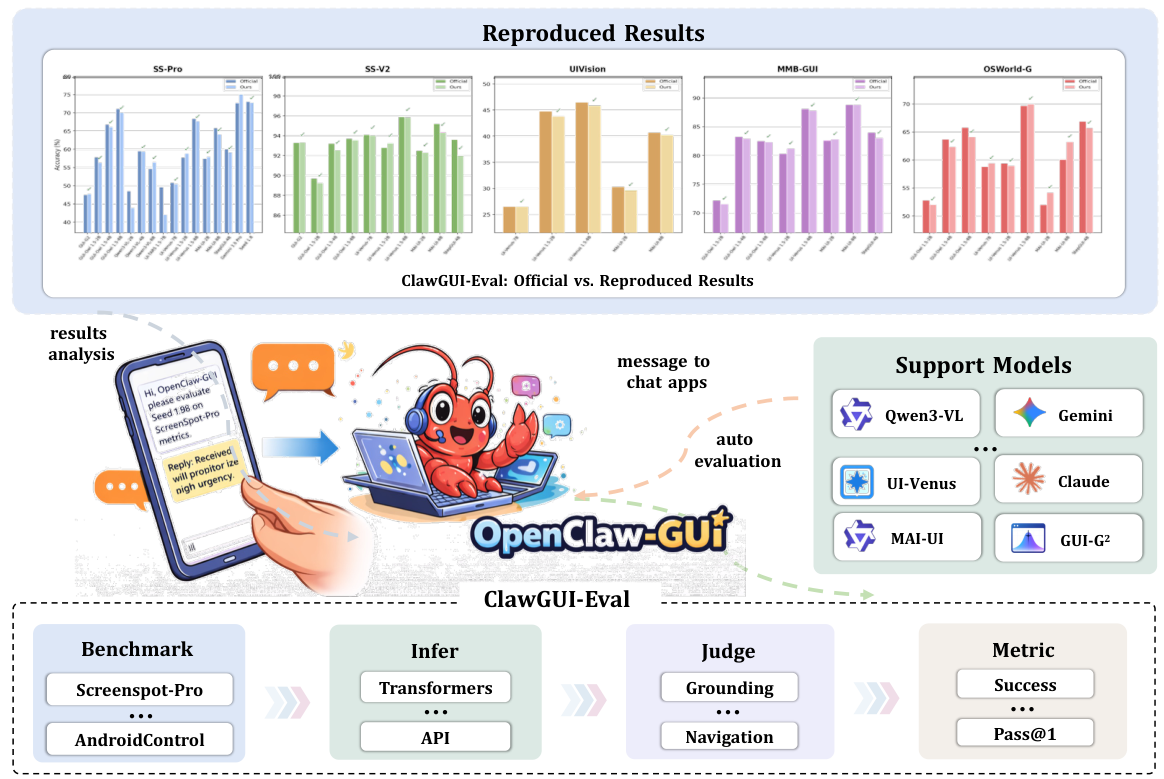
Infer
Given a benchmark and target model, generate raw predictions. Both local GPU inference (Transformers) and remote API inference are supported. Prompt formatting, coordinate normalization, image resolution, and sampling temperature are pinned per model rather than chosen at evaluation time.
Judge
Raw model outputs are parsed and compared to ground truth with benchmark-specific judges: a point-in-box judge for standard grounding, polygon/region judges for complex layouts, and MLLM-based judges for navigation goal achievement. Re-judging old predictions under an updated parser is free — inference is not re-run.
Metric
Per-sample labels are aggregated into accuracy / Pass@1 scores with breakdowns by platform, UI element type, and task category. Every intermediate artifact — predictions, judgments, scores — is canonicalized so anyone can re-score the same predictions independently.
Benchmark & model coverage
ClawGUI-Eval covers 6 benchmarks across GUI grounding and navigation, and supports 11+ models spanning closed and open-source families. Overall reproduction rate against published baselines is 95.8% (46 out of 48 cells with official numbers).
From research pipeline to real users' phones
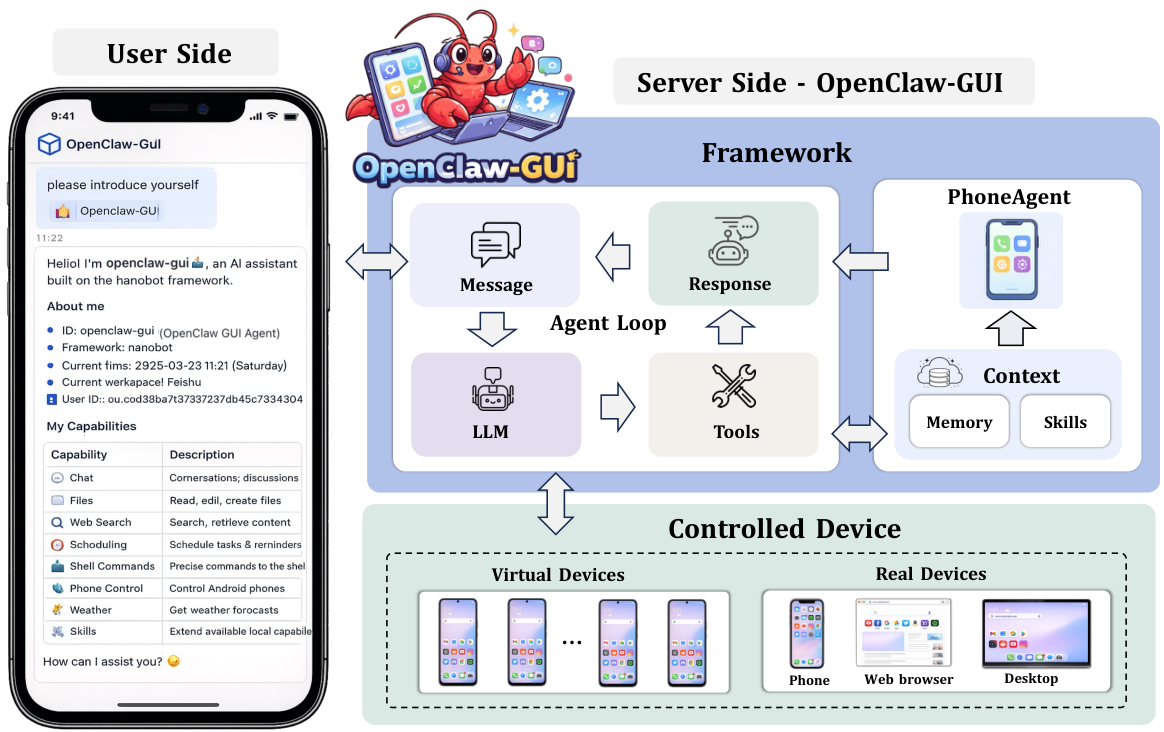
Hybrid CLI + GUI Control
Neither CLI alone nor GUI alone is sufficient. CLI is precise but only reaches applications with programmatic interfaces; GUI has universal coverage but higher step cost. ClawGUI-Agent leverages CLI efficiency where interfaces permit and falls back to pixel-level GUI operation where they do not, combining precision with broad reach.
Personalized Memory
A persistent personalized memory system automatically extracts structured facts from interactions — contact names and relationships, frequent applications, recurring flows, preferences — and feeds them back into the agent's context on future tasks, so the agent actually gets better at serving a specific user over time.
Remote and Local Control
The same agent runtime drives a local emulator, a physical phone on the user's desk, or a remote device farm. In remote control mode the agent is accessed through 12+ chat platforms — Feishu, DingTalk, Telegram, Discord, Slack, QQ, and more — so users can trigger tasks from the app they already use every day.
ClawGUI-Eval as a Deployable Skill
ClawGUI-Eval is exposed to the agent as a first-class tool skill. A single natural-language command triggers a complete benchmark evaluation pipeline — turning the evaluation harness itself into something an end user can invoke, closing the loop from research to deployment.
Evidence the pipeline works end-to-end
ClawGUI-2B is trained end-to-end inside ClawGUI-RL, starting from MAI-UI-2B, using 64 parallel Docker-based virtual environments on 8×A6000 (48GB) GPUs with GiGPO (rollout group size 8). Evaluation is on MobileWorld GUI-Only (117 tasks requiring real-world mobile interactions via vision alone) and the full ClawGUI-Eval benchmark matrix.
Main results
Every step counts: dense reward unlocks better GUI policies
GRPO assigns a single advantage score per episode, which is too coarse for long-horizon GUI tasks where a misclick early in a trajectory can be masked by a later success. GiGPO groups steps by anchor-state: steps reaching the same intermediate state are clustered into sub-groups, and per-step advantages are estimated by discounted return normalization within each group.

Dense step-level supervision via GiGPO yields a 17.9% relative gain over episode-level GRPO, confirming that fine-grained credit assignment is a critical factor in GUI-agent RL training, not an optional luxury.
Benchmarking the benchmarks: can we trust published GUI numbers?
Reproducibility is a prerequisite for meaningful progress, yet GUI evaluation is notoriously hard to reproduce. Prompt ordering, coordinate normalization, image resolution, and sampling configuration each shift reported accuracy by several points — and these choices are often undocumented.
ClawGUI-Eval pins every evaluation choice per model and adopts a strict three-stage Infer → Judge → Metric pipeline across 6 benchmarks and 11+ models. Overall reproduction rate is 95.8% (46 out of 48 cells with official baselines). Open-source models reproduce at 95.7%; closed-source models are slightly harder because API-level sampling variance is outside the evaluator's control.
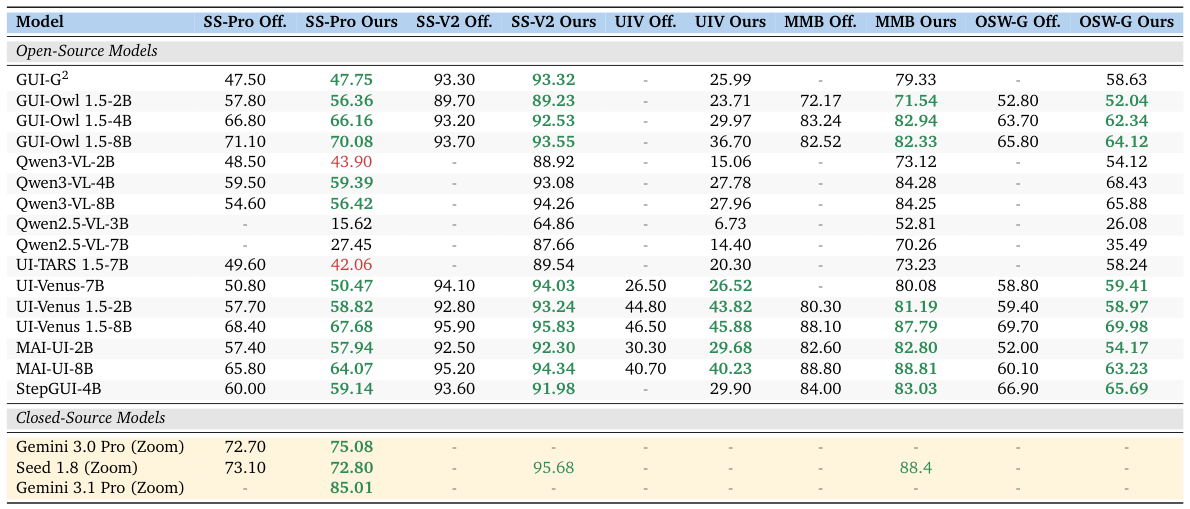
Don't compare papers by their own reported numbers. A standardized harness with pinned evaluation choices shows that published GUI scores deviate from reproducible scores by small but consistent margins — cross-paper comparison requires a shared infrastructure, not trust in individual leaderboards.
What this says about the next year of GUI agents
Toward a unified GUI-CLI agentic harness
The dominant lesson from the past year — from Claude Code and Hermes Agent to MiniMax M2.7's self-evolving loop — is that agent progress happens when training, evaluation, and a real deployment surface are co-designed. ClawGUI's hybrid CLI+GUI control is an explicit bet that the right substrate is not one of CLI alone or GUI alone, but a single harness that can do both and pick the right tool per task.
Scaling online RL beyond emulators
Current GUI-agent RL training is confined almost entirely to emulator sandboxes, which drift from real app behavior and cannot cover the applications that dominate real usage. Code-generation-style authentication-free task distributions that mirror real interaction flows without real user credentials, together with on-device RL using privacy-preserving trajectory collection, are the two paths toward training at the scale real deployment demands.
Toward on-device, always-present system agents
As on-device inference becomes practical, the final shape of a GUI agent looks less like a remote service invoked on demand and more like a persistent system-level intelligence running locally — able to see what the user sees, remember prior context, and act across apps without any per-app integration.
World models for GUI environments
Today's GUI agents act reactively — observe a screenshot, predict an action, wait for feedback. What they lack is an internal model of how the screen will evolve in response to a candidate action. A GUI world model would let the agent imagine several candidate actions before committing, which is the same generalization that transformed robotics and game-playing.
An open stack the community can build on
We presented ClawGUI, a unified open-source framework that integrates online RL training, standardized evaluation, and real-device deployment into a single coherent pipeline for GUI-agent development. ClawGUI-RL provides the first open-source infrastructure validated on both parallel emulators and real physical devices. ClawGUI-Eval gives the community a shared reproducible evaluation harness. ClawGUI-Agent closes the loop from research to end users through everyday chat apps with persistent personalized memory.
ClawGUI-2B, trained end-to-end within this pipeline, reaches 17.1% on MobileWorld GUI-Only and validates the framework as more than a research artifact: it is a usable base layer the community can build on rather than re-implement from scratch.
Show references
- Agashe, J. Han, S. Gan et al. Agent-S: An open agentic framework that uses computers like a human, 2024. arXiv:2410.08164.
- Anthropic. Claude code overview, 2025.
- S. Bai et al. Qwen2.5-VL Technical Report, 2024.
- K. Cheng et al. SeeClick: Harnessing GUI grounding for advanced visual GUI agents, 2024. arXiv:2401.10935.
- L. Feng, Z. Xue, T. Liu, B. An. Group-in-group policy optimization for LLM agent training, 2025. arXiv:2505.10978.
- T. Fu et al. GUI-G2: Gaussian reward modeling for GUI grounding, 2025. arXiv:2507.15846.
- Z. Gu et al. UI-Venus technical report, 2025. arXiv:2508.10833.
- HKUDS. CLI-Anything: Making all software agent-native, 2026.
- W. Hong et al. CogAgent: A visual language model for GUI agents, 2024. arXiv:2312.08914.
- J. Hu et al. Reinforce++: stabilizing critic-free policy optimization, 2025. arXiv:2501.03262.
- Q. Kong et al. MobileWorld: Benchmarking autonomous mobile agents, 2025. arXiv:2512.19432.
- H. Lai et al. AutoWebGLM: A large language model-based web navigating agent, 2024. arXiv:2404.03648.
- H. Lai et al. ComputerRL: Scaling end-to-end online RL for computer use agents, 2025. arXiv:2508.14040.
- K. Li et al. ScreenSpot-Pro: GUI grounding for professional high-resolution computer use, 2025.
- Y. Liu et al. InfiGUI-R1: From reactive actors to deliberative reasoners, 2025. arXiv:2504.14239.
- Z. Lu et al. UI-R1: Enhancing efficient action prediction of GUI agents via RL, 2025. arXiv:2503.21620.
- D. Luo et al. Vimo: Generative visual GUI world model for app agents, 2025. arXiv:2504.13936.
- R. Luo et al. GUI-R1: A generalist R1-style vision-language action model for GUI agents, 2025. arXiv:2504.10458.
- H. Mozannar et al. Magentic-UI, 2025.
- S. Nayak et al. UI-Vision: A desktop-centric GUI benchmark, 2025.
- NousResearch. Hermes-Agent, 2026.
- Y. Qin et al., 2025.
- J. Schulman et al. Proximal policy optimization algorithms, 2017. arXiv:1707.06347.
- B. Seed. Seed1.8 model card: Towards generalized real-world agency, 2026. arXiv:2603.20633.
- Z. Shao et al. DeepSeekMath: Pushing the limits of mathematical reasoning, 2024. arXiv:2402.03300.
- G. Sheng et al. HybridFlow: A flexible and efficient RLHF framework, 2025.
- Y. Shi et al. MobileGUI-RL: Advancing mobile GUI agent through RL in online environment, 2025. arXiv:2507.05720.
- P. Steinberger and OpenClaw Contributors. OpenClaw, 2026.
- F. Tang et al. GUI-G2, 2025a. arXiv:2507.15846.
- F. Tang et al. Think twice, click once, 2025b. arXiv:2503.06470.
- F. Tang et al. A survey on (M)LLM-based GUI agents, 2025c. arXiv:2504.13865.
- V. Team et al. UI-Venus-1.5 technical report, 2026. arXiv:2602.09082.
- H. Wang et al. UI-TARS-2 technical report, 2025. arXiv:2509.02544.
- J. Wang et al. Mobile-Agent-v2, 2024a. arXiv:2406.01014.
- X. Wang et al. MMBench-GUI, 2025.
- Y. Wang et al. OpenClaw-RL, 2026. arXiv:2603.10165.
- J. Wener. OpenCLI, 2026.
- Z. Wu et al. OS-Atlas: A foundation action model for generalist GUI agents, 2024. arXiv:2410.23218.
- H. Xu et al. Mobile-Agent-v3.5, 2026. arXiv:2602.16855.
- Y. Xu et al. Aguvis: Unified pure vision agents for autonomous GUI interaction, 2024. arXiv:2412.04454.
- C. Zhang et al. AppAgent, 2023. arXiv:2312.13771.
- H. Zhou et al. MAI-UI technical report, 2025. arXiv:2512.22047.
- C. Zheng et al. Group sequence policy optimization, 2025. arXiv:2507.18071.
- Y. Zheng et al. Code2World, 2026. arXiv:2602.09856.
- Full citation details are in the original PDF: arXiv:2604.11784.