KnowRL: Boosting LLM Reasoning via Reinforcement Learning with Minimal-Sufficient Knowledge Guidance
RLVR keeps stalling on hard reasoning problems because rewards are sparse, and adding longer prefixes or richer abstractions just introduces redundancy and confusion. KnowRL reframes hinting as a minimal-sufficient guidance problem — decompose hints into atomic Knowledge Points (KPs) and pick a compact, interaction-aware subset with Constrained Subset Search (CSS). At 1.5B scale, KnowRL-Nemotron hits 70.08 average accuracy on eight reasoning benchmarks without KPs at inference (+9.63 vs Nemotron-1.5B) and 74.16 with selected KPs — a new SOTA.
What the paper proposes
RLVR (Reinforcement Learning with Verifiable Rewards) improves the reasoning ability of large language models, but it stalls on hard problems because reward signals are sparse — every rollout fails, so group-based objectives like GRPO see zero gradient. Existing hint-based RL methods patch this by injecting partial solutions or abstract templates, but they treat guidance as a quantity-expansion problem: longer prefixes, richer templates. This introduces redundancy, cross-hint inconsistency, and extra inference overhead.
KnowRL (Knowledge-Guided Reinforcement Learning) reframes hint design as a minimal-sufficient guidance problem. During RL training, KnowRL decomposes hints into atomic Knowledge Points (KPs) — the indispensable mathematical principles for each problem — and uses Constrained Subset Search (CSS) to pick a compact, interaction-aware subset. The paper also identifies a pruning interaction paradox: removing any single KP may help, but removing several at once can hurt — so robust subset curation matters.
Training KnowRL-Nemotron-1.5B from OpenMath-Nemotron-1.5B on CSS-curated data reaches 70.08 average accuracy across eight reasoning benchmarks without KP hints at inference time — already +9.63 over Nemotron-1.5B and +1.50 over JustRL. With selected KPs at inference it further improves to 74.16, a new state of the art at the 1.5B scale. Model, curated data, and code are open-sourced at github.com/Hasuer/KnowRL.
Three Limitations of Existing Hint-Based RL
Recent methods — fixed-ratio prefix hints (QuestA, POPE), adaptive solution hints (StepHint, UFT), and abstraction-based hints (TAPO, Guide, Scaf-GRPO) — all treat stronger guidance as longer prefixes or richer abstractions. Figure 1 illustrates why this axis is the wrong one: it reveals three failure modes that share a common root.

Critical-segment effect
Most of a prefix-style hint is redundant. Accuracy stays flat as you add more tokens until a short decisive segment — the 'critical segment' — is included, and then it jumps. Scaling prefix length thus wastes tokens and obscures which piece of the hint actually carried the signal.
Cross-hint inconsistency
Different hints can suggest different solution routes for the same problem — e.g., the Cayley–Menger determinant vs. 3D coordinate embedding vs. the dispehnoid volume formula for a tetrahedron volume. Layering several of these simultaneously confuses the model rather than helping it.
Guidance-efficiency trade-off
Abstraction-based hints require an external teacher to generate rich templates at inference time. The resulting extra compute and latency buy only marginal accuracy — a poor trade when the goal is a deployable small model.
From 'More Guidance' to 'Minimal-Sufficient Guidance'
RLVR improves LLM reasoning by optimizing rule-based correctness without human preference labels. It is scalable and cheap to supervise, but it suffers from a key bottleneck: reward sparsity on hard problems. When a complex question yields uniformly incorrect rollouts, group-based methods such as GRPO produce zero advantage, so a large fraction of training data contributes no gradient.
The community's response has been hint-based RL: inject auxiliary guidance into prompts to raise the chance of producing a reward-yielding rollout. Three flavors exist — fixed-ratio solution-prefix hints, adaptive solution hints, and abstraction-based hints — but all scale guidance along a token-quantity axis. As Figure 1 shows, that axis hits diminishing returns, layering conflicts, and inference-cost walls.
KnowRL asks a different question: instead of how much guidance, ask what is the smallest sufficient set? Decompose guidance into atomic Knowledge Points (KPs) and build a problem-specific subset that is minimal but interaction-aware. This reframing is what ties the three motivation failures above into one design principle.
Contributions
- Reformulate hint design as a minimal-sufficient guidance problem — not a quantity-expansion problem.
- Introduce Knowledge Points (KPs) as atomic units of guidance, extracted per problem from verified correct solutions.
- Identify and quantify the pruning interaction paradox: removing one KP can help, but removing several at once can hurt more than expected.
- Propose two interaction-aware selection strategies, Constrained Subset Search (CSS) and Consensus-Based Robust Selection (CBRS), and analyze their trade-offs.
- Train KnowRL-Nemotron-1.5B with CSS-selected hints, reaching 70.08 / 74.16 average accuracy on eight reasoning benchmarks — a new SOTA at 1.5B scale.
The KnowRL Framework
At a high level, KnowRL follows a simple end-to-end workflow. For each training problem it (1) constructs candidate Knowledge Points, (2) removes leakage and redundancy to obtain a compact problem-specific subset, and (3) uses the curated subset as hint data for RL training only when guidance is needed. Guidance is attached in the prompt under a ## Hint header (see the augmented prompt example in Appendix C.2 below).
Generate correct solutions
For each problem, sample responses from DeepSeek-R1 until at least one verified correct solution is obtained. This grounds subsequent KP extraction in a real, working chain of reasoning.
Extract raw Knowledge Points
Given the problem and a verified correct solution, prompt DeepSeek-R1 to extract only the indispensable mathematical principles required to solve the problem. This yields an initial candidate KP set K = {k₁, k₂, …, kₙ}.
Leakage verification
To prevent information leakage, DeepSeek-R1 verifies each KP as an automated reviewer. Failed cases are manually revised so that every retained KP is generalizable and not instance-bound.

## Hint section listing curated Knowledge Points — unit conversion, key considerations, knowledge-point references, etc.With all raw KPs injected (avg 5.86 KPs per problem), OpenMath-Nemotron-1.5B only moves from 60.46 → 61.03 average accuracy across eight benchmarks. Raw KP construction alone is not enough — we must pick a problem-specific subset carefully.
Problem-wise KP Subset Selection
For each problem with candidate set K, KnowRL estimates accuracies offline under three configurations: empty set \(\emptyset\), full set K, and leave-one-out K \(\setminus\) {kᵢ}. The goal is a parameterized decision operator \(D_\varepsilon : K \to K^* \subseteq K\) that picks the most helpful subset for each problem. A naive 'Max-Score' baseline chooses among {∅, K, K \ {kᵢ}} — simple but restricts each problem to only three configurations.
Strict Leave-One-Out
With tolerance ε = 0, remove every kᵢ whose single-KP ablation strictly improves over the full-set accuracy. Aggressive pruning, but sensitive to finite-sample noise and prone to over-pruning.
Tolerant Leave-One-Out
With tolerance ε = 1/32, relax the threshold to absorb sampling randomness. T-LOO retains more KPs than S-LOO but still under-performs CSS and CBRS, because jointly removing 'non-essential' KPs can introduce conflicts and cause larger-than-expected accuracy drops.
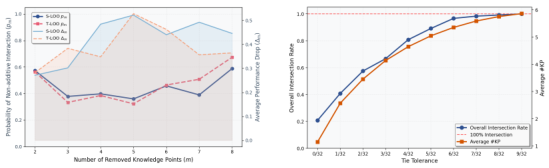
CSS — Constrained Subset Search
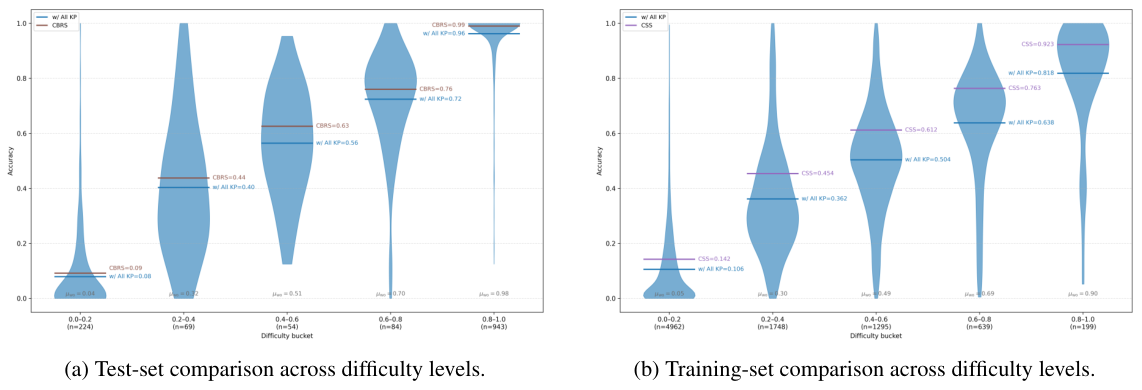
Exhaustive search over 2^|K| subsets is infeasible, so CSS restricts the search space to non-degrading KPs H = {kᵢ | A₋ᵢ ≥ max(A_K, A_∅)}. Within H, near-optimal removals N = {kᵢ ∈ H | A₋ᵢ ≥ A_max − δ} are pruned directly; the remaining candidates C = H \ N are enumerated exhaustively (|C| stays small in practice). The final configuration is chosen as argmaxS A(S) over all enumerated subsets plus ∅ and K. CSS achieves the best offline trade-off in Table 1 — highest average accuracy with compact hint sets.
CBRS — Consensus-Based Robust Selection
Instead of averaging over 8 × 32 samples, CBRS treats each of the 8 independent evaluation runs as a separate vote. For each run it ranks candidate configurations; ties are broken by smallest score variance across the 8 runs, then by smaller hint-set size. CBRS gives strong performance with a compact KP set, but as the ablations show, it slightly under-performs CSS on the hardest benchmarks.
Training KnowRL-Nemotron-1.5B
KnowRL is evaluated on four axes — training data construction, training setup, evaluation protocol, and final benchmark results. Training uses QuestA (8.8k instances after dedup, CSS-selected KPs) with OpenMath-Nemotron-1.5B as the backbone; RL runs for 2,960 steps on 8× H100 nodes (64 GPUs total) for about 13 days of wall-clock time.
Headline Numbers
Training Setup
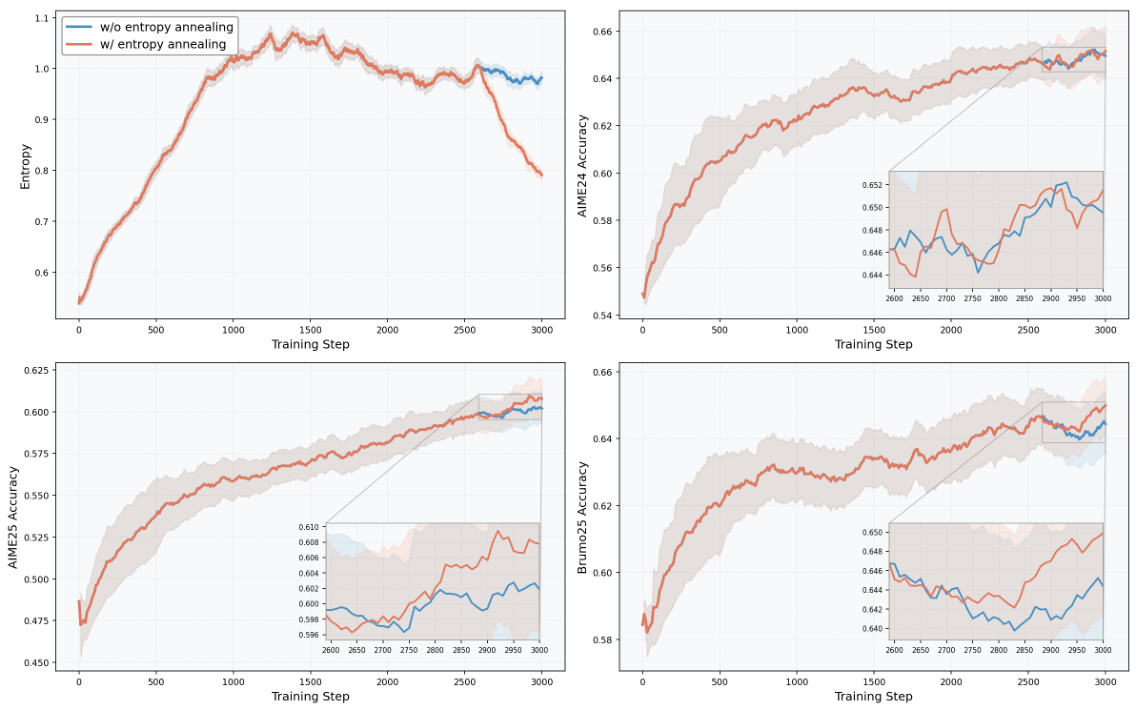
Batch size 256 with four updates per step; constant learning rate 1e-6; clip-ratio range [0.8, 1.28]; 8 samples per question at top_p = 1.0, T = 1.0; max response length 24k; token-mean loss; no KL loss and no entropy bonus; dynamic sampling enabled. Entropy annealing is used: with clip_high = 0.28, entropy rises early (encouraging exploration), then begins to decrease at step 2,590 as the model searches for optimal paths. Evaluation follows the JustRL protocol — rule-based verifier (mathverify 0.8.0) with fallback to Compass Verifier-3B; 32k max tokens, top_p = 0.7, T = 0.9, 8 samples per problem on AIME24/25, HMMT25, CMIMC25, BrumoS25, MATH-500, Olympiad-Bench.
Main Results
Across all eight benchmarks, KnowRL-Nemotron-1.5B consistently posts the strongest overall numbers. Even without KP hints at inference it reaches a 70.08 average — clearly surpassing Nemotron-1.5B by +9.63 and JustRL by +1.50. With CBRS-selected KPs the average rises to 73.46 and with CSS-selected KPs to 74.16. Gains are particularly pronounced on competition-style benchmarks: under CSS, +15.11 on AIME25, +12.98 on HMMT25, and +15.49 on CMIMC25.
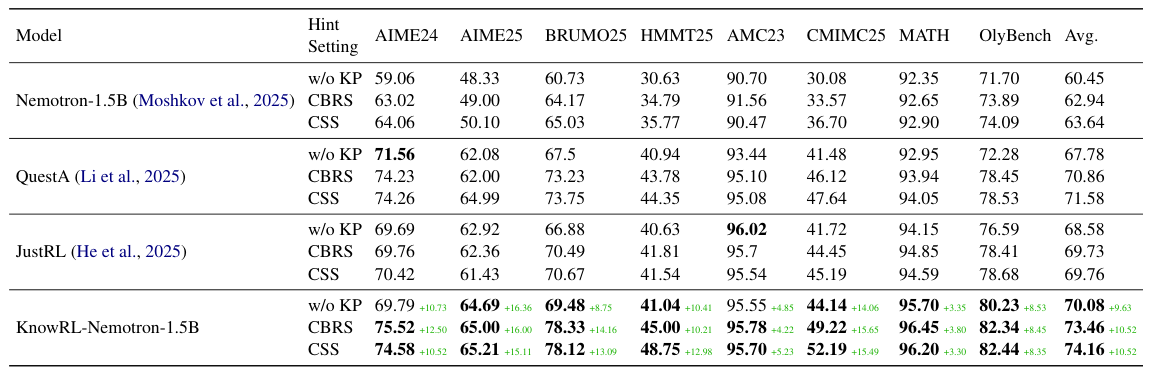
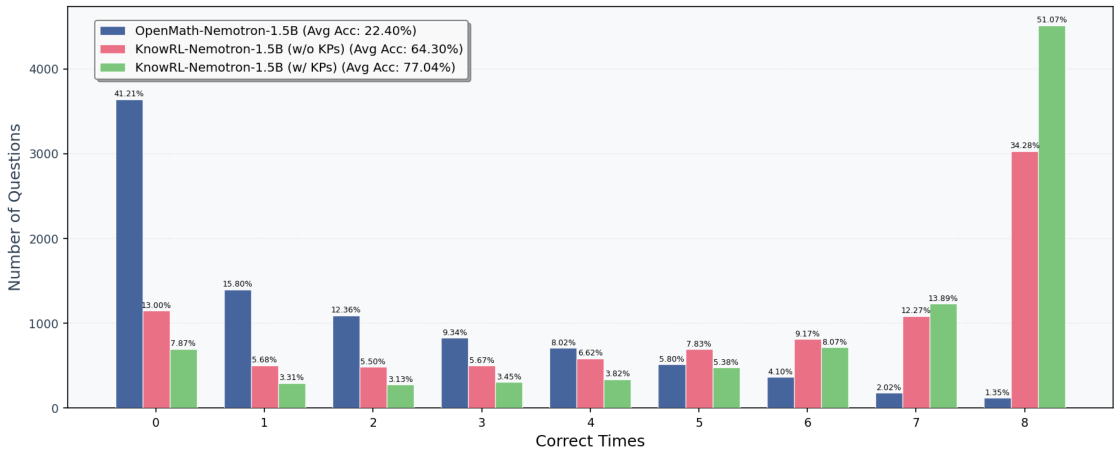
Even without KP hints at inference, KnowRL-Nemotron-1.5B's policy is meaningfully stronger (70.08, +9.63 over the backbone). The selected-KP setting (74.16) adds an inference-time boost on top. The largest gains appear on the hardest competition-style benchmarks — exactly where reward sparsity used to kill the learning signal — confirming that KnowRL improves policy quality itself, not just prompt-time scaffolding.
CSS vs CBRS — Which Selection Strategy Wins?
CSS and CBRS select comparable numbers of KPs per problem, so comparing them isolates selection quality from guidance volume. Section 5 of the paper studies their training dynamics and downstream accuracy under matched training budgets.
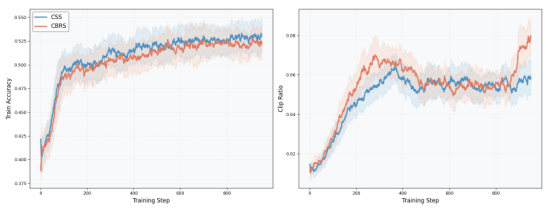
CSS — stable, global search
Prunes low-value candidates first, then enumerates over a small constrained set — a broader search for high-quality global configurations. Consistently leads under matched budgets (65.00 vs 64.68 at step 400; 66.46 vs 65.72 at step 900) and wins the hardest benchmarks (HMMT25, CMIMC25).
CBRS — noise-robust consensus
Aggregates votes across independent rollouts, so it is robust to sampling noise when the candidate pool is small. Induces slightly more aggressive policy updates (higher clip ratio late in training) which can help in some regimes but tends to be less stable than CSS on the hardest reasoning splits.
What KnowRL Changes About RLVR
KnowRL reframes hint design for RLVR as a minimal-sufficient guidance problem rather than a quantity-expansion one. By decomposing prefixes and abstractions into atomic Knowledge Points and selecting robust subsets via Constrained Subset Search, it sidesteps the critical-segment effect, cross-hint inconsistency, and guidance-efficiency trade-off all at once.
The paper also isolates a pruning interaction paradox — removing one KP can help, while removing several can hurt more than expected — and shows that CSS handles it explicitly. KnowRL-Nemotron-1.5B sets a new state of the art at the 1.5B scale (70.08 / 74.16 average) and ships with publicly available model, training data, and code, inviting reproducible follow-up work on minimal-sufficient guidance for reasoning RL.
References (20+ entries — click to expand)
- M. Balunović, J. Dekoninck, I. Petrov, N. Jovanović, M. Vechev. MathArena: Evaluating LLMs on uncontaminated math competitions, 2025.
- Y. Chen, J. Sheng, W. Zhang, T. Liu. Improving reasoning capabilities in small models through mixture-of-layers distillation. EMNLP 2025.
- D. Guo et al. DeepSeek-R1 technical report, 2025a.
- K. Li et al. QuestA: Curriculum-based solution-prefix hint RL, 2025.
- Y. Liu et al. UFT: Unified fine-tuning with adaptive hint ratios, 2025a.
- Y. Liu et al. Compass Verifier-3B, 2025b.
- Z. Moshkov et al. OpenMath-Nemotron-1.5B technical report, 2025.
- S. Nath et al. Guide: Template-based reasoning guidance for RL, 2025.
- N. Nie et al. Scaling RL with verifiable rewards, 2026.
- Y. Qu et al. POPE: Prefix-optimized policy exploration, 2026.
- Z. Shao et al. GRPO: Group Relative Policy Optimization in DeepSeekMath, 2024. arXiv:2402.03300.
- B. Team et al. Open-source reasoning model release, 2025.
- R. Team et al. RLVR foundations, 2026.
- Y. Wang et al. RL for reasoning: a survey, 2026.
- Z. Wu et al. TAPO: Template-augmented policy optimization, 2025.
- Q. Yu et al. Dynamic sampling for RL training, 2025.
- H. Zhang, Math-AI. AIME24 benchmark, 2024.
- H. Zhang, Math-AI. AIME25 benchmark, 2025.
- K. Zhang et al. StepHint: Adaptive step-level hints for RL, 2025b.
- L. Zhang et al. Scaf-GRPO: Scaffolded GRPO with abstract hints, 2025c.
- HMMT25, CMIMC25, BrumoS25, MATH-500, Olympiad-Bench: standard reasoning evaluation suites used in this paper.
- Full reference list available in the arXiv PDF.