Toward Autonomous Long-Horizon Engineering for ML Research
Abstract
Autonomous AI research has advanced rapidly, but long-horizon ML research engineering remains difficult: agents must sustain coherent progress across task comprehension, environment setup, implementation, experimentation, and debugging over hours or days. We introduce AiScientist, a system built on a simple principle — strong long-horizon performance requires both structured orchestration and durable state continuity. AiScientist combines hierarchical orchestration with a permission-scoped File-as-Bus workspace: a top-level Orchestrator maintains stage-level control through concise summaries and a workspace map, while specialized agents repeatedly re-ground on durable artifacts such as analyses, plans, code, and experimental evidence rather than relying primarily on conversational handoffs — yielding thin control over thick state. Across two complementary benchmarks, AiScientist improves PaperBench score by 10.54 points on average over the best matched baseline and achieves 81.82 Any Medal% on MLE-Bench Lite. Ablation studies further show that the File-as-Bus protocol is a key driver of performance: removing it reduces PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points. These results suggest that long-horizon ML research engineering is a systems problem of coordinating specialized work over durable project state, rather than a purely local reasoning problem.
Three Ideas at a Glance
Thin Control over Thick State
The Orchestrator keeps only a small, stable context across stage transitions. All the heavy project state — paper analyses, plans, code, logs, experiment records — lives outside the conversation, in a permission-scoped shared workspace.
File-as-Bus Coordination
Agents coordinate by reading and writing role-aligned artifact regions (paper_analysis/, submission/, append-only logs) rather than by chatting. Removing this bus drops MLE-Bench Lite Any Medal by 31.82 points.
Benchmarks Back It Up
PaperBench improves by 10.54 points on average over the best matched baseline; MLE-Bench Lite reaches 81.82 Any Medal%. Gains hold under both Gemini-3-Flash and GLM-5 backbones.
1. Introduction
Automating scientific research has emerged as one of the most ambitious goals in artificial intelligence. In ML specifically, progress could substantially accelerate discovery, improve reproducibility, and broaden access to high-quality research systems.
Within this broader agenda, we focus on a more operationally demanding setting: autonomous long-horizon engineering for ML research. An agent must own the end-to-end technical work of building, running, and iteratively improving ML research systems over hours or days. Concretely, the difficulty arises from underspecification, system setup burden, delayed and often confounded experimental feedback, and the need to maintain state continuity across iterations.
We address this challenge with AiScientist. Our central design principle is to treat long-horizon performance as a joint problem of orchestration and state continuity: agents must not only coordinate work across heterogeneous stages, but also preserve evolving project state with enough fidelity for later decisions to build on it safely.
Our Contributions
- We introduce AiScientist, a system for autonomous long-horizon ML research engineering that supports the full loop from interpreting research specifications and setting up runnable systems to experimentation and iterative refinement.
- We propose an artifact-mediated coordination design that combines hierarchical orchestration with a permission-scoped shared workspace. Through a File-as-Bus protocol, the system preserves state continuity via durable artifacts while keeping top-level control lightweight.
- We evaluate AiScientist on PaperBench and MLE-Bench Lite, showing substantial gains over strong baselines and yielding empirical insights into long-horizon ML research engineering — especially the importance of durable state continuity.
2. Task Formulation
We formulate the long-horizon ML research engineering task through PaperBench. Given a research paper P, a bare Docker environment E with GPU access, and a time budget T, the agent must produce a runnable submission that reproduces the paper's target metrics.
Four challenges that make this hard
Research specifications are typically incomplete rather than complete blueprints. Important implementation details are often implicit, scattered across sections, or omitted entirely, so the agent must recover them from sparse cues.
Success depends on substantial setup work beyond algorithmic implementation: configuring environments, acquiring datasets and models from permitted sources, and integrating these resources into a runnable system.
Meaningful evidence arrives only after experiments run. Discrepancies may stem from interpretation, implementation, data processing, or infrastructure, so the agent must reason from delayed and often confounded signals.
Each round produces code, configurations, logs, results, and diagnostic evidence that later decisions must correctly interpret and build on. Progress depends on maintaining continuity across iterations.
3. AiScientist: an Artifact-Mediated Research Lab
AiScientist is built around a simple systems view of long-horizon ML research engineering: strong performance depends not only on decomposing work into the right stages, but also on preserving evolving project state with enough fidelity that later decisions can build on it safely. A Tier-0 Orchestrator keeps thin stage-level control through concise summaries and a workspace map, while Tier-1 specialists and optional Tier-2 subagents operate over a shared, permission-scoped workspace.
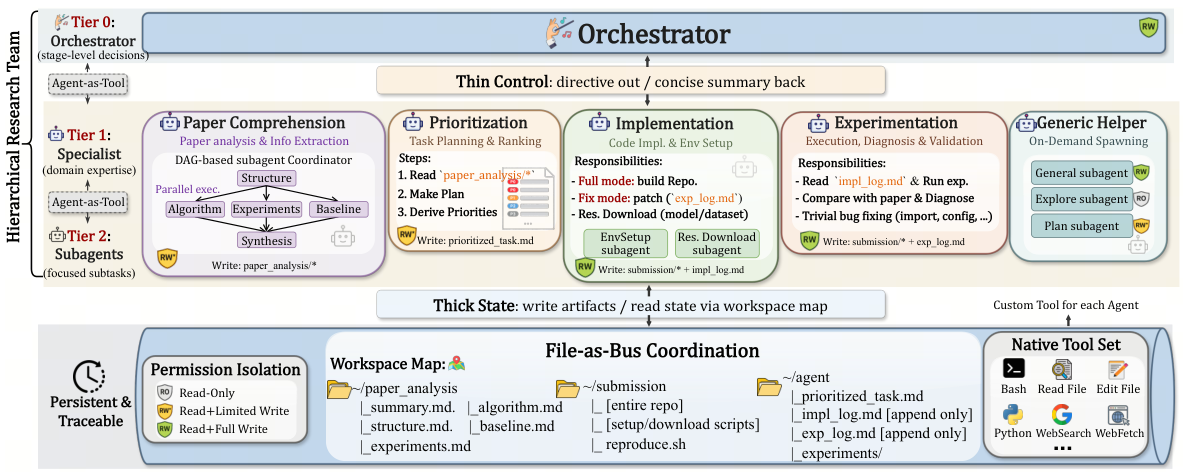
3.1. Thin Control over Thick State
The core systems principle of AiScientist is thin control over thick state. Here, thin refers to the small, stable context needed to make routine control decisions, whereas thick refers to the much larger body of externalized project state that must remain faithful across iterations.
Let W_t denote the workspace at step t. A lightweight workspace map m_t is maintained as a textual index of the major artifact regions and their roles.
Formal formulation
Workspace map: a textual index of artifact regions — a navigational interface to the workspace, not a lossy replacement.
$$m_t = \mathcal{M}(W_t)\tag{1}$$
Orchestrator action selection: the top-level controller chooses the next action using the stage-level context and the workspace map, optionally inspecting the workspace on demand.
$$a_t = \mathcal{T}_0(c_t, m_t, G; W_t),\ a_t \in \mathcal{T}_0 \cup \mathcal{A}_1 \tag{2}$$
Specialist invocation: a specialist runs its own local loop and returns only a concise summary together with workspace updates.
$$(s_t, \Delta W_t) = \tau_j(d_t, m_t; W_t),\quad c_{t+1} = c_t \oplus s_t,\quad W_{t+1} = U(W_t, \Delta W_t) \tag{3}$$
Reading the equations without a math background
Equations (1)–(3) look intimidating, but each one describes a very concrete everyday move:
- (1)
m = M(W): automatically generate a table of contents for the entire project folder. The table is short; the folder is huge. - (2) Orchestrator picks action: the boss looks at the table of contents and a short status note, then decides "run shell command" or "call the Paper Comprehension specialist." No long chat history needed.
- (3) Specialist returns: the specialist does its internal work, writes or edits files, and hands back a two-line summary plus a list of changed files. The boss only absorbs the summary.
The notation hides it, but the takeaway is operational: the boss never reads a novel-length transcript; they read a TOC and a bullet summary.
This design realizes progressive disclosure at the level of control and handoff. The Orchestrator carries only a small, stable control interface across stage transitions, making decisions from summaries and the map rather than from accumulated chat history.
3.2. File-as-Bus Coordination
AiScientist implements artifact-mediated coordination through a File-as-Bus protocol. In long-horizon ML research engineering, the critical intermediate state is already naturally file-valued: paper analyses, environment-setup scripts, resource-download manifests, training code, checkpoints, evaluation metrics, and append-only execution logs. The workspace is treated as the system of record rather than passive storage.
Three role-aligned artifact regions
paper_analysis/
submission/
reproduce.sh entry point, written by Implementation and Experimentation specialists.impl_log.md · exp_log.md
Because state lives in durable artifacts rather than in a shared chat, agents can re-enter the project from the current workspace state, read task-relevant regions, and act without needing the full prior discourse.
Analogy: Slack vs. Git
Most multi-agent systems coordinate through something like Slack threads — messages and replies pile up until nobody can find anything. File-as-Bus coordinates more like Git + a shared repo: every agent reads the current files, makes its change, writes it back, and the next agent picks up from that file — not from 400 messages of chat history. That's why it scales to 24-hour autonomous runs where older agents would lose the plot.
3.3. Hierarchical Orchestration via Agent-as-Tool
If File-as-Bus coordination provides the state substrate, hierarchical orchestration provides the control mechanism. The Orchestrator routes the right expertise to the right stage — from comprehension to planning, implementation, experimentation, and debugging — while specialists run their own local loops and Tier-2 subagents handle focused leaf subtasks.
The key design choice is Agent-as-Tool: each specialist is exposed to the Orchestrator through the same callable interface as ordinary tools such as shell execution, file inspection, or web search. Delegation is an action within the Orchestrator's normal tool-use loop, and each specialist's private context is re-initialized at each invocation so detailed reasoning does not accumulate at the top level.
Tier-1 specialists
Transforms the paper into implementation details, target metrics, and uncertainty notes. Can coordinate multiple subagents so that independent analytical dimensions are processed in parallel before synthesis.
Converts paper understanding into an ordered execution contract: identifies dependencies, ranks milestones by impact and feasibility, and writes the plan to prioritized_tasks.md.
Turns plans and failure reports into code. Full mode builds the reproduction repo from analysis artifacts and the prioritized plan. Fix mode patches the existing codebase in response to directives.
Executes the end-to-end pipeline, compares produced metrics against the paper's targets, and records results and unresolved issues in exp_log.md.
Spawns lightweight helpers for auxiliary subtasks such as exploration, planning, or one-off operations that do not warrant a dedicated specialist workflow.
Tier-2 subagents are tightly scoped leaf workers created within a specialist's local horizon — structure extraction, algorithm and baseline analysis, environment setup, resource download, and exploratory investigation.
3.4. Evidence-Driven Research-Engineering Loop
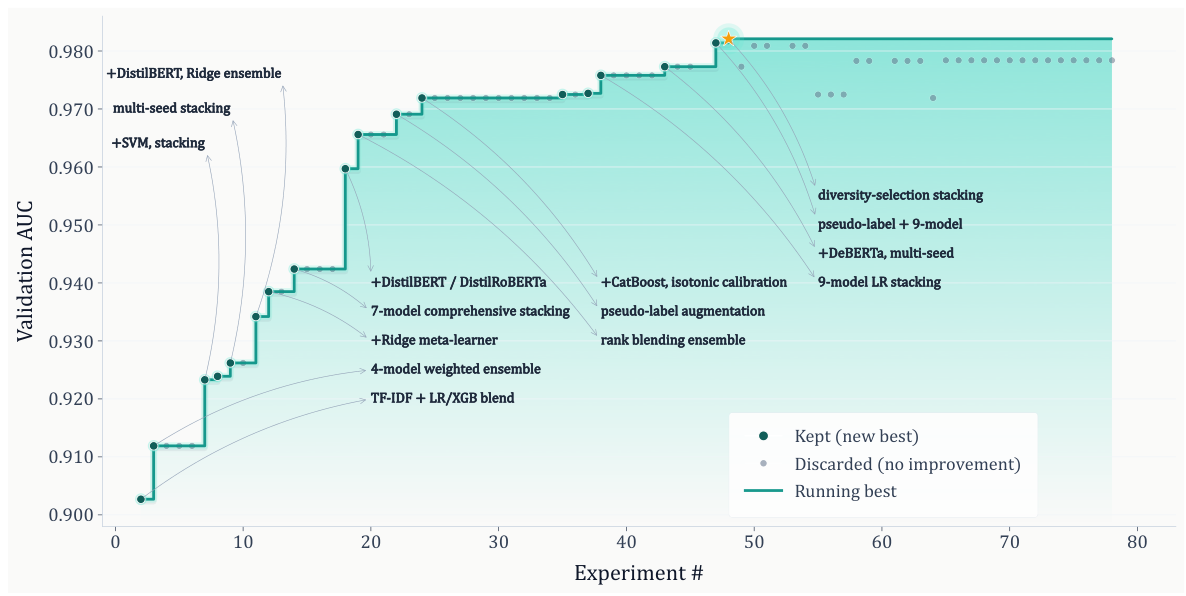
AiScientist runs an evidence-driven research-engineering loop over the evolving workspace rather than a rigid one-pass pipeline. Early in the trajectory, the Orchestrator emphasizes paper comprehension and prioritization so that implementation proceeds from a clear, ranked plan. Once a scaffold exists, the dominant pattern becomes iterative alternation between implementation and experimentation.
This loop is driven by executable evidence. Experimental runs produce failure traces, partial successes, metric gaps, and resource bottlenecks that determine what should be built, fixed, or tested next. These outputs are written back as durable artifacts so future iterations can reason about them precisely.
4.1. Experimental Setup
Benchmarks
From-scratch replication of top-tier conference papers. Evaluates whether an agent can go from an unfamiliar paper to a working reproduction inside a bare Docker environment.
Kaggle-style ML competitions that emphasize sustained experiment improvement. Success requires not one submission but many rounds of iterative refinement.
Baselines
On PaperBench we compare against BasicAgent and IterativeAgent under the same evaluation protocol. On MLE-Bench Lite we report controlled comparisons against strong autonomous ML engineering systems (AIDE, LoongNow, ML-Master) and additionally include official leaderboard results as contextual reference.
Implementation Details
We instantiate AiScientist with two backbone LLMs: Gemini-3-Flash and GLM-5. Across both benchmarks, each run is allocated one H20 GPU and a 24-hour budget per task.
4.2. Main Results on PaperBench
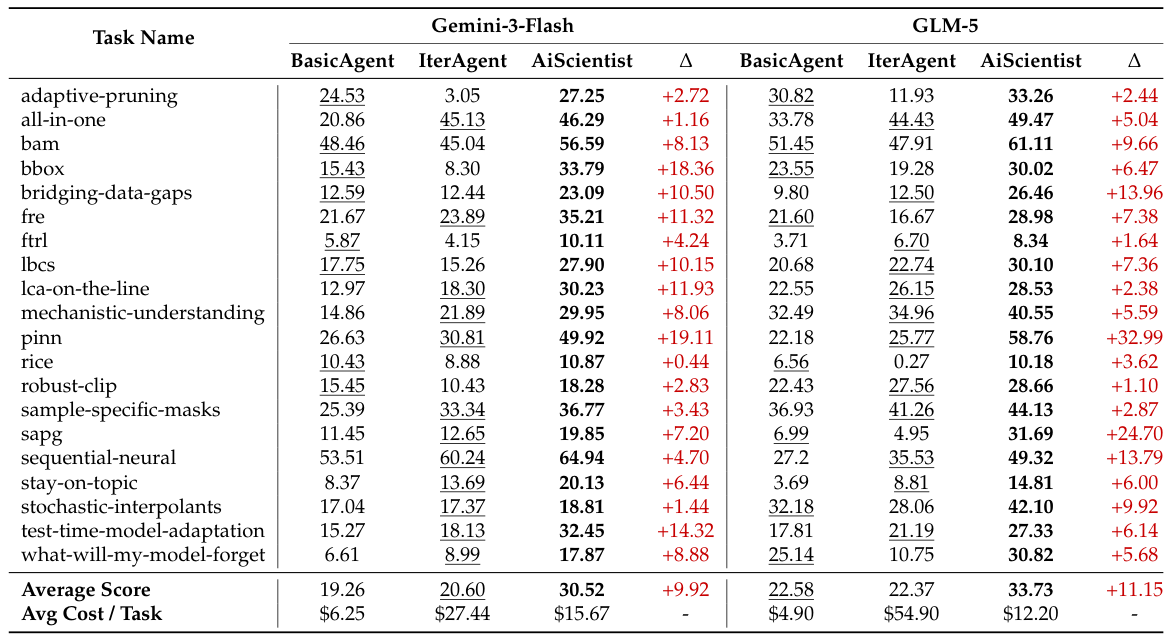
Across both backbones, AiScientist improves over the best matched baseline by 9.92 and 11.15 points, respectively. It also narrows the gap to the reported human baseline of 41% after 48 hours of effort.
Compared with IterativeAgent, AiScientist attains substantially higher average scores at much lower cost per task: $15.67 vs $27.44 under Gemini-3-Flash, and $12.20 vs $54.90 under GLM-5. The gain is not coming from simply buying more interaction time.
4.3. Main Results on MLE-Bench Lite
MLE-Bench Lite complements PaperBench by focusing on sustained experiment improvement on competition-style ML tasks, where success depends less on one-shot reproduction and more on whether an agent can iteratively refine a pipeline.
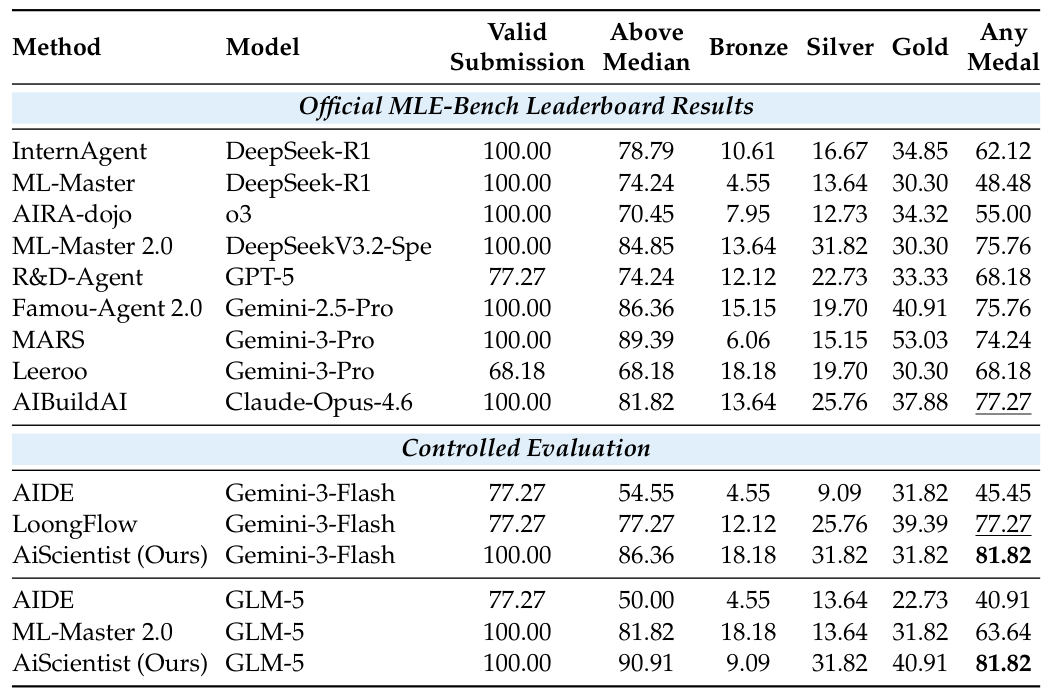
On the controlled evaluation, AiScientist delivers the strongest overall performance under both backbones. It reaches the same 81.82 Any Medal% with Gemini-3-Flash and GLM-5, improving over the strongest matched baseline by 4.55 and 18.18 points, respectively. This also exceeds all reported leaderboard Any Medal values listed in Table 2.
4.4. Mechanism Analysis
We analyze which mechanisms account for the gains of AiScientist. We focus on two questions: whether durable artifact-based continuity is a key driver, and whether simpler non-hierarchical agent organizations would suffice.
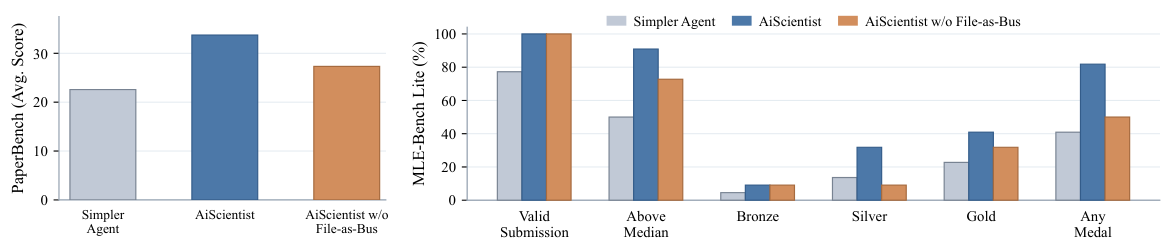
File-as-Bus Ablation
Removing File-as-Bus drops PaperBench by 6.41 points and MLE-Bench Lite Any Medal by 31.82 points. Valid Submission and Bronze are largely intact, but losses concentrate on the stronger outcome metrics (Above Median, Silver, Gold). Durable artifacts matter more for later-round refinement than for a minimally competitive first submission.
Simpler Agent Comparison
The gains are not merely from adding interaction volume. IterativeAgent already adds more interaction than BasicAgent yet still trails AiScientist without File-as-Bus — indicating that hierarchical orchestration adds value beyond longer chat sessions.
Why "Valid Submission" survives but "Gold" collapses without File-as-Bus
This asymmetry is the most interesting finding of the ablation. A first minimally-working submission only requires the agent to produce any runnable pipeline — one good round of implementation is often enough, so losing durable state doesn't hurt much. Gold medals, by contrast, require dozens of iterative refinements where each round must build correctly on all the tuning, failed experiments, and metric history from previous rounds. That's exactly where a reliable artifact record becomes load-bearing: without it, the agent keeps re-deriving decisions it already made and loses signal about what has and hasn't been tried.
Product takeaway: if you're building a long-running AI agent and it plateaus after "first working version," suspect a state-continuity problem before suspecting the LLM.
6. Conclusion
Autonomous long-horizon ML research engineering is difficult because failures surface late, their causes are often confounded across interpretation, implementation, and infrastructure, and progress must remain coherent across repeated implementation–experimentation cycles. AiScientist reframes this as a systems problem — coordinating specialized work over durable project state — and demonstrates that the combination of hierarchical orchestration and File-as-Bus coordination yields substantial gains on both PaperBench and MLE-Bench Lite. We hope the thin control over thick state principle offers a useful lens for future long-horizon autonomous research systems.