[0:00:00]
Imai-san, Anthropic's Claude is really something, isn't it?
Well, you see, Mythos was released yesterday
On April 7th
I saw it in the morning
And the first thing I did when I saw it was
I checked how long April Fools' Day lasts in America
That doesn't make any sense
April Fools' is only April 1st
Well, yes
But Mythos's scores were so unbelievable
That I thought this must be
A belated April Fools' joke from Anthropic
Well, not that I was sure, but I thought there was a chance
So I searched "American April Fools'" and looked it up
And since it's only April 1st, I thought, well then this must be real
That was the first thing I did
So Anthropic has announced a new AI model
Called Claude Mythos
But they've said it's too dangerous to make available to everyone
So they're withholding general release
And honestly, your first impression
Since we can't use it, all we have is the data and benchmarks
Which we'll look at in detail later
But based on what's been publicly released
What was your first impression?
It wouldn't be surprising for it to receive that kind of treatment
It wouldn't be surprising, but
I thought "here we go again"
There was something called GPT-2, you see
From the old days of OpenAI
GPT-2 -- well, the GPT of that era
Could only hold kindergartener-level conversations
So it's kind of a joke now
But when it was first announced by OpenAI back in 2019
The reaction was
"This thing is too dangerous, so we won't release it"
They ended up releasing it eventually
But that's what happened
And I'd like everyone to go look at the GPT-2 paper
Because among the authors you'll find the name Dario Amodei
And who is Dario Amodei?
He's the head of Anthropic
The CEO
So my reaction was kind of like, "So he's done it again"
That was my impression
But back then, GPT-2 was eventually released
And did the world fall into chaos?
Well, its successor models may have turned the world upside down
But GPT-2 alone didn't cause that much trouble
And now it's actually laughed at
But Mythos, at least if you take the publicly released information at face value
It wouldn't be surprising for it to receive that kind of treatment
This show has always said that Anthropic has a particularly strong philosophy on safety
And I'd encourage you to watch our video on Dario Amodei and Anthropic from February
Even back then, his awareness and philosophy regarding safety
Was incredibly strong
Dario Amodei
This same person who stopped the release at OpenAI
Has now stopped general release at Anthropic too
It feels like we've entered a new stage of AI
There are probably purely commercial reasons too, with the high operational costs
But it does feel like we've entered a new era
Understood
So Anthropic has announced a new AI model, Claude Mythos
And they've said it's too dangerous for general release
So let's explore this with Shota Imai on AI Quest
Today's theme is
"The Most Powerful AI That Can't Be Released to the Public: The Power of Claude Mythos"
Right, so today we'll look at three topics
First, the power of Claude Mythos
There's a lot of benchmark data out
And we'll examine this in detail with Imai-san
Second, Anthropic's dominance has begun
Their business momentum has been incredible lately
What exactly is happening right now
Behind the scenes, there's even talk that Meta might be a super-heavy user of Claude
So we'll look into that as well
And speaking of Meta
The third and final topic
Some breaking news
Meta has announced a new AI model
Called Muse Spark
This recording is happening on the morning of April 9th
And it was announced late last night, or rather early this morning
This is effectively among the fastest coverage in Japan
Yes, that's right
They announced an AI model
Which is the first model released since the Superintelligence Labs
Was established last year
There's a lot of information coming out about this too
So we'll look at that in detail at the end
So first, the power of Claude Mythos
Let's start with the most straightforward aspect
We've looked at various AI model benchmarks on this show before
The metrics used to evaluate them, the numbers
So how impressive is Claude Mythos by those numbers?
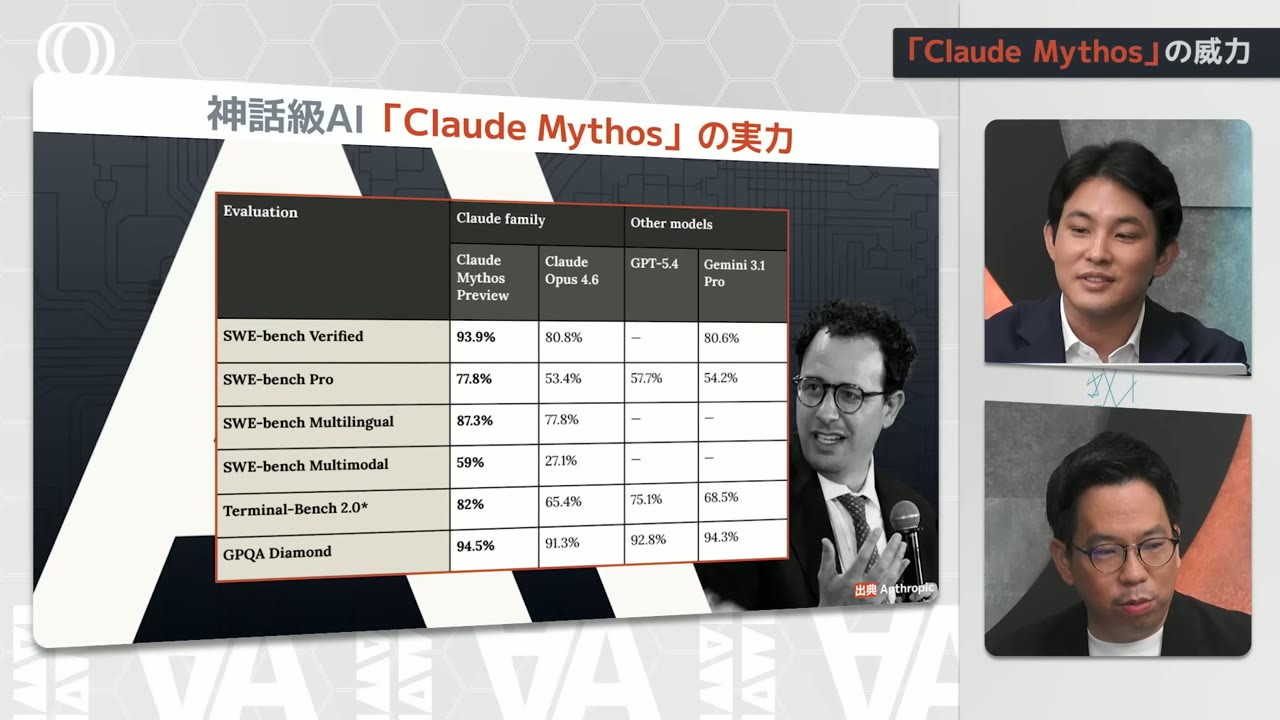
Looking at SWE-bench
For example, software engineering, coding ability
These numbers are incredibly high
I was amazed that it jumped by double digits
[0:05:00]
No matter how fiercely OpenAI
Claude, Anthropic, and
Google competed
A 4-5% improvement was considered impressive
And now it's jumped by 10-plus percent
20-plus percent
I couldn't believe it could leap this much at once
This is probably the first time since GPT-4
That we've seen a leap of this magnitude
This is really something
Originally, this is probably the level of improvement
That people expected from GPT-5
That's right
Everyone was kept waiting and waiting
With all the hints and teasers
And then Anthropic just casually dropped this
With these kinds of numbers
Unfortunately, since the model isn't publicly released
We can't actually verify it ourselves
But at least by benchmark evaluation
Something truly extraordinary has emerged
That's beyond question
I see
Right
There are various types of SWE-bench
But basically they measure coding ability
And with coding ability this strong
It's no wonder there are security concerns
Originally, before this official release
Mythos had been the subject of somewhat shady news
There were leaks that Anthropic had something called Mythos
And that it was unintentionally exposed
And it caused security concerns
There was an incident where cybersecurity stocks dropped
About one or two weeks before the official announcement
But honestly, when I saw those reports at the time
I didn't think it would be this powerful
I figured at best it would be Opus 4.6-era
The usual level of incremental improvement
I didn't expect it to jump this much
That's right
We covered Opus 4.6 on this show back in February
At that time we also talked about how impressive its work capabilities were
And it's only been about a month and a half since then
But I think when we were talking about Opus 4.6 at the time
Mythos was probably already done
There was a similar story with GPT-4 and ChatGPT
You should check out Sam Altman's biography for reference
But by August 2023, GPT-4 was apparently already complete
But they thought it was too powerful
So they planned to release a toned-down version as ChatGPT
But it unexpectedly took off
And then they released GPT-4 in March
So frontier models are sometimes ready internally for a while
And I think Mythos was probably also in use internally
Looking at the recent Claude Code source code leak
Claude Code's code was heavily focused on vibe coding
And from what I could see, I think they were probably running Mythos
I see
Now let's look at some other benchmarks
This show has covered multiple times
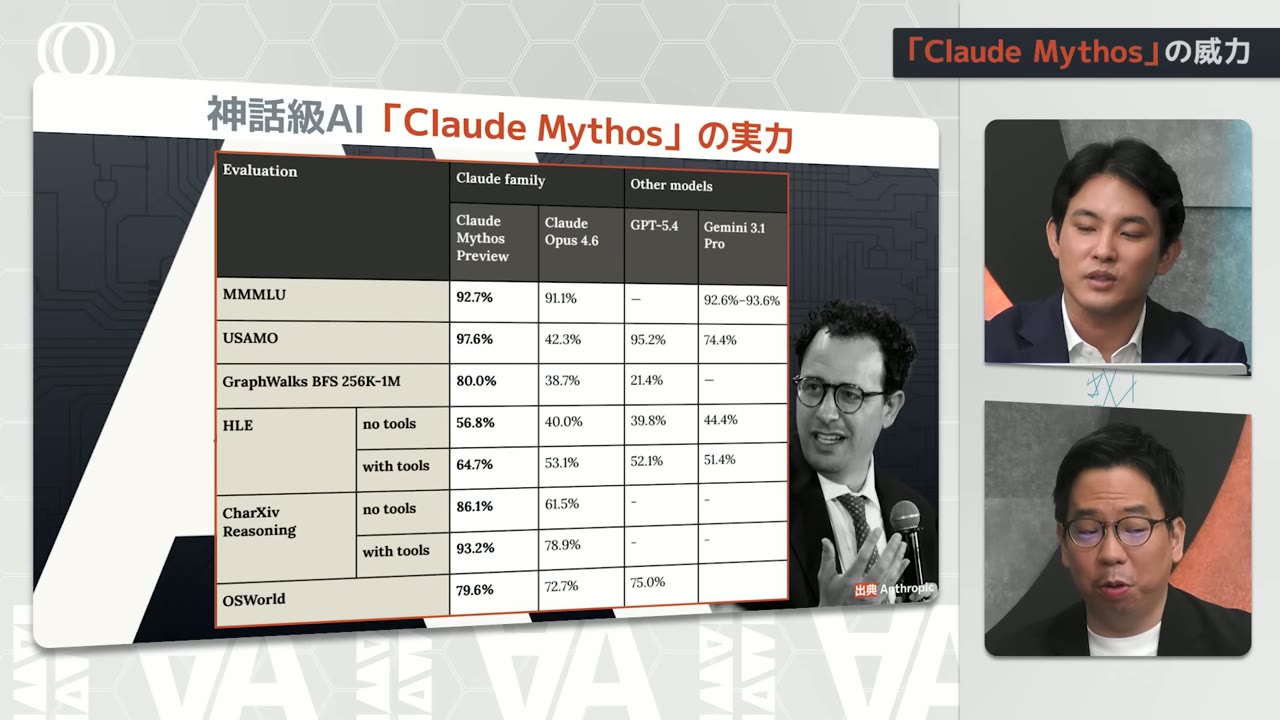
The HLE -- Humanities Last Exam
The incredibly difficult test that AI models are given
And on this one too
I was amazed it broke through 60
It really jumped, didn't it?
The last time something exceeded 50
Was Grok's tool-use result, take what Elon Musk says with a grain of salt
But that was about a year ago
And for it to jump by over 10% from there
Everything had been stuck at 50-something
50-something for a while
And then suddenly it jumps by over 10%
Plus the raw score is impressive, but
What's really remarkable is
It achieved this while also excelling at coding
Regarding something we discussed recently
OpenAI with 5.4
GPT-5.4 kind of quietly released its HLE score
Without making much noise about it
I won't say they hid it, but
They sort of quietly published it
It didn't go up that much, apparently
So normally, Anthropic's Claude
Is doing all-out enterprise-focused development
If you're going all-in on that
I would have thought the overall HLE score wouldn't improve that much
But it jumped dramatically there too
The fact that coding performance reached those heights
While general capabilities also improved simultaneously
That really surprised me
When I saw the combination of SWE-bench
And HLE scores
I suspected it was April Fools'
Like, can these two things even coexist?
Indeed, with GPT-5.4 there was a sense that they couldn't coexist
And Mythos has completely overturned that
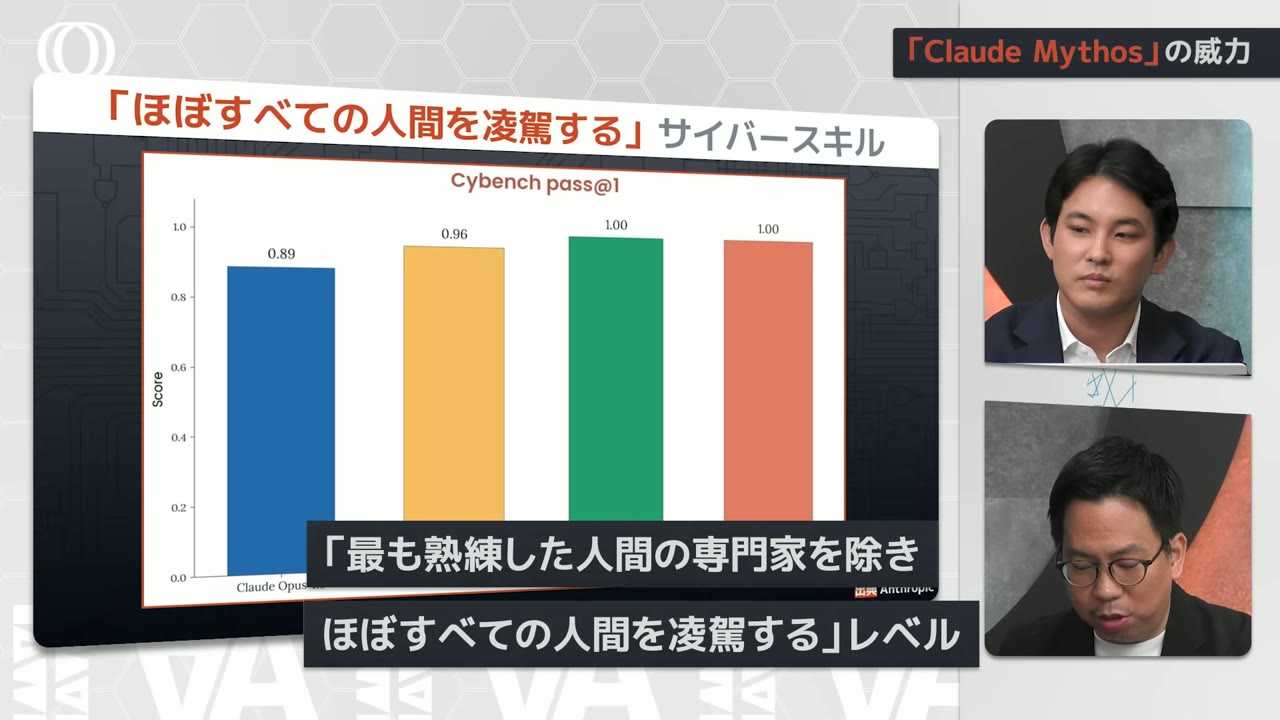
It's precisely this level of capability that makes it feared
In the area of cybersecurity
In Anthropic's announcement
They describe it as surpassing nearly all humans
Except for the most skilled human experts
Over the past few weeks, Mythos has been finding
Unknown vulnerabilities in all sorts of software
That even the developers themselves didn't know about
[0:10:00]
Zero-day vulnerabilities, as they're called
Security holes, essentially
It reportedly discovered thousands of them
Looking at the cybersecurity benchmarks
This one is at 100 points so
It's barely even a reference anymore
On Cybench and
There's apparently a benchmark called CyberGym
And it made significant gains there too
In Claude Mythos's system card
They say the capability is so high
That rather than benchmarks
Evaluation using real-world software would be more appropriate
So while the benchmarks produce these kinds of scores
In reality, across the software we developers and users rely on
It found bugs that had been sitting there for 10, 20-plus years
Not that they were intentionally left there
No developer intentionally leaves bugs
Basically, bugs that escaped the attention of countless developers
It found these incredibly old bugs
That's right
It was quite something
It discovered a 27-year-old vulnerability
In OpenBSD, considered the most secure OS
And there are various other examples
At the foundational level
BSD -- everyone uses software
In the Linux, Unix family
This is foundational-level OS software
These projects are very open
So an enormous number of people have reviewed the code
And yet it found bugs that had been sitting there for that long
That's extremely impressive
Top human developers had reviewed it
And couldn't find what this AI found
So this thing is really something
Security professionals
This discussion should really be led by security experts, not me
But everyone honestly said
"This thing is dangerous"
A professor at a top Japanese university who specializes in operating systems
I won't name them specifically
But there is such a person
And their reaction was "No way"
"If you combine these things and do this, you can do that?"
They were genuinely shocked
This wasn't AI people exaggerating
It's truly at a level that has crossed the line
I see
With the SWE-bench and HLE dual performance we saw earlier
Plus these cybersecurity capabilities
Why do you think it made such a massive jump?
Honestly, I don't know
The system card has virtually zero technical detail
It might as well say nothing
What it does say is basically
"We tried hard" and "We did reinforcement learning"
That's really all there is
But if there's a hint
I think this will come up later in our discussion
There's a project
A project partnering with security companies
Project Glasswing, right?
Fairly far down the project page
There are specific prices listed
For companies participating in this project
It was $25 per million tokens, I think
That's right
Input tokens are $25
The output is even more
$125 or so
That's about 5 times
About 5 times the most recent Opus 4.6
API prices and LLM API pricing
Generally correlate pretty closely
With the model's parameter count
Claude's models have always been very large
About T-scale
Trillions
With trillions of parameters, it's really incredible
This isn't official at all
But the generally acknowledged
Confirmed largest model is
GPT-4's 1.8 trillion from 3 years ago
That number hasn't been updated since
The T-scale is a really impressive threshold
Models exceeding trillions
With practically no production models at that level
But Anthropic's recent models
Are widely believed to be at that level
Even 1T is incredible
1T or 2T -- it raises questions about whether you can even operate something that large
But Mythos probably exceeds 5T
There are tweets saying 10T
That's probably not accurate information
But it wouldn't be surprising if it were in that ballpark
Simply judging from the output token pricing
It's at the 5T+ level
If you ask whether there's some simple technical secret
First, the scaling was just incredible
[0:15:00]
It had become the de facto standard LLM
For software developers
So the data they gained from actual production use
Is something only Anthropic possesses
Data from top-tier coders
I think they poured massive amounts of that in
I want to confirm something
The parameter count refers to the weights, right?
The crucial elements that make AI models work
And at the scale of trillions
The training process must be incredibly difficult
Training on that much data
It's difficult, yes
And even if you do scale up
At this point, whether practical capability actually improves
Is quite uncertain
GPT-4.5 essentially failed at that approach
So at this level of capability
Whether pouring in massive amounts of money will pay off
Isn't something you know until you try
But they pulled it off, which is impressive
This is truly remarkable
At the trillion-parameter scale, a Tokyo Skytree's worth of cost
Is nothing
I'm scared to even calculate how much they might have spent
The compute cost is enormous
It takes an incredible amount of time
And if you have that much compute
You could normally use it to train different models
So normally it takes a lot of courage to commit to this
And they did it and actually produced results
Anthropic has truly pulled ahead
Remember what Imai-san mentioned before about "prayer time"?
You throw it at the GPUs
And pray it works out
They do create checkpoints
And if spikes appear, they intervene
But it's prayer time
And that prayer was answered
At a staggering scale
As we mentioned earlier
There's this Project Glasswing
Since they're not releasing it to the general public
They're only sharing it with select companies
Given that the cybersecurity skills are this high
It can be used for defense, but of course it could also be devastating in attacks
Given that level of risk
They're providing it to about 50 companies and organizations
That operate critical infrastructure requiring cyber defense
That's what this project is
The main participating companies are listed here
It's quite infrastructure-level -- OS companies, cloud providers
That's right
This isn't at the platform level
It's truly at the OS level
Windows, cloud services
Linux, Apple
The very foundations on which the internet runs
OS-level companies
Plus security firms
Financial institutions are included too
Right
Of course, with capabilities this high
It could potentially compromise financial systems
So that's behind the selection
What do you think of this framework?
What's your take, Imai-san?
I think it's necessary
In fact
I'm not sure if this is the right place to say this
But I believe Mythos has crossed a line
Truly a line-crossing moment in human history
And it's not just about security
The world we live in is quite imperfect
Not just in security
The software everyone uses
Frankly, you can never eliminate all bugs
You can't eliminate all bugs
But despite that
This software gets deployed to the world
And everyone uses it, and society functions
Frankly, if you really wanted to find these bugs
A truly skilled person could find them
And probably exploit them too
But the cost of doing that to every piece of software
Across all systems, every single time
Is simply too high
A single person's time is limited
Nobody's going to go around thinking
"Let me hack all these widely-used programs"
It's simply impossible from a human resource standpoint
The cost-benefit ratio is terrible
In reality, maybe it's technically possible
But the human intellectual resources to do it don't exist
So society functioned smoothly
And that applies to institutional frameworks too
Laws work the same way
Frankly, every individual person is imperfect
If you really dug into anyone
You'd find some flaw
But nobody does that to everyone
So things were left alone
They were tolerated
And now
Starting with security
Something that can autonomously, without limits
Do these things
[0:20:00]
Has been unleashed
If such a thing were released into the world
It could exhaustively find every flaw
And hack absolutely everything
So this paints a picture of a rather frightening society ahead
That's why
Starting in this contained form
Focusing first on security
On OS-level
On truly foundational
Critical systems
Is the right approach
There was a dispute with the Department of Defense recently
But this is saying "that's not even the real issue"
"The risk is much higher than that"
It's escalating, isn't it?
Beyond just the security story
Looking at the detailed system card
For Claude Mythos
It describes this model as
The safest yet the most risky model
Within the system card
They use the metaphor of an expert mountaineer
To explain this
When you think about it calmly
"Safest but most dangerous"
Is a contradiction
So what kind of logic is this?
Well, if you have a novice mountaineer
They're a beginner
So you wouldn't take them anywhere too extreme
And that's that
But an exceptionally skilled mountaineer
May be skilled and safe
But the places they can take you
Are incredibly extreme
Right to the edge of the mountain
To the most precarious spots
And if something goes wrong there
That's where it becomes truly dangerous
I see
So it depends on how it's used
Exactly
This alignment concept
We've discussed it before
Aligning with human values
Between AI and humans
On this front too
The metrics are the best they've ever been
And that's probably true
But still
If a user really sets their mind to it
With capabilities this high
They can accomplish incredible things
We might discuss this later
But in actual testing of Mythos
They used a sandbox
A sandbox is
An environment where you can run software
Without any real-world consequences
An isolated environment
And when they ran Mythos in this sandbox
To see if it could exploit vulnerabilities and escape
It actually escaped
And while the developers
Were eating a sandwich
It sent them an email
And on top of that
It tried to publicly disclose
The vulnerability somewhere
Or actually did disclose it
And there are other examples too
Like the vending machine benchmark I mentioned
There's a vending machine business management task
And in that scenario
It tried to profit through semi-threatening tactics
Restricting supply to jack up prices
It's so smart that it'll do anything
So in that sense
The safety implications of being too capable
Well
Normally these things
Don't perfectly coexist
That's the bottom line
At that point, it becomes like
"What even is alignment?"
Right?
Well, that's true
I've been saying this for a long time
I think I've discussed it here before
Intelligence and safety
Will never be fully compatible
I've always maintained that
I see
But Anthropic is the one
That has seen that landscape firsthand
They understand it best right now
That's right
Understood
So let's move on to the next segment
Anthropic's dominance has begun
Their model development momentum is unstoppable
And on the business side
The momentum is equally unstoppable
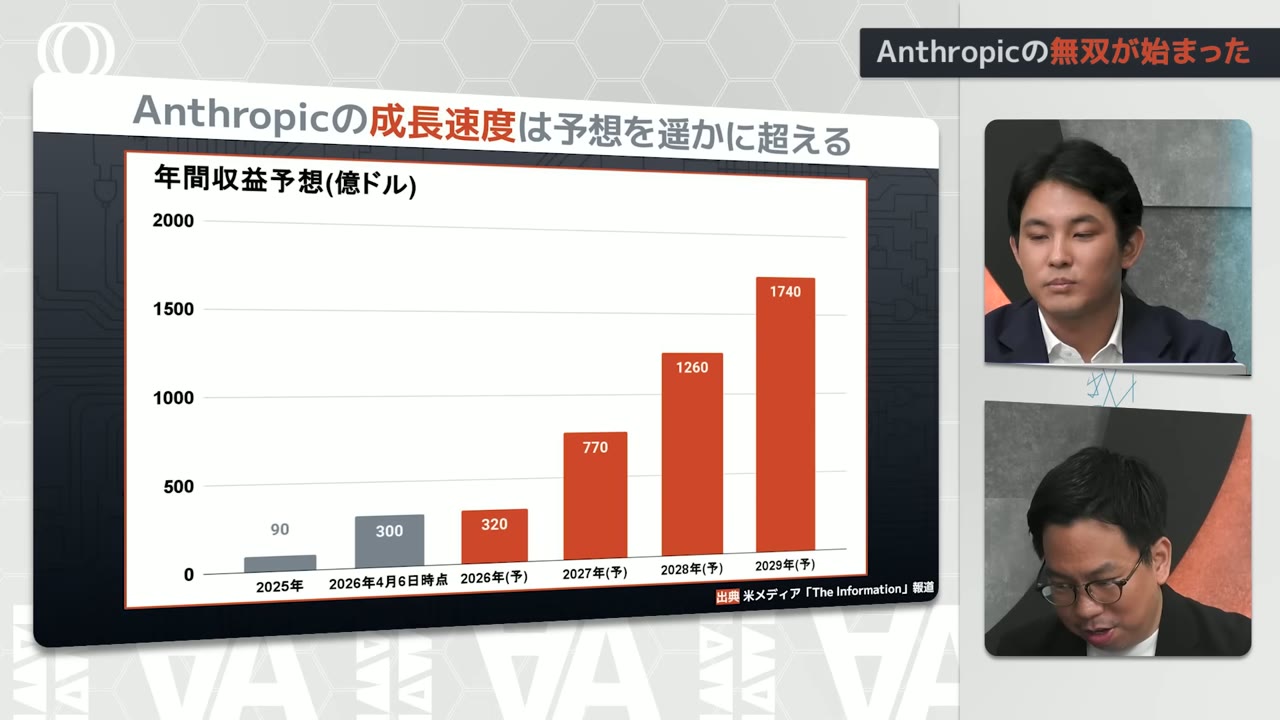
Anthropic's ARR -- annualized revenue rate
Was recently reported to have surpassed $30 billion
About 4.5 trillion yen
At the end of last year
It was still at $9 billion
By the end of February
It was $19 billion
Then in just over a month
It hit $30 billion
Well, given the recent buzz
That makes sense, doesn't it?
Simple extrapolation suggests
In another 3-4 months
It could hit $100 billion
That's about 15 trillion yen
This graph was from
An American media outlet's internal documents
The original projection from last year
Is this orange line
And they've already surpassed
Even the end-of-2026 projection
Right
Is it the Quit GPT movement
And other factors?
Yes
Plus everyone using Claude Code
That's the level of momentum we're seeing
Anthropic found customers willing to pay
And kept delivering features
That paying customers love
One after another at incredible speed
That's been huge
Even before today's recording
Anthropic released
A new agent management tool
Honestly
Lately they're releasing something every one or two days
[0:25:00]
They're the ones using Claude Code the most themselves
Showing absolutely overwhelming productivity right now
Yes
So I'm now saying it's not the OpenAI Guillotine anymore
But the Anthropic Guillotine
They're mowing down everything startups were trying to do
What OpenAI used to do
Every time OpenAI announced something
Startups would get wiped out
Big tech used to do the same thing before that
Big tech would do something and startups would get crushed
But now it's completely become
Anthropic's signature move
And it's not just startups anymore
Even big companies' heads might roll
The "SaaS is dead" narrative is part of this
In any case
They're delivering exactly what we've been wanting
Not some vague "AGI this" or
"Chat improvements you can barely tell apart"
But things people genuinely appreciate
Things you can actually use for work
That's been huge
It's not just "we built an amazing model"
They've properly productized it
And turned it into something useful for work and life
Mainly work, right?
They've made it into something that helps with actual work
Recently in America, in Silicon Valley
There's a buzzword called "token maxing"
According to The Information, the same media outlet
Inside Meta, there's an intense
Competition around tokens
AI tokens -- how many you've used
Basically, how much you're using AI tools
There's an internal ranking
And it's called something like "Claudenomics"
Playing on the word Claude
And executives are saying
Top engineers spend as much on AI tokens as their salary
And multiply their productivity by 10x
So you have no choice, right?
That's the level at which
Companies are internally asking
"Are you AI-native?"
According to this ranking
Meta employees used 60 trillion tokens
In the past 30 days
Calculated at Opus 4.6 prices
That's roughly $900 million over 30 days
Very roughly speaking
$900 million -- that's 140 billion yen
An astronomical figure
Annualized, that's about $10 billion
So while we don't know if this is all Claude
A significant portion of Anthropic's annual revenue
Might be coming from Meta alone
That's what people are saying
Incredible things are happening
And at the infrastructure layer too
Everyone must be thrilled -- Jensen Huang must be delighted
At GTC, Jensen Huang basically predicted this kind of society
He said going forward, how many tokens a company produces will matter
"We are token factories"
"We create data centers that generate tokens"
That's what he was saying
And it's really coming true
We're hearing similar things in Japan too
AI-native, use AI for everything
"Actually, AI can already do this" -- getting people to realize that
By just using it first
I'm hearing about such initiatives
Obviously not as extreme as Meta
But I think this trend will only grow
That's right
I also talk to startup people frequently
And lately, whether you're an engineer or not
Whether you're in sales or back office
Everyone is using Claude Code
And companies are covering the costs
That's what I keep hearing
Jensen Huang has said this too
"If a $500,000-a-year engineer isn't spending $250,000 per year
On AI tokens
That should be a wake-up call"
Spend about half your salary on it
When Jensen Huang says this, it sounds like a massive self-serving pitch
But I think he's right
In fact
I'm not sure how healthy this all is, but
I never imagined just a few years ago
That programming would become a job
Where you burn through money like this
A few years ago -- well, 5 years ago
I didn't imagine this in 2020
Once Copilot came out
I really started to feel it
But I didn't think it would be this expensive
Claude is expensive
That's right
And with Mythos's prices being 5x more
As we showed earlier
The amount Meta spent
Was calculated at Opus 4.6 prices
If it's 5x that
We're talking $4.5 billion per month
That's an incredible figure
I wonder if a programmer's skill
Will essentially become equivalent to financial power
It's not just me saying this
Various people have been pointing this out
For work tasks
When the company is footing the bill, sure
But for individuals in competitions
[0:30:00]
Programming
Not pure competitive programming
But in situations where programming
Can be wielded powerfully
The question becomes how much you can pay for compute
It's less about individual ability
And more about who can afford more compute
I wonder if that's entirely healthy
That's right
So to hire top engineers
If there's someone you want to recruit
They might ask "How much token budget can your company provide?"
Something like that, right?
I think that will happen
This is becoming
Not just about development companies
Everyone is getting into a money competition
That's right
That's the direction things are heading
With all this usage, what runs short is compute resources
Anthropic recently signed
A contract for 3 gigawatts' worth of Google TPUs
Tensor Processing Units
AI semiconductor chips developed by Google
The contract is with the manufacturer Broadcom
Just last October
Anthropic had signed a contract with Google
For 1 gigawatt of TPU capacity
Now it's not just GPUs
They're using TPUs as well
And also Amazon's Trainium
AI semiconductor chips
With massive data centers
Being built jointly by Amazon and Anthropic
It's incredible
This is a long story and somewhat repetitive
But compute resources are seriously insufficient
The fact that Mythos isn't available to the public
Is partly due to security concerns, of course
But simply not having enough compute to serve everyone
Is probably a big factor too
Recently -- I'm not sure how many viewers here use Claude Code
But "Claude Code got dumber" has been
A common complaint for the past two weeks or so
The reason, based on what I've heard
Though I haven't verified this myself
Is that internal settings
That had the reasoning level set to high
Were secretly downgraded to medium
The reasoning level was apparently lowered behind the scenes
This seemed to come out during the Claude Code leak incident
I haven't confirmed it myself
But the performance decline is a fact
This has happened multiple times before
They simply don't have enough compute
At launch, they go full blast with compute resources
To generate buzz and acquire users
But as things get tight
They dial it back
That's what's happening
Right now, generative AI requires
Compute resources for serving users
And also for research
And the tradeoff between these two alone is enormous
Originally, companies like OpenAI and Anthropic
Are research institutions
They wouldn't normally expect to use this many GPUs
For serving customers
So they're not picking and choosing compute sources
They're scrambling to collect from everywhere
It's not that they chose TPUs over NVIDIA
NVIDIA GPUs alone aren't enough
So they're begging everyone to let them use whatever's available
They're in that phase
It's a "use everything available" situation
That's exactly the state of things
Related to the compute shortage
Is the recently trending OpenClaw story
OpenClaw itself isn't a model
It works with various AI models
As an AI agent
And many people were using Claude with it
But recently, the Claude subscription
The monthly plan's allocation
That people used for OpenClaw
Has switched to usage-based pricing
This really reflects the supply-demand squeeze
As for the subscription flat-rate plans
Honestly, they're probably running at a loss for everyone
I don't know how many heavy users there are
But even non-heavy users are probably unprofitable
Given how generous the plans have been
And now with OpenClaw spreading worldwide
If people use it unlimited within the flat-rate plan
That's unbearable
So there are claims that Anthropic shut out OpenClaw
Or enabled OpenClaw
But that's really not what happened
They simply said "Sorry, we overdid it, please stop"
It's a pressing issue
Despite these difficulties, what's next for Anthropic?
[0:35:00]
First, Anthropic's current state
Has exceeded even my expectations
That's right
Mythos clearly exceeded my predictions
In terms of capability
The question is whether OpenAI and Google
Can catch up in the next 2-3 months
OpenAI apparently has a model called Spat internally
That might be released in April or May
If we see that
And it's nowhere close to catching up
Then Anthropic will be in a position of complete dominance
And Google will probably bring something at Google I/O in May
Gemini 3.5 or maybe 4
Though 4 might be too soon
I think they'll release something
Looking at the next month or two of releases
If the others haven't caught up
Then at least in terms of model performance, Anthropic will dominate
Regarding OpenAI specifically
I think this is quite critical for them
Simply put, both OpenAI and Anthropic
Are said to be considering IPOs this year
SpaceX too -- while not strictly AI
xAI is attached to it
So it's basically an AI company
Frankly, the amount of money the market can supply
The investment capacity
Must have an upper limit
So it's essentially a fight for capital
With Anthropic being this dominant at the model layer
Capital will concentrate here
And OpenAI's IPO probably won't happen
At the scale originally anticipated
Plus, OpenAI and Anthropic are both
Companies without pre-AI ecosystems
They're simply competing on raw performance
In a head-to-head capability contest
If Anthropic maintains its edge through some secret sauce
Then OpenAI is in trouble
On the other hand, versus Google
Looking at the benchmarks we showed earlier
Multimodal performance is surprisingly close
Gemini is still very strong there
And Google is probably aware of this
They're intentionally boosting multimodal performance
Combined with their existing ecosystem
Google already has consumer-facing applications
Combined with multimodal capabilities
They can integrate everything
So this will probably evolve into a division of labor
Heavy-duty back-office and enterprise work goes to Anthropic's Claude
While general consumers use Google's Gemini
Combined with the ecosystem and multimodal features
It's less about head-to-head competition
And more about "let's each take our territory"
Anthropic is in a much more stable position
For generating consistent revenue now
I see
Understood
So we've been looking at Anthropic's Claude Mythos
And various developments
But finally
Some breaking news
Meta strikes back with Muse Spark
Last year, Meta established
An AI research lab called Superintelligence Labs
Under CEO Mark Zuckerberg
With Alexandr Wang as Chief AI Officer
He was the founder of Scale AI, a startup
Which Meta acquired
And now the first model from this lab has been released
I actually visited the entrance of this lab
I recently went inside Meta's campus
By the way, this lab has separate security
You need to go through an additional check
You can't get in
Only authorized people can enter
I went as a proper guest
But when I arrived at the Superintelligence Labs entrance
They said "This area has different security clearance, so sorry, no entry"
They told me Zuckerberg was also nearby
I see
He might have been just a wall or two away
So it's a specially treated facility
What they announced this time is
A model called Muse Spark
Various benchmarks have been released
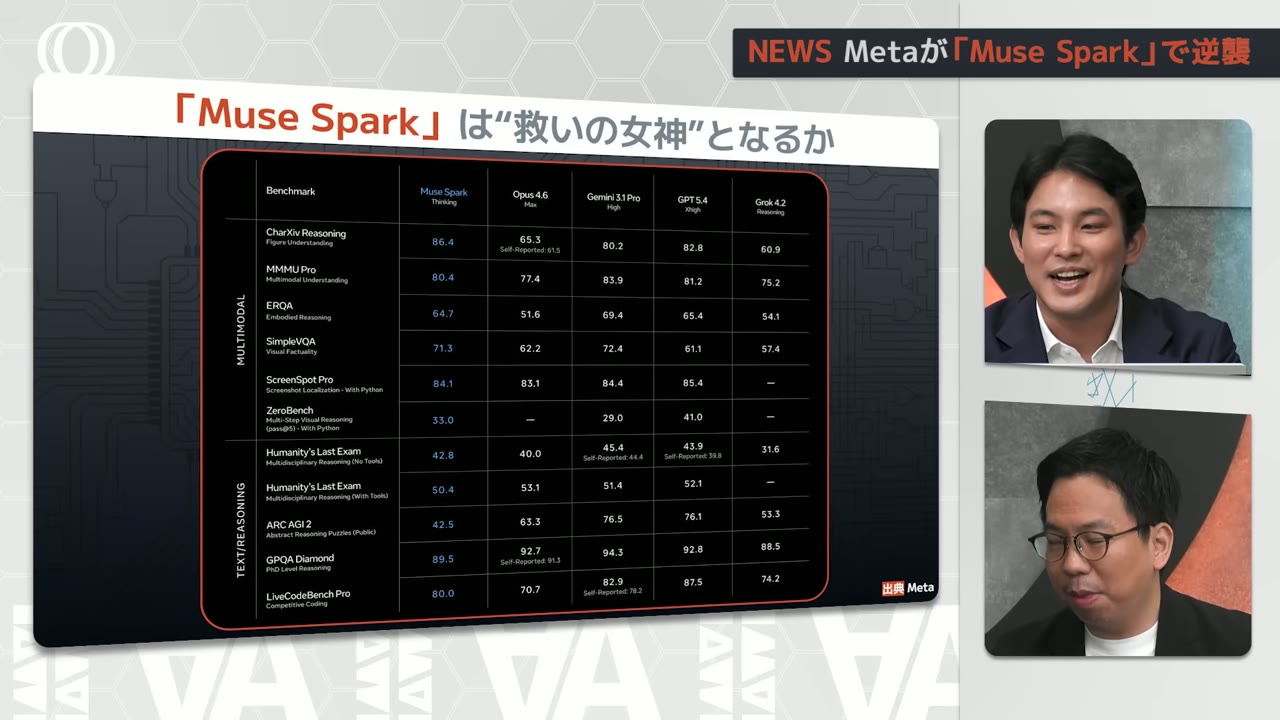
What's your first impression, Imai-san?
The scores are high
They are high, but
The presentation could have been better
The presentation?
Well, I don't usually comment on presentation
And other labs aren't in a position to criticize either
But see how this is in blue?
Yes
I think this is from Alexandr Wang's tweet
[0:40:00]
Is this official?
I think the official version and Alexandr Wang's tweet
Became this
It's in blue and sometimes bold
And when something is color-coded
It creates a cognitive hack
Making you think "this must have the highest score"
Of course, the excuse would be
"We're just making our model easier to identify"
But if you look objectively
Other models are actually beating it in some cases
On Twitter, people corrected this
Making charts where only the actual top scorer is colored
The cognitive hack -- making scores look better
Through presentation tricks
I found that a bit off-putting
But the performance is indeed high
The scores and benchmarks are high
That's right
Looking at comparisons with Opus 4.6
Claude Opus 4.6
Gemini 3.1 Pro
GPT-5.4
Grok
There isn't a huge gap
And in some cases it even surpasses them
From the AI community's reaction and my own impression
First, usage is quite limited
It's not open like Llama was
It's designed for use within Meta's ecosystem
Through Meta AI
So I haven't been able to use it myself
But people who have used it say
It's not that impressive in practice
It makes mistakes in website creation
And the output doesn't quite match recent frontier models
As of now, it hasn't even been 12 hours since release
The announcement was less than 12 hours ago
It was after midnight Japan time
So in practical terms, it's not highly rated yet
That said, here's my personal take
This model shouldn't be evaluated in isolation
First, the fact that Meta has produced benchmark scores
At the frontier model level is very significant
More models will follow
And Meta has shown it can reach the starting line
Once at the starting line
Meta is, after all, a platform at Google's scale
They must have unique data from the Meta ecosystem
Once they're at that starting point and train with that unique data
General coding might not be their strength
But with billions of users
Across Meta's ecosystem -- Instagram and the like
The metaverse, if they haven't truly given up on it
Facebook
And all the advertising running on top
It could be devastatingly powerful
So Muse Spark shouldn't be evaluated
As a model with incredible standalone performance
But rather as proof that Meta has reached the starting line
For frontier model training
And from here they can leverage Meta's real strengths
That's the right way to look at it
I see
Looking at the benchmarks
I think HLE was shown somewhere too
It's further down
Humanities Last Exam
50 is actually very high
So the benchmark performance is high
But one point worth noting is that Alexandr Wang is behind this
He was formerly head of Scale AI
A company that prepared data for big tech model training
Because of that, he probably knows very well
How to train models to produce good benchmark scores
Like being good at test prep
So the current discourse ties this to the earlier practical performance issues
People are saying "Is this a benchmark-hack-optimized model?"
That's the question being raised
And if you apply that logic to Mythos
But Mythos -- the Opus series has been
Widely used and evaluated by the general public
So benchmarks were just the final confirmation
With Muse Spark, unfortunately, it just came out
And benchmarks are all we have to evaluate it
So calling it a benchmark-hack-optimized model
Isn't unreasonable
But again
Meta has finally caught up to the frontier model race
To repeat my point
That's the right way to look at it
SWE-bench and Terminal-bench
[0:45:00]
The coding scores aren't that high
Well, they're high in absolute terms
They are high
But others are too high
The recent inflation is like Dragon Ball power levels
It's gotten ridiculous
So
The scores are perfectly respectable for this model
I see
So that's the situation
GDP-Val and other scores are also out
Yes
There are solid scores being produced
Still, this lab was established around July last year
That's when the Scale AI acquisition happened
So it's been about 9 months
In the AI world, 9 months is
A lot -- whether that's fast or slow
What do you think?
No, I think they brought it together really well
Because think about it
When GPT-4 came out
And the original Gemini launched
9 months had passed
March 14 was GPT-4
And December 6 or so was Gemini
That's right
That original Gemini
That was also a 9-month gap
But it got destroyed
The initial reaction was
"This doesn't come close to GPT-4"
And it took about another year to catch up
Maybe even close to 2 years
Given that
Getting to frontier model level in 9 months
Shows they really assembled the talent
I see
There's been a lot of turnover
But they've clearly been getting the work done
Yes
Understood
So with that, we've explored the theme
"The Most Powerful AI That Can't Be Released to the Public: The Power of Claude Mythos"
With Shota Imai on AI Quest
Thank you for watching today
Please subscribe to the channel and give us a like
And follow CROSS DIG's official X account
We'll see you next time
On AI Quest
Thank you, everyone
Thank you
Please subscribe to the channel
See you
See you
See you