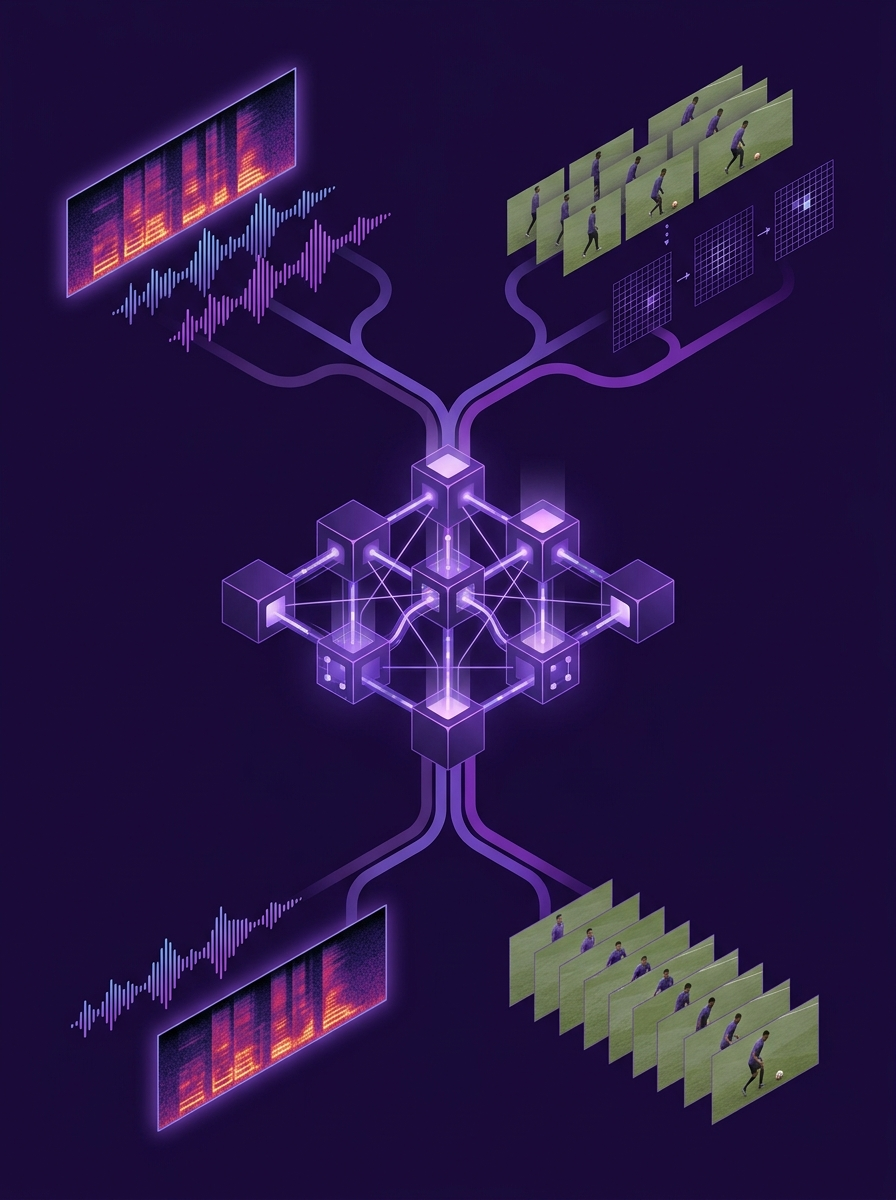
🟡 Intermediate Multimodal Spatial Reasoning Viewpoint Token Warping Benchmark
NEW
2026-04-03
トークンワーピングがMLLMの近傍視点推論を助ける | Flecto
ViT画像トークンを並べ替えるだけで、MLLMがファインチューニングなしに近傍視点から推論できるようになる。新提案のViewBenchで全ベースラインを上回る。
ViT画像トークンを並べ替えるだけで、MLLMがファインチューニングなしに近傍視点から推論できるようになる。新提案のViewBenchで全ベースラインを上回る。
人間が93.8%解ける問題を最先端AIはたった56.3%しかクリアできない。このベンチマークはマルチモーダルエージェントの失敗箇所と原因を初めて体系的に解明する。
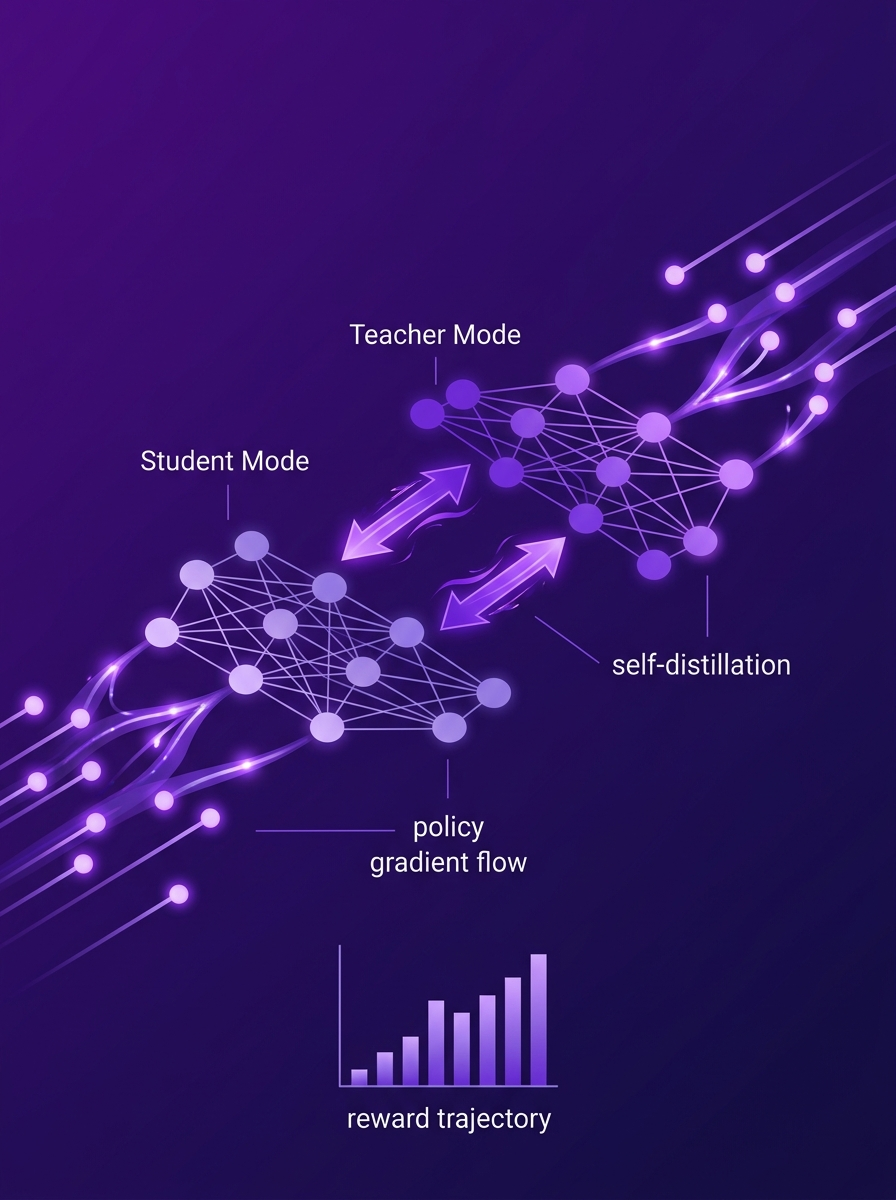
RLSDはオンポリシー自己蒸留の情報リーク問題を解決し、教師をトークンレベルの更新量評価器として活用することで、5つのマルチモーダル推論ベンチマークでSOTAを達成。
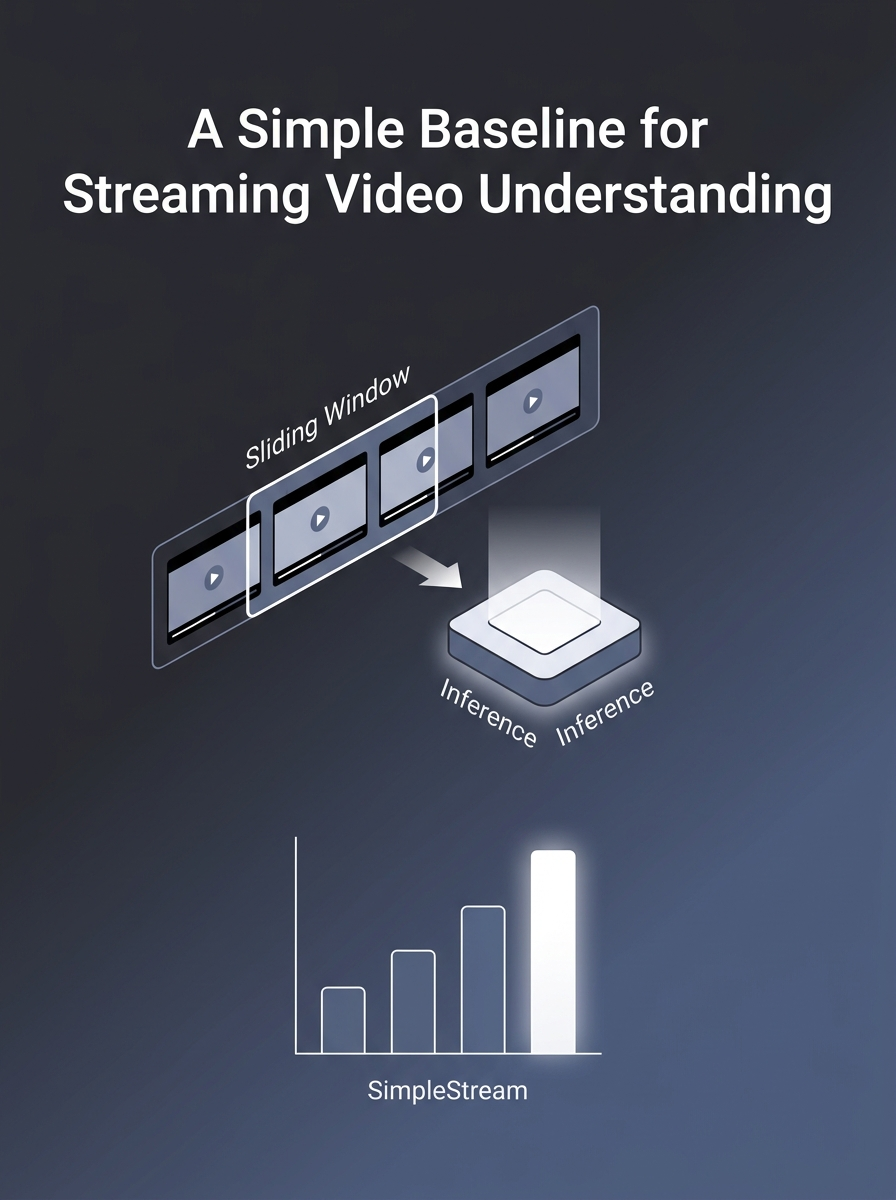
わずか4フレームのスライディングウィンドウで、全ての公開ストリーミングモデルを半分のGPUメモリで上回るベースラインの発見。
ハーネス自動最適化エージェントがTerminalBench-2で1位を獲得。ファイルシステムアクセスによる因果推論でACEを7.7ポイント上回る成果。
DataFlexは動的データ選択・ドメインミックス最適化・サンプル重み付けを単一のLLaMA-Factory互換フレームワークに統合し、再現性の高いデータ中心LLM学習を実現します。
PixelSmileはピクセルレベルで精密な表情編集を実現し、従来手法の意味的重複問題を克服。
Mistral AIのVoxtral TTSは最小限のデータから高度に自然な多言語音声を生成し、表現力豊かなTTSの新基準を確立。
RealRestorerは大規模画像編集モデルを活用し、従来手法では対処できなかった複雑な劣化を処理する汎用的な実世界画像修復を実現。
Intern-S1-Proは世界初の1兆パラメータ科学マルチモーダルモデルで、50以上の科学ベンチマークで最高性能を達成。
本論文は自然言語エージェントハーネス(NLAH)を提案し、エージェントの制御ロジックをコードではなく編集可能なテキストで記述できることを示す。コードから自然言語への移行で55%の性能向上を達成。
Calibriは軽量なパラメータ効率的キャリブレーションで拡散トランスフォーマーの隠れた能力を引き出し、最小限の計算コストで大幅な品質向上を実現。
自律型AIエージェントのデータ漏洩・権限昇格・悪意あるツール実行をリアルタイムで防御する3層セキュリティフレームワーク。
CUA-Suiteは55時間の専門家アノテーション付きデスクトップ操作動画を提供する、コンピュータ操作エージェント訓練のための大規模ベンチマーク。
Transformerのアテンション出力を残差として再利用するシンプルな改良。追加パラメータなしで推論・長文脈性能を向上させる。
AIは自らツールを構築することで超知能を達成できるか?本論文はDiligent Learnerフレームワークによりその可能性を論じる。
Gemini-2.5-Flashが自動生成したコードハーネスで違法手を完全排除。145のTextArenaゲームで、より小さなモデルが大規模モデルを超える。
PaperBananaはVLMエージェントを活用して学術論文のイラストを自動生成する、AI研究ワークフローを変革するフレームワーク。
テキストプロンプトから映像と音声を同時生成する統合基盤モデル。従来の映像・音声別パイプラインを不要にする。
ACEはLLMコンテキストを進化するプレイブックとして扱い、体系的なコンテキスト最適化によりエージェントベンチマークで+10.6%の性能向上を達成。
VibeVoice は7.5 HzトークナイザーでEncodec比80×圧縮を実現し、次トークン拡散によって最大4話者・90分の自然な対話を1つのLLMコンテキストウィンドウ内で合成できる画期的なTTSモデルです。
LlamaFactoryは100以上の言語モデルを最小限のコードでファインチューニングする統合フレームワークを提供し、LoRA、QLoRA、RLHFなどをすぐに利用できます。
CARLA-Airはドローン飛行と自動運転を単一シミュレーションに統合し、共同シミュレーションのオーバーヘッドなしに空地協調AI研究を可能にします。
ECoT合成とIndustrial Code World Modelにより、汎用コードと産業コードの両方で最高精度を達成した新しいコードモデル。