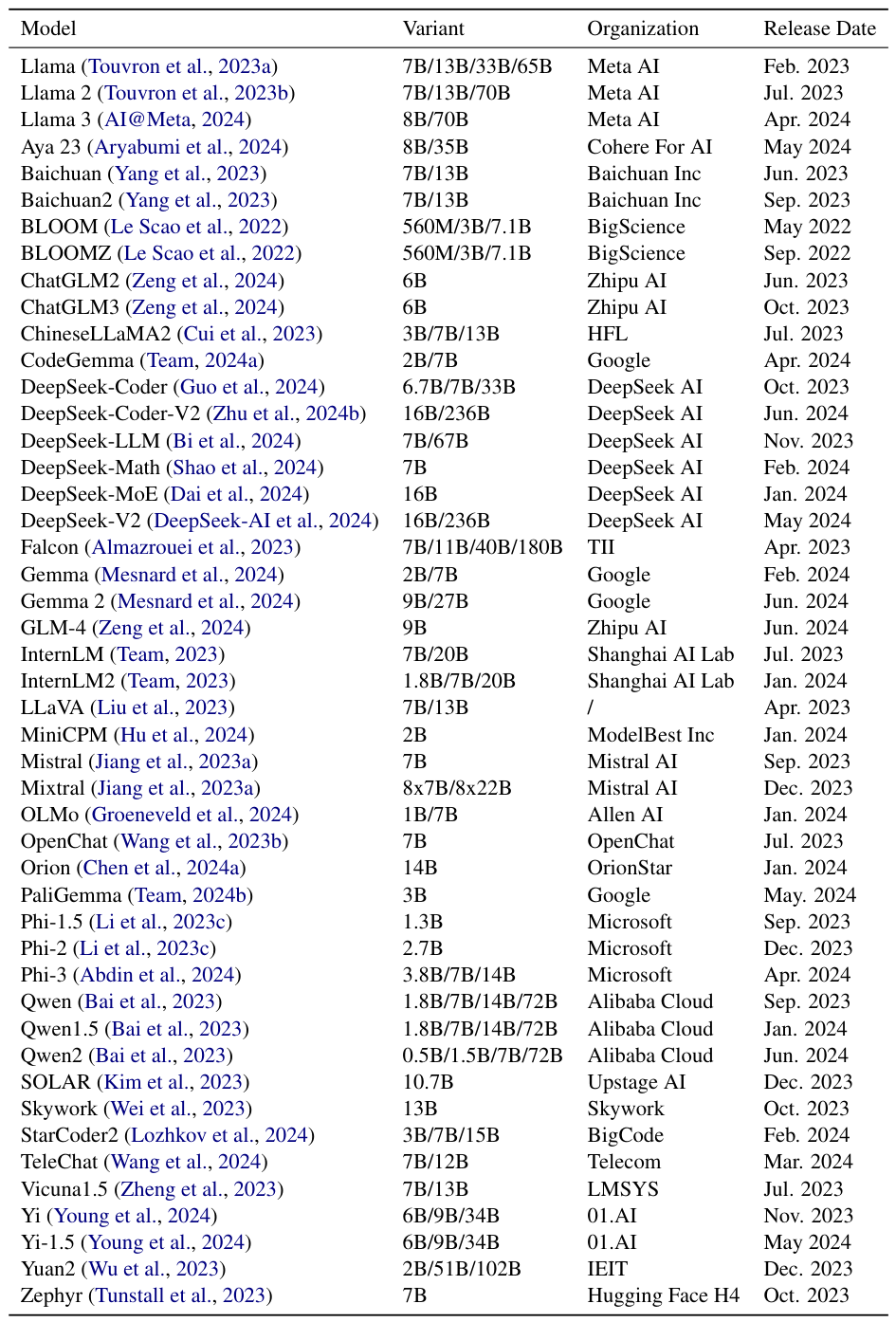
既存のフレームワークとの機能比較
LlamaFactoryは、最適化手法、計算効率化技術、および学習パラダイムにおいて、包括的なサポートを提供することで際立っており、その範囲は、他のどの競合フレームワークも匹敵しません。
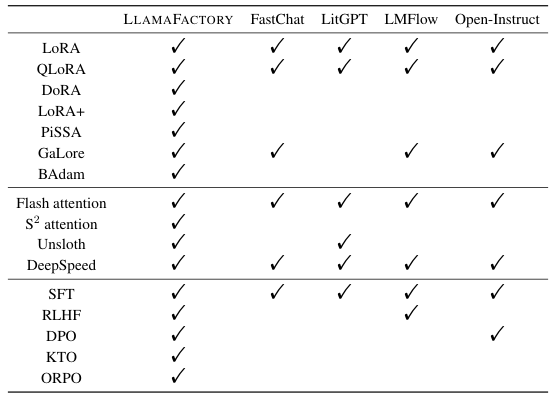
最先端の効率的な学習方法を統合した、統一的なフレームワーク。これにより、コーディングなしで、100種類以上のLLM(大規模言語モデル)のファインチューニングを柔軟にカスタマイズできます。
大規模言語モデル(LLM)を、様々な下流タスクに適応させるためには、効率的なファインチューニングが不可欠です。しかし、これらの手法を異なるモデルに適用するには、かなりの労力が必要です。LlamaFactoryは、最先端の効率的なトレーニング手法を統合した、統一的なフレームワークです。このフレームワークは、組み込みのWeb UIであるLlamaBoardを通じて、コーディングなしで100種類以上のLLMのファインチューニングを柔軟にカスタマイズするためのソリューションを提供します。このフレームワークは、言語モデリングおよびテキスト生成タスクにおいて、実験的に検証されており、25,000以上のGitHubスターと3,000以上のフォークを獲得しています。
大規模言語モデル(LLMs)は、驚くべき推論能力を示し、質問応答、機械翻訳、情報抽出など、幅広いアプリケーションを支えています。Hugging FaceのオープンLLMランキングには5,000以上のモデルが登録されており、このエコシステムは急速に成長しています。しかし、これらのモデルを特定のタスクに適用することは、大きな課題を伴います。
これらの問題に対処するため、LlamaFactory は、特定のモデルやデータセットへの依存性を最小限に抑える、3つの主要モジュール(Model Loader、Data Worker、Trainer)を備えたモジュール式のフレームワークを提供します。これにより、事前学習、教師ありファインチューニング (SFT)、RLHF、および DPO を含む、数百のモデルやトレーニング手法への柔軟な拡張が可能になります。
ファインチューニングとは、あらかじめ学習済みの言語モデル(例えば、GPTやLlamaなど)を取り、特定のデータセットでさらに学習させることで、特定のタスクにおける性能を向上させるプロセスです。
これは、幅広い教育を受けた大学卒業生を採用し、その後、特定の職務に必要な実践的なトレーニングを行うことに似ています。“事前学習”は、一般的な知識を身につけさせ、“ファインチューニング”は、特定の分野の専門家へと成長させるものです。
LlamaFactoryは、最適化手法、計算効率化技術、および学習パラダイムにおいて、包括的なサポートを提供することで際立っており、その範囲は、他のどの競合フレームワークも匹敵しません。
LlamaFactoryの効率的なファインチューニング技術は、大きく2つのカテゴリに分けられます。効率的な最適化(どのパラメータを更新する必要があるかを削減する)と、効率的な計算(各計算ステップのコストを削減する)です。これらを組み合わせることで、メモリ使用量をパラメータあたり18バイトからわずか0.6バイトまで削減できます。
LoRA (Low-Rank Adaptation) は、最も人気のある効率的なファインチューニング手法の一つです。モデル内の数十億ものパラメータをすべて更新するのではなく、LoRAでは、元の重みを固定し、小さく、学習可能な「アダプター」行列を追加します。
巨大な図書館(モデル)があると想像してください。すべての本を書き換える代わりに、特定のページがどのように読み込まれるかを変更する、小さな付箋(アダプター)を追加します。これははるかに安価で高速です。
これらのバリエーションはすべて、共通の考え方を持っています。パラメータのすべてではなく、少数のパラメータを学習させることで、GPUメモリの使用量を数十GBからわずか数GBに削減します。
GaLore は、Gradient Low-Rank Projection の略です。LoRA は小さなアダプターを追加しますが、GaLore は異なるアプローチを取ります。GaLore は、モデルがどのように更新されるかを指示する信号である勾配を、より低次元の空間に投影します。これにより、すべてのパラメータを学習しながら、はるかに少ないメモリを使用できます。つまり、すべてのパラメータを更新しますが、勾配の計算は圧縮されます。
アテンション機構は、Transformer モデルの中核をなすものですが、非常に多くのメモリを消費します。メモリの使用量は、シーケンス長に対して二乗で増加します。Flash Attention は、計算の構成を「I/O 認識型」に再構成することで、GPU の計算コアと GPU メモリ間の高価な読み書きを最小限に抑えます。
その結果、2〜4 倍高速で、大幅に少ないメモリを使用し、かつ数学的に同等の結果が得られます。これは、不要なファイルキャビネットへのアクセスを避けるために、ワークフローを再構成するようなものです。

LlamaFactoryは、主に以下の3つのモジュールで構成されています。Model Loader(LLMとVLMの両方のモデルアーキテクチャを処理します)、Data Worker(シングルターンおよびマルチターンの対話に対応した統合パイプラインを通じてデータを処理します)、そしてTrainer(事前学習、SFT、RLHF、およびDPOにわたって効率的なファインチューニング技術を適用します)。さらに、コードを書かずにファインチューニングを実行できるWeb UIであるLlamaBoardが上に配置されています。
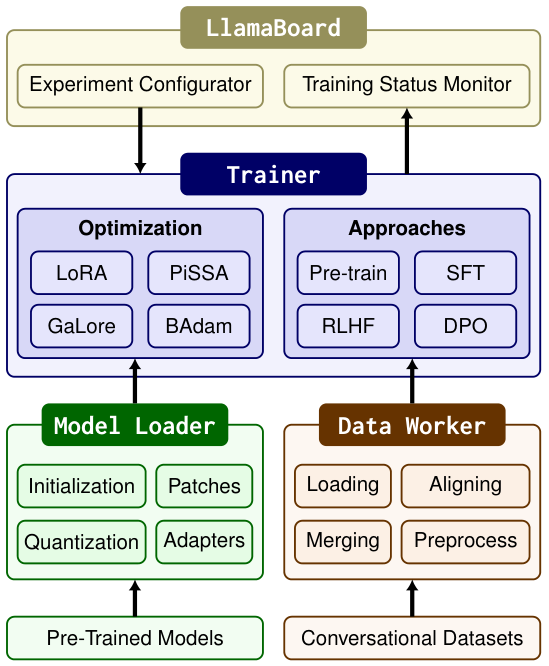
様々なアーキテクチャに対応し、モデルの初期化、パッチ適用、量子化、アダプターの接続、および精度調整を処理します。
異なる形式のデータセットを、柔軟な微調整を可能にする統一された構造に標準化します。
「データ記述仕様」は、LlamaFactoryがLLM(大規模言語モデル)のエコシステムにおける「データ形式の混乱」に対処するための方法です。異なるデータセットが異なるJSON構造を使用します(Alpacaはinstruction/input/outputを使用し、ShareGPTはconversations配列を使用します)。各形式に特化したカスタムローダーを作成する代わりに、小さな設定ファイルを作成し、LlamaFactoryにデータセットのフィールドをどのように標準化された形式にマッピングするかを指示します。これにより、異なるソースからのデータセットを、単一のトレーニング実行で組み合わせて使用できます。
最先端のトレーニング手法と、分散トレーニングのサポートを統合しています。
通常のRLHF(強化学習による人間からのフィードバック)の学習には、4つの異なるモデルが同時に動作する必要があります。具体的には、ポリシーモデル、参照モデル、報酬モデル、そしてバリューモデルです。これにより、RLHFは非常に多くのGPUリソースを消費し、通常は複数の高性能GPUが必要となります。
LlamaFactoryのモデル共有RLHFは、この問題を、単一の基本モデルと複数の軽量アダプターを使用することで解決します。
これにより、RLHFは「クラスタが必要」から「単一の一般的なGPUで動作する」へと変化し、これはアライメント学習をより身近にするための大きな一歩となります。
LlamaFactoryは、Data Workerパイプラインを通じて、以下の5種類のデータセット構造をサポートしています。プレーンテキスト、Alpacaに似たデータ、ShareGPTに似たデータ、評価データ、そして、これら全てを統合する標準化されたフォーマットです。この柔軟性により、ユーザーはあらゆる一般的な形式で独自のデータを持ち込むことができます。

LlamaBoardは、GradioをベースにしたWebインターフェースであり、ユーザーはコードを一切書かずに、LLM(大規模言語モデル)のファインチューニングをカスタマイズできます。設定から評価まで、シームレスな体験を提供します。
ウェブインターフェースを通じて、ほとんどのパラメータに対して適切なデフォルト値が設定された状態で、ファインチューニングの引数をカスタマイズできます。トレーニング前に、データセットをUI上で直接プレビューして検証することができます。
トレーニングログと損失曲線は、リアルタイムで可視化および更新され、ユーザーはトレーニングの進捗状況を監視し、ファインチューニングのプロセスに関する洞察を得ることができます。
テキストの類似度スコア(BLEU-4、ROUGE)を自動的に計算することも、ファインチューニングされたモデルと直接チャットすることで、人間による評価を行うことも可能です。
英語、ロシア語、中国語に対応したインターフェースのローカライゼーションにより、より幅広いユーザーがLlamaBoardを利用して、ファインチューニングのワークフローを行うことができるようになりました。
トレーニング効率は、PubMedデータセット(3600万件以上の生物医学記録)を用いて、Gemma-2B、Llama2-7B、およびLlama2-13Bモデルで評価しました。比較された手法には、フルファインチューニング、GaLore、LoRA、およびQLoRAが含まれており、ピークメモリ使用量、トレーニングのスループット(トークン/秒)、およびパープレキシティ(PPL)を測定しました。
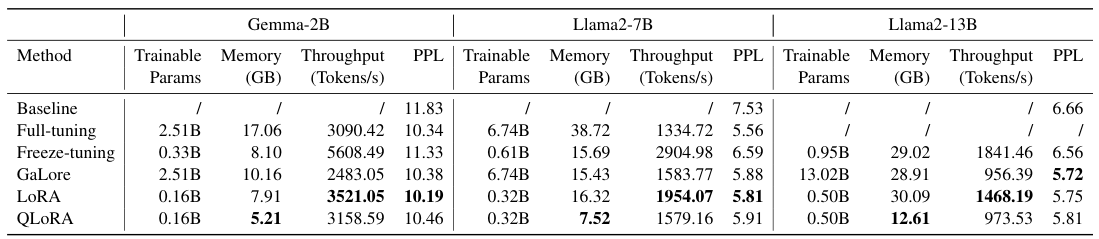
QLoRAは、事前学習済みの重みが低い精度で保存されるため、常に最も低いメモリ使用量を実現します。LoRAは、ほとんどの場合で最高の処理速度を提供します。注目すべき点として、Llama2-13Bのフルファインチューニングを行うと、単一のA100 40GB GPUでメモリ不足が発生しますが、QLoRAではわずか12.61GBで処理できます。
Perplexity (PPL) は、モデルが次の単語をどれだけ正確に予測できるかを測る指標であり、値が小さいほど良いことを示します。PPLが10の場合、モデルは各ステップで、10個の同程度の確率の単語の中から選択する必要があるのと同程度の混乱を抱えていることを意味します。
重要な点: QLoRAは、Gemma-2Bの場合、わずか5.21GBを使用します(フルファインチューニングの場合は17.06GB)。これは3.3倍のメモリ削減です。しかし、Perplexityの差はわずか(10.46 vs 10.34)であり、品質の低下はごくわずかです。Llama2-13Bの場合、単一のA100 GPUではフルファインチューニングは単純に不可能ですが、QLoRAはわずか12.61GBでそれを実現できます。
性能は、以下の3つのテキスト生成タスクで評価されました。CNN/DailyMail および XSum(英語の要約)、および AdGen(中国語の広告生成)。8つのInstruction-tunedモデルを、フルファインチューニング、GaLore、LoRA、およびQLoRAを用いてテストし、平均ROUGE-1、ROUGE-2、およびROUGE-Lスコアを測定しました。
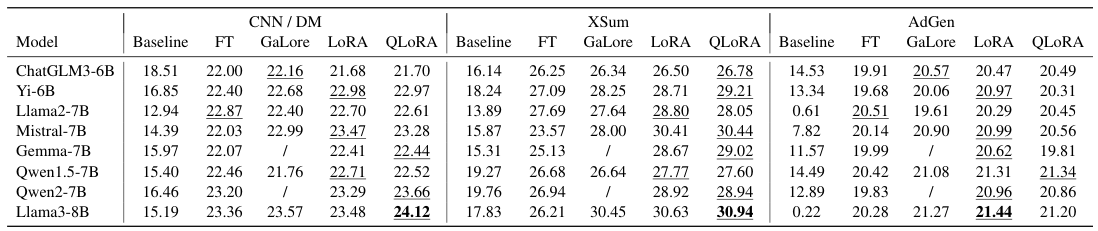
重要な発見として、LoRAとQLoRAは、ほとんどの場合において最高のパフォーマンスを発揮することが示されており、多くの場合、フルファインチューニングと同等またはそれ以上の性能を発揮します。これは、効率的な手法が品質を犠牲にしないことを示しており、むしろ正則化効果によって品質を向上させることができ、かつメモリ使用量をわずかなものに抑えることができることを意味します。
ROUGE スコア は、生成された要約と参照要約間のテキストの重複を測定します。ROUGE-1 は、一致する単語の数をカウントし、ROUGE-2 は、一致する単語ペアの数をカウントし、ROUGE-L は、最長の共通部分列を見つけます。重要な点は、LoRA と QLoRA は、多くの場合、完全なファインチューニングよりも優れた性能を発揮するということです。これは、パラメータの制約が、過学習を防ぐための正則化の一種として機能するためであると考えられます。
LlamaFactoryは、統一されたモジュール式フレームワークが、LLM(大規模言語モデル)のファインチューニングをより身近なものにできることを示しています。モデル、データセット、およびトレーニング方法間の依存関係を最小限に抑えることで、多様な効率的な手法を用いた100種類以上のLLMのファインチューニングを可能にします。さらに、LlamaBoardは、コーディング不要のWebインターフェースを提供することで、設定、トレーニング、および評価のプロセスを簡素化します。
LlamaFactoryは、大規模言語モデル(LLM)の実践者からなる大きなコミュニティを引きつけ、オープンソースの発展に大きく貢献しています。Hugging Faceの「Awesome Transformers」リストに掲載されており、効率的なファインチューニングフレームワークの代表的なものとして知られています。著者は、このフレームワークを基に開発を行う際には、責任ある利用とモデルのライセンス遵守を重視しています。