ベンチマーク結果
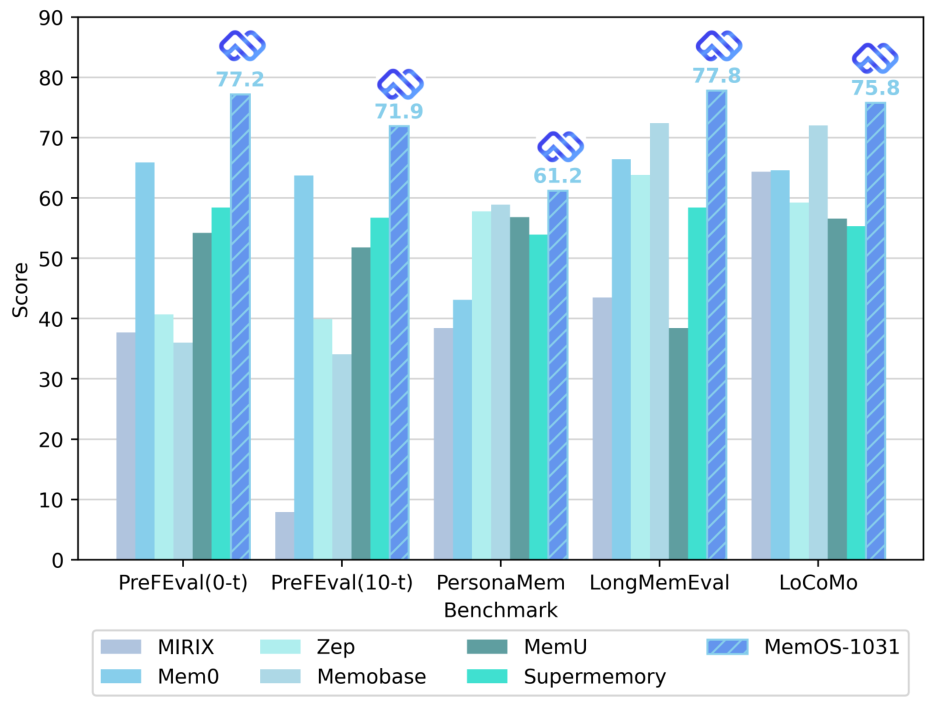
MemOSは、主要なメモリベンチマーク(PrefEval-0t, PrefEval-10t, PersonaMem, LongMemEval, LoCoMo)において、最先端の性能を達成しており、Mem0、Zep、MemBase、MIRIX、およびSupermemoryを上回る結果を示しています。
6
ベンチマーク — 全てにおいてNo.1
PrefEval-0t#1
PersonaMem#1
LongMemEval#1
LoCoMo#1
MemTensor (Shanghai) Technology Co., Ltd. · 上海先進アルゴリズム研究所 (Institute for Advanced Algorithms Research, Shanghai) · 中国電信研究院 (Research Institute of China Telecom) · 同济大学 (Tongji University) · 浙江大学 (Zhejiang University)
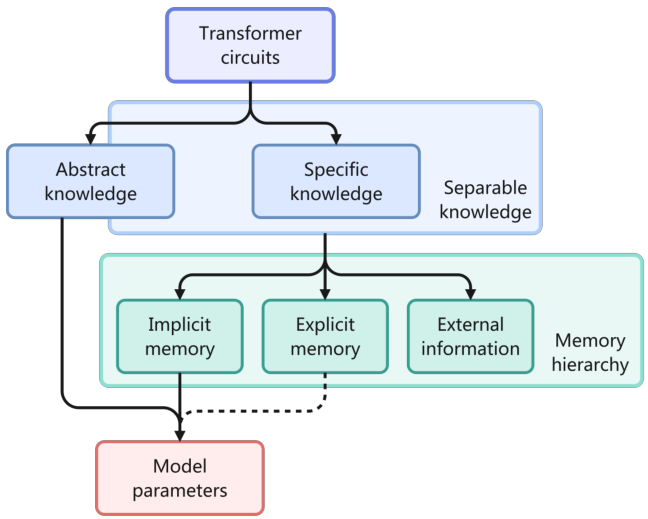
LLM(大規模言語モデル)は、明確に定義されたメモリ管理システムが不足しており、これが長文の文脈理解や継続的なパーソナライズを制限しています。我々は、MemOSという、メモリを第一級のリソースとして扱うメモリオペレーティングシステムを提案します。これは、プレーンテキスト、活性化ベース、およびパラメータレベルのメモリを、MemCubeと呼ばれる単一の階層構造のフレームワークで統合します。
MemOSは、主要なメモリベンチマーク(PrefEval-0t, PrefEval-10t, PersonaMem, LongMemEval, LoCoMo)において、最先端の性能を達成しており、Mem0、Zep、MemBase、MIRIX、およびSupermemoryを上回る結果を示しています。
Transformerアーキテクチャの登場と自己教師あり事前学習の成熟により、大規模言語モデル(LLMs)は現代のAIの中核となっています。膨大なデータセットで訓練されたこれらのモデルは、そのパラメータに膨大な世界の知識をエンコードし、驚くべきタスク間の汎化能力を示します。
しかし、依然として根本的な課題が残っています。LLM(大規模言語モデル)は本質的にステートレス(状態を持たない)です。各セッションは最初から始まり、過去のやり取り、ユーザーの好み、または進化する知識といった、永続的な記憶を持っていません。LLMがツールから、時間と空間をまたいで動作する持続的なエージェントへと移行するにつれて、この制限は重大なボトルネックとなります。
既存のアプローチ、例えばRetrieval-Augmented Generation (RAG) は、メモリを後付けの機能として扱います。これは、ライフサイクル管理や永続的な表現との統合が欠けている、ステートレスな回避策です。RAGは外部知識をプレーンテキストで導入しますが、異種メモリタイプの統合や、時間経過に伴うメモリの進化を管理することはできません。
この問題を解決するために、我々はMemOSを提案します。これは、AIシステム向けのメモリオペレーティングシステムです。MemOSは、プレーンテキスト、アクティベーションベース、およびパラメータレベルのメモリの表現、スケジューリング、および進化を統合し、コスト効率の高いストレージと検索を可能にします。コアとなるユニットであるMemCubeは、メモリの内容と、プロヴェナンスやバージョン情報などのメタデータをカプセル化します。
LLM(大規模言語モデル)のメモリに関する研究は、4つの主要な段階を経て発展してきました。初期の暗黙的メモリと明示的メモリの定義から始まり、人間の記憶アーキテクチャに似たものへと進み、現在では体系的なメモリオペレーティングシステムが主流となっています。
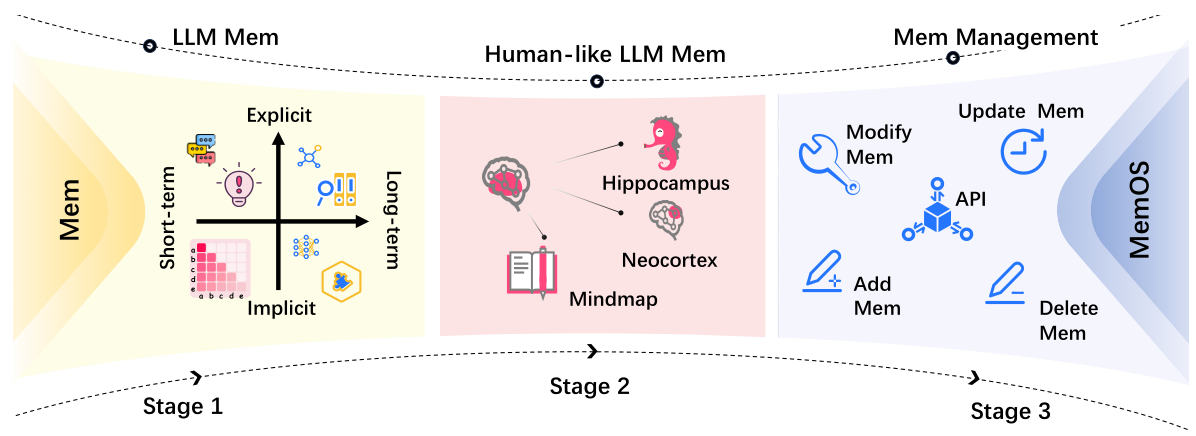
初期の研究では、暗黙的なメモリ(事前学習を通じてモデルの重みにエンコードされるもの)と、明示的なメモリ(テキストやキー・バリューペアとして外部に保存されるもの)との区別が探求されました。代表的なシステムには、RAG、kNN-LMs、およびprefix tuningなどがあります。
海馬(短期記憶)と新皮質(長期記憶の定着)に触発された研究者たちは、持続的な知識の保存のために、マインドマップのような構造を持つ、複数の構成要素からなるメモリアーキテクチャを開発しました。
Mem0やZepのようなシステムは、メモリ操作のための明示的なAPI(追加、変更、更新、削除)を導入しました。しかし、これらは依然として独立したものであり、異なる種類のメモリを単一のフレームワークで統合することができません。
MemOSは、LLM(大規模言語モデル)のメモリに対して、OSレベルのリソース管理の原則を導入します。具体的には、統合されたスケジューリング、ライフサイクル制御、ガバナンスポリシー、および異なる種類のメモリ間の移行機能を提供します。これは、メモリをOSのリソースとして扱う初のシステムです。
AGIが、複数のタスク、役割、およびモダリティを含む、ますます複雑なシステムへと進化するにつれて、LLMは単に「世界を理解する」というだけでなく、経験を蓄積し、好みを保持し、時間とともに進化する必要があります。
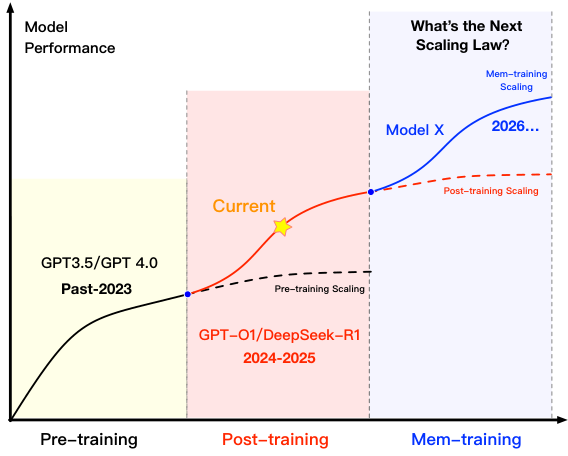
モデルの性能は、従来のスケール則によって予測される上限に近づきつつあります。現在の研究パラダイムは、データとパラメータ中心の前学習から、強化学習による調整(後学習、例えば、GPT-O1、DeepSeek-R1)へと移行していますが、この変化は収穫逓減の段階に入っています。
MemOSは、次世代の技術としてMem-training Scalingを提案します。これは、LLM(大規模言語モデル)が、展開環境全体で継続的にメモリを蓄積・改善することで、事前学習後の性能限界を突破できるという考え方に基づいています。数千もの異種モデルインスタンスが、MemOSインフラストラクチャを通じて、その場で経験を蓄積し、互いに共有することができます。
従来のコンピューティングシステムでは、OSがハードウェアリソース(CPU、メモリ、ストレージ)を集中管理し、効率的なアプリケーションの実行をサポートします。MemOSは、この同じ原則をLLM(大規模言語モデル)のメモリリソースに適用します。
以下の表は、従来のOSコンポーネントと、それに対応するMemOSのコンポーネントとの関連性を示しています。OSがハードウェアをアプリケーションから抽象化するように、MemOSはLLMアプリケーション向けに、異種メモリタイプ(パラメータ、アクティベーション、プレーンテキスト)を抽象化します。
| Traditional OS | MemOS Module | Function |
|---|---|---|
| Registers / Microcode | Parameter Memory | Long-term ability |
| Cache / I/O Buffer | Activation Memory | Fast working state |
| Main Memory | Plaintext Memory | External episodes |
| Scheduler | MemScheduler | Prioritise ops |
| File System | MemVault | Versioned store |
| System Call | Memory API | Unified access |
| Device Driver | MemLoader / Dumper | Move memories |
| Package Manager | MemStore | Share bundles |
| Auth / ACLs | MemGovernance | Access control |
| Syslog | Audit Log | Audit trail |
MemOSは、LLM(大規模言語モデル)のメモリを、3つの主要なタイプに体系化し、それらが連携して、揮発性の推論状態から持続的なパラメータ知識まで、知識表現のフルスペクトルを反映するように設計されています。
明示的に保存された、構造化/非構造化テキストデータ。これには、会話履歴、ユーザーの好み、エピソードノートなどが含まれます。解釈の容易性が最も高く、統合コストが最も低いです。高速アクセスを可能にする、メインメモリに類似した機能を提供します。
推論と関連付けられた活性化状態 — KVキャッシュ、隠れ状態制御ベクトル。プレーンテキストとパラメータメモリを接続します。フルファインチューニングなしで、高速な動作状態の注入を可能にします。
モデルの重みに含まれる暗黙的な知識 — LoRAアダプター、重みパッチ、ファインチューニングされたモジュール。最も深い統合レベルと耐久性を持つ。長期的なスキルと知識の定着に使用されます。
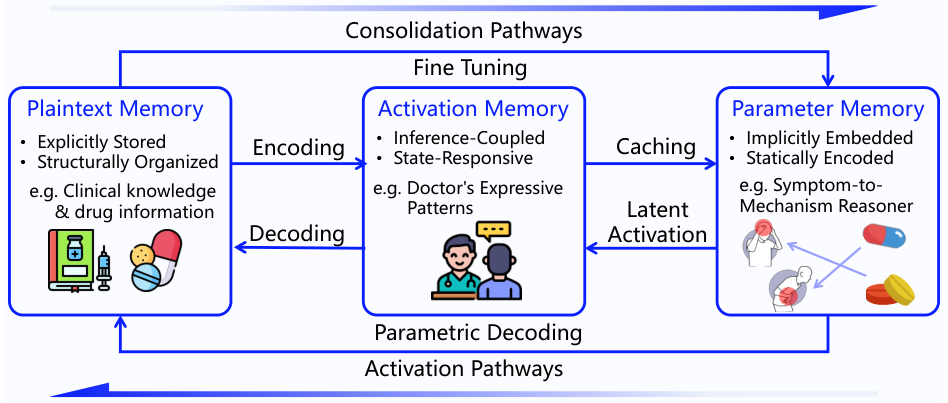
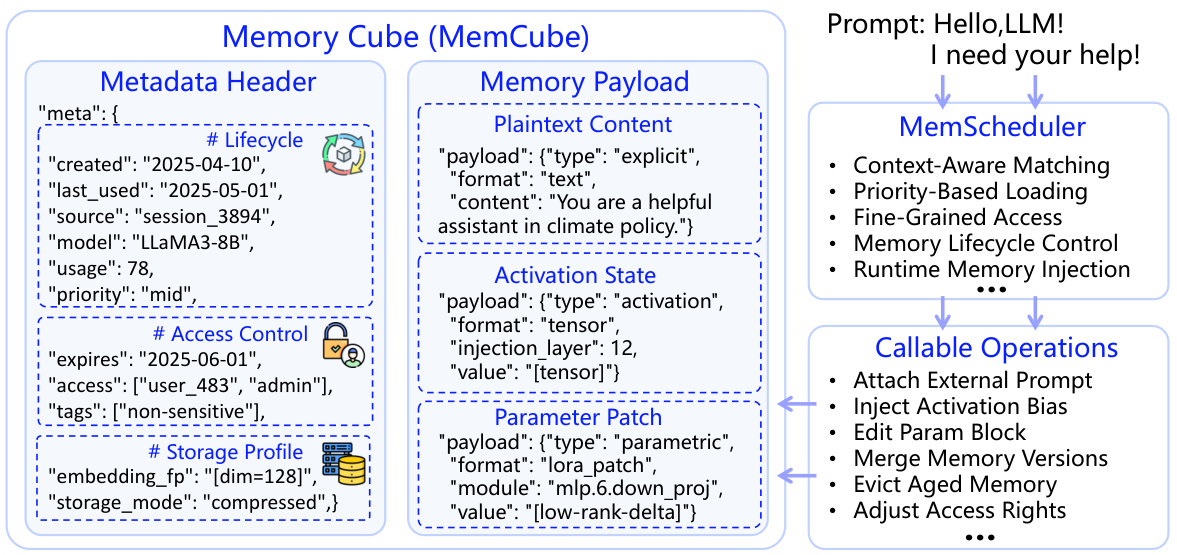
MemCubeは、3種類のメモリすべてにおいて、メモリの表現、ライフサイクル管理、およびスケジューリングを標準化する、統一された抽象化レイヤーです。
各MemCubeは、メタデータヘッダー(ライフサイクルタイムスタンプ、アクセス制御リスト、ストレージプロファイル)とメモリペイロード(プレーンテキストコンテンツ、アクティブ化状態、またはパラメータパッチ)で構成されます。MemCubesは、時間経過とともに構成、移行、および統合することができます。
MemSchedulerは、コンテキストを考慮したマッチング、優先順位に基づいたロード、メモリのライフサイクル制御、および実行時メモリの注入を処理します。これにより、適切なMemCubesを、適切なLLMに、適切なタイミングで割り当てることができます。
"meta": {
"created": "2025-04-10",
"source": "session_3894",
"model": "LLaMA3-8B",
"priority": "mid",
"expires": "2025-06-01",
"access": ["user_483", "admin"]
}
"payload": {
"type": "explicit",
"format": "text",
"content": "You are a helpful assistant..."
}
MemOSは、複雑なメモリタスクの効率的な実行、動的なスケジューリング、および適切なガバナンスをサポートするために、モジュール式の3層アーキテクチャを採用しています。
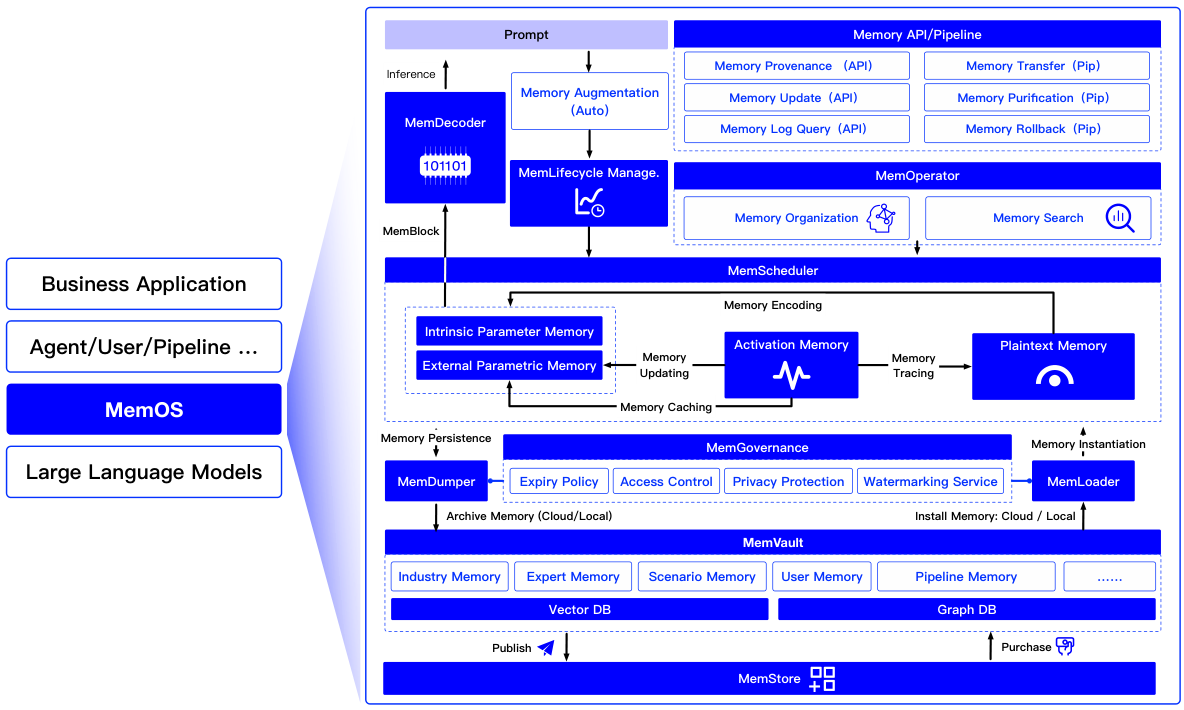
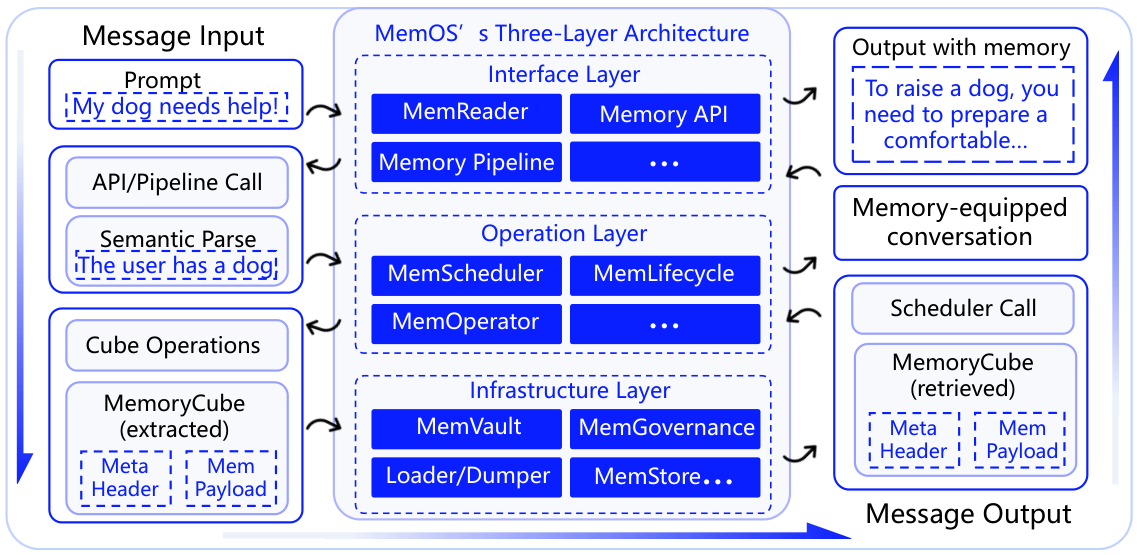
ユーザーがメッセージを送信すると、MemReaderは意図を解析し、MemoryQueryを生成します。MemOperatorは、MemVaultから一致するMemCubesを取得し、MemSchedulerは関連するメモリをLLMのコンテキストに注入します(プレーンテキスト、アクティベーションバイアス、またはパラメータパッチとして)。その後、モデルは、メモリを付加した応答を生成します。この一連の操作はすべて、MemGovernanceによって監査ログに記録されます。
私たちは、MemOSの機能を、包括的な実験とコンポーネントレベルの実験を通じて体系的に評価します。具体的には、長文コンテキストのメモリ性能、パーソナライゼーションの理解、チャンクサイズの感度、検索の堅牢性、およびKVベースの高速化といった、システム全体のパフォーマンスをベンチマークします。
MemOSは、LoCoMoおよびLongMemEvalのベンチマークにおいて、MIRIX、Zep、MemBase、Mem0、およびSupermemoryと比較評価されています。MemOS-1031は、最高平均スコア(75.80)を達成し、これは以前最高だったMemBase(72.01)と比較して5%の改善に相当します。
| Method | Memory Size | LiftAge ↑ | F1 ↑ | ROUGE-L ↑ | BLEU ↑ | Avg ↑ | LoCoMo ↑ |
|---|---|---|---|---|---|---|---|
| No Memory | — | 68.22 | 54.26 | 68.54 | 46.88 | 64.33 | 28.10 |
| MIRIX | 1,172 | 73.33 | 58.75 | 52.34 | 45.83 | 64.57 | 43.46 |
| Zep | 2,701 | 66.23 | 52.12 | 54.82 | 33.33 | 59.22 | 41.23 |
| MemBase | 2,102 | 73.12 | 64.65 | 81.20 | 53.12 | 72.01 | 50.18 |
| Mem0 | 617 | 66.34 | 63.12 | 27.10 | 50.01 | 56.55 | 35.15 |
| Supermemory | 500 | 67.30 | 51.12 | 31.77 | 42.67 | 55.34 | 34.87 |
| MemOS-1031 | 1,589 | 81.09 | 67.49 | 75.18 | 55.90 | 75.80 | 45.27 |
MemOSは、個人化の品質を評価するために、PrefEvalおよびPersonaMemのベンチマークで評価されます。MemOSは、ゼロターン設定と10回の無関係なターン設定の両方において、最も優れたパーソナライズされた応答性能を達成し、同時に、最も低いPreference Unaware Rate(ユーザーの好みを考慮しない割合)を示しており、これはMemOSが、無関係なコンテキストに惑わされることなく、常にユーザーの好みを記憶し、適用していることを意味します。
PersonaMemベンチマークにおいて、MemOSは最高の精度を達成し、同時に許容可能なコンテキスト長を維持しました。これは、広範囲なインタラクション履歴にわたって、ユーザーの嗜好の変化を効果的に処理する能力の高さを示しています。
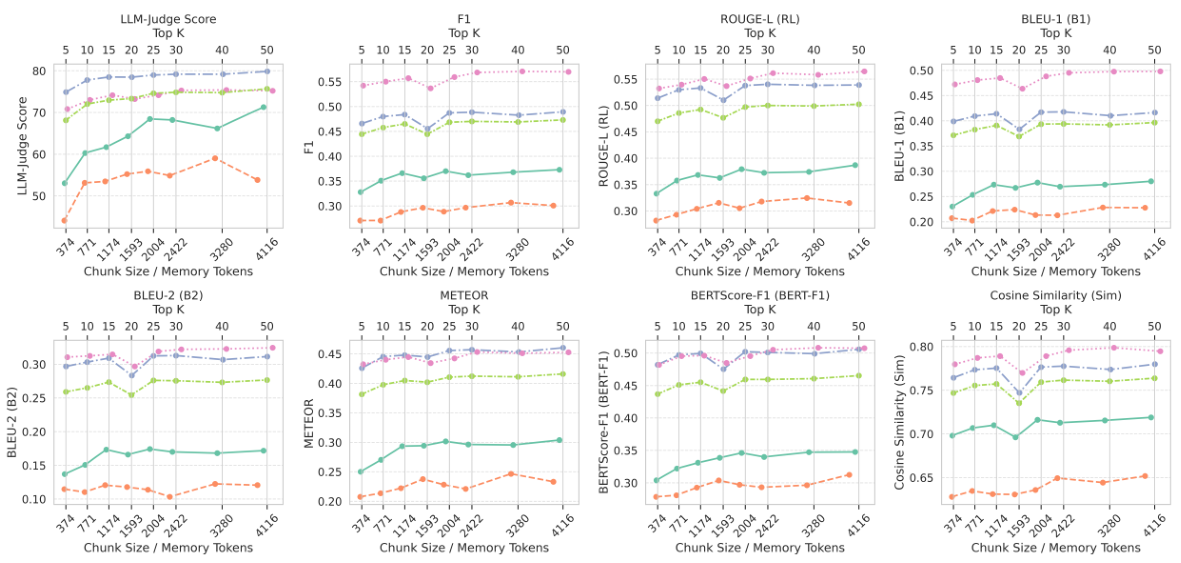
複数の指標にわたって、MemOSのパフォーマンスに与える影響について、取得されたメモリチャンクの数(Top-K)とチャンクサイズの影響を分析します。パフォーマンスは、Top-K=3およびチャンクサイズが約512トークンの場合に安定し、コンテキストウィンドウの使用量と検索品質の最適なバランスを提供します。
我々は、ネットワークAPIを介したメモリ検索の効率性と堅牢性を、1秒あたりのクエリ数(QPS)が異なる状況下で評価する、集中的な評価を実施します。評価指標には、メモリへの挿入(add)および検索(search)操作の両方について、P99、P90、および平均遅延時間、ならびに成功率が含まれます。
MemOSは、すべてのQPSレベルにおいて100%の成功率を達成し、同時に最も低いレイテンシを維持しました。これは、高い同時実行状況下でも、堅牢な本番環境レベルのメモリ検索パフォーマンスを発揮することを示しています。
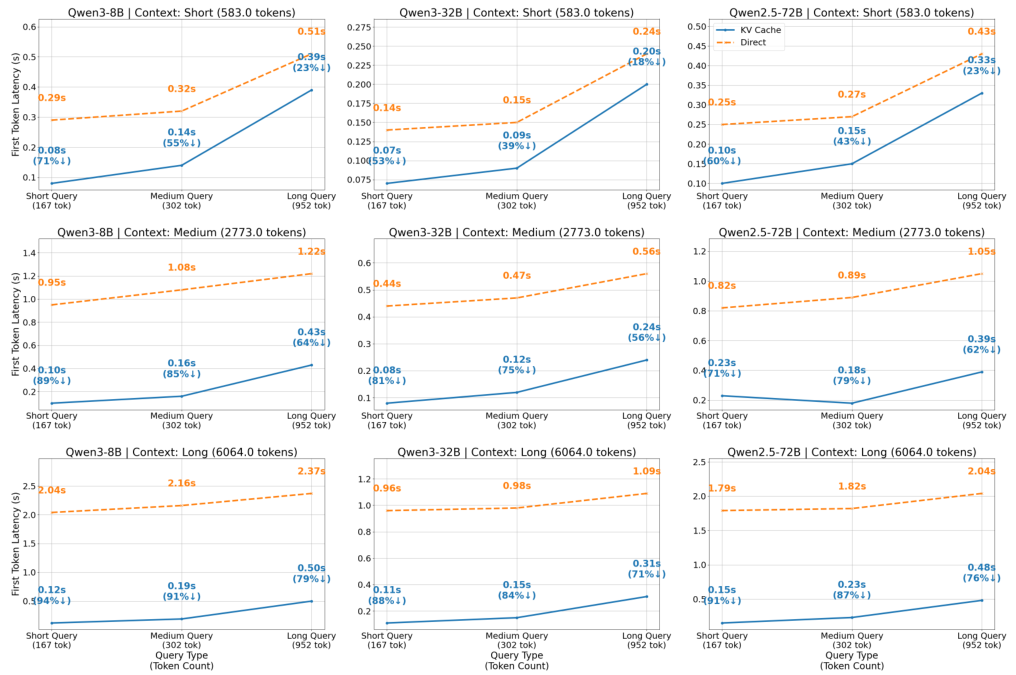
KVベースのメモリインジェクションは、メモリの内容からキー・バリューキャッシュを事前に計算し、推論時に繰り返されるアテンション計算を省略します。ここでは、モデルサイズ(3B、7B、72B)、コンテキスト長(短い/中間の/長い)、およびクエリ長において、標準的なアテンションと比較して、最初のトークンまでの時間(TTFT)を比較します。
MemOSは、永続的なメモリがモジュール化され、管理可能なリソースとなるAIアプリケーションのための新しいパラダイムを提供します。主な応用シナリオは以下の通りです:
MemOSは、メモリをシステムのリソースとして第一に扱い、複数の形式でのメモリの統合的なライフサイクル管理とオーケストレーションを可能にします。この抽象化は、以下の2つの主要なアーキテクチャ的革新をサポートします。
ドメインの専門家は、MemStoreを通じて、構造化された経験的な知識を公開できます。これは、知識のプラグインのようなものです。ユーザー(学生、企業担当者、アシスタントモデルなど)は、これらの知識モジュールを購読し、ダウンロードし、アクティブ化することで、ファインチューニングなしに、すぐに特定の分野の専門知識を獲得できます。
ユーザーと開発者は、標準化されたタスクレベルのMemory APIコールを通じてメモリにアクセスします。これにより、ローレベルのベクトルインデックス処理、KVキャッシュ、またはコンテキストオーケストレーションを扱う必要がありません。Memoryは、従来のOSにおけるストレージサブシステムと同様に、普遍的で、長期間利用可能で、共有可能なインフラストラクチャリソースです。
MemOSは、セッションやモダリティを越えて、会話履歴、ユーザーの好み、タスクのコンテキストを維持します。これにより、コンテキストウィンドウの制限なしに、シームレスな長期的なインタラクションが可能になります。
ドメイン知識は、完全な再学習なしに、MemCubeの注入によって継続的に更新することができます。新しい情報は、プレーンテキストまたは活性化レベルで統合され、その後、時間の経過とともにパラメータメモリに統合されます。
ユーザー固有の好み、コミュニケーションスタイル、および役割定義は、MemCubesとして保存され、推論時に注入されます。これにより、多様なユーザープロファイルに対して、真にパーソナライズされた体験を提供することが可能になります。
MemCubesは、MemStoreを通じて、モデルインスタンスやプラットフォーム間でエクスポート、インポート、および転送が可能です。これにより、ユーザーが自身のAIメモリを所有できる、分散型のメモリマーケットプレイスが実現します。
今回、LLM(大規模言語モデル)向けに設計されたメモリオペレーティングシステム「MemOS」をご紹介します。MemOSは、次世代のLLMのために、基盤となるメモリインフラを共同で構築することを目的としています。MemOSは、パラメータメモリ、アクティベーションメモリ、および明示的なプレーンテキストメモリなど、異種メモリタイプに対して、統一された抽象化と統合された管理フレームワークを提供します。
MemCubeという抽象化技術は、制御可能で、柔軟性があり、進化可能なメモリ管理を可能にし、大規模な継続学習とパーソナライズされたモデリングのための基盤を築きます。MemOSは、評価されたすべてのベンチマークにおいて最先端のパフォーマンスを達成し、KVベースのメモリアクセラレーションによって、最初のトークンまでの時間を大幅に短縮します。
今後の展望として、私たちは、モジュール式のメモリリソースを中心とした、インテリジェントなエコシステムを構想しており、これは分散型のメモリマーケットプレイスによって支えられます。このパラダイムシフトは、ステートレスなツールから、メモリが豊富な持続的なエージェントへと移行するものであり、これはAIシステム設計における次のフロンティアを意味します。