はじめに
近年のText-to-Speech(TTS)システムは単話者・短発話合成において印象的な成果を上げています。しかし、複数の異なる話者による長時間・自然な対話生成という大きな課題は未解決のままです。2人の話者が数千トークンにわたって一貫した声質、自然な発話交替、自然なプロソディを維持する30分のポッドキャストを生成することは、既存モデルが確実に達成できる範囲をはるかに超えています。
核心的な課題はスケールです。Encodecなどの標準的なオーディオコーデックは75〜600 Hzで動作するため、数分間の音声だけで数十万ものトークンが生成され、現行LLMのコンテキスト容量を大幅に超えます。トークン密度を根本的に削減しない限り、長時間多話者生成は計算的に不可能です。
なぜフレームレートが音声処理で重要なのか?
音声処理における「フレームレート」(Hz単位)とは、音声1秒あたりに生成されるトークンまたは潜在ベクトルの数を意味します。従来のEncodecは75 Hzで動作するため、1分間の音声 = 75 × 60 = 4,500トークンになります。複数話者による30分のポッドキャストでは135,000トークンにも達し、ほとんどのLLMのコンテキストウィンドウ(通常4K〜32K)を大幅に超えます。
VibeVoice のトークナイザーはわずか7.5 Hzを実現し、Encodecの10分の1のトークン数で済みます。同じ30分のポッドキャストで約13,500トークンとなり、64Kのコンテキストウィンドウに余裕で収まります。課題は、音質を損なわずに音声を10分の1に圧縮することです。答えは6段階のダウンサンプリングを持つ巧みなVAEアーキテクチャです。
VibeVoice はわずか7.5 Hzで動作する新しい連続音声トークナイザーで、音声の忠実度を保ちながらEncodec比80×以上の圧縮を実現することでこの課題を解決します。この超低フレームレートにより、標準的なLLMバックボーンを使用した64Kトークンのコンテキストウィンドウ内で、90分・4話者の合成が実現可能になります。
アーキテクチャは意図的にシンプルに設計されています。事前学習済みLLM(Qwen2.5、1.5Bまたは7Bパラメータ)が音声プロンプトとテキストスクリプトを処理し、軽量な拡散ヘッドがトークンごとに連続音声潜在ベクトルを生成します。このシンプルさは意図的なもので、VibeVoice が単一の統合パイプラインに集約した複雑な独立コンポーネントを従来の設計は必要としていました。
主な貢献
- 超低フレームレートトークナイザー(7.5 Hz) — Encodec比80×圧縮を実現する新しい連続音声トークナイザー。トークンコストのごく一部で音声の忠実度を保持
- 次トークン拡散LLMバックボーン — LLMシーケンスモデリングとトークンレベル拡散デコードを組み合わせた、高忠実度連続音声のための統合フレームワーク
- 64Kコンテキストウィンドウ / 90分合成 — 1回の生成ランで最大4話者を同時サポート。オープンソースTTSで前例のない性能
- 最先端の品質 — VibeVoice-7B は、好み・自然さ・豊かさのMOSスコアにおいてGemini-2.5-Pro-Preview-TTS、Eleven-V3、および全オープンソース競合モデルを上回る
手法
2.1 音声トークナイザー
VibeVoice は音響特徴と意味特徴の両方を学習するために2つの独立したトークナイザーを採用しています。長時間音声の生成はこの分離から恩恵を受けます。音響トークナイザーは超低ビットレートで音質を保持し、意味トークナイザーは言語コンテンツを独立して捉えます。
音響トークナイザー
自己回帰設定での分散崩壊を防ぐために、Variational Autoencoder(VAE)の原理 — 具体的にはLatentLMのo-VAEバリアント — に基づいています。効率的なストリーミングのために1D深度方向因果畳み込みを使用した、修正Transformerブロックの7段階の階層的ミラー対称エンコーダー-デコーダーを特徴とします。
6つのダウンサンプリング層が画期的な圧縮を実現します。エンコーダーはタイムステップごとに連続潜在ベクトルZtを生成し、デコーダーはこれらの潜在表現から波形を再構築します。設計全体が因果的(causal)で、リアルタイムのストリーミング合成が可能です。
意味トークナイザー
音響トークナイザーのエンコーダーの階層的アーキテクチャを反映しますが、VAEコンポーネントなしで決定論的です。音響的な忠実度ではなく、コンテンツ中心の言語特徴を抽出することに特化しています。
プロキシ学習目標として自動音声認識(ASR)を使用します。これにより意味潜在表現が言語コンテンツに根付き、モデルが何が言われているか(意味的)とどのように聞こえるか(音響的)を別々に理解できるようになります。これが一貫した長時間生成の鍵です。
VAEとは何か、なぜ分散崩壊が問題なのか?
Variational Autoencoder(VAE)は、入力を単一の固定ベクトルではなく、コンパクトな確率分布(平均と分散)にエンコードすることを学習します。デコード時にはこの分布からサンプリングして元のデータを再構築します。利点は、潜在空間が滑らかで連続的になり、音声間の補間が自然に行えることです。
問題点:各トークンが前のトークンに依存する自己回帰モデルでは、標準的なVAEは分散崩壊に悩まされます。モデルが確率的成分を完全に無視することを学習してしまい、潜在空間がほぼ決定論的に縮退します。LatentLMの「o-VAE」バリアントは分散項を再パラメータ化することでこれを修正し、生成プロセス全体で意味のある不確実性を維持します。
2.2 VibeVoice アーキテクチャ
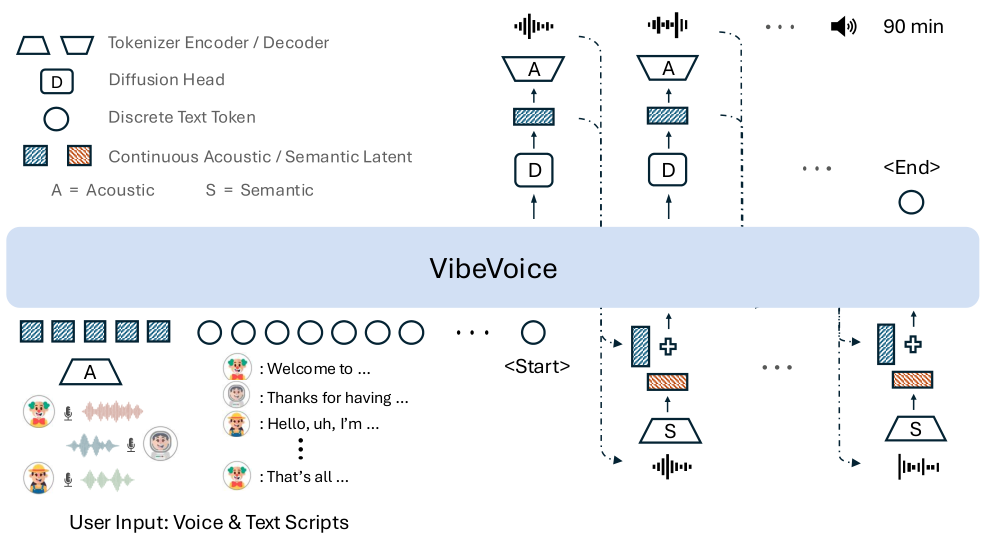
VibeVoice はコアとなるシーケンスモデルとして大規模言語モデル(LLM)を使用し、専用の音声エンコードと拡散ベースのデコードと統合されています。LLM(Qwen2.5)は音声フォント特徴とテキストスクリプト埋め込みを交互に処理し、役割識別子で話者を区別します。各ステップで、LLMの隠れ状態を条件とする軽量な拡散ヘッドが次の連続音響潜在ベクトルを生成します。
次トークン拡散(Next-Token Diffusion)とは何か?
標準的な自己回帰言語モデルはトークンを1つずつ生成します。各トークンは離散的(語彙から選択するカテゴリ値)です。音声は異なります — 連続的(波形)です。可能な音声の「辞書」から選ぶことはできません。
拡散モデルは連続生成の問題をランダムノイズから始めて目標信号に向かって段階的にノイズ除去することで解決します。しかし従来の拡散モデルは出力全体を一度に生成し、トークンごとの生成ではありません。
次トークン拡散は両方を組み合わせます。各自己回帰ステップで、離散トークンを出力する代わりに、モデルはLLMの隠れ状態を条件として小さな拡散プロセスを実行し、次の連続潜在ベクトルを生成します。LLMが各音声セグメントの「意図」を提供し、拡散が音響的な詳細を埋める、というイメージです。これにより任意の長さの音声のストリーミング生成が可能になります。
入力表現
X = [Speaker1:Z1, Speaker2:Z2, ..., SpeakerN:ZN] + [Speaker1:T1, Speaker2:T2, ..., SpeakerN:TN]
Zは音声プロンプトからの音響潜在特徴を表し、Tは意味テキスト埋め込みを表します。話者役割識別子(Speakerk)が特徴を交互に配置することで、64Kトークンのコンテキストウィンドウ全体を通して、どの話者がどの音声セグメントを生成しているかをモデルが追跡できます。
トークンレベル拡散:各自己回帰ステップで、拡散ヘッドはLLMの隠れ状態hiを条件として、ノイズ除去された音響潜在を予測します。学習時は順方向ノイズ付加プロセスの逆転を学習します。推論時はDPM-Solver++を使用して10ステップで高速サンプリングを行い、実用的なストリーミング生成を実現します。
モデルはQwen2.5の2つのスケール(1.5Bと7B)でインスタンス化されました。拡散ヘッドは4つのTransformerレイヤーで構成されます。学習時、音響・意味トークナイザーは凍結されており、LLMと拡散ヘッドのみが学習されるため、効率的なファインチューニングが可能です。
結果
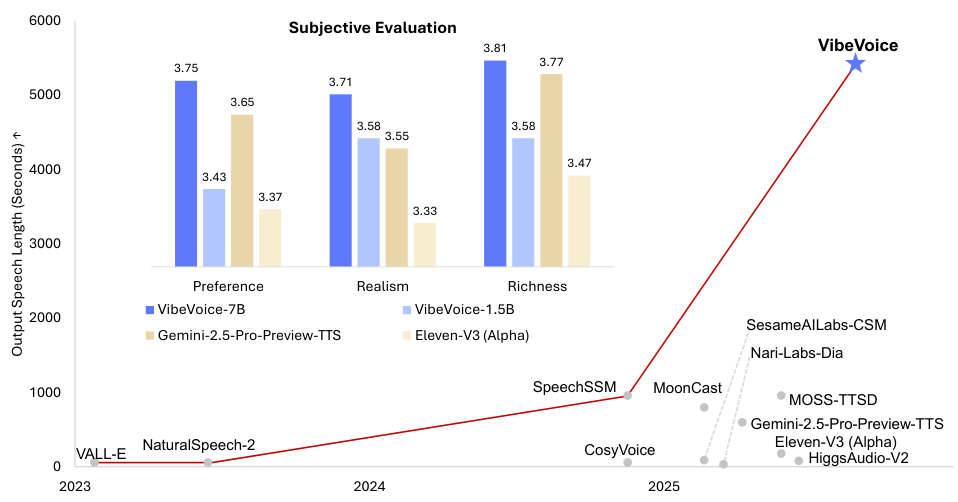
3.1 長時間ポッドキャスト評価
VibeVoice は最先端の対話音声モデルと比較評価されました。Nari Labs Dia、SesameAILabs CSM、Higgs Audio V2、Eleven-V3 Alpha、Gemini-2.5-Pro-Preview-TTS です。テストセットは8本の長い会話テキストで、合計約1時間に及びます。
客観評価:単語誤り率(WER)はWhisper-large-v3とNemo ASRで測定されました。話者類似度(SIM)はWavLM-largeの話者埋め込みを使って計算されました。
主観評価:24名の人間アノテーターが各システムを3つの次元でスコアリングしました。自然さ(Realism)(自然さ・プロソディ・感情・発話交替の滑らかさ)、豊かさ(Richness)(声調・感情・会話ダイナミクスの表現力)、好み(Preference)(総合的な試聴好み)です。
VibeVoice モデルは客観的・主観的指標の両方で全競合システムを上回ります。7Bモデルは1.5Bに対して特に知覚的品質スコアで大幅な向上を示します。LLMバックボーンのスケールアップが音声品質の向上に直結するという、全評価次元で一貫した知見が得られました。
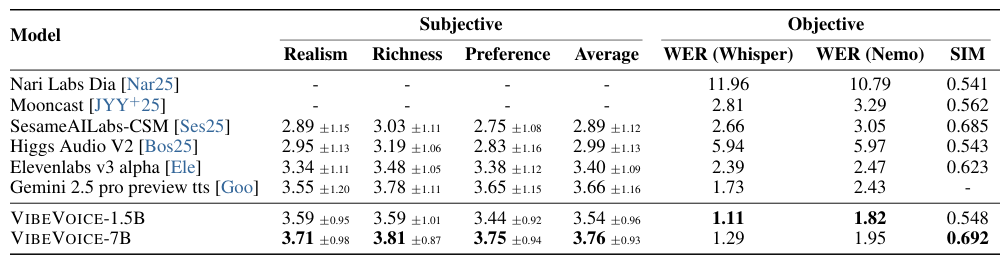
主要な知見:VibeVoice-7B は平均MOS 3.76を達成し、長時間会話においてGemini-2.5-Pro-Preview-TTS(3.40)、MOSS-TTSD(3.54)、Eleven-V3 Alpha(3.66)を上回りました。WER-Whisperの1.29%と話者類似度0.692は高い客観的品質を示しています。
3.2 ゼロショット短発話評価
VibeVoice は主に長時間音声で学習されましたが、SEEDの短発話ベンチマークでも評価されました。Common Voiceから英語約1,000サンプル・中国語約2,000サンプルを使用。指標:CER↓(中国語文字誤り率)、WER↓(英語単語誤り率)、SIM↑(話者類似度)。
比較モデルは25〜50 Hzのフレームレートで動作しますが、VibeVoice-1.5B はわずか7.5 Hzを使用し、音声1秒あたりの生成トークン数を7分の1に削減します。これにより、競争力のある精度を維持しながら推論コストを大幅に削減します。
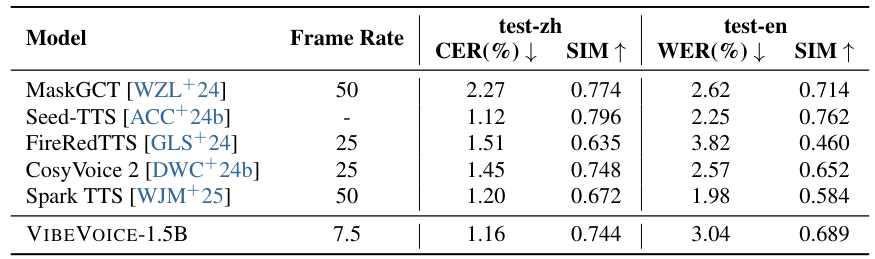
主要な知見:VibeVoice-1.5B は7.5 HzのフレームレートでCER 1.16%(中国語)とWER 3.04%(英語)を達成 — MaskGCT(50 Hz、CER 2.27%)、Seed-TTS(–、CER 1.12%)、Spark TTS(50 Hz、CER 1.20%)と競争力があります。主に長時間音声で学習されたにもかかわらず、強い汎化能力を示しています。
3.3 トークナイザー再構築品質
音響トークンから再構築された音声の忠実度は、極端な圧縮下でトークナイザーが本質的な音響情報をどれほど保持するかを測ります。VibeVoice のトークナイザーは、PESQ↑、STOI↑、MOS↑、SIM↑、UTMOS↑を用いて、LibriTTS test-cleanとtest-other上でグランドトゥルース、DAC、EnCodec、SpeechTokenizer、WavTokenizer と比較されました。
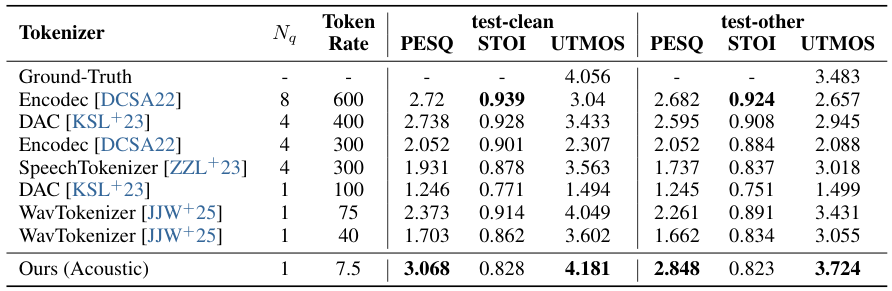
主要な知見:7.5 Hz(DACの86 Hz、EnCodecの75 Hzと比較)において、VibeVoice のトークナイザーは競争力のあるPESQ・STOI・UTMOSスコアを達成 — 80×圧縮が音質を大幅に損なわないことを実証しています。これが90分合成を可能にするコア技術です。
音声品質指標の解説
- PESQ(知覚的音声品質評価) — 参照に対する音声劣化の人間の知覚をシミュレート。スコア範囲1〜4.5、高いほど良い。電話品質の業界標準。
- STOI(短時間客観明瞭度) — 音声の明瞭度(言葉が理解できるか?)を測る。範囲0〜1、高いほど明瞭。
- UTMOS — 人間のMOS評価を自動的に予測するAIシステム。人間のアノテーションにコストがかかる大規模評価で有用。
- SIM(話者類似度) — トークナイザー再構築後に音声の特徴がどれほど保持されているか。
表3の主要な洞察:VibeVoice はわずか7.5 Hzで全指標で競争力のあるスコアを達成 — 圧縮が音声品質を大幅に損なわないことを証明しています。
結論・制約・リスク
VibeVoice は長時間・多話者音声生成のための新しいフレームワークを提案します。80×圧縮を実現する超低フレームレート(7.5 Hz)音響トークナイザー、音響・意味のハイブリッド音声表現、エンドツーエンドのLLMベース次トークン拡散バックボーンを統合することで、VibeVoice は最大4話者・最大90分の会話合成を実現します。
モデルは長時間ポッドキャスト生成で最先端の品質を達成しながら、短発話ベンチマークでも強い汎化能力を維持します。1.5Bから7Bへのスケールアップが知覚的品質を一貫して改善します。今後の方向性として、より豊かなプロソディ制御、より広い言語サポート、背景音声モデリングが挙げられます。
制約と責任ある使用
対応言語の範囲
現在は英語と中国語のみをサポートしています。他の言語のテキストは、予期しない音声出力や品質低下を引き起こす可能性があります。
音声のみ
音声合成のみに特化しています。背景ノイズ、音楽、効果音、重なり合う音声セグメントはサポートされていません。
音声の重なりなし
現在のモデルは音声の重なりを明示的にモデル化・生成しません。これは自然な会話の一部であり、未解決の研究課題として残っています。
倫理的リスク:ディープフェイクと偽情報
高品質の合成音声は、なりすまし・詐欺・偽情報拡散に悪用される可能性があります。ユーザーはテキストの信頼性を確保し、誤解を招く用途を避けなければなりません。VibeVoice はさらなる安全性テストなしに商用または現実世界での展開は推奨されません。研究目的のみを意図しています。
参考文献(45件)
- [ACC+24a] Philip Anastassiou et al. Seed-tts: A family of high-quality versatile speech generation models. arXiv:2406.02430, 2024.
- [ACC+24b] Philip Anastassiou et al. Seed-tts: A family of high-quality versatile speech generation models. arXiv:2406.02430, 2024.
- [Bos25] Boson AI. Higgs Audio V2: Redefining Expressiveness in Audio Generation. GitHub, 2025.
- [CNM+24] Yushen Chen et al. F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching. arXiv:2410.06885, 2024.
- [CWC+22] Sanyuan Chen et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE JSTSP, 2022.
- [DCSA22] Alexandre Défossez et al. High fidelity neural audio compression. arXiv:2210.13438, 2022.
- [DWC+24a] Zhihao Du et al. CosyVoice 2: Scalable streaming speech synthesis with LLMs. arXiv:2412.10117, 2024.
- [DWC+24b] Zhihao Du et al. CosyVoice 2: Scalable streaming speech synthesis with LLMs. arXiv:2412.10117, 2024.
- [Ele] ElevenLabs. ElevenLabs v3 alpha.
- [GLS+24] Haohan Guo et al. FireRedTTS: A foundation TTS framework for industry-level applications. arXiv:2409.03283, 2024.
- [Goo] Google. Gemini 2.5 Pro Preview TTS.
- [Goo24] Google. NotebookLM. 2024.
- [GZMY22] Zhifu Gao et al. Paraformer: Fast and accurate parallel transformer for non-autoregressive ASR. Interspeech 2022.
- [HJA20] Jonathan Ho, Ajay Jain, Pieter Abbeel. Denoising diffusion probabilistic models. NeurIPS 33, 2020.
- [JCC+25] Dongya Jia et al. DiTar: Diffusion transformer autoregressive modeling for speech. arXiv:2502.03930, 2025.
- [JJW+25] Shengpeng Ji et al. WavTokenizer: An efficient acoustic discrete codec tokenizer. ICLR 2025.
- [JYY+25] Zeqian Ju et al. MoonCast: High-quality zero-shot podcast generation. arXiv:2503.14345, 2025.
- [KSL+23] Rithesh Kumar et al. High-fidelity audio compression with improved RVQGAN. NeurIPS 2023.
- [KW14] Diederik P. Kingma, Max Welling. Auto-Encoding Variational Bayes. ICLR 2014.
- [LTL+24] Tianhong Li et al. Autoregressive image generation without vector quantization. arXiv:2406.11838, 2024.
- [LVS+23] Matthew Le et al. Voicebox: Text-guided multilingual universal speech generation at scale. NeurIPS 2023.
- [LWI+24] Zhijun Liu et al. Autoregressive diffusion transformer for TTS. arXiv:2406.05551, 2024.
- [LZB+22] Cheng Lu et al. DPM-Solver: A fast ODE solver for diffusion probabilistic models. NeurIPS 2022.
- [LZB+25] Cheng Lu et al. DPM-Solver++: Fast solver for guided sampling of diffusion models. MIR, 2025.
- [Nar25] Nari Labs. Nari Labs Dia. GitHub, 2025.
- [Ope25] OpenMOSS Team. MOSS-TTSD. GitHub, 2025.
- [PSJ+24] Se Jin Park et al. Long-form speech generation with spoken language models. arXiv:2412.18603, 2024.
- [RBHH01] Antony W. Rix et al. PESQ: Perceptual evaluation of speech quality. ICASSP 2001.
- [RKX+23] Alec Radford et al. Robust speech recognition via large-scale weak supervision. ICML 2023.
- [SBW+24] Yutao Sun et al. Multimodal latent language modeling with next-token diffusion. arXiv:2412.08635, 2024.
- [Ses25] SesameAILabs. SesameAILabs CSM Model. GitHub, 2025.
- [SHB15] Rico Sennrich, Barry Haddow, Alexandra Birch. Neural machine translation of rare words with subword units. arXiv:1508.07909, 2015.
- [SJT+23] Kai Shen et al. NaturalSpeech 2: Latent diffusion models for zero-shot TTS. arXiv:2304.09116, 2023.
- [SXN+22] Takaaki Saeki et al. UTMOS: UTokyo-SaruLab system for VoiceMOS Challenge 2022. arXiv:2204.02152, 2022.
- [THHJ10] Cees H. Taal et al. A short-time objective intelligibility measure. ICASSP 2010.
- [VSP+17] Ashish Vaswani et al. Attention Is All You Need. NeurIPS 2017.
- [WCW+23] Chengyi Wang et al. Neural codec language models are zero-shot TTS synthesizers. arXiv:2301.02111, 2023.
- [WJM+25] Xinsheng Wang et al. Spark-TTS: An efficient LLM-based TTS model. arXiv:2503.01710, 2025.
- [WZL+24] Yuancheng Wang et al. MaskGCT: Zero-shot TTS with masked generative codec transformer. arXiv:2409.00750, 2024.
- [XJM+23] Hainan Xu et al. Efficient sequence transduction by jointly predicting tokens and durations. INTERSPEECH 2023.
- [YYZ+24] An Yang et al. Qwen2.5 technical report. arXiv:2412.15115, 2024.
- [YZC+25] Zhen Ye et al. LLASA: Scaling train-time and inference-time compute for speech synthesis. arXiv:2502.04128, 2025.
- [ZDC+19] Heiga Zen et al. LibriTTS: A corpus derived from LibriSpeech for TTS. arXiv:1904.02882, 2019.
- [ZQW+25] Leying Zhang et al. CoVoMix2: Advancing zero-shot dialogue generation. arXiv:2503.00872, 2025.
- [ZZL+23] Xin Zhang et al. SpeechTokenizer: Unified speech tokenizer for speech LLMs. arXiv:2308.16692, 2023.