概要
大規模言語モデル(LLM)のアプリケーション、例えばエージェントや特定の分野における推論システムは、ますます「コンテキスト適応」に依存しています。これは、入力に指示、戦略、または証拠を追加するものであり、モデルの重みを更新するものではありません。従来の技術は使いやすさを向上させますが、多くの場合、「簡潔性バイアス」に悩まされ、それが分野固有の知識を簡潔な要約に置き換えてしまうことがあります。また、「コンテキストの崩壊」も問題で、反復的な書き換えによって詳細が時間とともに失われてしまいます。
本稿では、ACE (Agentic Context Engineering)というフレームワークを提案します。これは、コンテキストを、戦略を蓄積、洗練、整理する進化するプレイブックとして捉え、モジュール化された生成、反省、キュレーションのプロセスを通じて実現します。ACEは、構造化された段階的な更新によってコンテキストの崩壊を防ぎ、詳細な知識を保持し、長文コンテキストモデルに対応できるように設計されています。エージェントおよび分野固有のベンチマークにおいて、ACEはオフライン(システムプロンプト)とオンライン(エージェントのメモリ)の両方でコンテキストを最適化し、強力なベースラインを常に上回る結果を示しました。エージェントにおいて+10.6%、金融分野において+8.6%の改善が見られました。
エージェント型コンテキストエンジニアリングとは?
従来のLLM改善はモデルの重みを更新するファインチューニングが主流でしたが、コストが高く時間もかかります。 ACE(エージェント型コンテキストエンジニアリング)は発想を転換し、モデル自体を変えるのではなく、 モデルに与える入力(コンテキスト)を継続的に改善します。タスクを実行するたびにAIが自ら「取扱説明書」を 更新し、次回のパフォーマンスを高めるイメージです。「エージェント型」とは、この改善プロセス自体がAIエージェントに よって自動化されていることを意味します。
1. 概要 — 全体的なパフォーマンス
現代のAIアプリケーションは、ますますコンテキスト適応に依存しています。モデルの重みを変更する代わりに、コンテキスト適応は、トレーニング後に、明確な指示、構造化された推論ステップ、またはドメイン固有の知識をモデルの入力に直接組み込むことで、パフォーマンスを向上させます。
コンテキスト適応 vs ファインチューニング
ファインチューニングは知識をモデルの重みに永続的に焼き込む手法です。高コスト・要ラベルデータ・新チェックポイント生成が必要で、更新のたびに再学習が求められます。コンテキスト適応は対照的に、推論時に指示・例・戦略をモデルへの入力として追加するだけです。GPU学習は不要で更新は即時、同じベースモデルがコンテキストを切り替えるだけで複数タスクに対応できます。ACEはそのコンテキストを自動最適化します。
主な発見事項:
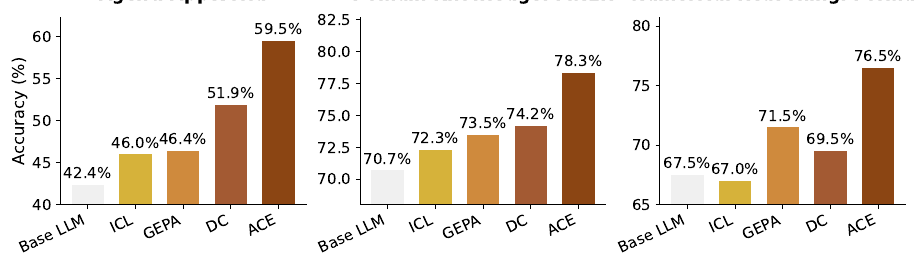
- ACEは、強力なベースラインを常に上回り、エージェントにおいて平均+10.6%、ドメイン固有のベンチマークにおいて+8.6%の改善が見られます。
- ACEは、ラベル付きの教師なし学習を使用せずに、効果的なコンテキストを構築し、実行フィードバックと環境からの信号を活用します。
- AppWorldにおいて、ACEは、最上位の商用レベルエージェントであるIBM-CUGA (GPT-4.1)と同等のパフォーマンスを発揮し、さらに小さいオープンソースモデルであるDeepSeek-V3.1を使用しています。
- ACEは、既存の方法よりも大幅に少ない回数の試行回数で済み、より低い適応遅延を実現します。
2. 背景と動機
2.1 コンテキスト適応
コンテキスト適応とは、LLMの重みを変更するのではなく、入力を作成または修正することで、モデルの動作を改善する手法を指します。代表的な手法としては、Reflexion、TextGrad、GEPA、Dynamic Cheatsheetなどがあり、これらはすべて、反復的なコンテキスト改善のために、自然言語によるフィードバックを活用しています。
2.2 限界:簡潔性バイアスとコンテキストの崩壊
なぜこの2つの失敗が重要なのか?
チェス戦略ガイドをAIに管理させる場面を想像してください。
- 簡潔性バイアス:AIがガイドを短い箇条書きに圧縮し続け、レアだが重要な戦術(「キング・ポーン終盤のツークツワング」等)が切り捨てられる。
- コンテキストの崩壊:一括書き換えを繰り返すと、書き換えるたびに詳細が失われ、最終的にはガイドなしより性能が低下してしまう。
ACEは全体を書き直さず新規エントリを追加し、完全な重複のみ削除することでこの両問題を解決します。
3. エージェント型コンテキストエンジニアリング (ACE)
ACEは、Dynamic Cheatsheetのエージェント設計に触発され、3つの専門的なLLMコンポーネントに分けて、構造化された役割分担を導入します。
「進化するプレイブック」というメタファー
スポーツやビジネスのプレイブックは、実績ある戦略を集めた生きたドキュメントです。 チームは勝敗から学ぶたびに更新します。ACEはこのメタファーをAIに適用します。 コンテキストプレイブックは空の状態から始まり、タスク実行のたびに更新されます。 Generatorがプレイブックを参照してタスクを実行し、Reflectorが結果から教訓を抽出し、 Curatorがその教訓を新しいエントリとして書き込みます。数十回の反復を経ると、 ベースモデルを再学習することなく、タスク特化の豊富な知識ベースが完成します。
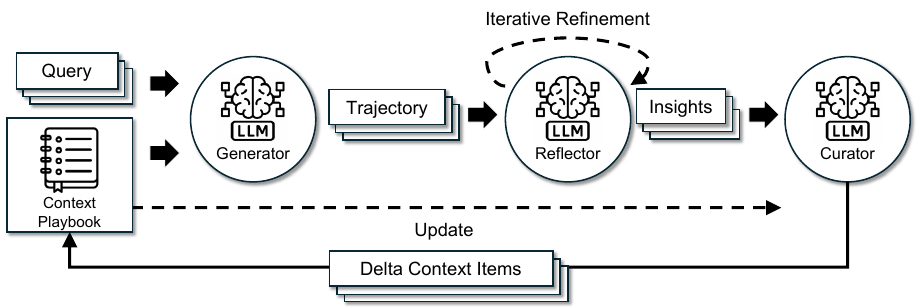
3.1 段階的なデルタ更新
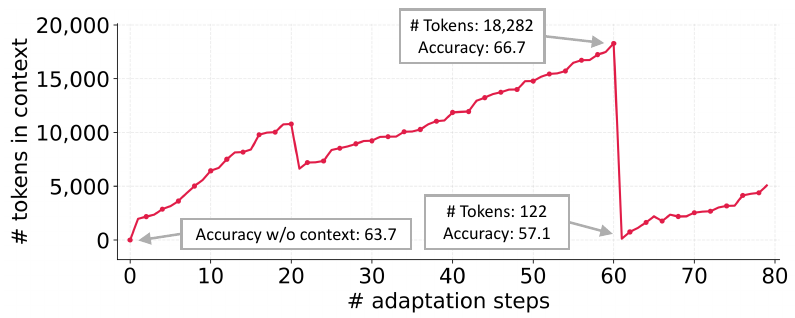
ACEは、コンテキスト全体を再生成するのではなく、コンパクトな デルタコンテキストを段階的に生成します。これは、リフレクターによって抽出された少数の候補項目であり、キュレーターによって統合されます。これにより、過去の知識が維持され、完全な書き換えにかかる計算コストを回避できます。
デルタ更新 — Gitコミットに例えると
プレイブック全体をタスクごとに書き直す代わりに、ACEは差分のみを追加します。 新しいヒント、修正された戦略、観察された失敗パターンなどです。これはGitコミットに似ています。 各実行が小さな差分を生成し、それをメインブランチにマージします。履歴は完全に保持され、 何も失われず、更新コストもドキュメント全体を再生成する場合と比べて大幅に削減されます。
3.2 成長と改善
段階的な成長に加えて、ACEは、コンテキストがコンパクトな状態を維持するように、定期的なまたは遅延された 改善を行います。重複排除のステップにより、意味的な埋め込みを使用して項目を比較し、冗長性を排除することで、包括的でありながらも冗長性のないプレイブックを維持します。
セマンティック重複排除とは?
プレイブックが成長するにつれ、異なる言葉で本質的に同じことを述べたエントリが現れます。 ACEはセマンティックエンベディングでこれを検出します。各箇条書きが意味を捉えた 数値ベクトルに変換され、コサイン類似度が閾値を超えるペアは重複とみなされ一方が削除されます。 これにより、表面的な言い回しの差異ではなく意味レベルでの重複を除去でき、 プレイブックをスリムに保ちながらも固有の知識は一切失いません。

4. 結果
4.3 エージェントベンチマーク: AppWorld (DeepSeek-V3.1-671B)
| 手法 | 正解ラベル | Test-Normal | Test-Challenge | 平均値 | ||
|---|---|---|---|---|---|---|
| TGC↑ | SGC↑ | TGC↑ | SGC↑ | |||
| DeepSeek-V3.1-671BをベースとしたLLM | ||||||
| ReAct | — | 63.7 | 42.9 | 41.5 | 21.6 | 42.4 |
| オフライン適応 | ||||||
| ReAct + ICL | ✓ | 64.3 | 46.4 | 46.0 | 27.3 | 46.0 |
| ReAct + GEPA | ✓ | 64.9 | 44.6 | 46.0 | 30.2 | 46.4 |
| ReAct + ACE | ✓ | 76.2 | 64.3 | 57.3 | 39.6 | 59.4 |
| ReAct + ACE | ✗ | 75.0 | 64.3 | 54.4 | 35.2 | 57.2 |
| オンライン適応 | ||||||
| ReAct + DC (CU) | ✗ | 65.5 | 58.9 | 52.3 | 30.8 | 51.9 |
| ReAct + ACE | ✗ | 69.6 | 53.6 | 66.0 | 48.9 | 59.5 |
表1: AppWorldの結果。ACEは、ベースラインと比較して平均で+10.6%向上し、正解ラベルがなくても効果的です。
AppWorldベンチマークの指標の読み方
- TGC(タスクゴール達成率):エージェントが割り当てられた目標を完全に達成できたか。厳格な二値評価。
- SGC(サブゴール達成率):中間ステップの何割を正しく完了できたか。より柔軟な評価指標。
- Test-Normal vs Test-Challenge:「Challenge」はより難しい多段階ワークフロー。難易度が上がるほど手法間の差が広がります。
- 正解ラベル(✓/✗):適応時に正解ラベルを使用したかどうか。ACEはラベルなし(✗)でも教師ありの競合手法(✓)を上回り、実行フィードバックだけで自己改善できることを示しています。
- オフライン vs オンライン:オフラインはデプロイ前にシステムプロンプトを改善。オンラインは稼働中にエージェントメモリをリアルタイム更新。
4.4 ドメイン特化ベンチマーク: 金融 (DeepSeek-V3.1)
| 手法 | 正解ラベル | FiNER (正答率↑) | Formula (正答率↑) | 平均値 |
|---|---|---|---|---|
| DeepSeek-V3.1をベースとしたLLM | ||||
| ベースLLM | — | 70.7 | 67.5 | 69.1 |
| オフライン適応 | ||||
| ICL | ✓ | 72.3 | 67.0 | 69.6 |
| MIPROv2 | ✓ | 72.4 | 69.5 | 70.9 |
| GEPA | ✓ | 73.5 | 71.5 | 72.5 |
| ACE | ✓ | 78.3 | 85.5 | 81.9 |
| ACE | ✗ | 71.1 | 83.0 | 77.1 |
| オンライン適応 | ||||
| DC (CU) | ✓ | 74.2 | 69.5 | 71.8 |
| DC (CU) | ✗ | 68.3 | 62.5 | 65.4 |
| ACE | ✓ | 76.7 | 76.5 | 76.6 |
| ACE | ✗ | 67.3 | 78.5 | 72.9 |
表2: 金融分析の結果。ACEは、オフライン適応において、正解ラベルを使用した場合、平均+12.8%の改善を達成しています。
なぜドメイン特化の改善が重要なのか?
FiNER(金融テキストの固有表現認識)やFormula(金融数式推論)のような 金融NLPタスクは、一般的なLLM学習では十分に扱われない高度に専門化された知識を必要とします。 財務略語、報告慣行、業界特有の専門用語などです。ACEのプレイブックはドメイン内の事例から これらのニュアンスを蓄積し、解決した事例が増えるたびに成長する分野特化参照シートを モデルに提供します。正解ラベルありの場合の+12.8%という向上幅は、ドメイン特化コンテキストが 汎用ベースLLMと比べてどれだけ大きな可能性を持つかを示しています。