
Lightricks
LTX-2: 高効率な音声・映像統合基盤モデル
初のオープンソースの、テキストから音声と動画を同時に生成する基盤モデル
19B Parameters
18x Faster
Open Source
Stereo Audio
同期した動画と高品質な音声トラック(音声、 Foley 効果、環境音を含む)を生成する統合モデル。これにより、極めて高い計算効率で、最先端の品質を実現します。
Lightricks
初のオープンソースの、テキストから音声と動画を同時に生成する基盤モデル
同期した動画と高品質な音声トラック(音声、 Foley 効果、環境音を含む)を生成する統合モデル。これにより、極めて高い計算効率で、最先端の品質を実現します。
根本的な問題点: 現在のテキストから動画への変換モデルは、視覚的に素晴らしい映像を生成するものの、音声がないという問題があります。一方、テキストから音声への変換モデルは、特定の分野(音声、音楽、または効果音など)に特化しています。非同期のパイプラインを利用した音響・映像生成の試みは、全体的な同時分布をモデル化できておらず、唇の動きの同期や環境音といった重要な要素を見落としています。
最近のテキストから動画(T2V)の拡散モデル、例えばLTX-Video、WAN 2.1、およびHunyuan Videoは、テキストの指示に基づいて、視覚的にリアルで動きに一貫性のある動画を生成するという点で、目覚ましい進歩を遂げています。しかし、これらのモデルは依然として基本的な制約があり、同期された音声によって伝えられる意味、感情、および環境に関する情報を省略しています。
並行して、テキストから音声への生成技術は、タスク固有のシステムから、より汎用的な表現へと進化してきましたが、それでも多くのモデルは特定の分野に特化しており、音声生成に対する統一的なアプローチを提供しているとは言えません。
一貫性のあるオーディオビジュアル体験を実現するには、統合モデルが必要であり、それがビジョンとサウンドの間の生成的な依存関係を同時に捉える必要があります。 Veo 3 や Sora 2 などのプロプライエタリなシステムは、この方向性を探求していますが、それらはクローズドソースです。 LTX-2 は、統合アーキテクチャを用いてこの課題に対処する、最初のオープンソースモデルです。
Transformerベースのバックボーンで、140億パラメータのビデオストリームと50億パラメータのオーディオストリームを備えており、これらは双方向のクロスアテンションと時間軸RoPEによって接続されています。この非対称な設計により、計算リソースを各モダリティの複雑さに合わせて効率的に割り当てることができます。
Gemma3 12Bを使用した、多層特徴抽出と学習された「思考トークン」を備えた、高度なテキスト条件付けモジュール。これにより、生成される音声のプロンプト理解と音響的正確性が向上します。
効率的な因果関係に基づいたオーディオ VAE で、高忠実度の 1次元潜在空間 を生成し、拡散モデルを用いた学習に最適化されています。これにより、最大 20秒 の連続的なステレオオーディオを生成できます。
革新的な双方向CFG方式であり、テキストとクロスモーダルガイダンスの独立したスケールを使用することで、音声と映像の整合性を大幅に向上させ、同期に対するきめ細やかな制御を可能にします。
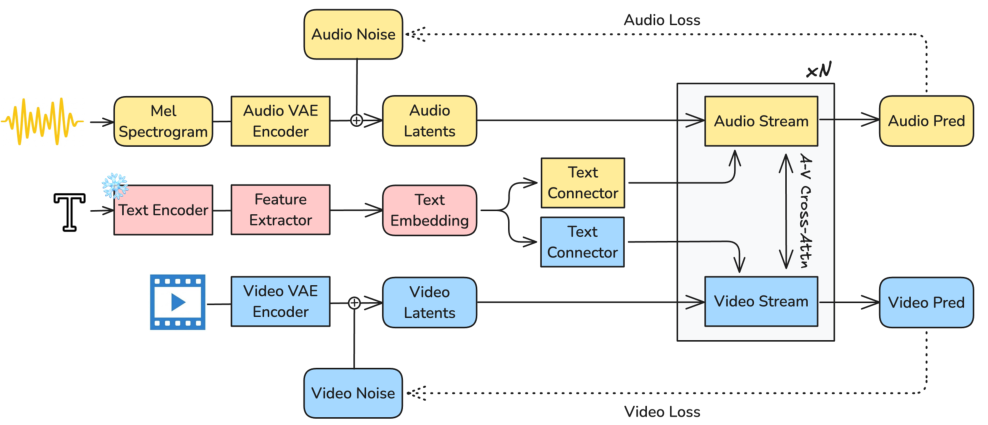
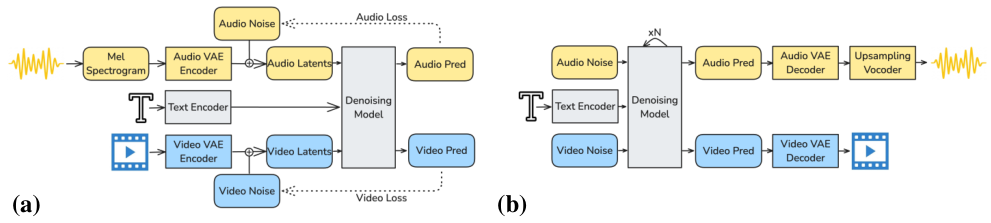
ビデオとオーディオを共有の潜在空間に無理やり統合するのではなく、LTX-2はそれぞれモダリティに特化したVAEを使用します。ビデオは、空間時間因果VAEを使用し、オーディオは、メルスペクトログラムベースの1次元の潜在空間を持つ因果VAEを使用します。これにより、各エンコーダを独立して最適化できます。
動画と音声は、根本的に異なる情報密度を持っています。14Bパラメータのビデオストリームは、複雑な空間的および時間的な視覚コンテンツを処理し、一方、5Bパラメータのオーディオストリームは、より低次元のオーディオデータを処理します。両者は同じアーキテクチャの設計に基づいていますが、幅と深さにおいて異なります。
モデル全体に配置された双方向クロスアテンションレイヤーにより、厳密な時間的整合が実現されます。クロスモーダルな相互作用において、1D temporal RoPEを活用することで、モデルは、リップシンクや環境音といった依存関係を捉えながら、単一モーダルの生成品質を低下させることなく、これを実現します。
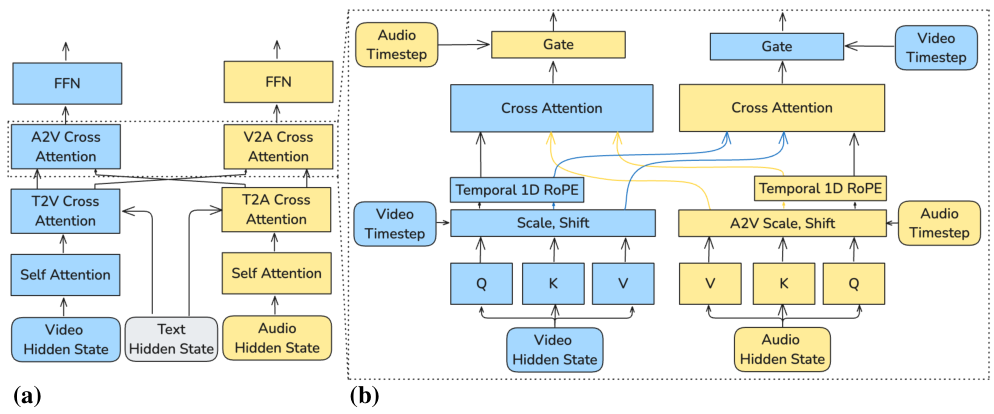
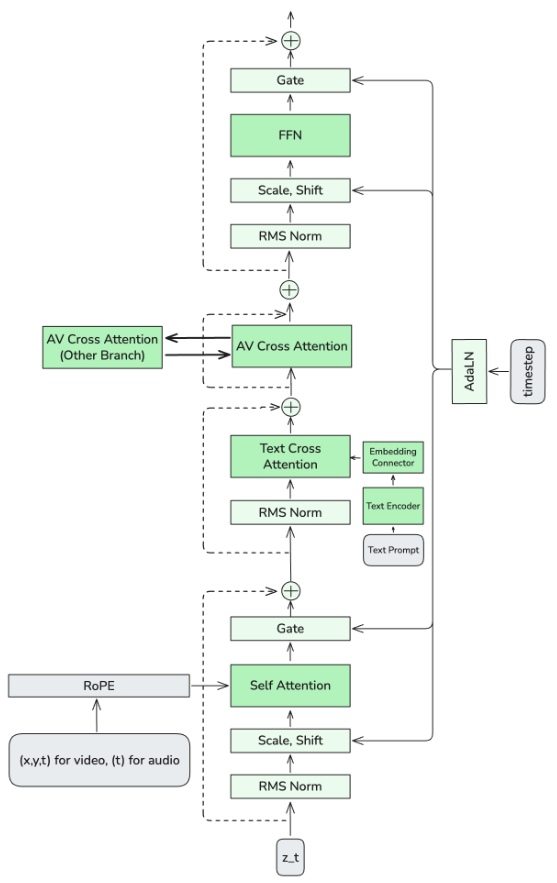
LTX-2の中核となるのは、非対称なデュアルストリーム拡散トランスフォーマーです。その基盤は、140億パラメータを持つ高容量のビデオストリームと、50億パラメータのオーディオストリームで構成されています。両方のストリームは同じアーキテクチャ設計を採用しており、各ブロックは、Self Attention、Text Cross-Attention、Audio-Visual Cross-Attention、およびFeed-Forward Network (FFN)で構成されています。活性化を安定させるために、RMS正規化層が演算の間に挿入されています。
このモデルは、構造をエンコードするためにRotary Positional Embeddings (RoPE)を使用します。ビデオストリームでは、3D RoPEが、空間次元(x、y)と時間(t)にわたって位置情報を注入します。オーディオストリームでは、1D RoPEは、時間次元のみをエンコードします。クロスモーダルアテンション中には、RoPEの時間コンポーネントのみが使用され、これにより、クロスモーダルアテンションは、空間的な対応関係ではなく、時間的な同期に焦点を当てるように強制されます。
ここで重要なのは、どのような情報がいつ重要になるか、ということです。
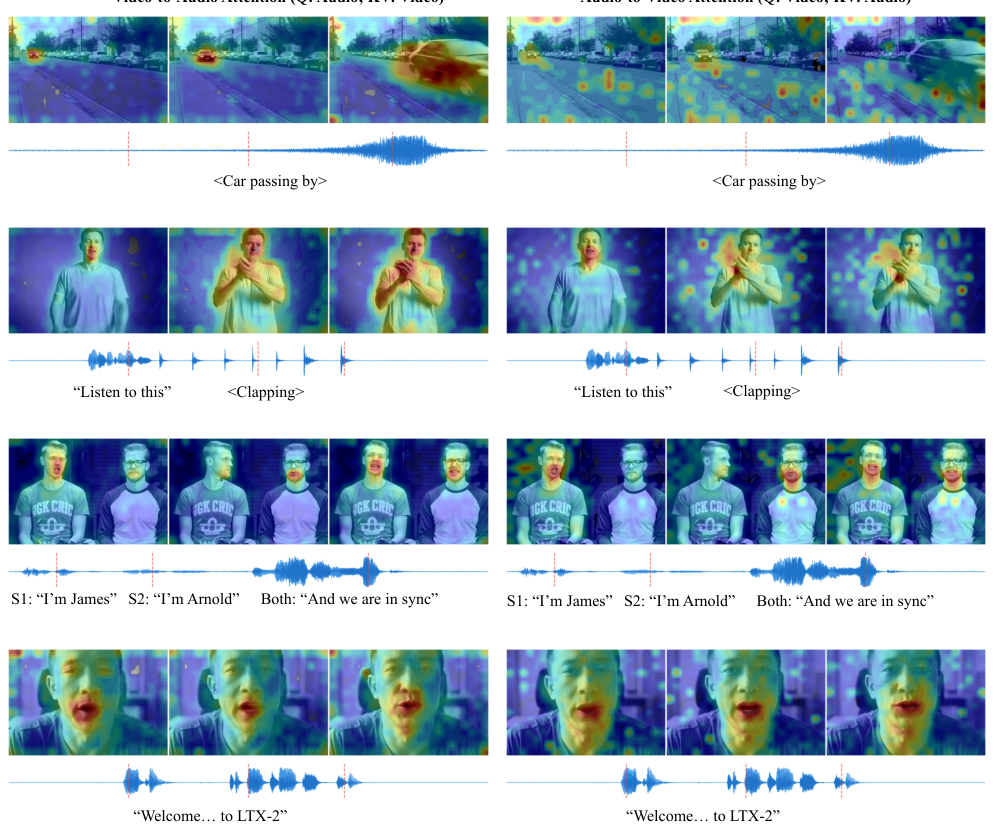
各層において、音声視覚クロスアテンションモジュールは、ストリーム間で双方向の情報伝達を可能にします。可視化の結果から、モデルが音声イベントとそれに対応する視覚的な要素を正しく関連付けていることが示されています。具体的には、車のエンジン音は車両に集中し、音声波形は唇の動きと一致し、拍手のタイミングは手拍子と一致しています。
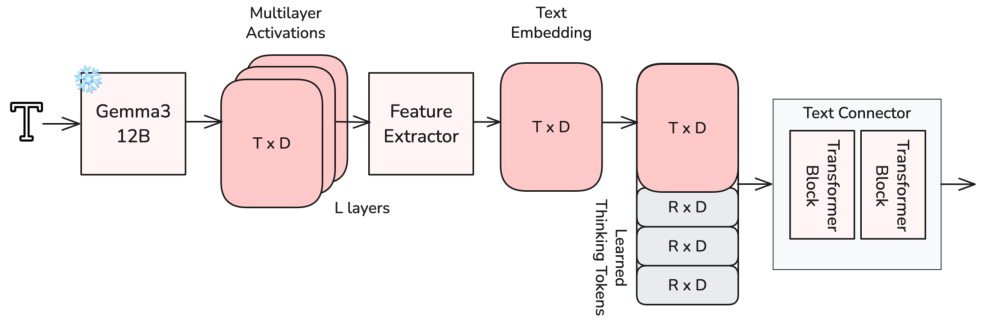
LLMの最終的な因果関係層に依存するのではなく、LTX-2はすべてのデコーダ層にわたって特徴を抽出します。中間表現は、初期の層における低レベルの音声学から、後期の層における高レベルの語義まで、より広範な言語学的特徴を捉えます。この抽出プロセスは、3つのステップで構成されます。
投影行列 W は、LTX-2 モデルと共に、標準的な拡散 MSE 損失関数を用いた短い初期トレーニング段階で最適化されました。これにより、モデルのプロンプトへの適合性と、全体的な生成品質が向上しました。
「register tokens」に触発されたLTX-2は、テキスト埋め込みに付加されるlearned thinking tokens(プロンプトごとにR個)を導入しています。これらのトークンと元の埋め込みは、2つのTransformerブロックで構成されるText Connectorモジュールを通して同時に処理されます。これにより、拡散Transformerに条件付けを行う前に、より豊かなトークン間の相互作用とコンテキストの混合が可能になり、生成品質が大幅に向上します。
数学の問題を解いているとき、最終的な答えを出す前に「下書き」を書くことを想像してみてください。“Thinking tokens” はこれと似たような仕組みで動作します。これらは、モデルが情報を「思考」し、生成を行う前に、情報を組み合わせるための追加の学習可能なパラメータです。
具体的には、R 個の追加トークン(初期値は学習済み)がテキストの埋め込みベクトルに付加され、トランスフォーマーブロックを通してまとめて処理されます。これらのトークンは、入力テキストに対応するものではなく、代わりに、モデルがテキスト表現を組み合わせ、洗練させるための計算領域として機能します。この概念は、ビジョン トランスフォーマーで使用されている register tokens からインスピレーションを得ています。
LTX-Videoの効率的な深層潜在空間に着想を得て、LTX-2はコンパクトな因果的オーディオVAEを採用しています。これはメロスペクトログラムの入力を処理し、それらを1次元の潜在トークンにエンコードします。このコンパクトな表現により、効率的な拡散ベースの学習が可能になりながら、高忠実度のオーディオ再構成品質を維持します。
最終的な波形は、HiFi-GANアーキテクチャをベースとしたボコーダーを使用して再構成されます。このボコーダーは、ステレオ合成とアップサンプリングを共同で行うように改良されています。これにより、デコードされたメルスペクトログラムが直接、高品質なステレオ波形に変換されます。
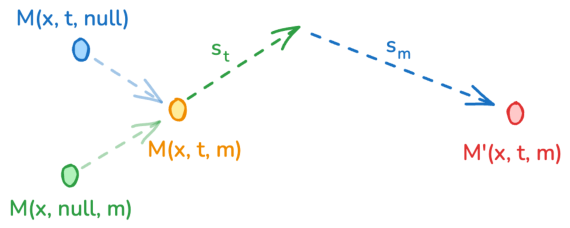
推論時、LTX-2は、テキストプロンプトに対する高い忠実性を維持しながら、クロスモーダルの一貫性と同期を高めるために、Classifier-free Guidance (CFG)のマルチモーダル拡張を利用します。
$$M'(x,t,m) = M(x,t,m) + s_t \cdot \bigl(M(x,t,m) - M(x,\varnothing,m)\bigr) + s_m \cdot \bigl(M(x,t,m) - M(x,t,\varnothing)\bigr)$$
st はテキストによる誘導の強さを制御し、sm はクロスモーダル誘導の強さを制御します。sm を大きくすると、モダリティ間の相互情報量の改善が促進され、より強力なクロスモーダル誘導により、より正確な口の動きの同期 と、より一貫性のある効果音の配置が可能になります。
Classifier-Free Guidance (CFG) は、生成品質を向上させるために広く使用されている技術です。基本的なアイデアは、推論時にモデルが2つの予測を行うことです。1つはテキストプロンプトに基づいており、もう1つは条件なしの予測です。この2つの予測の差を増幅させることで、出力がプロンプトで記述されている内容により近づきます。
LTX-2は、これに加えて2つの異なるガイダンススケールを導入しています。
この分離により、「私の記述にどの程度合致しているか?」と「音声と映像はどの程度同期しているか?」を個別に調整できます。これは、単一スケールのCFGと比較して大きな利点です。
推論は、より低い解像度から開始され、約0.5メガピクセルの基本潜在表現を生成します。これにより、全体的な構造、動き、および音声コンテンツを、処理負荷を抑えた状態で捉えることができます。
専用の潜在空間アップスケーラーは、動画の潜在空間の空間解像度を向上させながら、時間的な一貫性と音声の同期を維持します。
アップスケールされた潜在表現は、重なる空間的および時間的なタイルに分割されます。各タイルは個別に最適化され、最終的な出力で1080pの画質を実現します。
LTX-2は、LTX-Videoデータセットのサブセットを使用しており、重要で有益な音声を含むビデオクリップのみが選択されています。このデータセットでは、音声が意味的に重要である— つまり、単なる背景ノイズではなく、音声、環境音、および音楽要素が含まれる— ビデオに焦点を当てています。
新しいビデオ字幕システムが開発されました。このシステムは、視覚的なコンテンツと音声コンテンツの両方を説明するものです。字幕は、詳細かつ客観的であり、見たものと聞こえたものを記述するだけで、感情的な解釈は含まれていません。
LTX-2は、以下の3つの重要な側面から評価されます。それは、人間の主観評価によるオーディオビジュアル品質、標準的なベンチマークによる映像のみの性能、そして計算効率です。
人間の嗜好性に関する研究では、LTX-2 が オープンソースの代替手段(例えば、Ovi)と比較して、顕著に優れた性能を示すことが示されています。さらに、LTX-2 は、その計算コストと推論時間のほんの一部で、プロプライエタリなモデルと同等の嗜好性を実現しています。
LTX-2は、マルチモーダルモデルであるにもかかわらず、その視覚ストリームは、標準的なビデオ生成タスクにおいてトップレベルのパフォーマンスを維持しています。Artificial Analysisの公開ランキングでは、LTX-2は優れた結果を示しており、音声を追加することによってビデオの品質が低下しないことを示しています。
LTX-2アーキテクチャの主な利点は、その極めて高い効率です。H100 GPU上で、Wan 2.2-14B(ビデオのみ、140億パラメータ)と比較した場合:
| Model | Modality | Params | Sec/Step |
|---|---|---|---|
| Wan 2.2-14B | Video Only | 14B | 22.30s |
| LTX-2 | Audio + Video | 19B | 1.22s |
パラメータ数が多く(19B vs 14B)、「音声と動画を同時に生成する」にもかかわらず、LTX-2は、1回の拡散ステップあたりで、およそ18倍高速です。この速度の優位性は、最適化された潜在空間メカニズムによるものです。
LTX-2は、同期されたステレオ音声付きで、最大20秒の連続したビデオを生成できます。これは、現在のほとんどのテキストからビデオへのモデル(T2Vモデル)の制限を超えるものです。
LTX-2は、以下の4つの主要な革新を通じて、LTX-Videoを拡張し、統合された視聴覚基盤モデルを実現します。具体的には、非対称なデュアルストリームトランスフォーマーアーキテクチャ、思考トークンを用いた高度なテキスト条件付けと、Gemma3 12Bからの多層特徴抽出、効率的な1次元潜在空間を持つコンパクトな因果音声VAE、そして、詳細な視聴覚制御を可能にする、モダリティを考慮したclassifier-free guidanceです。
実験結果によると、LTX-2はオープンソースのT2AV生成において、新たなベンチマークを確立しました。最高水準の高品質なオーディオビジュアルを提供しながら、同クラスで最も高速なモデルです。
すべてのモデルの重みとコードは、研究の促進とオーディオビジュアルコンテンツ制作の民主化のために、公開されています。
社会への影響
機会
テキストから音声と動画を生成する技術は、コンテンツクリエイター、教育者、およびアクセシビリティツールに役立ちます。LTX-2のようなモデルは、高品質な映像コンテンツの制作をより身近なものにし、個人や小規模チームでもプロレベルのメディア制作を可能にすることができます。
課題
現実的な合成メディアは、ディープフェイクや偽情報など、悪用される可能性を秘めています。責任ある利用のためには、透かしの挿入、コンテンツの出所追跡、およびAIによって生成されたコンテンツの明示的な開示といった対策が必要です。