AIエージェント
学術イラストレーション
PaperBanana: AI研究者向けの学術イラストレーションの自動化
北京大学 · Google Cloud AI Research
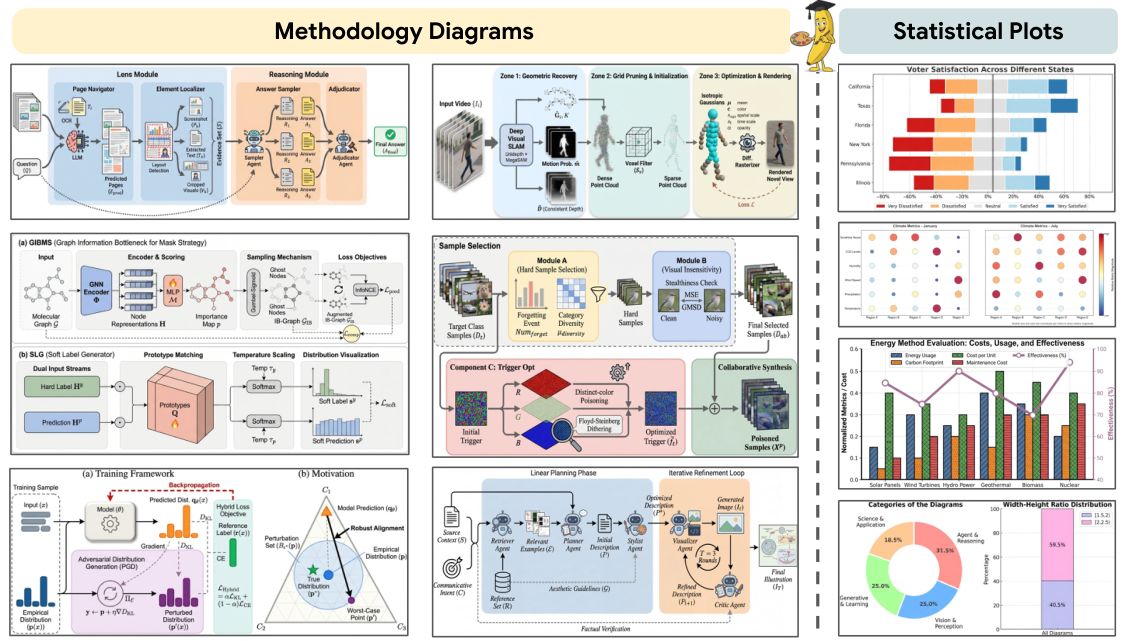
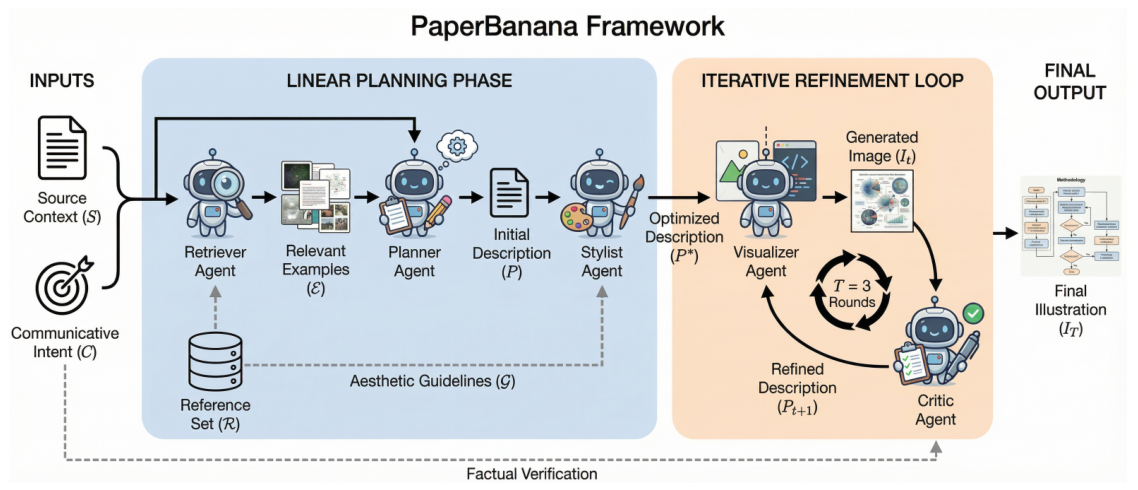
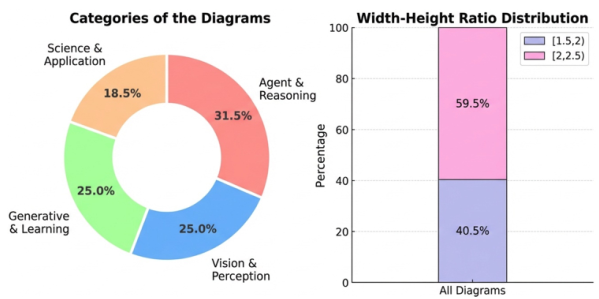
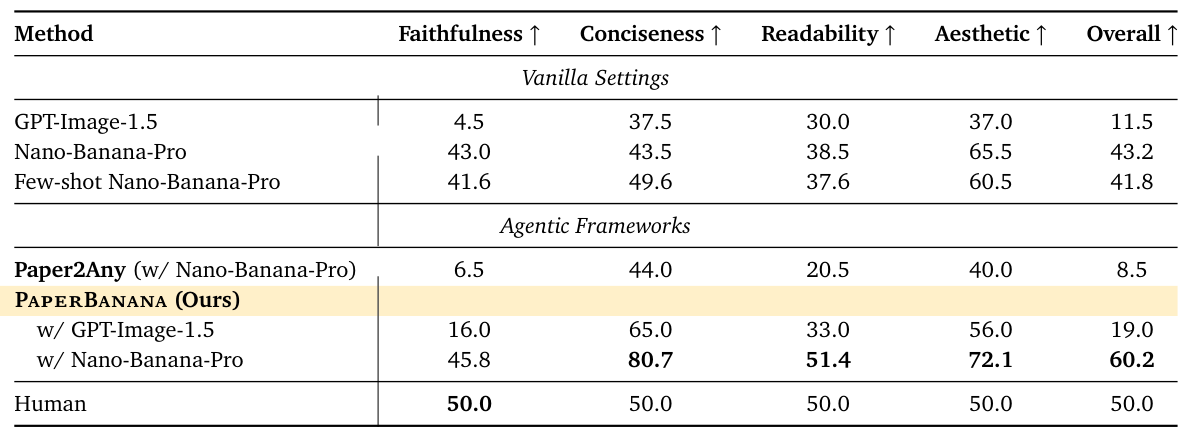
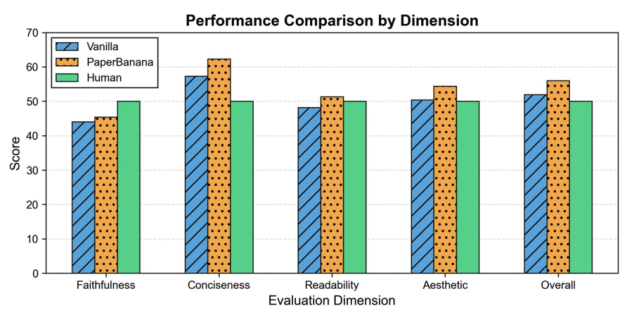
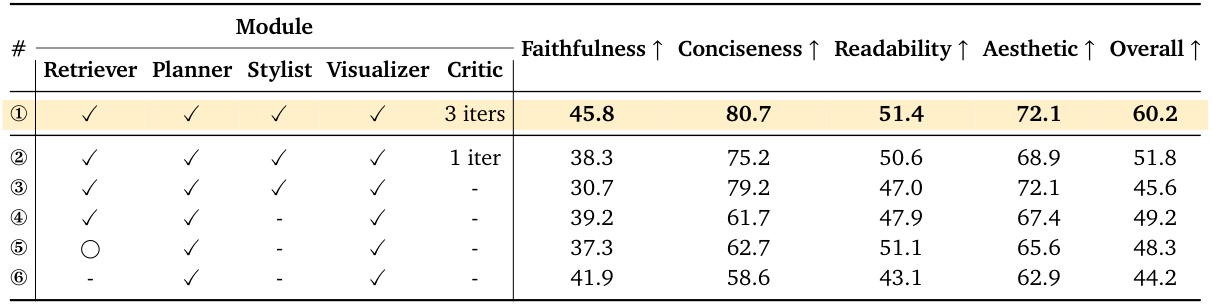
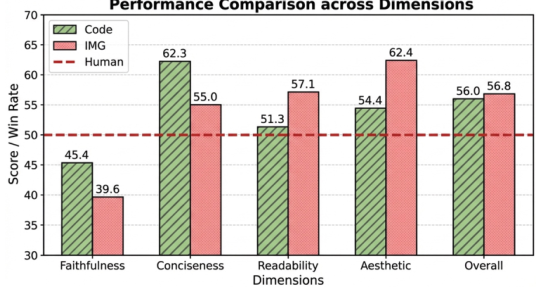
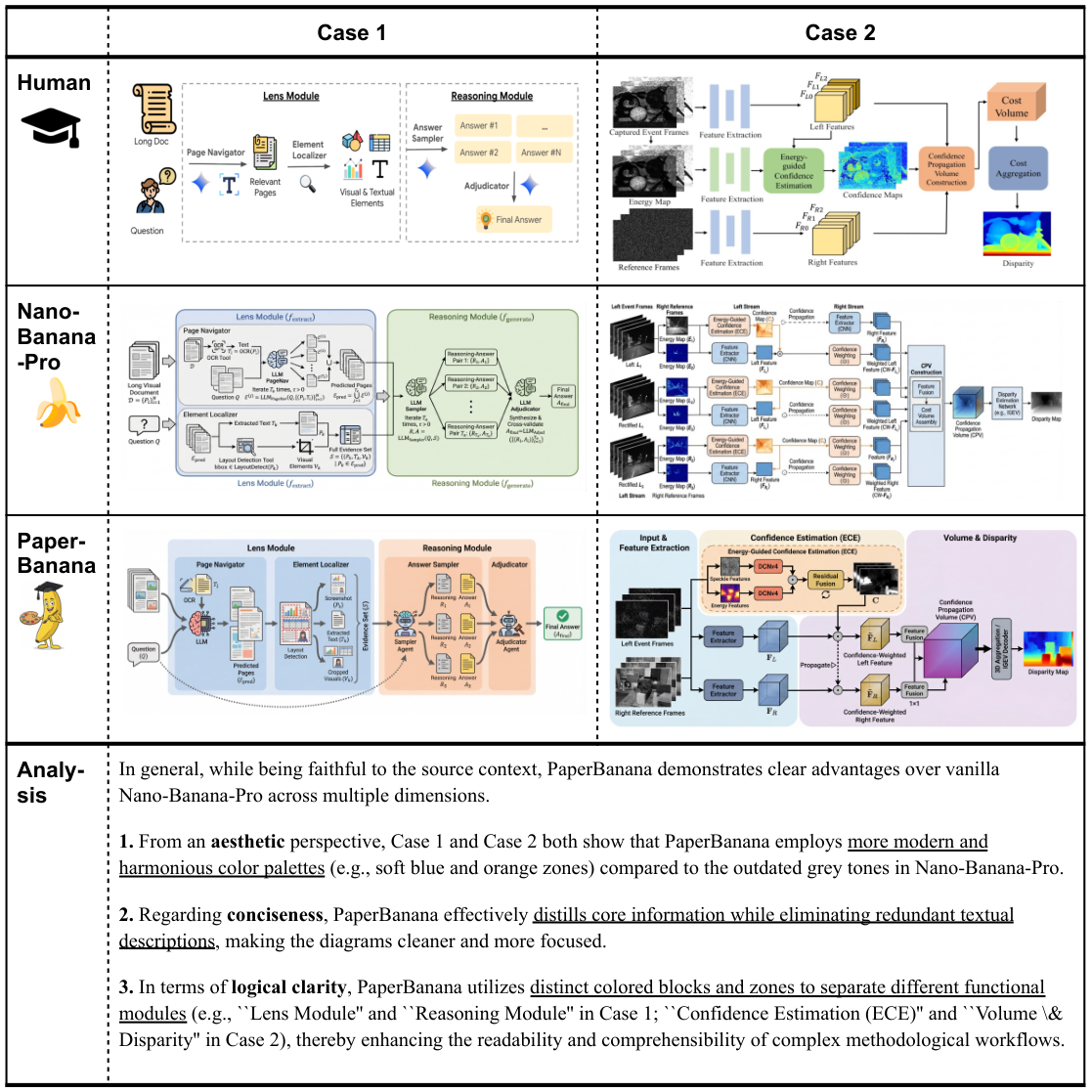
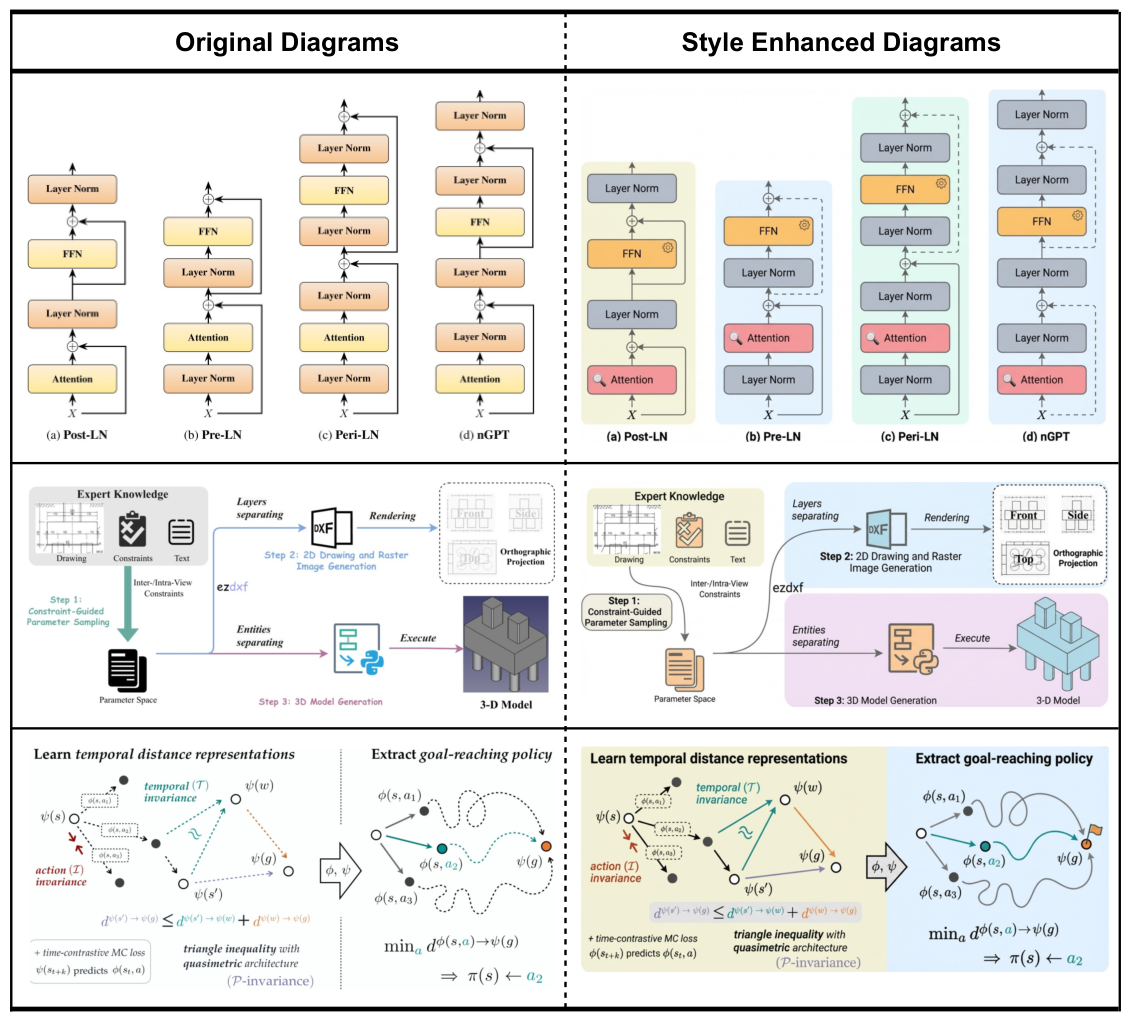
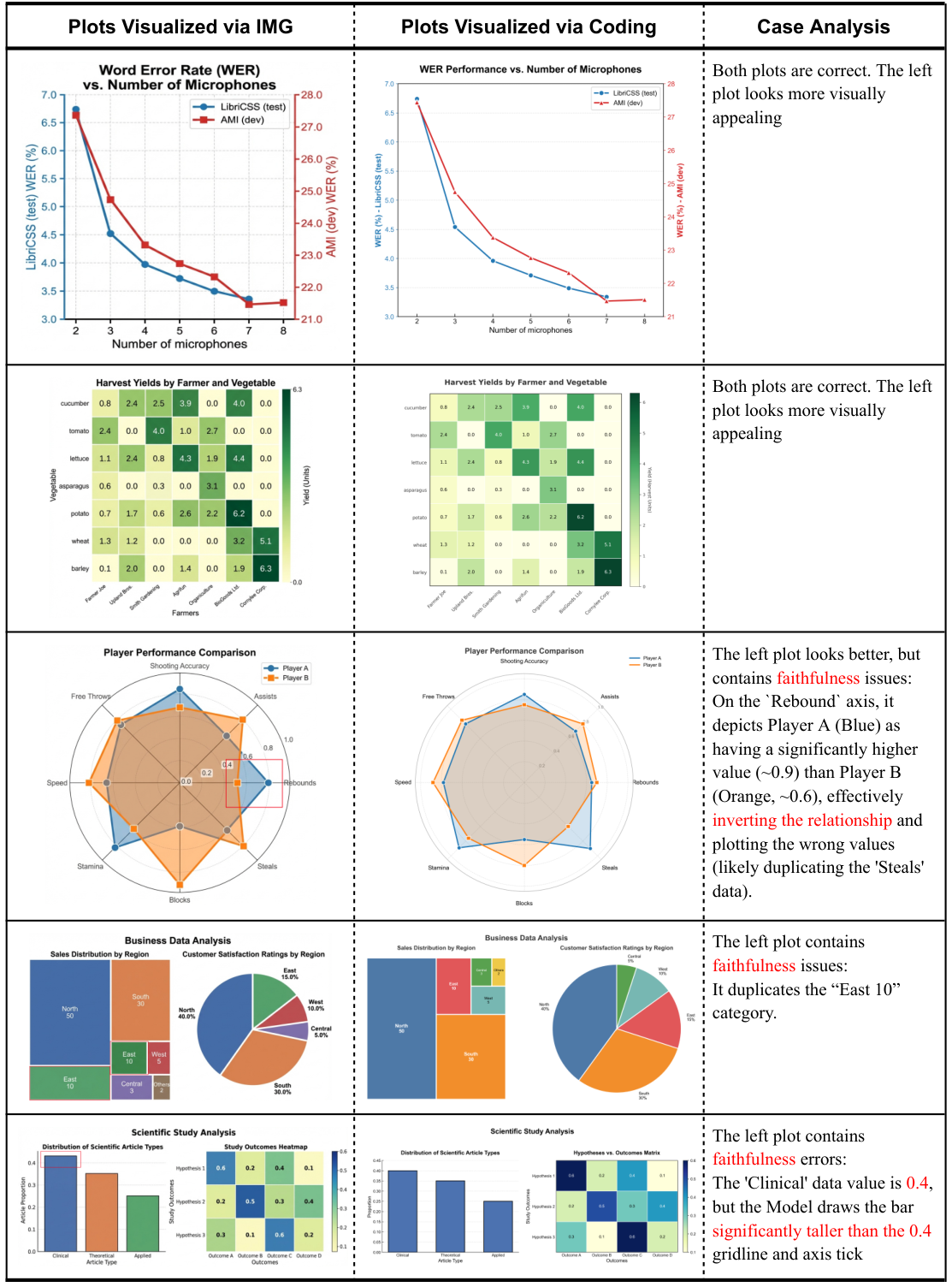
PaperBananaは、学術論文で利用可能な高品質なイラストを自動生成するエージェントベースのフレームワークです。Retriever、Planner、Stylist、Visualizer、そしてCriticという5つの専門的なエージェントを連携させることで、科学的なコンテンツを高品質な方法論図や統計グラフに変換します。また、PaperBananaBenchというベンチマークが付属しており、4つの側面における厳密な評価のための292件のテストケースを提供します。
+2.8%
忠実さ
+37.2%
簡潔さ
+12.9%
読みやすさ
+6.6%
美学