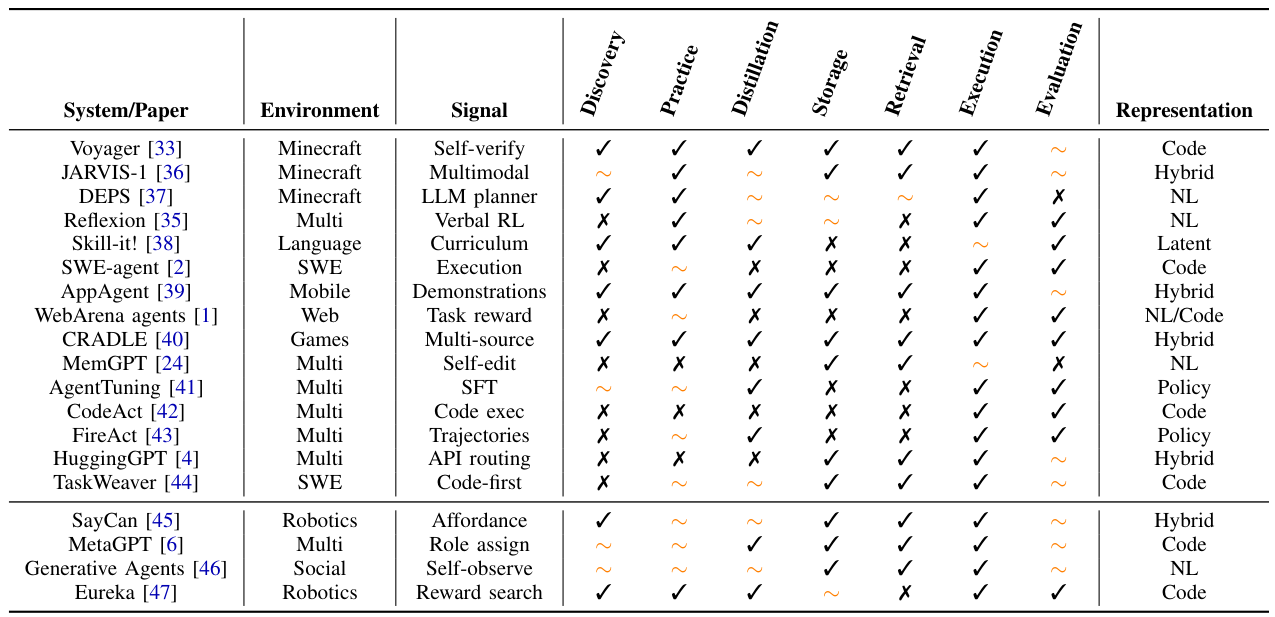
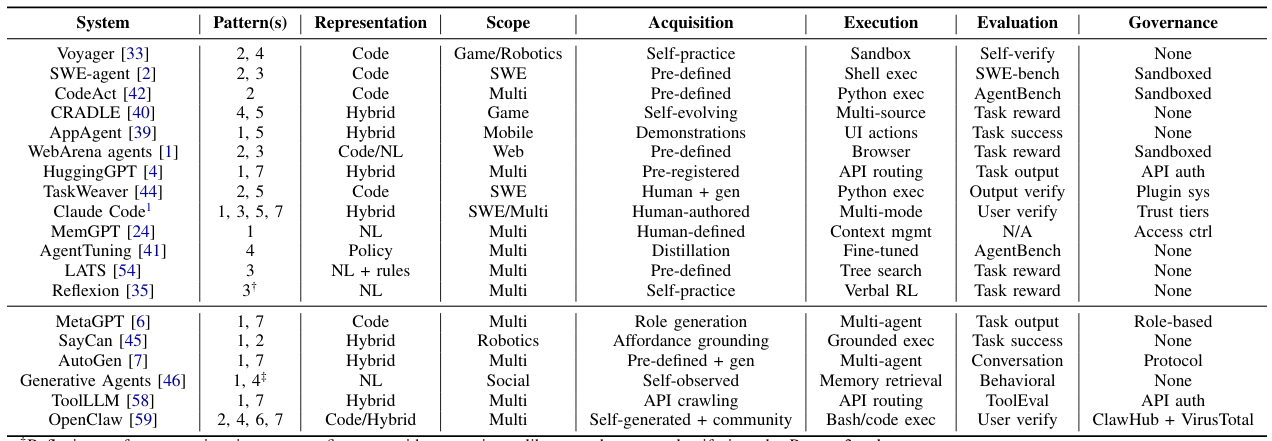
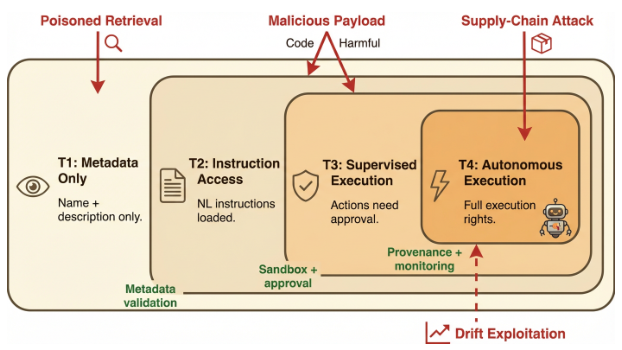
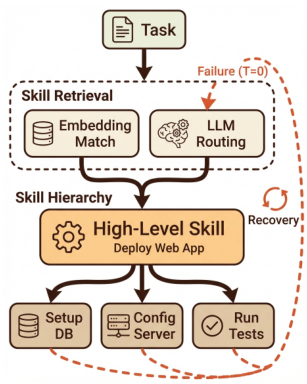
主体性スキルとは何ですか?
スキルとは、単なるツール呼び出しや指示以上のものです。それは、再利用可能で呼び出し可能なモジュールであり、一連の操作やポリシーをカプセル化し、エージェントが反復的な条件下で目標のクラスを達成することを可能にします。これには、独自の適用可能性ロジック、実行ポリシー、終了条件、および呼び出し可能なインターフェースが含まれます。
2.1 形式的な定義
エージェントのスキルは、それを関連する抽象化と区別する重要な特性を捉えた四重組として形式化されます。エージェントが、行動空間A、観測空間O、および目標空間Gを介して環境Eと相互作用するとします。
Definition 1 (Agentic Skills)
各コンポーネントは、スキルを同時に実行可能、再利用可能、かつ管理可能にするという、他の既存の抽象化では完全に提供できない3つの重要な特性を実現する上で、それぞれが独自の役割を果たします。
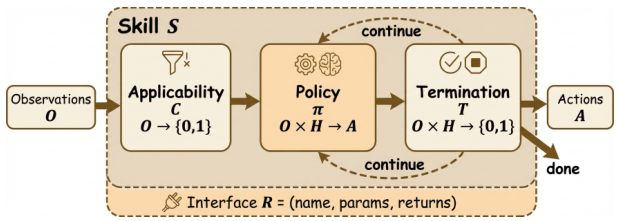
S = (C, π, T, R) の分解
この四重組が、本論文の中核となる主張です。スキルとは、単に呼び出し可能な関数ではなく、契約なのです。これは、サービスレベルアグリーメント(SLA)を持つマイクロサービスのようなものです。
- C (Condition: 条件) — このスキルは、どのような場合に呼び出すことができるのか? 例えば、「ウェブサイトのナビゲーションは可能ですが、認証が必要なページではできません」
- π (Policy: ポリシー) — どのように実行されるのか? これは実際の動作であり、コード、自然言語による指示、または学習されたポリシーです。
- T (Termination: 終了条件) — いつ終了するのか? 成功、失敗、またはタイムアウトの条件であり、単に「完了するまで実行」ではありません。
- R (Interface: インターフェース) — 他のスキルやエージェントは、何を見るのか? 入力、出力、副作用—APIの境界です。
T と C がないと、単に「スキル」は関数呼び出しにすぎません。この契約こそが、異なるコンテキストで再利用可能で安全にするものです。
適用条件
この機能は、観察結果と目標を{0,1}に照らして評価し、このスキルが現在の状況に適しているかどうかを判断します。これは、スキルが有効になるための条件を満たすかどうかを判定する「ゲート関数」として機能します。スキルの「いつ使うべきか」という知識を司るものです。
実行可能なポリシー
観察データや履歴をアクションに変換すること:これがスキルの基本的な仕組みです。これは、プロンプトテンプレート、Python関数、強化学習のポリシー、またはそれらの組み合わせとして実装できます。πが、原始的なアクションの代わりに、ライブラリΣから別のスキルを選択する場合、階層的な構成が生まれます。
終了条件
スキルが完了したかどうか(成功したか、またはそうでないか)を、現在の目標との関係において指定します。これが、モジュール化を可能にするものです。呼び出し元は、正確にいつ制御が自分たちに戻ってくるかを知ることができます。T がない場合、スキルを安全に連携させることはできません。
呼び出し可能なインターフェース
この機能は、スキルのプログラミング上の境界を定義します。具体的には、名前、パラメータのスキーマ、および戻り値の型を規定します。これにより、エージェント、他のスキル、および外部のオーケストレーターが、このスキルを確実に呼び出すことができます。`R` なしでは、内部の知識をプログラム的に利用できません。
2.2 スキルと関連する抽象化
主体的なスキルは、デザインの領域において独特な位置を占めています。これらは単なるツール、計画、または記憶ではありません。以下の表は、これらのスキルを5つの主要な側面から比較しています。

vs. ツール
ツールとは、固定されたインターフェースを持ち、内部的な判断を行わない、基本的な機能(例:ウェブ検索API)のことです。スキルはツールを呼び出すことができますが、適用可能性のロジック、複数ステップのシーケンス、および明示的な終了条件によって、それらを拡張します。この区別は、システムコールとライブラリルーチンの違いに似ています。
vs. 計画
プランは、タスクをサブゴールに分解する、一度きりの思考成果物です。プランはセッションの範囲内で有効であり、追加の解釈なしに直接実行することはできません。スキルはセッション間で保持され、実行可能なポリシーを含み、呼び出し可能なインターフェースを提供します。
vs. 記憶
エピソード記憶と意味記憶は、観察や事実を保存します。スキルは手続き記憶であり、それがどのように行動するかをコード化するものであり、何が起こったかをコード化するものではありません。これは、認知心理学における「知っていること(宣言的)」と「知っている方法(手続き的)」の区別を反映しています。
vs. プロンプトテンプレート
プロンプトテンプレートは、適用条件や終了ロジックなしで、コンテキストウィンドウに挿入されるテキストの断片です。これらは、自動的に選択したり、階層的に構成したり、独立して制御したりすることはできません。スキルは、プロンプトエンジニアリングにおける最適なパターンを包括し、形式化します。