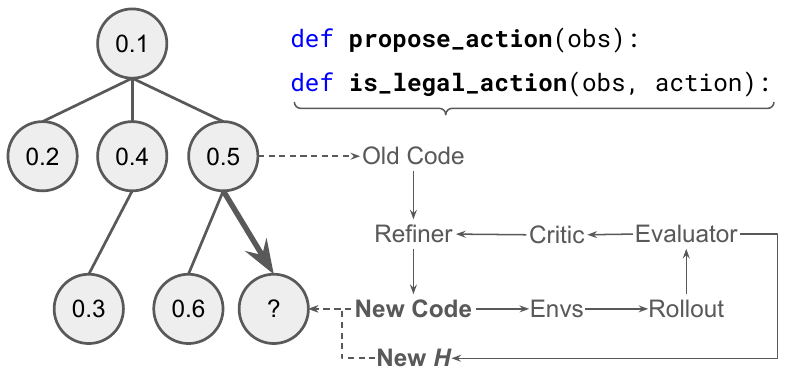
AutoHarnessの仕組み
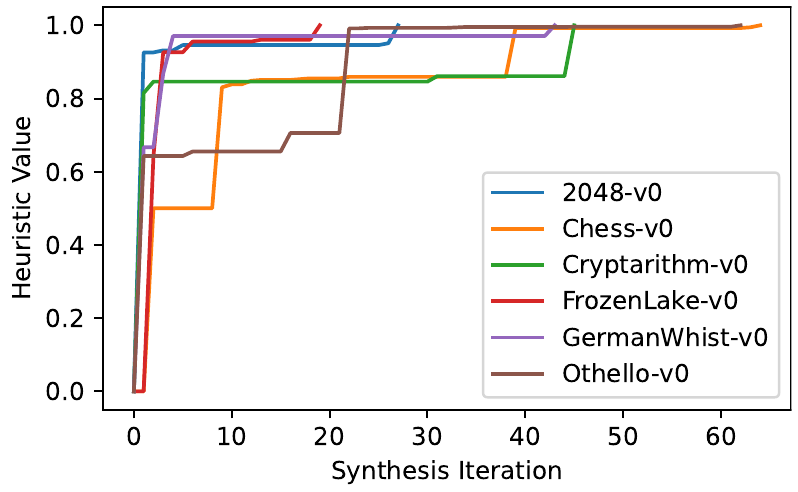
AutoHarnessは、複数のコード仮説をツリー構造で保持し、Thompson samplingを用いて、次にどのノードを改善するかを選択します。各ノードのヒューリスティック値は、そのコードバージョンが達成した平均的な合法的な移動の精度です。コードにバグがある場合(is_legal_action()がTrueを返すにもかかわらず、実際にはその移動が合法でない場合)、propose_action()とis_legal_action()の両方が改善されます。一方、is_legal_action()がFalseを返す場合(合法でない移動を正しく検出した場合)、propose_action()のみが修正されます。
二つの機能の分離:なぜ
•
•
この非対称な修正により、すでに正しいコードを「修正」することを避け、後続の反復での不要な変更を減らすことができます。
propose と is_legal を分離するのか?propose_action(obs)— 生成: 候補となる手を生成します。これは、合法的な盤面をすべて列挙するような単純なものから、ヒューリスティックなポリシーのような複雑なものまで様々です。is_legal_action(obs, action)— 検証: 手がゲームのルールで許可されている場合にのみTrueを返します。
•
is_legal_action が実際には不正な手に対して True を返す場合(誤検知)、チェッカーはルールを知らないため、両方の関数が間違っている可能性が高いため、両方を修正します。•
is_legal_action が正しく False を返す場合、不正な手を生成したのはプロポージャーのみであるため、propose_action のみを修正します。この非対称な修正により、すでに正しいコードを「修正」することを避け、後続の反復での不要な変更を減らすことができます。
AutoHarnessは、軽量なアクションフィルタリングから完全なコードのみのポリシーまで、3つの動作モードをサポートしています。
3つのモード: 「安全網」から「完全自律」までのスペクトル
AutoHarnessの3つの動作モードは、学習されたハーネスのテスト時において、LLMがどの程度関与するかという点で異なります。
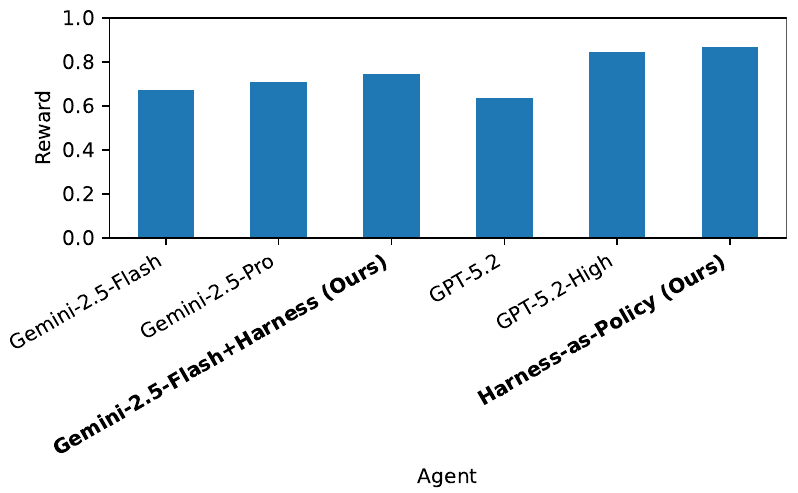
重要な違いは推論コストです。アクションバリファイアは、1ターンあたりにLLMを複数回呼び出す可能性がありますが、ハーネスをポリシーとして使用する場合、ゲーム中にLLMを呼び出すことはありません。「ほぼゼロの推論コスト」という見出しは、ポリシーモードにのみ当てはまります。
AutoHarnessの3つの動作モードは、学習されたハーネスのテスト時において、LLMがどの程度関与するかという点で異なります。
| モード | テスト時にLLMを使用? | ハーネスの役割 |
|---|---|---|
| アクションフィルター | はい — 許可されたセットから選択 | 許可された動作のみを列挙 |
| アクションバリファイア | はい — 提案し、再試行 | 提案された各動作を検証 |
| ポリシー | いいえ | 直接、アクションを出力 |
重要な違いは推論コストです。アクションバリファイアは、1ターンあたりにLLMを複数回呼び出す可能性がありますが、ハーネスをポリシーとして使用する場合、ゲーム中にLLMを呼び出すことはありません。「ほぼゼロの推論コスト」という見出しは、ポリシーモードにのみ当てはまります。
Harness-as-Action-Filter
propose_action()は、合法な手のセットを生成します。LLMはその後、連鎖思考推論を用いて最適な手をランク付けして選択します。
Harness-as-Action-Verifier (メインメソッド)
LLMが手を提案します。is_legal_action()がその手の合法性を検証します。無効な場合、LLMは「不正な手」という警告メッセージとともに再プロンプトされます。これが本論文で評価する主要なアプローチです。
Harness-as-Policy
最も極端なケースでは、コードが直接的に次のアクションを選択します。テスト時にLLMへの呼び出しは不要です。純粋なPythonで、推論コストがほぼゼロで、最も高い平均パフォーマンスを実現します。