エージェントがなぜいつも同じようなことを繰り返してしまうのか。
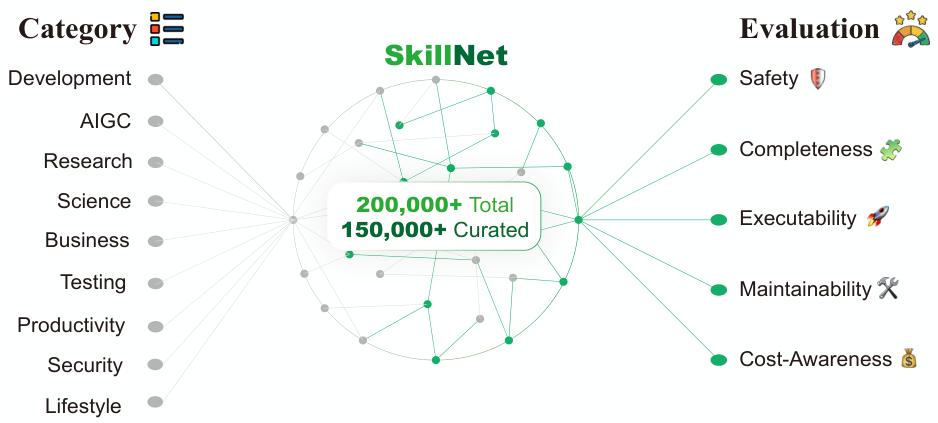
今日のAIエージェントは、様々なツールを使いこなし、複雑なタスクをこなすことができますが、その長期的な成長は、AIが発見した能力を蓄積し、転送するための統一的な方法の欠如によって制限されています。 スキル統合の仕組みがないため、エージェントは常に同じ解決策を個別に再発見します。SkillNetは、AIスキルを大規模に作成、評価、整理するためのオープンなインフラストラクチャです。これは、3層構造のスキルオントロジー(分類体系、関係グラフ、およびパッケージライブラリ)を導入し、実行パス、オープンソースリポジトリ、およびドキュメントからの断片化された経験を、20万件以上の候補スキルからなる構造化されたネットワークに変換し、そのうち15万件以上が高品質なエントリとしてキュレーションされています。各スキルは、安全性、完全性、実行可能性、保守性、およびコスト意識という5つの次元で評価されます。3つのベンチマーク(ALFWorld、WebShop、およびScienceWorld)において、SkillNetによって強化されたエージェントは、DeepSeek V3.2、Gemini 2.5 Pro、およびo4 Miniにおいて、平均報酬を+40%向上させ、インタラクションステップ数を−30%削減しました。
なぜスキルなのか、なぜ今なのか。
Richard Sutton氏は、現在我々は「経験の時代」に突入していると主張しています。知性は、静的な知識の獲得よりも、過去の試行から得られたヒューリスティックを効率的に検索し、適応的に再利用することに重点が置かれています。この変化は、AIが静的な質問応答にとどまらず、長期的な実行可能なタスクを調整する「エージェント時代」の到来を意味します。
しかし、現在のシステムは、手作業による設計や、一時的な文脈学習に依存しています。人間は、日常的な経験を再利用可能なスキーマに体系化します。例えば、プログラマーはアルゴリズムのロジックを理解し、その構文を暗記するのではなく、そのロジックを内面化します。しかし、現代のAIは、一時的な文脈と持続的な能力との間のギャップを埋めるのに苦労しています。中心的な課題は、もはや経験からの学習ではなく、断片化された経験を、組み合わせ可能なスキルユニットに変換することです。
象徴主義時代
形式的な記号論理は解釈可能ではあったものの、柔軟性に欠け、拡張性に問題がありました。
ディープラーニングの時代.
知識はパラメータ化され、強力になったものの、同時に不透明になり、モジュール化や再利用が困難になった。
エージェント時代.
スキルは、知性を単一の大きなパラメータ空間から切り離す、単純で汎用性の高い能力単位として現れる。
統合されたスキルフレームワーク。
SkillNetは、断片化されたエージェントの経験を、リッチな関係モデルを備えた、モジュール化された、組み合わせ可能なスキル群で構成される構造化されたネットワークへと変換します。これにより、チームはスケーラブルな基盤上で、実践的な知識工学を実現できます。
厳密な5軸評価プロトコル。
すべてのスキルは、安全性、完全性、実行可能性、保守性、およびコスト意識という定量的な指標に基づいて評価されます。これにより、リポジトリが拡張しても信頼性を維持できるようになります。
オープンなエコシステム。
20万件以上の候補者データ、15万件以上の厳選されたスキルデータベース、Pythonツールキット(`
skillnet-ai`)、および、エージェントの計画と実行において大きな進歩を示すベンチマーク。
エージェントスキルとは何ですか?
`スキル (skill) とは、エージェントの機能を拡張するための、軽量で、モジュール化された、再利用可能な抽象化です。機能的には、スキルは、中央の `SKILL.md` ファイルがメタデータ(名前、簡単な説明、使用条件)、手順、およびオプションでバンドルされたコード、テンプレート、または参照アセットを定義する、構造化されたフォルダです。`
スキルは、エージェントがオンデマンドで再利用可能な手続き知識にアクセスできるようにします。これには、データ分析パイプラインの自動化、ドメイン推論の実行、または構造化されたレポートの生成などが含まれます。スキルは自己記述型であるため、各機能は簡単に監査および改良できます。スキルは、ビジネスロジックが組織化されるためのインターフェースとなります。
スキルを、Claude Code の「スキルフォルダ」として考えてください
Claude Code や同様のフレームワークを使用する場合、「エージェントスキル」は、すでにご存知のスキルフォルダと全く同じものです。それは、エージェントが いつ 実行すべきか(「Postgres のマイグレーションにこれを使用する」など)を指示する `SKILL.md` ファイルを含むディレクトリです。また、どのように 実行すべきか(「1. スキーマをダンプする 2. 差分を比較する 3. マイグレーションを実行する」)も記述されています。エージェントは、タスクが一致した場合にのみ、完全な指示をロードします。そのため、この論文では、スキルをモジュール単位として扱っています。なぜなら、実際には、スキルはプロジェクト間でコピー&ペーストできるからです。
発見.
エージェントは、タスクに関連する可能性のあるスキルを判断するために、最小限のメタデータ(名前と説明)を読み込みます。
起動。
タスクが特定のスキルの説明と一致した場合、エージェントは `SKILL.md` に記載されている詳細な指示を読み、関連するリソースを準備します。
実行
エージェントは、指示をステップごとに実行し、必要に応じて、同梱されているコードを実行したり、参照されているアセットを利用したりして、タスクを完了します。
SkillNet の概要
SkillNetは、エージェントシステム向けの高品質なスキルを体系的に構築し、評価し、整理します。その目的は、断片化されたエージェントの経験と人間の知識を、再利用可能で検証可能なスキルエンティティに変換することであり、これにより、スケーラブルで信頼性の高い能力の成長を可能にします。
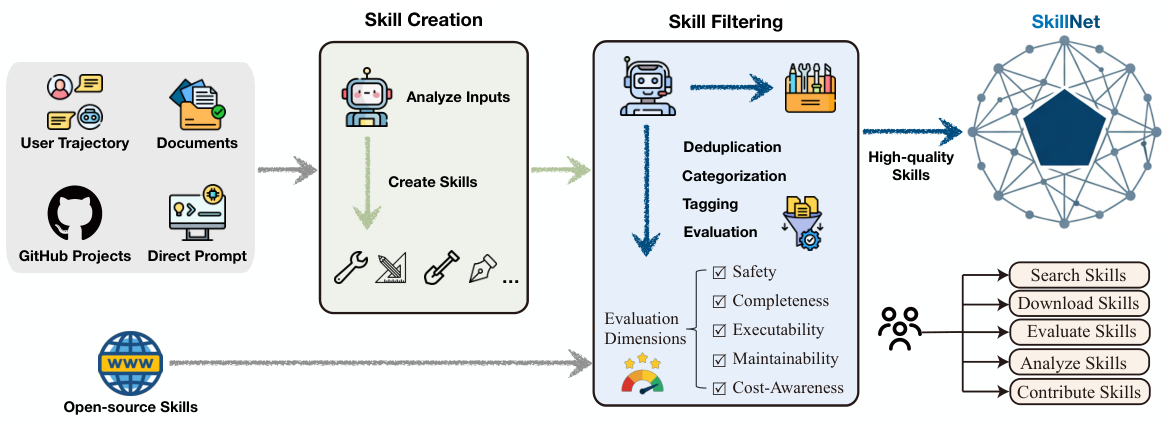
スキル作成
多様な入力データ—ユーザーの行動履歴、オフィス文書、GitHubプロジェクト、直接的な指示、そしてオープンなインターネット上のリソース—を分析し、実行可能なパターンを抽出し、それらを再利用可能な機能として構造化することで、新しいスキルを生成します。
スキル評価
候補者のスキルを、以下の5つの次元 — 安全性 (Safety), 網羅性 (Completeness), 実行可能性 (Executability), 保守性 (Maintainability), および コスト意識 (Cost-Awareness) — に沿って評価し、高品質なスキルのみをデータベースに登録します。
スキル分析
スキル間の構造的および機能的な関係を自動的に抽出し、大規模な型付きグラフを構築します。このグラフは、グローバルな推論と構成のために、類似性、階層構造、構成、および依存関係を捉えます。
オープンリソース
厳選されたリポジトリ、フロントエンドのウェブサイト、オープンなAPI、そして `skillnet-ai` というPythonツールキット。これらは、スキル管理、検索、評価、貢献のための、統合されたエコシステムを構成します。
スキルオントロジー (The Skill Ontology)
スキルオントロジーは、個々のスキルを構造化された、組み合わせ可能なネットワークに整理します。このアーキテクチャは、3つの段階的なレイヤーで構成されています。それは、タクソノミー、関係グラフ、そしてパッケージライブラリです。これらを組み合わせることで、単なるスキルの集合を、ナビゲート可能な知識構造へと変換します。
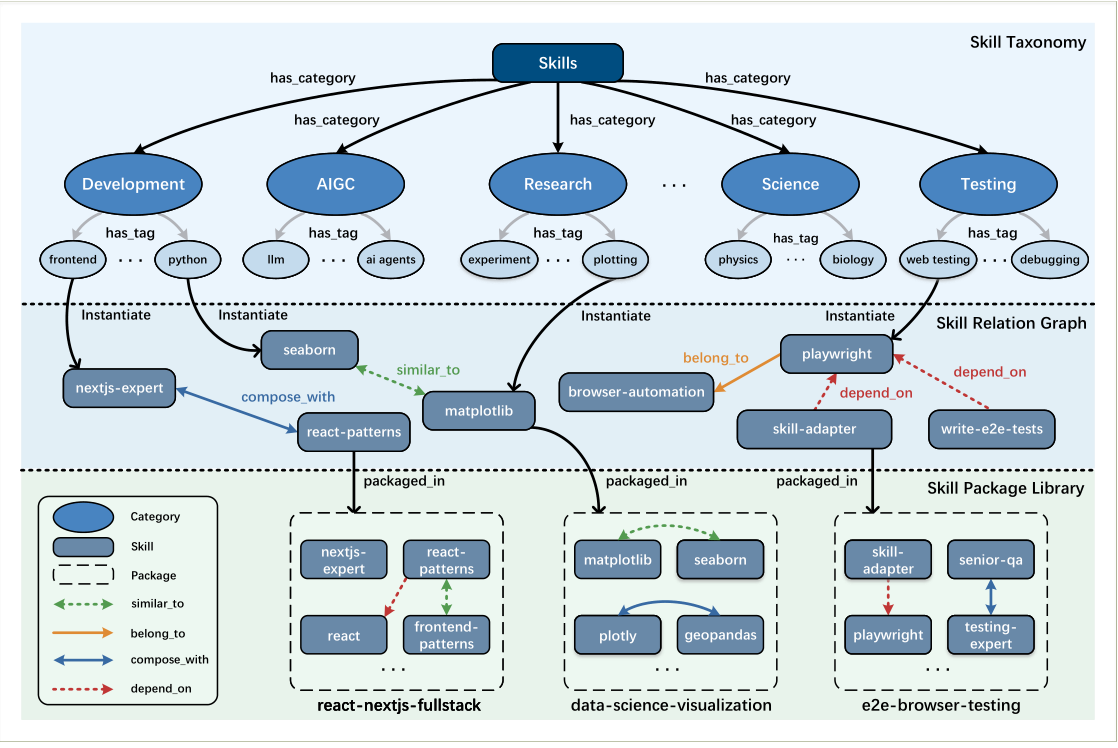
similar_to, belong_to, compose_with, depend_on)をモデル化します。スキルパッケージライブラリは、スキルをモジュール化されたパッケージにまとめます。例としては、data-science-visualizationやe2e-browser-testingなどがあります。スキル分類
カテゴリとタグの関係に基づいて構築された、多層階層構造です。広範な分野(Development, AIGC, Research, Science, Testing, …)を、より詳細なタグ(`frontend`, `llm`, `physics`)へと分類することで、高レベルのセマンティック構造を提供します。
スキル関係グラフ
抽象的なタグを具体的なスキルエンティティ(例:`matplotlib`, `playwright`)に変換し、それらを型付きのエッジで接続します。エッジの種類は、`similar_to`, `compose_with`, `belong_to`, `depend_on`などです。これは、推論と計画の基盤となります。
なぜ4つの関係エッジが重要なのか
15万件のスキルの単純なリストは検索できません。関係グラフこそが、リポジトリをエージェントが推論できるものへと変えるものです:
similar_to: エージェントが、最初のスキルが失敗した場合に、別のスキルに置き換えることを可能にします (冗長性)。compose_with: エージェントに、どのスキルが互いに連携するかを伝えます (自動パイプライン)。depend_on: 依存関係を明らかにし、エラーを未然に防ぎます。belong_to: 細かいスキルをまとめてより大きなワークフローとしてグループ化することで、全体像を把握した計画を立てることを可能にします。
具体的には、エージェントが「Next.jsのランディングページを作成する」と希望する場合、belong_toを通じてnextjs-expertからreact-patternsを発見し、depend_onでreactとの依存関係を確認し、必要に応じてfrontend-patternsに置き換えることができます。
スキルパッケージライブラリ
スキルの物理的な構成。個々のスキルは、`packaged_in`の関係を通じて「スキルパッケージ」にまとめられます(例:`react-nextjs-fullstack`、`data-science-visualization>)。これにより、モジュール化されたリリースとデプロイが可能になります。
新しいスキルがネットワークにどのように導入されるか.
SkillNetは、宣言的な知識と具体的な、実行可能なプログラムを結びつける中間的な能力単位としてスキルを扱います。自動化された作成パイプラインは、4種類の入力情報を標準化されたスキルに変換します。それらは、実行経路と会話ログ、オープンソースのGitHubリポジトリ、半構造化されたドキュメント(PDF、PowerPoint、Word)、そしてユーザーからの直接的な自然言語による指示です。
自動構築とは、無差別に情報を蓄積することを意味するものではありません。データに基づいたフィルタリングと統合のプロセスにより、各候補データは重複排除、検証、分類、スコアリングが行われ、最終的に選択されます。これにより、リポジトリは静的なコレクションではなく、自己進化するスキルエコシステムとして成長します。
- 重複排除 — スキルに関するMarkdownファイルのディレクトリ構造とMD5ハッシュを組み合わせて比較します。
- フィルタリング — ルールベースの検証とモデルベースのチェックを組み合わせることで、品質が低い、または意味的に空虚なスキルを排除します。
- 分類とタグ付け — 各スキルを10の機能カテゴリのいずれかに分類し、詳細なタグを付与します。
- 評価 — 安全性、完全性、実行可能性、保守性、コスト意識の観点から評価します。
- 選択的統合 — 以前のすべての段階を乗り越えたスキルのみを残します。
自己進化するスキルエコシステムであり、静的なコレクションではありません。
多次元スキル評価
スキル作成は重要ですが、リポジトリの有用性は最終的にその信頼性に依存します。SkillNetは、既存のリポジトリがほとんど標準化された評価を持っていないという問題を解決し、5つの軸による評価基準と、実行時の正確性を検証するためのサンドボックス環境を提供することで、そのギャップを埋めます。
安全
危険なシステム操作(例:許可されていないファイル削除)や、プロンプトインジェクションや敵対的な操作に対する堅牢性。
完全性
すべての重要な手順が網羅されているか、また、前提条件、依存関係、および実行制約が明確に記述されているか。
実行可能性
エージェントは、実際には、サンドボックス環境でこのスキルを実行でき、そこで、誤ったツール呼び出しや曖昧な指示が特定されます。
保守性
モジュール性および組み合わせやすさ:そのスキルは、グローバルな依存関係や後方互換性を損なうことなく、ローカルで更新できるか?
コスト意識
リアルタイムでのレイテンシ、計算リソース、およびAPI利用料金の状況を把握することで、本番環境における効率最適化を支援します。
実践者向け:5つの軸
スキルを、チームが提供するライブラリだと考えてください。これらの5つの軸は、コードレビューで既に利用している品質基準を反映しています。
- 安全性 ≈ 「危険な副作用はないか?」(例えば、確認なしにテーブルを削除する移行など)
- 完全性 ≈ 「READMEはすべての手順を説明しているか?」(前提条件 + 境界条件)
- 実行可能性 ≈ 「CI環境で問題なく実行されるか?」(実際のサンドボックスでの実行であり、単なるLLMの意見ではない)
- 保守性 ≈ 「依存関係に影響を与えずに派生させることができるか?」(モジュール性)
- コスト意識 ≈ 「p99のレイテンシとAPIの利用料金は?」(本番環境での運用性)
このアナロジーが重要な理由はその次の図にあります。自動評価システムは、博士号を持つ人間のレビュー担当者と、すべての軸において合致します。これは、エージェントのスキルに対する、実質的に自動化されたコードレビューシステムと言えます。
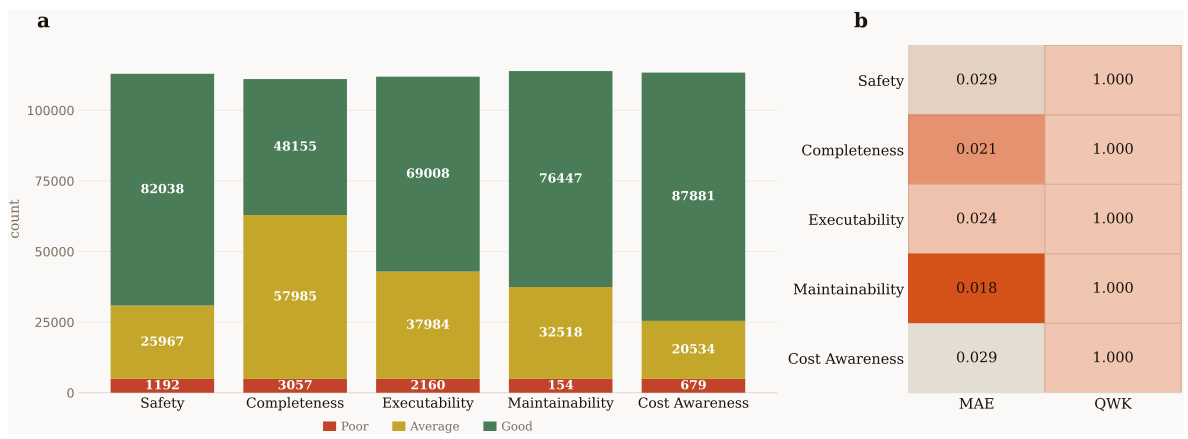
200件のランダムに抽出されたスキルについて、3名の博士号取得者によるコンピュータサイエンスの専門家が評価を行ったところ、LLM(大規模言語モデル)ベースの評価システムは、平均絶対誤差が0.03未満であり、すべての次元において、ほぼ完璧なQuadratic Weighted Kappa値(1.000)を達成しました。これは、SkillNetの自動品質ゲートが、大規模な運用においても信頼できるものであるという強力な証拠です。
スキル関係グラフの活用.
個々のスキル作成と評価に加えて、大規模なリポジトリは新たな課題を提示します。それは、スキルの間の関係を体系的に理解し、整理し、活用することです。SkillNetは、スキル分析を構造化された関係発見の問題として捉え、スキル間の4つの主要な関係タイプを自動的にアノテーションします。
similar_to
機能的に同等のスキル — 重複検出と置換を可能にします。
belong_to
あるスキルは、より大きなワークフローのサブコンポーネントであり、階層構造を表現します。
compose_with
2つのスキルが頻繁に組み合わせて使用されることがあり、その場合、片方のスキルがもう片方のスキルの出力結果を利用します。
depend_on
スキルを実行するには、前提条件(例:環境設定)が必要です。
グラフが実際にどのように構築されるか(手動でのラベル付けなし)
15万件のスキル間の関係を手動でラベル付けすることは不可能です。SkillNetの仕組みは、3段階のパイプラインです。(1) 埋め込み類似度 が、候補となる `similar_to` エッジを提案します。(2) コードと実行トレースの 静的解析 が、`depend_on` および `compose_with` エッジを提案します。(3) LLM推論エンジン が、候補をレビューし、エッジの種類をラベル付けします。これは、現代のナレッジグラフ構築で使用されている方法と同じで、Wikipediaのテキストではなく、実行可能なコードに適用されています。
SkillNetは、ハイブリッドパイプラインを通じてこれらの関係を構築します。セマンティック埋め込みの類似性、依存関係の抽出、および実行トレースのアライメントによって候補のエッジが生成され、その後、LLM(大規模言語モデル)による推論によって、それらが有向グラフ、型付きグラフ、および多関係グラフへと洗練されます。その結果、グローバルな推論、ワークフローの構成、およびタスク指向のスキル収集をサポートする、動的なスキルグラフが構築されます。
リポジトリ、API、およびPythonツールキット。
SkillNetは、完全なオープンインフラストラクチャとして提供されます。具体的には、大規模なキュレーションされたスキルリポジトリ、フロントエンドのウェブサイト(skillnet.openkg.cn)、キーワード検索とベクトル検索の両方をサポートするオープンアクセスAPI、そして汎用的なPythonライブラリとCLIツールskillnet-aiが含まれます。
このエコシステムを通じて、ユーザーはスキルをカテゴリ別に検索したり、APIドキュメントを閲覧したり、新しいスキルを投稿したり、スキルを検索してローカルワークスペースに直接ダウンロードしたり、トラジェクトリやコードベースから構造化されたスキルを作成したり、5つの品質次元に基づいて評価したり、大規模なスキル間の関係を分析したりすることができます。

skillnet-ai の実用的な利用例。このパッケージは、左側のコマンドラインインターフェースによるインタラクティブな利用と、右側のPythonライブラリによる、AI開発パイプラインへのシームレスな統合という、統一された機能を提供します。ベンチマーク:+40%の報酬、-30%のステップ数。
SkillNetは、3つのテキストベースのシミュレーション環境で評価されます。ALFWorldは、エージェントが日常的なタスクのためにオブジェクトを操作し、ナビゲートする、身体化された家庭環境のベンチマークです。WebShopは、製品の検索、比較、および制約付きの購入を含む、現実的なオンラインショッピングをシミュレートします。ScienceWorldは、エージェントが実験を行い、結果について推論する、仮想的な科学実験室です。
ベースラインとして、ReAct、ExpeL、および標準的なFew-Shotアプローチを使用します。SkillNetの変種は、タスク固有のスキルコレクションで拡張されており、評価時にエージェントは最も関連性の高いスキルを動的に選択、アクティベート、および実行します。バックボーンとして、DeepSeek V3.2、Gemini 2.5 Pro、およびo4 Miniを使用します。学習データとテストデータの重複を避けるため、学習データセットとテストデータセットは互いに重複しません。
ReActとExpeL — 性能を上回るための基準
ReAct は、推論(思考ステップ)と行動(ツール呼び出し)をループで組み合わせたものであり、LLMエージェントの最も広く使用されている基準の一つです。ExpeL(Experiential Learner)は、過去に成功した行動の履歴を記憶し、推論時にそれをFew-shotの例として利用します。どちらも、経験をコンテキストプロンプトとして扱います。SkillNetはさらに進んで、経験を名前、バージョン、評価がされた機能単位に変換し、どのエージェントでもインストールできるようにします。そのため、3つの異なるバックボーンモデルで性能向上が見られるのです。この改善は、より良いプロンプトから来ているのではなく、エージェントに実行可能なツールを提供することで、タスク間で持続する能力を提供することから生まれています。
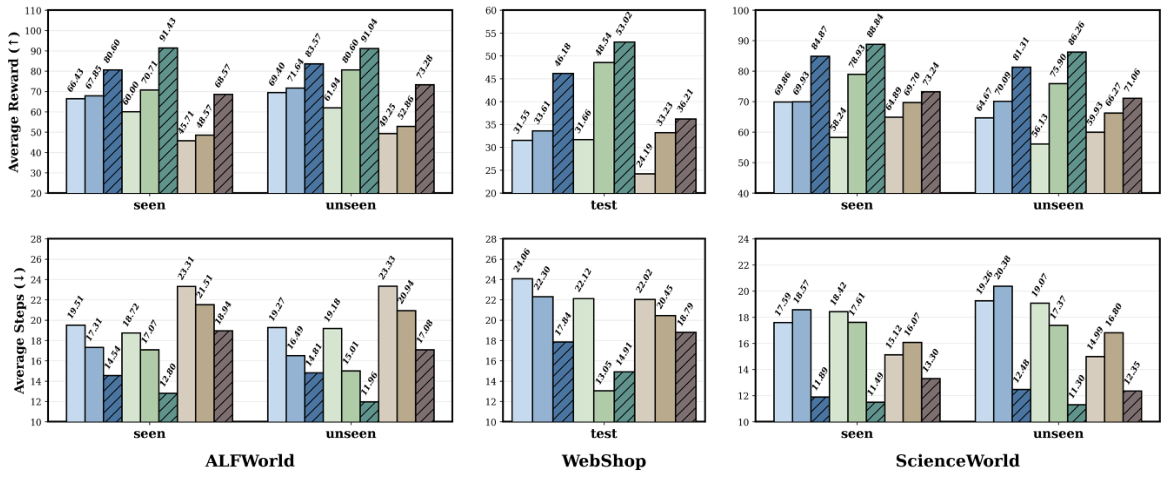
| Model | Method | ALFWorld Seen | ALFWorld Unseen | WebShop | ScienceWorld Seen | ScienceWorld Unseen | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| R↑ | S↓ | R↑ | S↓ | R↑ | S↓ | R↑ | S↓ | R↑ | S↓ | ||
| DeepSeek V3.2 | ReAct | 66.43 | 19.51 | 69.40 | 19.27 | 31.55 | 24.06 | 69.86 | 17.59 | 64.67 | 19.26 |
| ExpeL | 67.86 | 18.86 | 76.12 | 17.41 | 29.23 | 24.00 | 74.91 | 15.98 | 74.09 | 17.53 | |
| + SkillNet | 80.60 | 14.54 | 83.57 | 14.81 | 46.18 | 17.84 | 84.87 | 11.89 | 81.31 | 12.48 | |
| Gemini 2.5 Pro | ReAct | 60.00 | 18.72 | 61.94 | 19.18 | 31.66 | 22.12 | 58.24 | 18.42 | 56.13 | 19.07 |
| ExpeL | 68.57 | 17.88 | 70.15 | 17.04 | 33.12 | 19.31 | 72.76 | 15.01 | 67.37 | 14.91 | |
| + SkillNet | 91.43 | 12.80 | 91.04 | 11.96 | 53.02 | 14.91 | 88.84 | 11.49 | 86.26 | 11.30 | |
| o4 Mini | ReAct | 45.71 | 23.31 | 49.25 | 23.33 | 24.19 | 22.02 | 64.89 | 15.12 | 59.93 | 14.99 |
| ExpeL | 56.43 | 21.35 | 58.96 | 21.85 | 26.71 | 21.91 | 67.95 | 13.65 | 65.68 | 13.95 | |
| + SkillNet | 68.57 | 18.94 | 73.28 | 17.08 | 36.21 | 18.79 | 73.24 | 13.30 | 71.06 | 12.35 | |
Rは平均報酬(↑:高いほど良い)を示します。Sは平均ステップ数(↓:低いほど良い)を示します。最も優れた+SkillNetの結果は太字で強調表示されています。結果は論文から引用したものです。
行は次のように読み取ってください: Model × Method。 `R↑` はベンチマークの報酬(値が大きいほど良い)であり、`S↓` は完了までのステップ数(値が小さいほど良い)です。 各モデルブロックの + SkillNet の行が主要な結果です。その行と ReAct の行を比較して、実際の改善度合いを確認してください。
SkillNetを統合することで、平均的な報酬が40%向上し、ReActと比較してインタラクションのステップ数が30%減少します。この効果は、バックボーンのサイズによって増加します。具体的には、o4 Miniでは+15.7 R、Gemini 2.5 Proでは+28.5 Rの向上が見られます。この改善は、学習データと学習データ以外のデータセットの両方で確認されており、SkillNetがパラメータ知識に加えて、新たな能力を追加していることが示唆されます。
自律型科学およびコーディングエージェント.
SkillNetは、高度なユーザーの意図と実行可能なエージェントのアクションを結びつけ、専門的なスキルを、一貫性があり、評価可能なワークフローに整理します。以下に3つのシナリオを示し、それらが科学的発見、コーディング、および汎用的なパーソナルエージェントとの連携においてどのように役立つかを説明します。
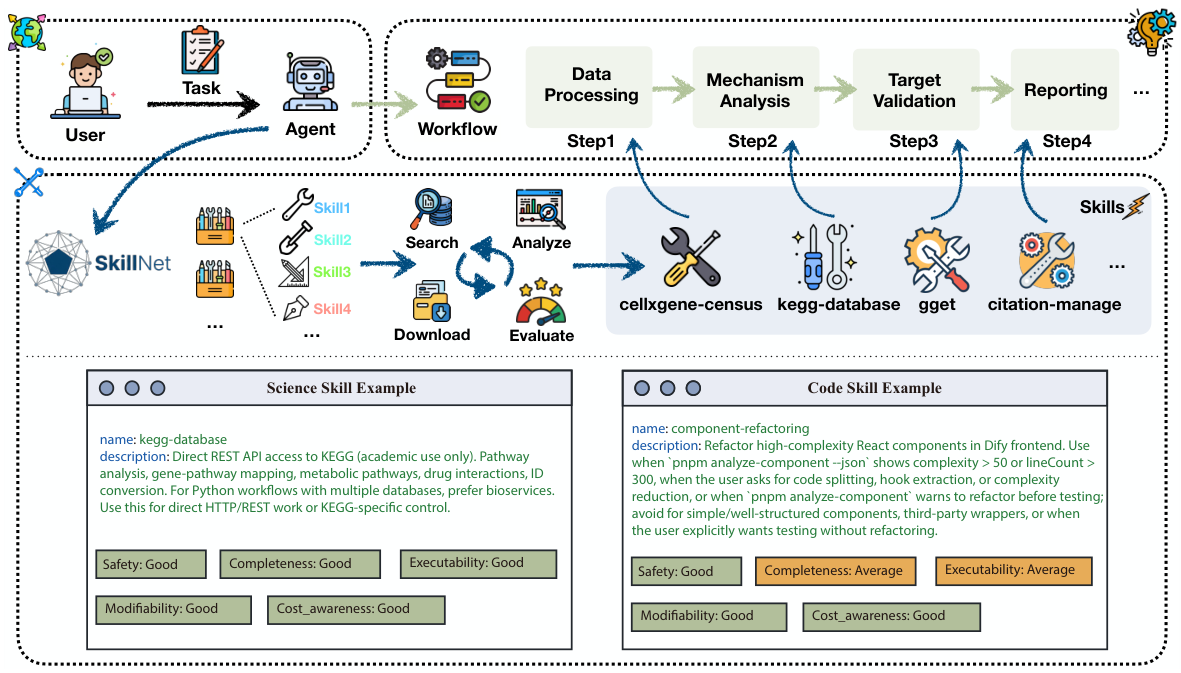
cellxgene-census、kegg-database、gget、citation-manage)によってサポートされます。下部は、科学とコーディングのシナリオにおける代表的なスキルカードを示しており、多次元評価が含まれています。自律的な科学的発見.
SkillNetは、データ処理、メカニズム解析、ターゲット検証、およびレポート作成のスキルを連携させます。例えば、SkillNetは、生データであるシングルセルRNA-seqデータを取得し、それをクラスタリングし、重要な遺伝子を生物学的経路にマッピングし、その臨床的意義をクロス検証し、その結果を引用可能な科学レポートとしてまとめます。
自律型コーディングエージェント
大規模なソフトウェアエンジニアリングのタスクにおいて、SkillNetは、システムの構造化されたビューを構築するためにコード分析スキルをスケジュールし、要件を分解し、回帰リスクを評価し、リアルタイムの可観測性によって裏付けられた、実装→テスト→検証のクローズドループパイプラインを実行します。
OpenClaw統合
OpenClawは、カスタマイズ可能なオープンソースのパーソナルエージェントフレームワークであり、SkillNetをスキルとして読み込みます。遅延ロードメタデータを使用し、タスク実行前にリポジトリに対して検索を行い、一致するスキルを必要に応じてインストールし、定期的にローカルワークスペースを分析することで、汎用的なエージェントを継続的に自己改善するシステムへと進化させます。
なぜOpenClawとの統合が真の試金石となるのか
ALFWorldのようなベンチマークは、制御されたサンドボックス環境で動作します。しかし、OpenClawのシナリオは異なります。それは、実際の、本番環境で利用可能な、インストール可能なパーソナルエージェントです。SkillNetが、遅延読み込みスキル、15万件のレポジトリに対する事前タスク検索、GitHubのURLからのオンデマンドインストール、および定期的な自己分析といった機能と、ここで機能する場合、それは単なる論文ではなく、エコシステムへと進化します。コミュニティがスキルを提供し、成功したタスクが新しいスキルとして統合され、同じSkillNetを使用するすべてのユーザーがエージェントの改善の恩恵を受けます。このサイクルこそが、著者がこれを「知識統合の主要な要素」と呼ぶ理由です。
スキルが記憶とワークフローをつなぐ架け橋となる。
SkillNetは、エージェントの生成能力に対する3つの補完的な制約という統一的な視点に基づいています。ワークフローは、明示的な手続き構造を課し、信頼性がありますが、柔軟性に欠けます。メモリは、文脈的な経験を蓄積し、適応性がありますが、無限に拡張される可能性があります。スキルは、これらの極端な状態を繋ぎ、再利用可能な能力単位をパッケージ化することで、生成を制約すると同時に、メモリを実用的なパターンとして整理します。
今後の展望として、新たな「一人ラボ」の概念は、単一の専門家がエージェントの集合体を統括する姿を想定しています。SkillNetは、スキルを知識統合と委任の主要な単位として位置づけます。個人がスキルリポジトリを構築し、エージェントがそれらをワークフローに構成し、そして記憶が継続的に経験を通じてそれらを洗練することで、孤立した自動化が累積的な機械的専門知識へと変貌します。
オープンワールドにおけるスキル進化.
オープンワールド環境における、自動的なスキル発見、抽象化、そしてドメインを越えた知識転移は、依然として難しい課題です。業界固有で、非公開のデータで構築されたSkillNetsが、将来のAIエージェントインフラの基本的な構成要素となる可能性もあります。
モデルとスキルの相乗効果
ニューロシンボリック統合とメモリメカニズムをどのように活用し、スキル構造がモデルの意思決定パスを誘導するようにするか—そして、モデルの能力が進化するにつれて、スキル階層をどのように再構築すべきか—という問題は、依然として未解決な課題です。
マルチエージェント連携
マルチエージェント環境において、SkillNetは共有表現および交換レイヤーとして機能し、協調的な計画、知識伝達、そしてエージェント間の累積的な経験をサポートします。
デジタルアバターと累積された専門知識。
エージェントの行動を継続的に統合し、再利用可能なスキルとして活用することで、蓄積されたスキルから徐々に高度化していくデジタルアバターを実現する道が開かれる。
制約事項
2つの重要な注意点があります。まず、スキルの網羅性は必然的に不完全です。多くの非公開または高度に専門的な能力は捉えきれませんし、低頻度で暗黙的な能力は、明示的な言語による記述に抵抗します。次に、自己構築されたスキルの品質は完全に保証できません。評価プロセスは明白な問題をフィルタリングしますが、微妙なエラーが残る可能性があります。
以下に翻訳されたテキストを示します。 翻訳されたテキスト: この文書は、特定の分野における参考文献を厳選して提示しています。
- Richard S. Sutton. The Era of Experience. 2024.
- OpenAI. GPT-4 Technical Report. 2023.
- Noah Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS 2023.
- Andrew Zhao et al. ExpeL: LLM Agents Are Experiential Learners. AAAI 2024.
- Shunyu Yao et al. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023.
- Shunyu Yao et al. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. NeurIPS 2022.
- Mohit Shridhar et al. ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. ICLR 2021.
- Ruoyao Wang et al. ScienceWorld: Is your Agent Smarter than a 5th Grader? EMNLP 2022.
- Guanzhi Wang et al. Voyager: An Open-Ended Embodied Agent with Large Language Models. 2023.
- Anthropic. Introducing Claude Code. 2024.
- Tao Yu et al. Towards Unified Skill Hubs for Autonomous Agents. 2025.
- DeepSeek-AI. DeepSeek V3.2 Technical Report. 2025.
- Google. Gemini 2.5 Pro Report. 2025.
- OpenAI. o4 Mini Model Card. 2025.
詳細な参考文献リスト(50件以上)は、arXivのPDFファイルでご覧いただけます。 上記の項目は、最も直接的に引用されている文献の厳選された一部です。