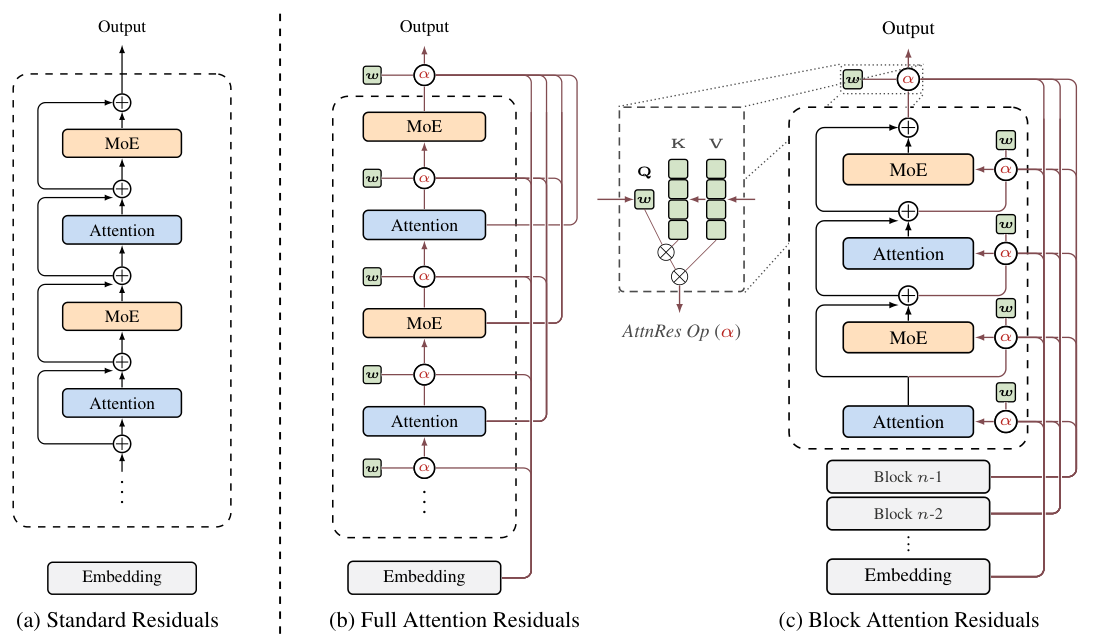
Attention Residuals: 手法
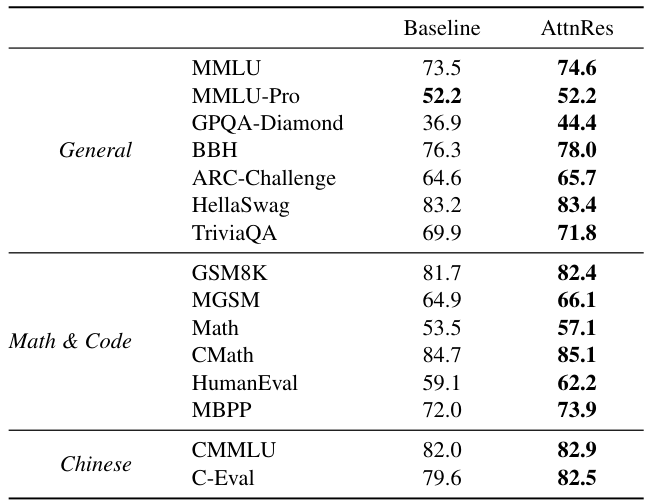
重要な洞察は、時間と深さの間の双対性 です。時間方向のRNNと同様に、残差接続は、深さ方向において、すべての過去の情報を単一の状態に圧縮します。系列モデリングにおいて、Transformerは、再帰をアテンションに置き換えることでRNNを改善し、各位置がすべての過去の位置を選択的に参照できるようにしました。AttnResは、この原則を深さの次元に適用します。
一般的な形式では、固定された累積和を次のように置き換えます。hl = Σ αl→j · vj 。ここで、α は、Σα = 1 を満たす、層ごとの注意の重みです。シーケンス長(これは数百万に達する可能性があります)とは異なり、ネットワークの深さは通常はそれほど大きくありません(L < 1000)。そのため、深さ方向の O(L2 ) の注意機構は、計算上実行可能です。
Full Attention Residuals
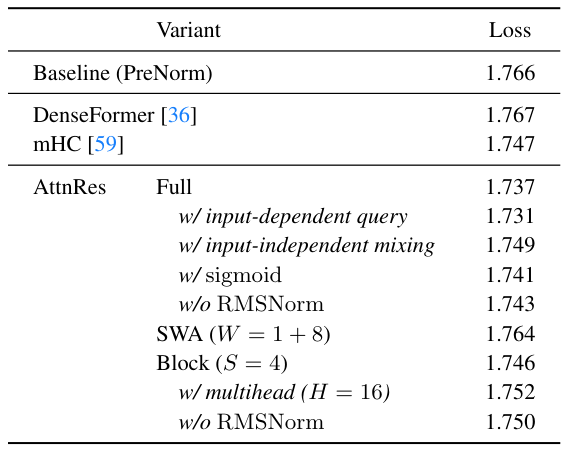
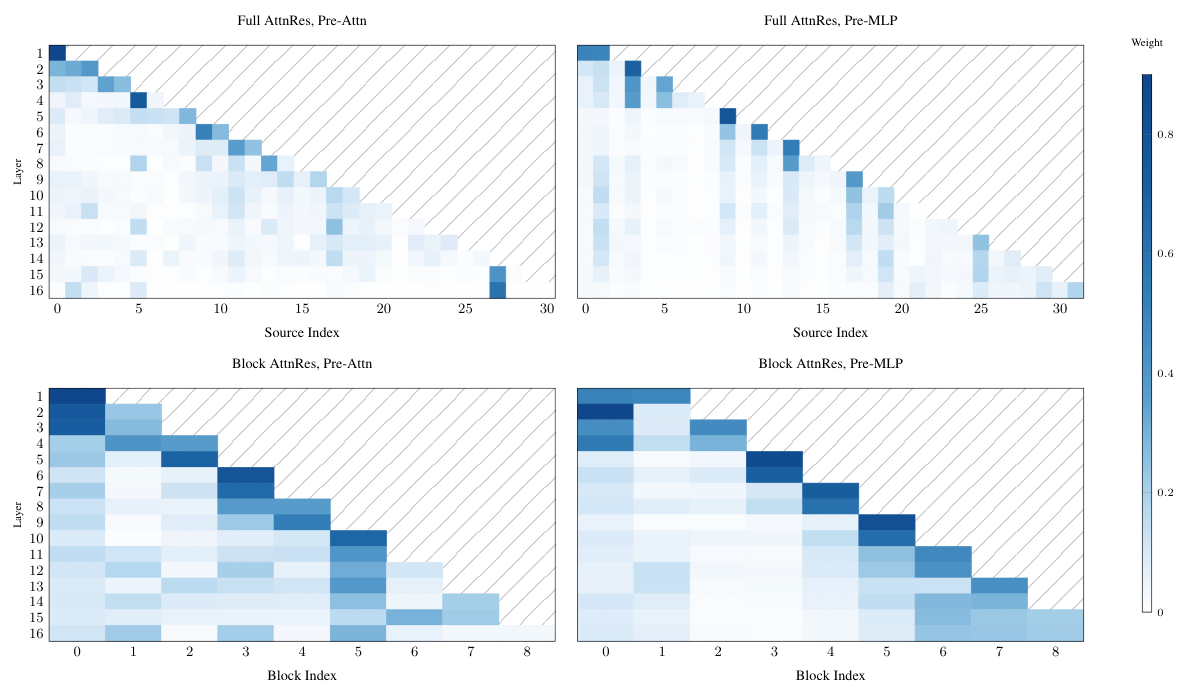
注意係数は、カーネル関数 φ を用いて、αl→j = φ(ql , kj ) として計算されます。 著者は、φ(q, k) = exp(qT RMSNorm(k)) を、softmax 正規化とともに採用しています。 クエリ q は、層ごとに特有の 学習可能なパラメータ (入力に依存しない) であり、これは並列計算を可能にするための意図的な設計上の選択です。
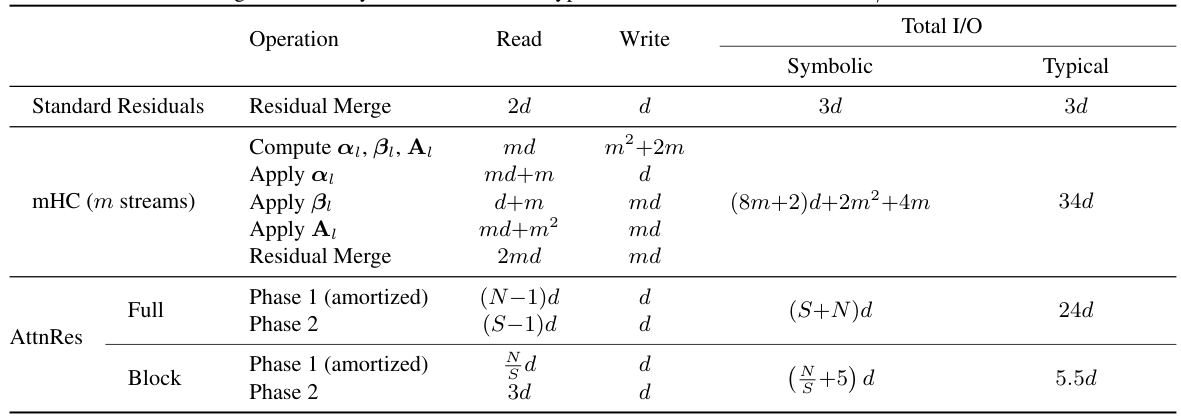
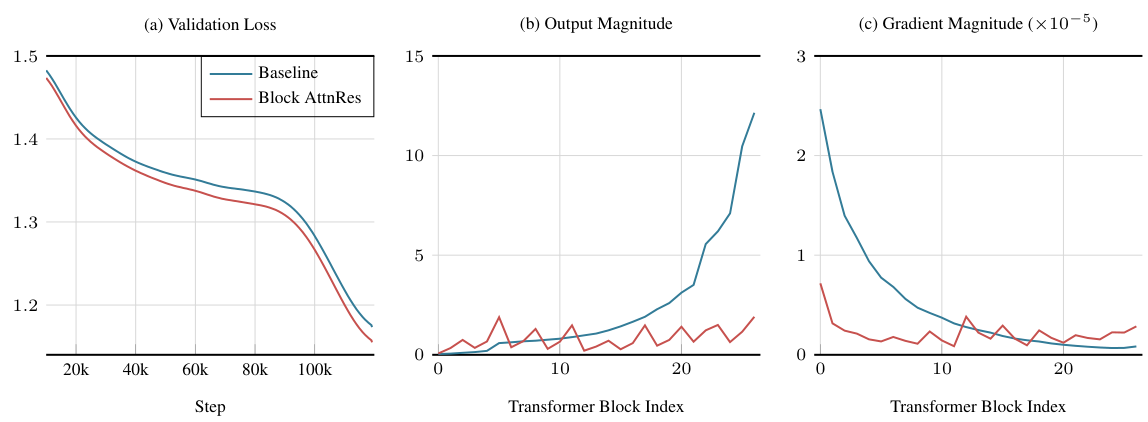
RMSNorm が φ の内部に組み込まれており、これにより、出力の大きさが大きい層が注意の重みに過度に影響を与えるのを防ぎます。各トークンについて、Full AttnRes は O(L2 d) の計算量と O(Ld) のメモリ量を必要とします。深さがシーケンス長よりもはるかに小さいことから、このコストは比較的わずかです。
標準的な学習におけるオーバーヘッドゼロ: O(Ld) のメモリオーバーヘッドは、バックプロパゲーションのために保持されているアクティベーションと完全に一致します。また、疑似的なクエリの独立性により、任意のグループのレイヤーに対する注意の重みは、シーケンシャルなレイヤーの実行を待つことなく、並行して計算できます。
「疑似クエリ」とは何か?
通常の注意機構(Transformerなど)では、クエリは現在の入力データから生成されます。一方、Full AttnResでは、クエリ wl は、学習可能なパラメータ です。これは、モデルが学習中に獲得する、入力から派生しない固定ベクトルです。これは意図的な選択であり、異なるレイヤーの注意機構の重みを並行して 計算できるようにするためです。なぜなら、それらは互いの結果に依存しないからです。トレードオフは、わずかに表現力が低下すること(クエリが特定の入力に適合しない)ですが、アブレーションスタディでは、このコストは小さいことが示されています。
ブロックアテンション残差構造
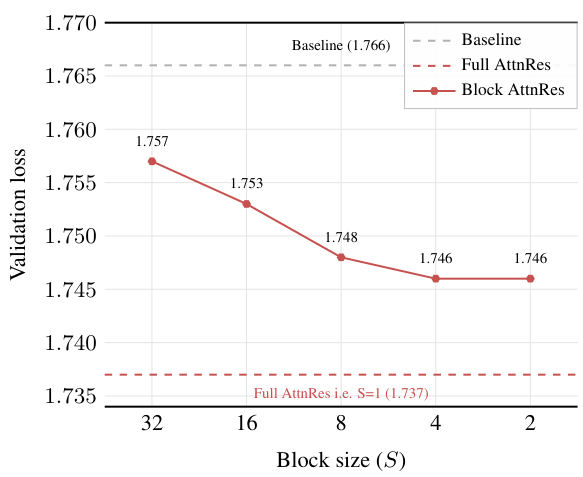
Block AttnResは、L層を、各ブロックがS = L/N層からなるN個のブロックに分割します。各ブロック内では、層の出力を合計によって単一の表現に削減します。ブロック間で、N個のブロックレベルの表現とトークン埋め込みに対して、フルアテンションが適用されます。これにより、メモリの使用量はO(L)からO(N)に、計算量はO(L2 )からO(N2 )にそれぞれ削減されます。
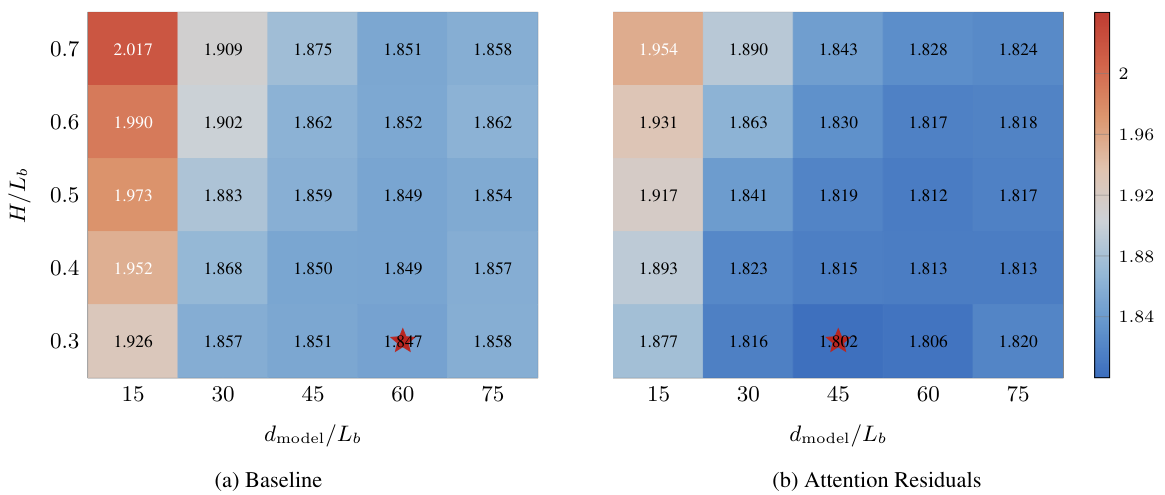
ブロック数 N は、2つの極値の間を補間します。N = L の場合、Full AttnRes が得られます 。N = 1 の場合、標準的な残差接続に帰着します 。実際には、S = 4(ブロックあたり4層)の設定が、ほとんどの利点をもたらしつつ、オーバーヘッドを最小限に押さえます。
2段階の計算戦略により、効率的な推論が可能になります。フェーズ1 では、バッチ処理されたクエリを使用して、キャッシュされたブロック表現に対して、すべてのS層のブロック間アテンションを同時に計算します。フェーズ2 では、ブロック内アテンションを逐次的に計算し、オンラインsoftmaxを通じて、フェーズ1の結果と統合します。これにより、メモリアクセスコストをブロック全体で償却できます。
二段階戦略の理解
54人の従業員(レイヤー)が、9つの部署(ブロック)に組織された会社を経営していると想像してください。各従業員の概要レポートが必要です。
第1段階(ブロック間): まず、9つの部署の各責任者から概要レポートを1つずつ収集します。すべての部署の概要レポートは一度に利用可能なので、効率的に一括処理できます。第2段階(ブロック内): 次に、各部署内で、個々の従業員を順番に処理します。各従業員について、その従業員のローカルな情報と、部署を横断した概要レポートを、オンライン・ソフトマックス (2つのソフトマックスの結果を最初から再計算することなく組み合わせる、数学的に正確な方法)を使用してマージします。
この戦略の利点は、第1段階にかかるコストが、ブロック内のすべてのレイヤーに分散される ため、各個々のレイヤーが負担するのは、ブロック間の処理にかかるコストのごく一部であることです。
アルゴリズム1: Block AttnResのための二段階計算。第1段階ではブロック間のクエリをバッチ処理し、第2段階では、オンラインsoftmaxマージによる逐次的なブロック内アテンションを処理します。