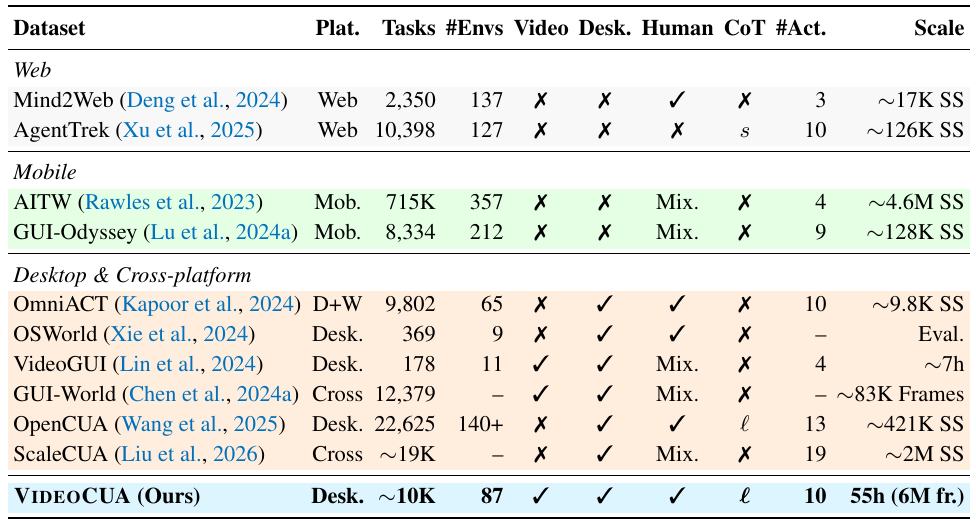
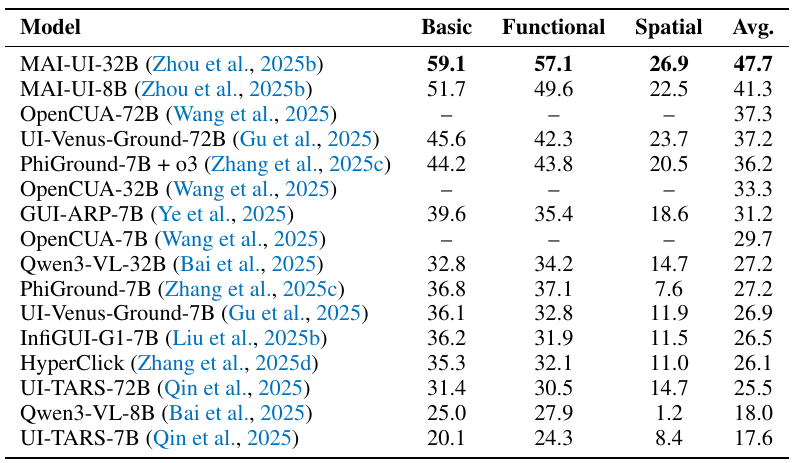
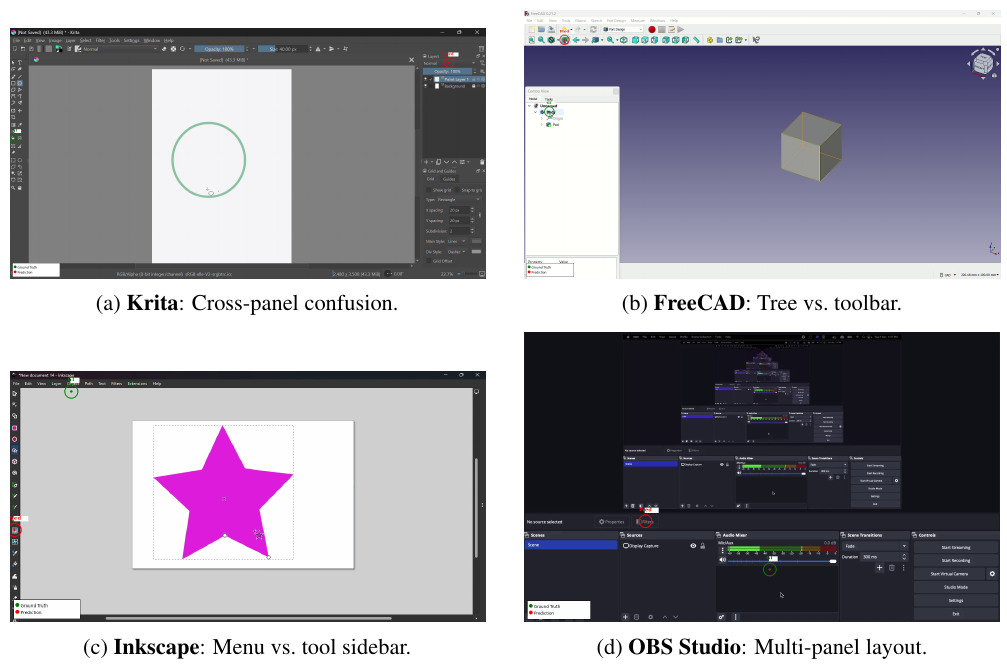
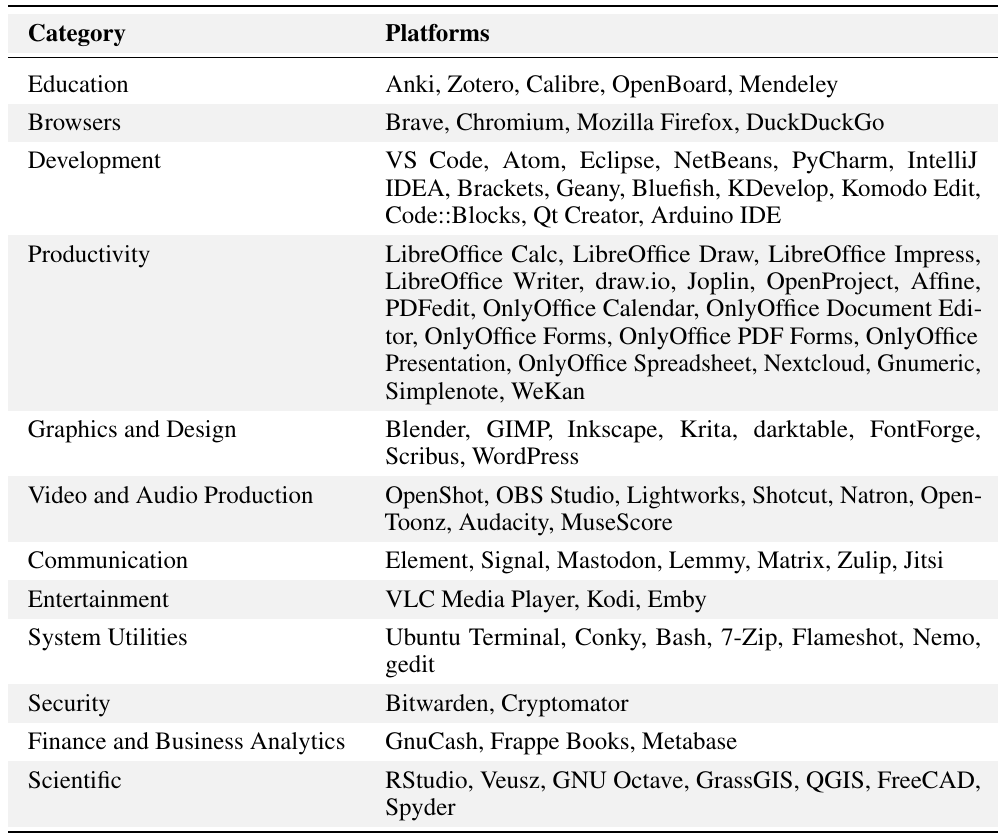
CUA-Suite エコシステム
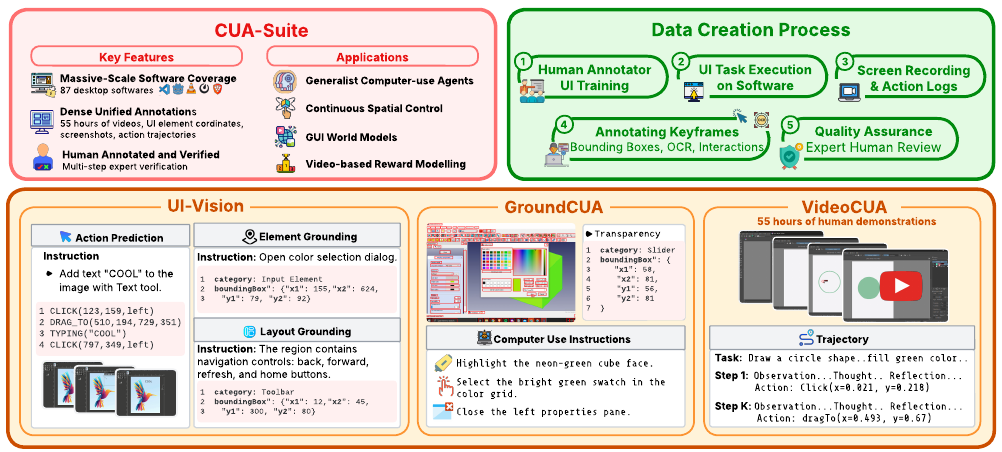
図 1: CUA-Suite 概要。デスクトッププラットフォーム全体で人間の GUI 操作軌跡が記録され、エキスパートにより検証され、キーフレーム、バウンディングボックス、インタラクションログでアノテーションされます。本スイートは UI-Vision、GroundCUA、VideoCUA で構成されます。
「コンピュータ操作エージェント(CUA)」とは?
コンピュータ操作エージェントとは、画面(ピクセルまたは解析されたUI要素)を観察し、クリック、タイピング、ドラッグ、スクロールなどのアクションを実行することでデスクトップコンピュータを操作できるAIシステムです。Web APIやコード実行とは異なり、CUAは人間と同じように視覚的にソフトウェアと対話するため、特別な統合なしにあらゆるアプリケーションに適用できます。主な課題は「現在何が画面に表示されているかを理解すること」「目標を達成するためにどのアクションを取るべきか知ること」「複雑なインターフェース上で正確にどこをクリックするかを特定すること」です。
VideoCUA
- 約 10,000 件の人手によるタスクデモンストレーション
- 55 時間の連続 30fps スクリーン録画
- ミリ秒精度のキネマティックカーソル軌跡
- 多層推論アノテーション(観察、思考、行動、振り返り)
- OpenCUA および ScaleCUA とフォーマット互換
GroundCUA
- 56K 枚のアノテーション付きスクリーンショット
- 360 万件の UI 要素アノテーション
- ピクセル精度の人手検証済みバウンディングボックス
- 要素の 50% に対する 8 つの意味カテゴリ
- グラウンディング用の 70 万件の instruction-tuning データセット
UI-Vision
- 450 件の高品質タスクデモンストレーション
- Element Grounding: テキストから UI 要素を特定
- Layout Grounding: 機能的に関連するグループを識別
- Action Prediction: 次の正しい行動を予測
- エージェント失敗の多面的診断