arXiv 2603.24800 · cs.CV · Mar 2026
Calibri: パラメータ効率の良いキャリブレーションによる拡散トランスフォーマーの性能向上
Only ~100 parameters. Consistent quality gains across FLUX, SD-3.5M, and Qwen-Image.
Reduces inference steps by 2–3×.

本論文では、Diffusion Transformers (DiTs) が持つ潜在能力を明らかにし、生成タスクを大幅に向上させる可能性を示します。ノイズ除去プロセスの詳細な分析を通じて、単一の学習済みスケーリングパラメータを導入することで、DiT ブロックの性能を大幅に向上させることができることを示します。 この洞察に基づいて、パラメータ効率の高い手法である Calibri を提案します。 Calibri は、DiT コンポーネントを最適に調整し、生成品質を向上させます。 Calibri は、DiT の調整を ブラックボックス報酬最適化問題 として捉え、進化的アルゴリズム を使用して効率的に解決し、わずか 約 100 のパラメータ のみを変更します。実験結果は、軽量な設計にもかかわらず、Calibri が様々なテキストから画像へのモデルにおいて、一貫して性能を向上させることを示しています。さらに、Calibri は、画像生成に必要な推論ステップを削減 し、高い品質の出力を維持します。
従来の画像生成モデルはノイズ除去のバックボーンに畳み込みネットワークを使用していました。Diffusion TransformerはそれをアテンションベースのTransformerアーキテクチャ(LLMと同種)に置き換えます。画像はパッチ(テキストのトークンに相当)に分割され、Transformerがすべてのパッチを同時に処理します。FLUXやStable Diffusion 3がその代表例です。アテンションがすべてのパッチを一度に参照できるため、DiTはグローバルな構図の処理に優れますが、計算コストが高いというトレードオフがあります。
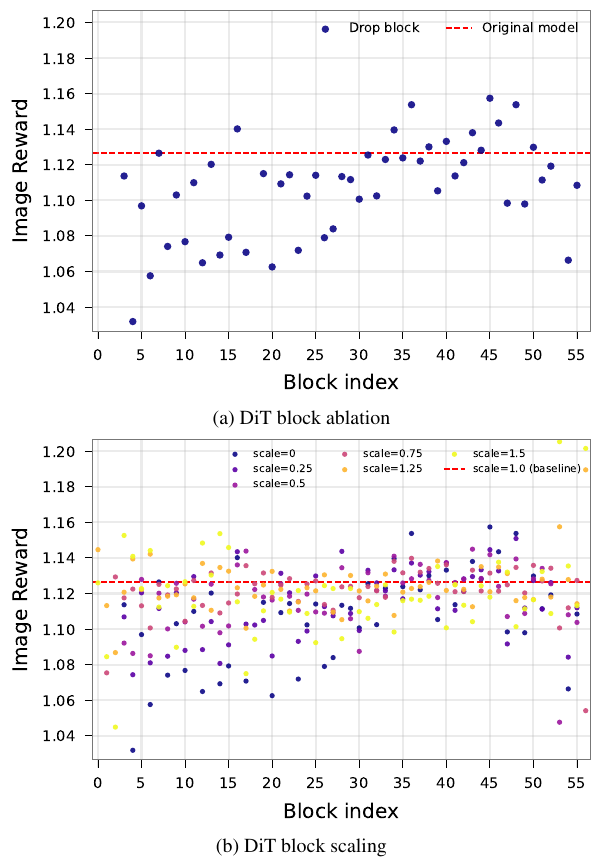
Stable Flowは、Transformerモデルにおいて「重要な層」を特定し、それらを除外するとモデルの出力に大きな変化が生じることを示しました。これに基づいて、著者らは、Qwen3モデルとFLUXモデルを用いて、64種類の多様なテキストプロンプトを使用して、各DiT ブロックの寄与を体系的に分析しました。
各DiTブロックl ∈ Lについて、その残差出力をバイパス(γ=0に設定)し、Image Rewardスコアへの影響を測定しました。驚くべきことに、特定のブロックを削除することで、生成される画像の品質が低下するのではなく、むしろ向上する場合があります。
Transformerでは、各ブロックが自身の入力に出力を加算します(「残差接続」)。γ=0はブロックの出力をゼロにすることを意味します。驚くべき発見は、一部のブロックが実際に画像品質を低下させていることです。これらのブロックは特定の生成タスクに対して最適に訓練されていないためです。この診断結果がCalibrの動機となっています。デフォルトの重みは最適ではなく、ブロックごとに単純なスカラーを追加する後処理で再訓練なしに修正できます。
別の実験では、各ブロックの出力をスカラーs ∈ {0, 0.25, 0.5, 0.75, 1.25, 1.5}倍にしました。その結果: 各DiTブロックについて、元の構成よりもパフォーマンスを向上させる最適なスケーリング係数が存在します。
標準的なDiTアーキテクチャは、最適ではない重み付けがされており、そのパフォーマンスは、ブロックの簡単な事後調整によって大幅に向上させることができます。
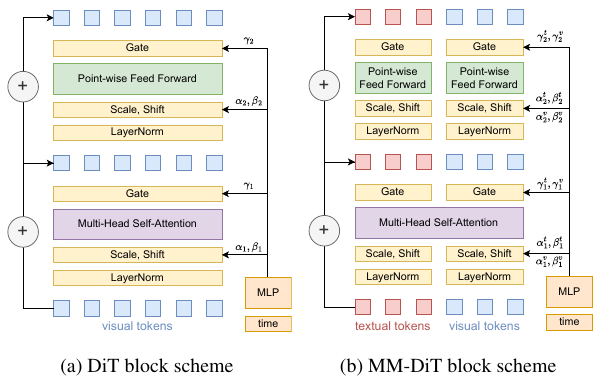
Calibriは、キャリブレーションパラメータをc = ω ∪ {si}として定義します。ここで、ωは出力レベルの重み、siは内部層のパラメータを表します。3つの粒度レベルが導入されています。
同じブロック内のAttentionとMLPの出力を、単一の共有されたスカラーsを用いて一様にスケーリングします。最も粗い粒度レベルです。FLUXの場合、57のパラメータを使用し、200イテレーション/32 GPU時間で収束します。
各ブロック内の個々の層を、異なる係数を用いてスケーリングします。より柔軟性があります。FLUXの場合、76のパラメータを使用します。パフォーマンスとトレーニング速度のバランスが最も良く、すべての報酬関数に対して最も一貫した改善が見られます。
MM-DiTモデルのゲートごとのキャリブレーションで、視覚とテキストのゲートに対して個別にスケーリングを行います。FLUXの場合、114のパラメータを使用します。HPSv3のターゲットメトリックは最も高くなりますが、収束が遅い(960イテレーション/150 GPU時間)。
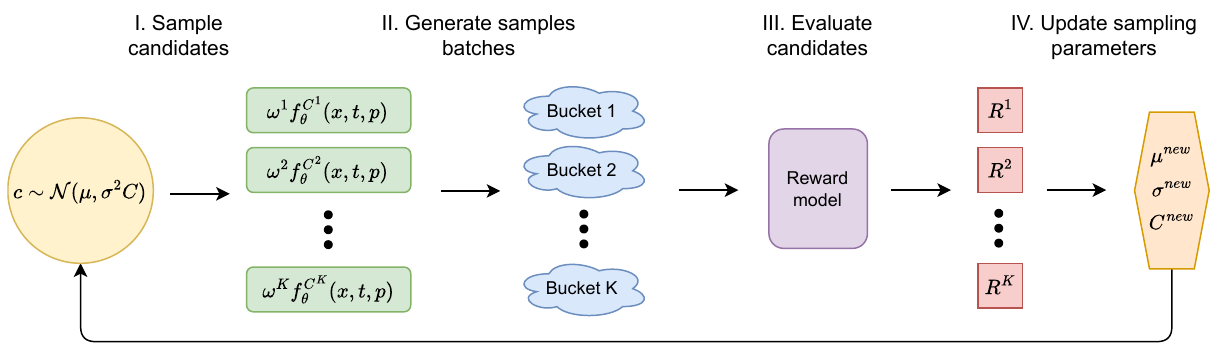
最適なキャリブレーション係数を見つけるために、Calibriは共分散行列適応進化戦略 (CMA-ES)を使用します。これは、勾配を必要としない最適化アルゴリズムです。各イテレーションで、候補解を多変量ガウス分布N(μ, σ2C)からサンプリングし、報酬モデルによって評価し、μ、σ、およびCを更新します。
通常のニューラルネットワーク訓練では誤差逆伝播法(バックプロパゲーション)を使います。しかし、ここでの目標は、何千もの生成画像をスコアリングする画像報酬モデル(HPSv3、Image Reward)であり、スケーリングスカラーからそのスコアへの微分可能な経路が存在しません。CMA-ESは問題全体をブラックボックスとして扱います:多数のスカラー候補セットを提案し、それぞれで画像を生成し、報酬を測定し、上位の結果を使って次世代の候補が抽出されるガウス分布を更新します。勾配は不要で、必要なのは画像評価のみです。
Calibriアンサンブルは、N個の異なるキャリブレーションモデルを単一のサンプラーに集約します。
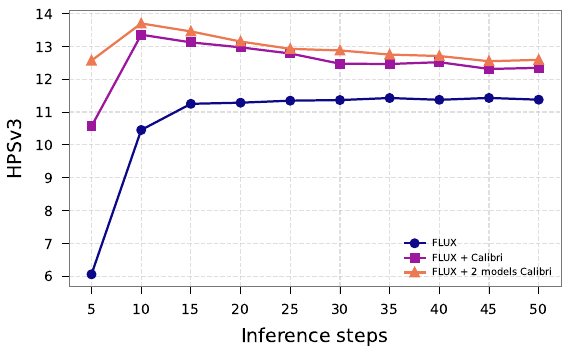
F{ci}(x, t, p) = ∑i=1N ωi fθsi(x, t, p|∅)N=2の場合、ブロックのスケーリングを使用するCalibriアンサンブルは、Skip Layer Guidance(空間時間ガイダンス)を一般化し、トレーニング不要なAuto-guidanceの一種となります。アンサンブルキャリブレーションは、すべての推論ステップでHPSv3の報酬を向上させ、最適なサンプリングステップ数を30〜50からわずか10〜15にシフトさせます。
拡散モデルはランダムなノイズを多くのステップにわたって段階的に除去することで画像を生成します。各ステップでは完全なニューラルネットワークが実行されます(NFE:関数評価回数)。ステップ数が多いほど品質は高くなりますが、それに比例した時間がかかります。FLUXのデフォルトは30ステップ、SD-3.5Mは80ステップです。Calibriアンサンブルは品質とステップ数のカーブをシフトさせ、以前は30〜50ステップ必要だった品質を10〜15ステップで達成できるようにします。これにより実質的に2〜3倍の高速化が無償で得られます。
すべての実験では、Fluxモデルを使用し、最適化はHPSv3報酬によってガイドされます。トレーニングおよびテスト用のプロンプトは、T2I-Compbench++から取得されます。バッチサイズ: 16、画像解像度: 512、推論ステップ数: 15(トレーニング時)。
HPSv3は、大規模な人間のペアワイズ選好データで訓練された学習型報酬モデルです。同じプロンプトに対する2枚の画像のうち、人間のアノテーターがどちらを好むかを投票し、ニューラルネットワークがその投票を予測するスカラースコアを学習します。HPSv3はその第3世代であり、人間の美的感覚により適合するよう改良されています。Image Reward(IR)とQ-Alignは代替の報酬モデルです:IRも選好訓練されており、Q-Alignは1〜5スケールでスコアを出力する品質評価モデルです。複数の報酬指標を使用することで、特定の指標の特性に過学習するリスクを軽減しています。
| スケーリング | Nパラメータ | イテレーション | HPSv3 | IR | Q-Align |
|---|---|---|---|---|---|
| — | — | — | 11.41 | 1.15 | 4.85 |
| ブロック | 57 | 200 | 13.29 | 1.17 | 4.91 |
| レイヤー | 76 | 410 | 13.41 | 1.24 | 4.90 |
| ゲート | 114 | 960 | 13.48 | 1.18 | 4.88 |
ゲートのスケーリングは、最も高いHPSv3スコアを達成しますが、他の報酬では性能が低下します。レイヤースケーリングは、最も一貫性のある改善と最も高速なトレーニング速度をもたらします。

| モデル | Calibri | HPSv3 | IR | Q-Align | NFE |
|---|---|---|---|---|---|
| FLUX | × | 11.41 | 1.15 | 4.85 | 30 |
| ✓ | 13.48 | 1.18 | 4.88 | 15 | |
| SD-3.5M | × | 11.15 | 1.10 | 4.74 | 80 |
| ✓ | 14.10 | 1.17 | 4.91 | 30 | |
| Qwen Image | × | 11.26 | 1.16 | 4.55 | 100 |
| ✓ | 12.95 | 1.18 | 4.73 | 30 |
| 手法 | 全体的な好み | テキストの整合性 | ||||
|---|---|---|---|---|---|---|
| Calibri | 同率 | オリジナル | Calibri | 同率 | オリジナル | |
| Flux | 51.87 | 7.33 | 40.80 | 38.71 | 37.68 | 23.61 |
| Qwen-Image | 54.62 | 7.91 | 37.47 | 40.29 | 37.65 | 22.06 |
評価者は、全体的な好みとテキストの整合性の両方において、Calibriを決定的に好む傾向があり、これは真に知覚できる改善(報酬アーティファクトではない)であることを確認しています。また、Calibratedモデルは、ベースラインモデルと比較して2〜3倍高速です。
HPSv3などの報酬モデルは「攻略」される可能性があります。モデルがメトリックで高スコアを出すパターンを学習しても、実際に人間の目には良く見えない可能性があります。実際のユーザー(200人の評価者、5,600件のペアワイズ比較)による人間評価は、改善が知覚的に本物かどうかの真実の基準を提供します。50%を超える勝率は、両方を並べて見せたときに評価者がベースラインよりCalibrの出力を好んだことを意味します。Calibriが51.9%(FLUX)と54.6%(Qwen-Image)の勝率を達成しているという事実は、メトリック向上がアーティファクトではないことを確認しています。
多様なプロンプトとモデルアーキテクチャにおける定性的な比較は、定量評価で報告されている一貫した視覚的な改善を確認しています。すべてのモデルは、表2と同じNFE(Non-Final Embedding)を使用しています。


Flow-GRPOは、フローマッチング拡散モデルのための強化学習ベースのアライメント手法です。LLMのRLHFから来たGroup Relative Policy Optimization(GRPO)という手法を使って、報酬信号に向けてモデルの全重みを微調整します。Calibriと異なり、Flow-GRPOは勾配ベースの最適化で数百万〜数十億のパラメータを変更し、大量のGPU計算リソースを必要とします。ここでの比較は、Calibri(約100スカラー、勾配不要)がFlow-GRPOの知覚的品質向上に匹敵でき、両者が補完的かつ組み合わせ可能であることを示しています。
本研究では、拡散トランスフォーマー (DiT) の生成能力を向上させるための、新規かつパラメータ効率の高い手法である Calibri を紹介しました。単一の学習済みスケーリングパラメータの潜在能力を活用することで、DiT の構成要素への寄与を最適化し、最小限のパラメータ変更で大幅な性能向上が可能であることを示しました。
キャリブレーションプロセスを、CMA-ES 進化戦略によって解決されるブラックボックス最適化問題として捉え、Calibri は約 102 個のパラメータのみを調整し、一貫して生成品質を向上させます。さらに、提案された推論時のスケーリング手法である Calibri Ensemble は、キャリブレーションされたモデルを効果的に組み合わせることで、さらなる結果の向上を実現します。
テキストから画像を生成する様々な拡散モデルにおける広範な実証評価により、Calibri の有効性と効率性が確認され、優れた生成品質を、計算コストを削減して実現できることが示されました。注目すべきは、Calibri が、高画質の出力を維持しながら、画像生成に必要な推論ステップ数を削減し、計算効率が重要な現実世界のアプリケーションにとって実用的なソリューションとなることです。