Intern-S1-Pro: 科学分野における大規模マルチモーダル基盤モデル
🔗 HuggingFaceでのモデル概要
「1兆パラメータ」とは実際どういう意味か?
モデルパラメータとは、ニューラルネットワークのすべての知識と推論能力を符号化した学習済み重みです。GPT-3は1750億パラメータでした。1兆(1012)パラメータは典型的な大規模モデルの5〜10倍に相当します。しかし、Intern-S1-ProはMixture-of-Experts(MoE)アーキテクチャを採用しており、単一の推論で「アクティブ」になるパラメータは一部のみです(「1T-A22B」=総計1兆だが1フォワードパスで約220億のみ有効)。これにより、1兆パラメータの密なモデルと同等の表現力を、計算コストの何分の一かで実現しています。
本稿では、初のone-trillion-parameter scientific multimodal foundation modelであるIntern-S1-Proをご紹介します。この前例のない規模に拡張されたモデルは、一般的な分野と科学分野の両方において、包括的な性能向上を実現します。より高度な推論能力と画像・テキスト理解能力に加え、高度なエージェント機能を備えています。同時に、その科学的な専門知識は大幅に拡張され、化学、材料、生命科学、地球科学など、重要な科学分野における100以上の専門的なタスクを習得しています。
この大規模化は、XTunerとLMDeployによる堅牢なインフラストラクチャのサポートによって実現しました。これにより、1兆パラメータレベルでの非常に効率的な強化学習(RL)トレーニングが可能になり、トレーニングと推論の間で厳格な精度の一貫性が確保されています。これらの進歩をシームレスに統合することで、Intern-S1-Proは、一般的な知能と専門的な知能の融合をさらに強化し、汎用的な能力におけるオープンソースモデルのトップレベルに位置しつつ、専門的な科学タスクの深さにおいて、独自のモデルを凌駕します。
1. 概要
大規模言語モデル(LLM)と視覚言語モデル(VLM)の登場は、人工知能の分野に革命をもたらし、推論、生成、そしてマルチモーダルな理解において、前例のない能力を提供しています。AI for Science (AI4S)の分野において、これらの基盤モデルは、タンパク質の構造予測から材料設計に至る、複雑な問題に取り組む研究者を支援し、科学的発見を加速させるための重要なツールとして登場しています。
効果的な科学的基盤モデルを構築するためには、モデルのサイズを拡大することが不可欠です。これは、科学分野に内在する膨大な多様性によるものです。自然言語と比較して、科学はより専門的な分野を包含しており、それぞれが独自の「言語」を持っています。これには、ドメイン固有の表記、知識、および推論パターンが含まれます。科学的基盤モデルは、幅広い科学的タスクをマスターしながら、一般的なテキストおよびビジョン能力を維持するのに十分な能力を持つ必要があります。
本研究では、最初の1兆パラメータの科学的マルチモーダル基盤モデルであるIntern-S1-Proを紹介します。3層のSAGE(汎用的な専門家を対象とした相乗アーキテクチャ)フレームワークに基づいて、一般タスクと特定のタスクを組み合わせて学習させた十分な大きさの汎用モデルは、いくつかの科学的タスクにおいて、特定のタスクに特化したモデルよりも優れた性能を発揮することを示します。これは、特定のタスクでは特化モデルが優れているという一般的な認識とは異なります。
エンジニアリングの側面では、XTunerトレーニングフレームワークとLMDeploy推論エンジンとの間で深い最適化を実現し、Intern-S1-Proを、その前身であるIntern-S1の4倍のサイズに拡大させながら、トレーニング効率の低下を約20%に抑えることに成功しました。
2. アーキテクチャ
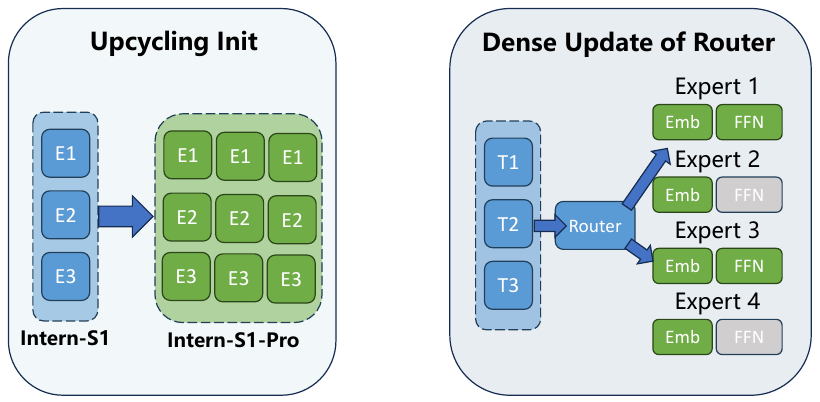
Intern-S1-Proは、expert expansionによりIntern-S1を改良したものであり、グループルーティング設計を採用し、安定したトリリオン規模のMoEトレーニングを実現します。
2.1 グループルーティング
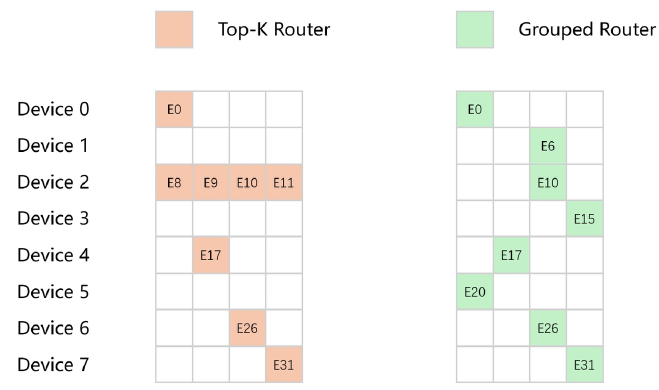
超大規模MoEモデルのトレーニングにおいては、Expert Parallelism (EP) が、GPUメモリと通信のオーバーヘッドを軽減するための主要な技術的アプローチとして機能します。しかし、従来のTop-kルーティング戦略によって引き起こされるexpertの負荷不均衡は、expert並列トレーニング中にデバイス間の負荷不均衡をもたらします。
Mixture-of-Experts(MoE)と負荷分散問題
標準的なTransformerでは、すべてのトークンが同じFFN重みを通過します。MoEモデルでは、各層が複数の並列「エキスパート」FFNを持ち、学習済みルーターが各トークンを上位k個のエキスパートにのみ送ります。これにより、計算コストを比例的に増やすことなくモデルの容量を拡大できます。問題は、ルーターが常に同じ少数の人気エキスパートにトークンを送ると、そのGPUデバイスが過負荷になり、他のデバイスが待機状態になることです。従来のTop-Kルーティングがこの不均衡を引き起こします。グループルーティングはエキスパートをグループに分割し、各グループから厳密に1つのエキスパートを選択することで解決します。入力分布にかかわらず、各デバイスが均等な負荷を確実に得られます。
そこで、従来のTop-K Routerをグループルーティングに置き換えることで、8ウェイのexpert並列トレーニング戦略におけるデバイス間の絶対的な負荷バランスを達成します。グループルーティングアーキテクチャでは、すべてのexpertが互いに排他的なG個のグループに均等に分割されます。各グループgにおいて、グループ内のスコアが最も高い上位(K/G)のexpertのみが選択されます。
Intern-S1-Pro 1Tモデルの構成(k = 8)とEP8トレーニング戦略とを組み合わせ、すべてのexpertを8つのグループに分割し、各グループ内で上位1つのexpertを選択することで、デバイス間の絶対的な負荷バランスを達成します。このアプローチは、トレーニング効率を大幅に向上させるだけでなく、トレーニング中のOOMリスクを根本的に排除します。
2.2 スパースexpertルーティングのためのStraight-Through Estimator
MoEアーキテクチャは、Top-k選択によって、各入力トークンをN個のexpertのうちの小さなサブセットであるK個のexpertにルーティングすることで、モデルの容量を拡張します。レイヤーの出力は次のとおりです。
なぜここでStraight-Through Estimatorが必要なのか?
Top-K選択操作(最高スコアのエキスパートを選ぶ)は微分不可能です。これは離散的なargmaxであり、勾配がルーターの重みに逆流できません。つまりルーターが「凍結」し、学習できなくなる可能性があります。Straight-Through Estimator(STE)はこの問題を解決するトリックです:フォワードパスでは離散的な選択を使用し、バックワードパスでは温度スケールのソフトマックスという連続関数であるかのように振る舞って勾配を計算します。これにより、すべてのルーターパラメータが毎ステップ勾配更新を受け取り、大規模においてもルーターを学習可能な状態に保ちます。
フォワードパスとバックワードパスのルーティング操作を分離するために、Straight-Through Estimator (STE)を導入します。STEのルーティング重みは次のように構成されます。
ここで、piτ = softmax(z/τ)i はスケーリングされたルーティング確率であり、sg(·) はstop-gradient演算子です。損失Lに関するlogit zjの勾配は次のとおりです。
STEにより、ルーターはトレーニング全体で一貫したデータ駆動型のフィードバックを受け取り、ルーターのすべての埋め込みが各パスで更新されることを可能にします。
2.3 ビジョンエンコーダー
Intern-S1-Proは、Native Vision Transformer (ViT)をビジョンエンコーダーとして採用しています。エンコーダーは、元の入力解像度に依存する視覚トークンの数ではなく、元の解像度で画像を処理します。
エンコーダーのトレーニングには、CC12M、LAION-COCO、SBU Caption、LAION-2B-Multi、およびWukongなど、約3億の画像とテキストのペアを使用したコントラスト学習が使用されます。
2.4 FoPE — フーリエ位置エンコーディング
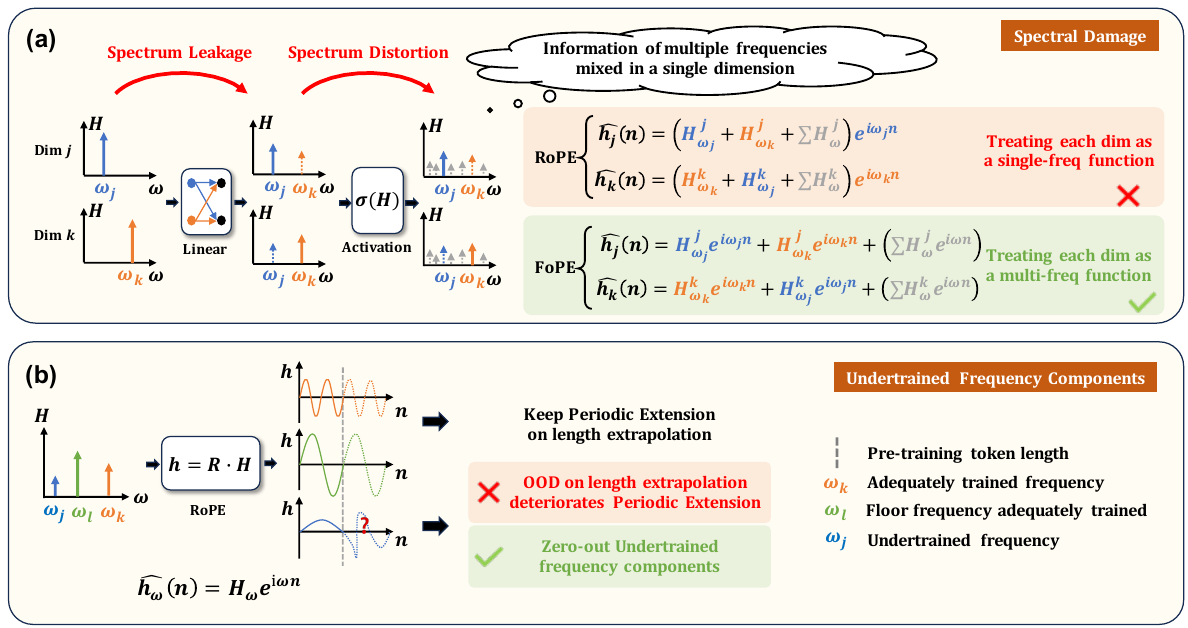
RoPE (Rotary Position Embedding)のような従来のポジショナルエンコーディング手法は、すべてのモダリティに粒状表現を課し、情報を局所的で離散的な単位として扱います。これにより、本質的に波動干渉およびスペクトル特性を持つ物理信号(画像、音声、ビデオ)に対する表現ギャップが生じます。
FoPE (Fourier Position Encoding)は、この制限に対処するために、Transformerモデルが位置と構造をどのようにエンコードするかを再考します。各次元を異なる周波数成分のフーリエ級数として扱い、情報をより効果的に分離し、スペクトル損傷を軽減します。不十分なトレーニングを受けた周波数成分は、その有害な影響を取り除くためにクリップされます。
RoPE vs FoPE:マルチモーダル信号の位置エンコーディング
Rotary Position Embedding(RoPE)は現代のLLM(LLaMA、GPT-4など)で主流の位置エンコーディングです。埋め込みベクトルを回転させてトークン位置を符号化し、テキストシーケンスには適しています。しかし、画像、音声、科学的信号は波のようなスペクトル構造を持ちます。ピクセルの意味はその2D近傍に依存しますが、1D順次回転ではそれをうまく表現できません。FoPEは各埋め込み次元をフーリエ級数の正弦波周波数成分として扱い(空間的・時間的に構造化されたデータに対してより自然な表現です)、「クリッピング」ステップは十分に訓練されていない周波数成分を除去してノイズを防ぎます。
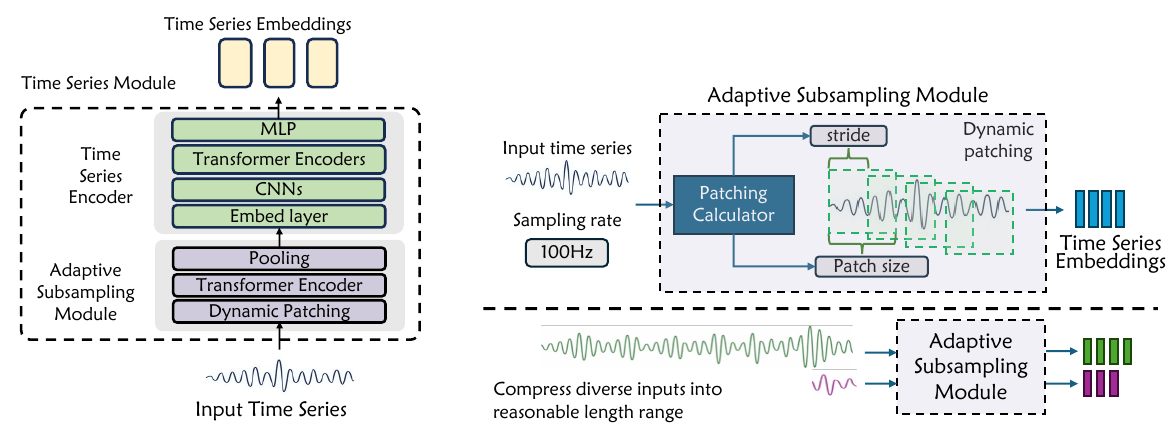
2.5 時系列エンコーダー
時系列は、複雑なプロセスの時間的進化を捉える、主要な科学データモダリティです。Intern-S1-Proの時系列モジュールは、適応的なサブサンプリングモジュールを備えており、これは連続信号をローカルセグメント(パッチ)に分割し、各パッチ内のローカルな動態を捉え、セグメント間の長距離依存関係をモデル化します。適応的にパッチサイズとストライドを決定することで、時間フレーム数を制御可能な範囲内に維持します。
このモジュールは、生理学的信号分析(EEGに基づくうつ病検出)、マルモセットの音声認識、および心電図異常モニタリングなど、100から106までの時間ステップのシーケンスを処理する範囲を拡大します。
3. 事前学習
Intern-S1-Pro は、画像とテキスト、およびテキストデータを使用して、合計 6兆トークン のデータで追加の事前学習を実施しており、特に科学画像に特化したキャプションデータの品質を向上させています。
3.1 キャプションパイプライン
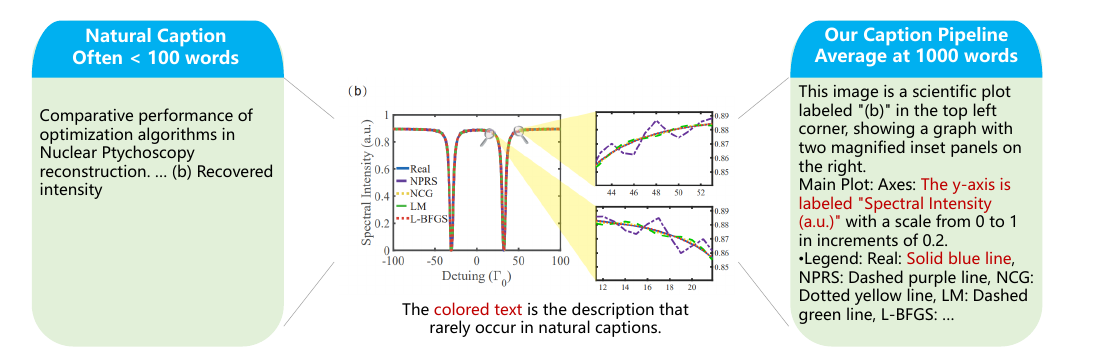
Web ソースからの科学画像は、短く、精度が低いキャプションを伴うことがよくあります。一方、PDF は科学的な視覚コンテンツの主要な媒体であり、実験結果、統計プロット、構造図、および公式の導出など、高密度な情報を含む図が含まれています。
科学的キャプションの品質がなぜそれほど重要なのか
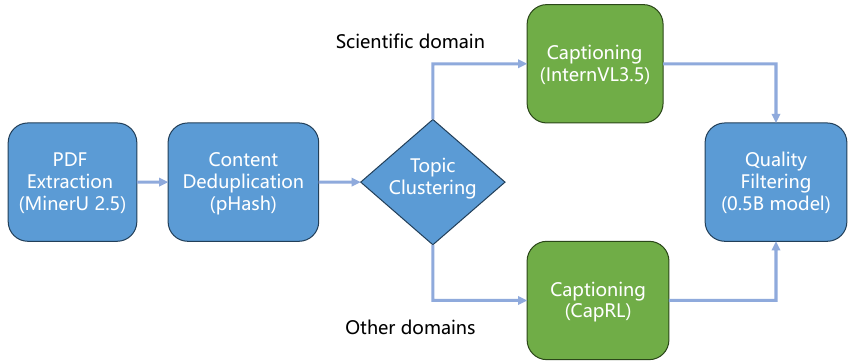
マルチモーダルモデルは、画像とテキストのペアで訓練することで視覚特徴とテキストを結びつける方法を学習します。あるプロットのキャプションが「図3」とだけ書かれていて、軸の意味や観察すべき傾向が説明されていない場合、モデルはその図から何も学びません。Web上でスクレイピングされた科学画像は特に問題が深刻です。このため、本論文はPDFからサブ図を抽出し、ドメインエキスパートモデル(科学図にはInternVL3.5-241B、その他にはCapRL-32B)を使用して約1000語の詳細なキャプションを生成する専用パイプラインを構築しました。結果として得られた270Bトークンの豊かな科学的画像とテキストデータは、このパイプラインなしには存在しなかったものです。
我々は、大規模な PDF データ生成パイプラインを独自に構築しました。具体的には、MinerU 2.5 を使用して、膨大な PDF コーパスからサブ図を抽出し、知覚ハッシュ (pHash) による正確な重複排除、トピック分類とモデルのルーティング (科学画像 → InternVL3.5-241B; 非科学画像 → CapRL-32B)、および 0.5B パラメータのテキスト品質識別器によるフィルタリングを行っています。その結果、約 2700億トークン の高品質な科学画像とテキストのキャプションデータが得られました。
3.2 科学データとテキストデータ間の矛盾の解決
構造化され、論理的な決定性が高い科学データを、意味の深さや言語的多様性に富んだ一般的なデータと直接混合すると、分布のずれや負の転移が生じる可能性があります。Intern-S1-Pro は、以下の 3 つの戦略を採用しています。
構造化された科学データの変換
PubChem などのデータベースからの異質な科学的な入力と出力のペアを、テンプレート構築とタスクフォーム変換によって文法的に正しい記述文に変換し、科学データを一般的なデータの表現スタイルに合わせます。
科学データの多様化
プロンプトの多様化とロールアウトメカニズムは、反復的な科学的なシーケンス (例: タンパク質配列) への過学習を防ぎます。科学的な事前知識と強力な基本モデルを組み合わせて、完全な推論チェーンを生成することで、知識の想起を論理的な演繹に変換します。
システムプロンプトの分離
トレーニングサイクル中に、科学データと一般的なデータに対して、互いに排他的なシステムレベルのプレフィックスを注入し、モデルに対して独立したコンテキスト処理環境を作成します。これにより、データの衝突を軽減し、モデルの安定性を向上させます。
4. 学習後
4.1 スパース MoE モデルのための安定した混合精度強化学習
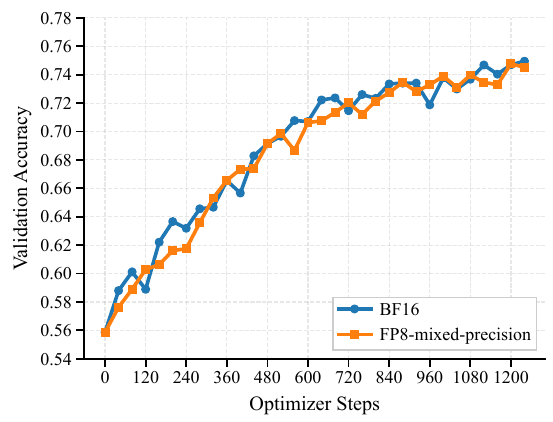
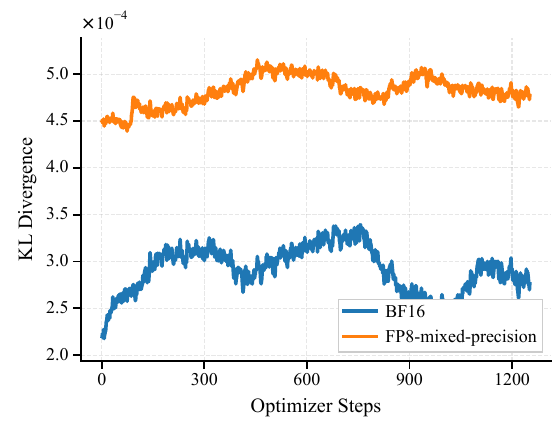
FP8 vs BF16:RLで混合精度が難しい理由
ニューラルネットワークは通常BF16(16ビットbfloat)で学習しメモリを節約しながら十分な数値精度を保ちます。FP8(8ビット浮動小数点)はメモリをさらに半分にしますが、数値的感度が大幅に高くなります。RLでは、学習エンジン(XTuner)と推論/ロールアウトエンジン(LMDeploy)が同じ入力に対して同一の確率を出力する必要があるため、これが重要です。わずかな不一致でもポリシーの乖離として蓄積され、学習が不安定になります。本論文の主な貢献は、数値的に敏感な演算(RMSNorm、ソフトマックス)を両エンジンで揃え、ロールアウト時のエキスパートルーティング決定を記録・再生し、残りのポリシー不一致に重要度サンプリング補正を適用するという一連の修正です。
トリリオンパラメータの MoE モデルへの強化学習の適用は、大きなメモリの課題をもたらします。Intern-S1-Pro は Intern-S1 よりもエキスパートの数が 4 倍ですが、FP8 量子化を RL フェーズで使用し、パフォーマンスを維持するための包括的な安定化フレームワークを実装しています。
- 演算子レベルの精度調整: 数学的に敏感なコンポーネント (RMSNorm、ルーターソフトマックス、位置エンべディング) において、LMDeploy ロールアウトエンジンと XTuner トレーニングエンジンの間の精度ギャップを削減。
- ロールアウトルーターのリプレイ: エキスパートのルーティングインデックスは、ロールアウト中に各層で記録され、ポリシー更新中にリプレイされ、エキスパートの選択の一貫性を確保。
- ターゲット混合精度: エキスパートの線形層は FP8 に量子化され、エキスパートではないコンポーネントは BF16 のまま、ロジ確率の忠実度を保つために FP32 の LM ヘッドを使用。
- デュアル重要サンプリング: トレーニングと推論の不一致のキャリブレーションとオフポリシーバイアスの補正を行うように変更された REINFORCE オブジェクティブ。
RL オブジェクティブ
デュアル重要サンプリングを使用した変更された REINFORCE 損失:
マスキング関数: M(ρi,t; α,β) = ρi,t if α < ρi,t < β, else 0
アドバンテージ推定: Âi,t = Ri − bi, bi = (1/(G−1)) ∑j≠i Rj
5. 評価
5.1 評価設定
| 推論 | 非推論 | |
|---|---|---|
| max tokens | 65,536 | 32,768 |
| temperature | 0.8 | 0 |
| top_p | 0.95 | 1.0 |
| top_k | 50 | 1 |
5.2 ベンチマーク
科学:
SciReasoner
SFE
SmolInstruct
MatBench
Mol-Instructions
MicroVQA
Biology-Instruction
XLRS-Bench
MSEarth-MCQ
一般:
MMMU-Pro
MMLU-Pro
AIME-2025
IMO-Answer-Bench
RefCOCO-avg
IFBench
OCRBench V2
SArena
LCB V6
GAIA
τ²-Bench
ScreenSpot V2
5.3 主要な結果
Intern-S1-Proは、オープンソースモデルの最上位レベルで非常に優れた機能を実証しています。科学評価では、Gemini-3-ProやGPT-5.2などのプロプライエタリモデルを複数のベンチマークで大幅に上回っています。
表 2: 科学と一般的なベンチマークにわたる包括的なパフォーマンス比較。太字 = 最高スコア、下線 = 2番目に高いスコア。
Intern-S1-Pro
1T-A22B
Qwen3-VL-235B
235B-A22B
Kimi-K2.5
1T-A32B
GPT-5.2
Gemini-3-Pro
科学タスク
SciReasoner 科学的推論
55.5 11.9 15.3 13.6 14.7
SFE 科学マルチモーダタスク
52.7 41.4 53.7 47.5 58.9
SmolInstruct 小分子
74.8 36.6 53.5 48.2 58.3
MatBench 材料物性予測
72.8 49.7 60.0 53.6 64.9
Mol-Instructions 生体分子指示
48.8 8.9 20.0 12.3 34.6
MicroVQA 生物学的顕微鏡
63.3 53.8 55.4 60.4 69.0
Biology-Instruction マルチオミクス配列
52.5 6.2 10.7 10.2 12.0
XLRS-Bench リモートセンシング
52.8 51.2 46.4 50.4 51.8
MSEarth-MCQ 地球科学
65.2 52.7 61.9 62.6 65.8
一般タスク
MMMU-Pro 知識と推論
72.8 69.9 78.5 79.5 81.0
MMLU-Pro 知識と推論
86.6 83.4 87.1 85.9 89.3
AIME-2025 数学推論
93.1 90.0 96.1 100.0 95.0
IMO-Answer-Bench 数学推論
77.3 72.3 81.8 86.3 81.3
RefCOCO-avg 視覚的接地
91.9 91.1 87.8 54.9 76.2
IFBench 指示追従
71.2 58.7 69.7 75.4 70.4
SArena (Icon) SVG生成
83.5 76.3 78.5 — 82.6
LCB V6 コード
74.3 72.0 85.0 87.7 86.9
GAIA (Text-Only) エージェント
77.4 47.8 79.9 71.1 75.5
τ²-Bench エージェント
80.9 57.4 76.8 76.6 85.4
ScreenSpot V2 エージェントと接地
93.6 92.8 92.4 49.4 94.7
5.4 時系列結果
Intern-S1-Proは、専用の時系列エンコーダーと動的なサブサンプリングプロセスを活用し、SciTSベンチマークの多様な科学的時系列タスクにおいて、Text LLMとVision-Language LLMの両方を大幅に上回るパフォーマンスを示しており、その有効性を検証しています。
表 3: SciTSベンチマークのサブセットの結果 (F1スコア)。
ASU01 ASU03 BIU01 BIU03
EAU01 MEU01 NEU06 PHU01 PHU04
Text LLM
GPT-4.1-mini 67.2 15.6 0.2 12.7 67.0 44.0 16.1 24.0 52.7
Gemini2.5-Flash 64.1 16.3 1.5 12.4 67.6 60.9 5.8 20.7 64.8
DeepSeek-V3 1.1 12.3 0.0 5.8 40.2 59.3 13.6 28.9 50.7
VL LLM
GPT-5-mini 65.7 18.9 0.8 17.9 67.6 30.4 13.3 21.4 47.8
Gemini2.5-Flash 61.6 15.2 0.9 8.3 72.5 64.1 11.6 22.7 59.0
Intern-S1-Pro 98.0 75.9 20.8 88.3 99.5 65.6 71.3 36.8 93.2
5.5 汎用的な大規模モデルの方が優れている場合がある:生物学の事例研究
両方のモデルは同じ基本的なデータセットでトレーニングされています。Intern-S1-Proは、より流暢なテキスト表現を特徴とするデータにアップグレードしています。結果は、より大規模で汎用的な基盤モデルが、同じ専門的なデータをより効果的に抽出し活用することを示しています。
表 4: 相同データでトレーニングされたBiology-Instruction(専門)とIntern-S1-Proの、生物学的配列タスクの比較。
データセット Biology-Instruction Intern-S1-Pro
DNA-cpd 44.54 54.60
DNA-emp 8.10 14.02
DNA-pd 58.18 82.65
DNA-tf-h 24.45 54.11
DNA-tf-m 39.91 60.80
Multi_sequence-antibody_antigen 10.26 44.76
Multi_sequence-promoter_enhancer 4.77 -1.30
Multi_sequence-rna_protein_interaction 59.01 58.51
DNA-enhancer_activity 53.28 55.16
RNA-CRISPROnTarget 3.77 15.69
Protein-Fluorescence 2.57 78.14
Protein-Stability 60.25 60.82
Protein-Thermostability 45.07 59.56
RNA-Isoform 59.06 82.95
RNA-MeanRibosomeLoading 47.64 52.41
RNA-ProgrammableRNASwitches 26.65 33.97
RNA-Modification 63.09 57.77
Protein-Solubility 63.02 67.60
RNA-NoncodingRNAFamily 4.77 34.50
Protein-FunctionEC 19.79 72.70
Multi_sequence-sirnaEfficiency 56.31 62.05
AVGスコア 39.24 52.45
Intern-S1-Proは、同じデータでトレーニングされた専用モデルよりも、+13.2のavgスコアで上回っています。これは、トリリオン規模の汎用的なトレーニングが、相乗効果を通じて同じ特殊なデータをより効果的に活用できることを示しています。
なぜ大きな汎用モデルが小さな専門モデルに勝るのか?
従来の常識では、専門モデルはニッチな分野でジェネラリストを上回るはずです(無関係なデータへの過学習を避けられるため)。しかしこの結果はその常識に異議を唱えています:Intern-S1-Proは生物学と一般データの両方で訓練されているにもかかわらず、同じ生物学的データを使った専用Biology-Instructionモデルを大幅に上回っています(平均39.24 vs 52.45)。最も可能性の高い理由は、1兆規模では、小さなモデルの「忘却」トレードオフなしにドメインのパターンの全多様性をマスターする十分な容量があることです。クロスドメイン転移(物理学→タンパク質折りたたみ、化学→分子生物学)も貢献しています。本論文はこれを「Specializable Generalist」と呼びます。汎用的で転移可能でありながら、専門化できるほど大きい、という意味です。
6. 結論
本レポートでは、科学的発見におけるAIの最前線を推進するために設計された、数兆パラメータの科学的多様性基盤モデルであるIntern-S1-Proをご紹介しました。Intern-S1の強力な基盤をさらに発展させ、革新的なエキスパート拡張戦略とグループルーティングを組み合わせることで、モデルを拡張しました。このアーキテクチャの革新は、デバイス間の効率的な負荷分散を保証するだけでなく、大規模なMoEモデルでよく見られるエキスパートの均質化やトレーニングの不安定性などのリスクを軽減し、トレーニングの安定性を大幅に向上させます。
モデルの科学的理解をさらに強化するために、高品質な多肢データ6兆トークンを用いた継続的な事前トレーニングを実施しました。このプロセスにおける重要な要素は、科学的イメージに特化した専門的なキャプションパイプラインの開発です。このパイプラインは、科学的な図に対する正確でアラインメントに重点を置いたキャプションを生成し、モデルが複雑な科学的な視覚コンテンツを解釈する能力を大幅に向上させます。
広範な評価の結果、Intern-S1-Proは、幅広い科学的ベンチマークにおいて最先端のパフォーマンスを達成し、堅牢な推論能力と深い専門知識を示しています。今後は、科学的発見の加速のために、モデルの機能をさらに専門的な科学分野に拡張していくことを目指します。
1
1兆パラメータMoEアーキテクチャ
グループルーティングによる絶対的な負荷バランスと安定した大規模トレーニングを実現した、最初の数兆パラメータの科学的多様性モデル。
2
科学的キャプションパイプライン
InternVL3.5およびCapRLによるドメイン知識を活用したキャプション生成により、PDFコーパスから収集した高品質な科学的画像-テキストデータ2700億トークンを使用。
3
数兆規模のFP8 RL
BF16と同等の品質を持つ、安定した混合精度RLにより、数兆パラメータのMoEモデルにおける効率的な強化学習を可能に。
4
汎用性と特化性の両立
特定の専門分野のモデルよりも優れた性能を発揮し、トップレベルの汎用性を維持。大規模化により、専門的なタスクに対する優れた習得能力を実現。
5.3 主要な結果
Intern-S1-Proは、オープンソースモデルの最上位レベルで非常に優れた機能を実証しています。科学評価では、Gemini-3-ProやGPT-5.2などのプロプライエタリモデルを複数のベンチマークで大幅に上回っています。
| Intern-S1-Pro 1T-A22B |
Qwen3-VL-235B 235B-A22B | Kimi-K2.5 1T-A32B | GPT-5.2 | Gemini-3-Pro | ||
|---|---|---|---|---|---|---|
| 科学タスク | ||||||
| SciReasoner | 科学的推論 | 55.5 | 11.9 | 15.3 | 13.6 | 14.7 |
| SFE | 科学マルチモーダタスク | 52.7 | 41.4 | 53.7 | 47.5 | 58.9 |
| SmolInstruct | 小分子 | 74.8 | 36.6 | 53.5 | 48.2 | 58.3 |
| MatBench | 材料物性予測 | 72.8 | 49.7 | 60.0 | 53.6 | 64.9 |
| Mol-Instructions | 生体分子指示 | 48.8 | 8.9 | 20.0 | 12.3 | 34.6 |
| MicroVQA | 生物学的顕微鏡 | 63.3 | 53.8 | 55.4 | 60.4 | 69.0 |
| Biology-Instruction | マルチオミクス配列 | 52.5 | 6.2 | 10.7 | 10.2 | 12.0 |
| XLRS-Bench | リモートセンシング | 52.8 | 51.2 | 46.4 | 50.4 | 51.8 |
| MSEarth-MCQ | 地球科学 | 65.2 | 52.7 | 61.9 | 62.6 | 65.8 |
| 一般タスク | ||||||
| MMMU-Pro | 知識と推論 | 72.8 | 69.9 | 78.5 | 79.5 | 81.0 |
| MMLU-Pro | 知識と推論 | 86.6 | 83.4 | 87.1 | 85.9 | 89.3 |
| AIME-2025 | 数学推論 | 93.1 | 90.0 | 96.1 | 100.0 | 95.0 |
| IMO-Answer-Bench | 数学推論 | 77.3 | 72.3 | 81.8 | 86.3 | 81.3 |
| RefCOCO-avg | 視覚的接地 | 91.9 | 91.1 | 87.8 | 54.9 | 76.2 |
| IFBench | 指示追従 | 71.2 | 58.7 | 69.7 | 75.4 | 70.4 |
| SArena (Icon) | SVG生成 | 83.5 | 76.3 | 78.5 | — | 82.6 |
| LCB V6 | コード | 74.3 | 72.0 | 85.0 | 87.7 | 86.9 |
| GAIA (Text-Only) | エージェント | 77.4 | 47.8 | 79.9 | 71.1 | 75.5 |
| τ²-Bench | エージェント | 80.9 | 57.4 | 76.8 | 76.6 | 85.4 |
| ScreenSpot V2 | エージェントと接地 | 93.6 | 92.8 | 92.4 | 49.4 | 94.7 |
5.4 時系列結果
Intern-S1-Proは、専用の時系列エンコーダーと動的なサブサンプリングプロセスを活用し、SciTSベンチマークの多様な科学的時系列タスクにおいて、Text LLMとVision-Language LLMの両方を大幅に上回るパフォーマンスを示しており、その有効性を検証しています。
| ASU01 | ASU03 | BIU01 | BIU03 | EAU01 | MEU01 | NEU06 | PHU01 | PHU04 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| Text LLM | ||||||||||
| GPT-4.1-mini | 67.2 | 15.6 | 0.2 | 12.7 | 67.0 | 44.0 | 16.1 | 24.0 | 52.7 | |
| Gemini2.5-Flash | 64.1 | 16.3 | 1.5 | 12.4 | 67.6 | 60.9 | 5.8 | 20.7 | 64.8 | |
| DeepSeek-V3 | 1.1 | 12.3 | 0.0 | 5.8 | 40.2 | 59.3 | 13.6 | 28.9 | 50.7 | |
| VL LLM | ||||||||||
| GPT-5-mini | 65.7 | 18.9 | 0.8 | 17.9 | 67.6 | 30.4 | 13.3 | 21.4 | 47.8 | |
| Gemini2.5-Flash | 61.6 | 15.2 | 0.9 | 8.3 | 72.5 | 64.1 | 11.6 | 22.7 | 59.0 | |
| Intern-S1-Pro | 98.0 | 75.9 | 20.8 | 88.3 | 99.5 | 65.6 | 71.3 | 36.8 | 93.2 | |
5.5 汎用的な大規模モデルの方が優れている場合がある:生物学の事例研究
両方のモデルは同じ基本的なデータセットでトレーニングされています。Intern-S1-Proは、より流暢なテキスト表現を特徴とするデータにアップグレードしています。結果は、より大規模で汎用的な基盤モデルが、同じ専門的なデータをより効果的に抽出し活用することを示しています。
| データセット | Biology-Instruction | Intern-S1-Pro |
|---|---|---|
| DNA-cpd | 44.54 | 54.60 |
| DNA-emp | 8.10 | 14.02 |
| DNA-pd | 58.18 | 82.65 |
| DNA-tf-h | 24.45 | 54.11 |
| DNA-tf-m | 39.91 | 60.80 |
| Multi_sequence-antibody_antigen | 10.26 | 44.76 |
| Multi_sequence-promoter_enhancer | 4.77 | -1.30 |
| Multi_sequence-rna_protein_interaction | 59.01 | 58.51 |
| DNA-enhancer_activity | 53.28 | 55.16 |
| RNA-CRISPROnTarget | 3.77 | 15.69 |
| Protein-Fluorescence | 2.57 | 78.14 |
| Protein-Stability | 60.25 | 60.82 |
| Protein-Thermostability | 45.07 | 59.56 |
| RNA-Isoform | 59.06 | 82.95 |
| RNA-MeanRibosomeLoading | 47.64 | 52.41 |
| RNA-ProgrammableRNASwitches | 26.65 | 33.97 |
| RNA-Modification | 63.09 | 57.77 |
| Protein-Solubility | 63.02 | 67.60 |
| RNA-NoncodingRNAFamily | 4.77 | 34.50 |
| Protein-FunctionEC | 19.79 | 72.70 |
| Multi_sequence-sirnaEfficiency | 56.31 | 62.05 |
| AVGスコア | 39.24 | 52.45 |
なぜ大きな汎用モデルが小さな専門モデルに勝るのか?
従来の常識では、専門モデルはニッチな分野でジェネラリストを上回るはずです(無関係なデータへの過学習を避けられるため)。しかしこの結果はその常識に異議を唱えています:Intern-S1-Proは生物学と一般データの両方で訓練されているにもかかわらず、同じ生物学的データを使った専用Biology-Instructionモデルを大幅に上回っています(平均39.24 vs 52.45)。最も可能性の高い理由は、1兆規模では、小さなモデルの「忘却」トレードオフなしにドメインのパターンの全多様性をマスターする十分な容量があることです。クロスドメイン転移(物理学→タンパク質折りたたみ、化学→分子生物学)も貢献しています。本論文はこれを「Specializable Generalist」と呼びます。汎用的で転移可能でありながら、専門化できるほど大きい、という意味です。
6. 結論
本レポートでは、科学的発見におけるAIの最前線を推進するために設計された、数兆パラメータの科学的多様性基盤モデルであるIntern-S1-Proをご紹介しました。Intern-S1の強力な基盤をさらに発展させ、革新的なエキスパート拡張戦略とグループルーティングを組み合わせることで、モデルを拡張しました。このアーキテクチャの革新は、デバイス間の効率的な負荷分散を保証するだけでなく、大規模なMoEモデルでよく見られるエキスパートの均質化やトレーニングの不安定性などのリスクを軽減し、トレーニングの安定性を大幅に向上させます。
モデルの科学的理解をさらに強化するために、高品質な多肢データ6兆トークンを用いた継続的な事前トレーニングを実施しました。このプロセスにおける重要な要素は、科学的イメージに特化した専門的なキャプションパイプラインの開発です。このパイプラインは、科学的な図に対する正確でアラインメントに重点を置いたキャプションを生成し、モデルが複雑な科学的な視覚コンテンツを解釈する能力を大幅に向上させます。
広範な評価の結果、Intern-S1-Proは、幅広い科学的ベンチマークにおいて最先端のパフォーマンスを達成し、堅牢な推論能力と深い専門知識を示しています。今後は、科学的発見の加速のために、モデルの機能をさらに専門的な科学分野に拡張していくことを目指します。
1兆パラメータMoEアーキテクチャ
グループルーティングによる絶対的な負荷バランスと安定した大規模トレーニングを実現した、最初の数兆パラメータの科学的多様性モデル。
科学的キャプションパイプライン
InternVL3.5およびCapRLによるドメイン知識を活用したキャプション生成により、PDFコーパスから収集した高品質な科学的画像-テキストデータ2700億トークンを使用。
数兆規模のFP8 RL
BF16と同等の品質を持つ、安定した混合精度RLにより、数兆パラメータのMoEモデルにおける効率的な強化学習を可能に。
汎用性と特化性の両立
特定の専門分野のモデルよりも優れた性能を発揮し、トップレベルの汎用性を維持。大規模化により、専門的なタスクに対する優れた習得能力を実現。