
RealRestorer モデル
オープンソースの、実世界の画像修復モデルであり、最先端の性能を達成し、クローズドソースのシステムと比較して高い性能を発揮します。Step1X-Edit をベースに、9種類の劣化タスクでファインチューニングされています。

画像修復は、自動運転や物体検出などの下流タスクにとって非常に重要です。しかし、既存の修復モデルは、トレーニングデータの規模と分布によって制限され、現実世界のシナリオへの汎化性能が低いことがよくあります。最近、大規模な画像編集モデルは、修復タスクにおいて優れた汎化能力を示しており、特にNano Banana Proのようなクローズドソースモデルは、画像を修復しながら一貫性を保つことができます。しかし、そのような大規模な汎用モデルで高い性能を達成するには、大量のデータと計算コストが必要です。 この問題を解決するために、9つの一般的な現実世界の劣化タイプをカバーする大規模なデータセットを構築し、最先端のオープンソースモデルをトレーニングすることで、クローズドソースの代替モデルとの差を縮めました。 さらに、464枚の現実世界の劣化画像を含む、劣化除去と一貫性維持に焦点を当てた評価指標であるRealIR-Benchを導入しました。広範な実験により、当社のモデルがオープンソース手法の中で最も優れた性能を発揮し、最先端の結果を達成することが示されました。実世界の画像修復がなぜ難しいのか?
多くの修復モデルは合成劣化(クリーン画像にガウスぼかしをかけるなど)で訓練され、同じ合成テストセットで評価されます。実世界の劣化(カメラブレ、SNSによる圧縮、屋外のもや)は合成パイプラインでは完全に再現できません。この合成→実世界のドメインギャップにより、ベンチマークでPSNR最高値を達成したモデルが実写真では目に見えて失敗することがあります。
オープンソースの、実世界の画像修復モデルであり、最先端の性能を達成し、クローズドソースのシステムと比較して高い性能を発揮します。Step1X-Edit をベースに、9種類の劣化タスクでファインチューニングされています。
9種類の劣化を網羅する、高品質な劣化合成パイプラインです。165万以上のペアになった学習サンプルを含み、合成データと実世界の劣化データを組み合わせ、詳細なノイズモデリングとセグメントを意識した摂動を行います。
9種類の劣化カテゴリーに分類された、464枚の実世界の劣化画像を含む新しいベンチマークです。劣化除去能力とコンテンツの一貫性維持の両方を測定する、カスタマイズされた非参照評価指標を使用しています。
RealRestorer は、Diffusion in Transformer (DiT) をベースとした、実用的な汎用画像編集フレームワークである Step1X-Edit をファインチューニングします。このモデルは、QwenVL テキストエンコーダーを使用して、ノイズ除去パスに高レベルのセマンティック情報を注入し、セマンティック情報とノイズ、および条件付き入力画像を処理するためのデュアルストリーム設計を採用しています。参照画像と出力画像はどちらも Flux-VAE を使用してエンコードされます。
従来の拡散モデルはU-Netをノイズ除去ネットワークに使用します。DiTはこれをVision Transformerに置き換え、画像をパッチに分割し、位置埋め込みを追加し、トランスフォーマーの自己注意ブロックがノイズのあるパッチを段階的に洗練します。トランスフォーマーはモデル規模に対してより良くスケールし、マルチモーダル条件付け(テキスト・参照画像)との統合が優れています。そのためFLUX、SD3、Step1Xなどの最新フロンティア画像モデルは全てDiTバックボーンを採用しています。
トレーニングは、2段階で行われます。
すべての実験は、8 台の NVIDIA H800 GPU で行われます。トレーニング全体のプロセスはおよそ 1 日かかります。
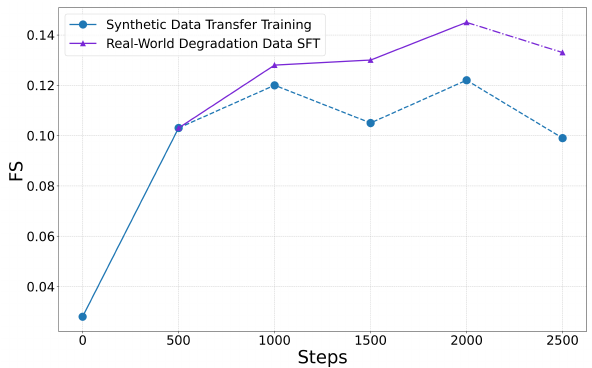
このグラフは、トレーニングステップ数ごとの RealIR-Bench での Final Score (FS) のパフォーマンスを示しています。Transfer Training Stage (青) では、モデルは基本的な修復能力を急速に獲得し、約 2,000 ステップで FS ≈ 0.122 に達した後、合成データの多様性の制限により低下します。
実世界のデータを使用した Supervised Fine-tuning Stage (紫) は、Transfer Training のピークをすぐに上回り、改善を続け、約 2,500 ステップで FS ≈ 0.145 に達します。このポイントを超えると、実世界のデータへの過学習を避けるために、早期終了を行います。
Progressively-Mixed トレーニング戦略(合成データと実データを 2:8 の比率で組み合わせる)は、過学習を防ぎながら、タスク間のロバスト性を維持します。アブレーションによって、この戦略を削除すると FS が 0.004 ポイント低下することが確認されました。
従来の画像修復ベンチマークは、主に合成されたノイズを含む単一の劣化タスクに焦点を当てており、現実世界のアプリケーションにおけるモデルの性能を評価するには不十分です。現実世界の劣化条件下での修復を適切に評価するために、我々はRealIR-Benchを構築しました。
修復の効果とコンテンツの忠実性を評価するために、2つの補完的な指標を使用します。
FS = 0.2 × (1 − LPS) × RS
FSは、修復の改善とコンテンツの保存の両方を総合的に反映しています。どちらかの側面でパフォーマンスが低いと、全体的なスコアが低下します。
PSNR/SSIMとは異なり、RealIR-Benchは、クリーンな参照ペアを使用せずに、本物の現実世界の画像で評価を行います。これにより、修復モデルのより実践的で包括的な評価が可能になります。
PSNRとSSIMはどちらも比較用のクリーン参照画像を必要とします。実世界の劣化写真にはそのような参照が存在しません。また、劣化が軽微なら入力をそのまま返すだけで高いPSNRが得られます。RealIR-BenchのVLMベースのRestoration Scoreは劣化が実際に除去されたかを直接判定し、LPIPSはコンテンツが幻覚・改変されていないかを確認します。

LPIPSは0(入力と同一)〜1(完全に異なる)の範囲。(1-LPS)はコンテンツ保存を報酬として与えます。RSはVLMによる劣化除去スコア(0〜5)です。積の形のため両方が良くなければならない:劣化を全部除去してもコンテンツが歪めば低(1-LPS)でペナルティ、コンテンツ完全保存でも何もしなければ低RSでペナルティ。係数0.2は典型的なモデルスコアが0.1〜0.15程度になるよう正規化しています。
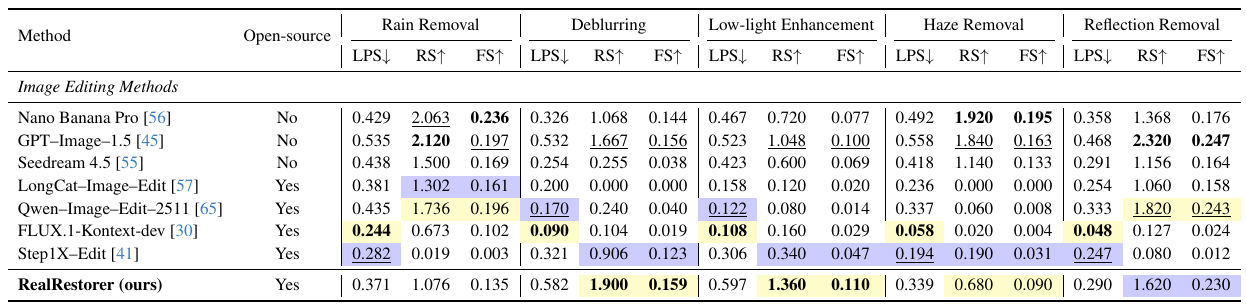
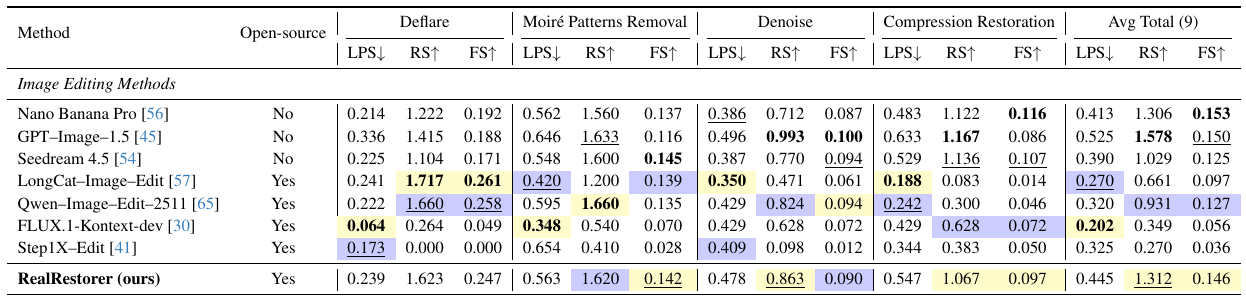
RealRestorer は、RealIR-Bench において、すべてのオープンソースモデルの中で 1位 を獲得しました (9タスクの平均で FS = 0.146)。 Nano Banana Pro (FS = 0.153) との差をわずか 0.007ポイント にまで縮め、 主要なクローズドソースの商用システムと遜色ない性能を達成しました。





提案された二段階のトレーニング戦略の貢献度を検証するために、著者らは、合成劣化データのみ、実世界の劣化データのみ、そして提案された完全な戦略を使用してモデルをトレーニングしました。
二段階の段階的混合戦略は、修復能力とコンテンツの一貫性をバランスさせるための鍵であり、より視覚的に安定し、一貫性のある修復結果をもたらします。
本稿では、複雑な現実世界の画像修復のための堅牢なオープンソース画像編集モデルである RealRestorer を紹介します。 合成データと現実データのギャップを縮小するために、合成データと、ノイズ除去された現実データのペアを組み合わせた、段階的な混合学習戦略と、包括的なデータ生成パイプラインを提案します。
さらに、本物の劣化画像を用いた、現実世界の画像修復のための VLM (Vision-Language Model) ベースの評価フレームワークを備えた、非参照ベンチマークである RealIR-Bench を発表します。 広範な実験により、RealRestorer が 9 つの画像修復タスクにおいて、オープンソースの最先端の性能を達成し、主要なクローズドソースの商用システムと比較して、結果が非常に類似していることが示されました。また、未知の劣化に対しても優れた汎化能力を示しています。
本稿で紹介したモデル、データ生成パイプライン、およびベンチマークは、現実世界の画像修復に関する今後の研究を支援するために公開します。
拡散モデルはランダムノイズから段階的にノイズを除去して画像を生成します。各ステップでDiTバックボーン(FLUXスケールで約40億パラメータ)を1回通過させます。28ステップ×1回フォワードパス=シングルステップモデルの約28倍のコスト。小さな専門的修復器(NAFNetやRestormerなど)は1回のパスで直接回帰を解きます。トレードオフ:拡散モデルはよりリアルなテクスチャを生成し汎化性が高いですが、シングルステップネットワークより10〜50倍遅くなります。
ベースモデルは 28 段階のノイズ除去プロセスを使用しており、より小さな専門的なネットワークと比較して、計算コストが高くなる可能性があります。 また、強い意味的な曖昧さがある場合 (例: 鏡に映った自撮り)、モデルはシーンの本来の内容と、意図しない反射を区別できない場合があります。 さらに、モデルは、信頼できる画素情報がほとんど存在しない、極端な劣化に対しては、うまく機能しない場合があります。