
事前学習
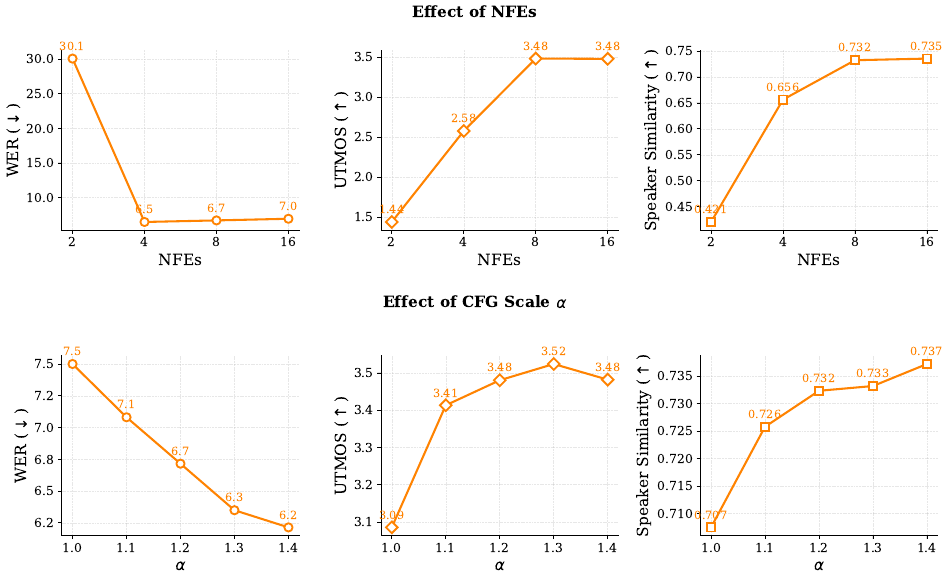
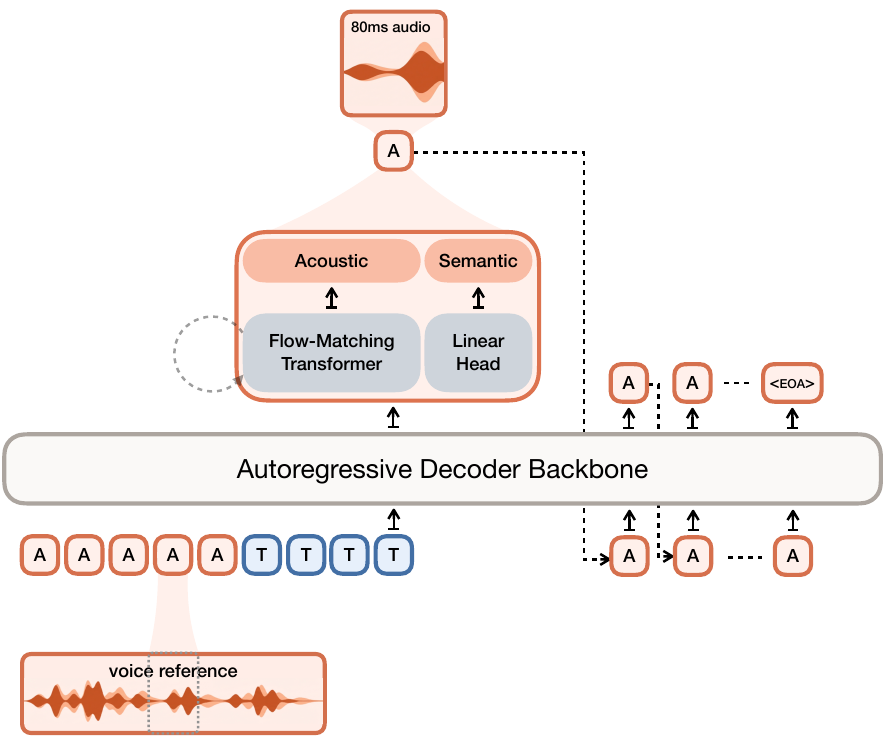
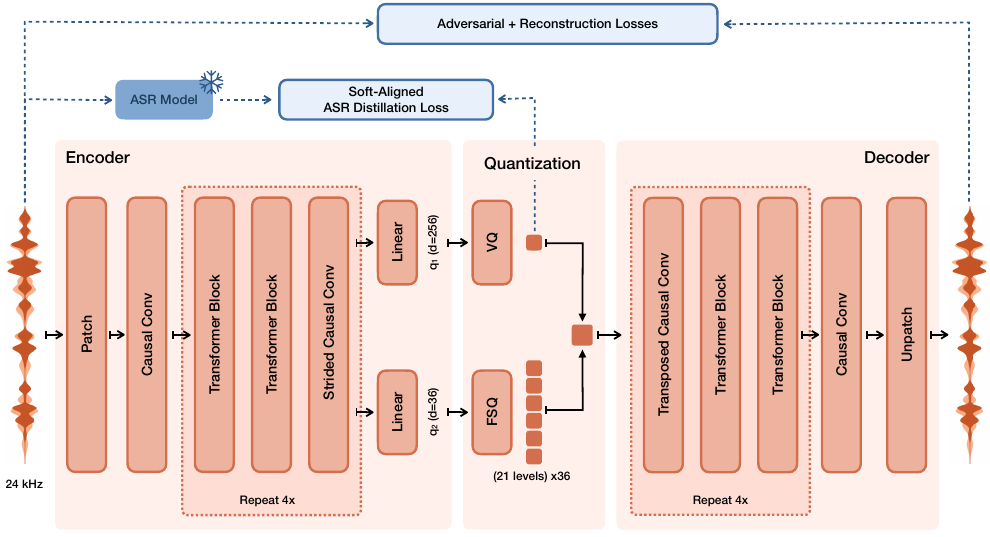
Voxtral Mini Transcribeから得られたペアになった音声と擬似ラベル付きのテキストデータでトレーニングされています。 各サンプルは、(A₁, T₂, A₂)というタプルで構成されます。A₁は音声参照、T₂はA₂のテキスト(生成対象)、A₂は音声です。
損失は、A₂のトークンに対してのみ計算されます。意味トークンに対してはクロスエントロピー、音響トークンに対してはフローマッチング損失が使用されます。 デコーダのバックボーンはMinistral 3Bから初期化され、テキスト埋め込み層は、低周波トークンに対するロバスト性を向上させるために固定されています。
音声活動検出 (VAD) は、無音フレームに対する損失を抑制します。シンプルなLLMベースのテキスト書き換えにより、正規化されたテキストと正規化されていないテキストに対するロバスト性が向上します。