😁 PixelSmile: 微細な表情編集への取り組み
*同等貢献 · †プロジェクトリーダー · ‡責任著者
1 Fudan University
2 StepFun
arXiv:2603.25728v1 [cs.CV] · 2026年3月26日
*同等貢献 · †プロジェクトリーダー · ‡責任著者
arXiv:2603.25728v1 [cs.CV] · 2026年3月26日
詳細な表情編集は、その本質的な意味的な重複によって長らく制限されてきました。この問題を解決するために、私たちは連続的な感情アノテーションを備えた Flex Facial Expression (FFE) データセットを構築し、構造的な混乱、編集精度、線形制御、および表情編集と同一性保持のトレードオフを評価するための FFE-Bench を確立しました。私たちは、完全に対称な同時学習によって表情のセマンティクスを分離する拡散フレームワークである PixelSmile を提案します。PixelSmileは、強度に関する監督とコントラスト学習を組み合わせることで、より強力で区別された表情を生成し、テキストによる潜在空間の補間を通じて、正確で安定した線形的な表情制御を実現します。広範な実験により、PixelSmileは優れた分離性と堅牢な同一性保持を実現し、連続的で制御可能で詳細な表情編集に効果的であることが確認されました。また、自然な表情のブレンドもサポートします。
「恐怖」と「驚き」はどちらも目が大きく見開かれ、眉が上がるという共通の身体的特徴を持ちます。この構造的な重複により、離散的な感情ラベルで訓練されたモデルはこれらのカテゴリを混同しがちです。「恐怖」を生成しようとしても、誤って「驚き」が生成されることがあります。PixelSmileはこれを単なるラベリングエラーではなく、表情空間における根本的な幾何学的問題として捉え、より良い分類器ではなく明示的な分離(disentanglement)を必要とするアプローチを取ります。
私たちは、表情間の構造的な意味的な重複を明らかにし、形式化しました。構造的な意味的な重複は、単なる分類エラーではなく、認識および生成的な編集タスクの失敗の主要な原因であることを示しています。
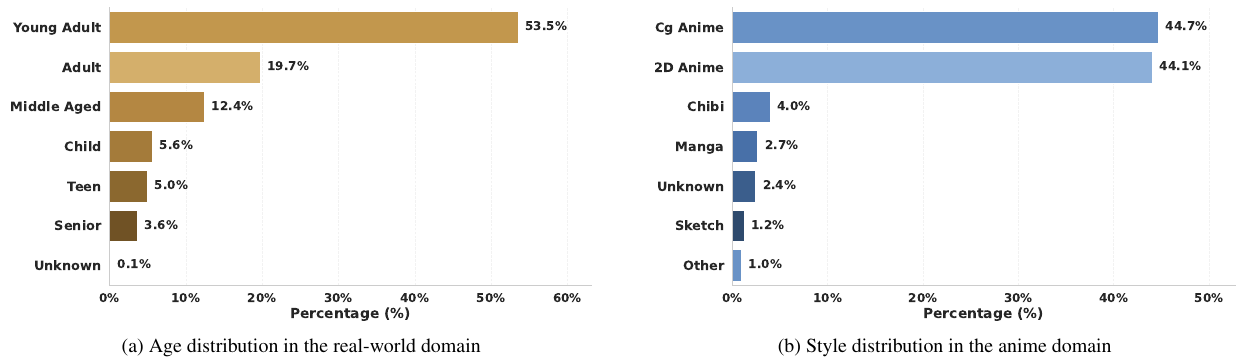
12の表情カテゴリを特徴とする大規模なクロスドメインコレクションであり、連続的な感情アノテーションが施されています。構造的な混乱、表情編集の精度、線形制御、および同一性保持のための多次元評価を行います。
完全に対称な同時学習とテキストによる潜在空間の補間を利用する、新しい拡散ベースのフレームワークです。重複する感情を効果的に分離し、分離された線形的に制御可能な表情編集を可能にします。
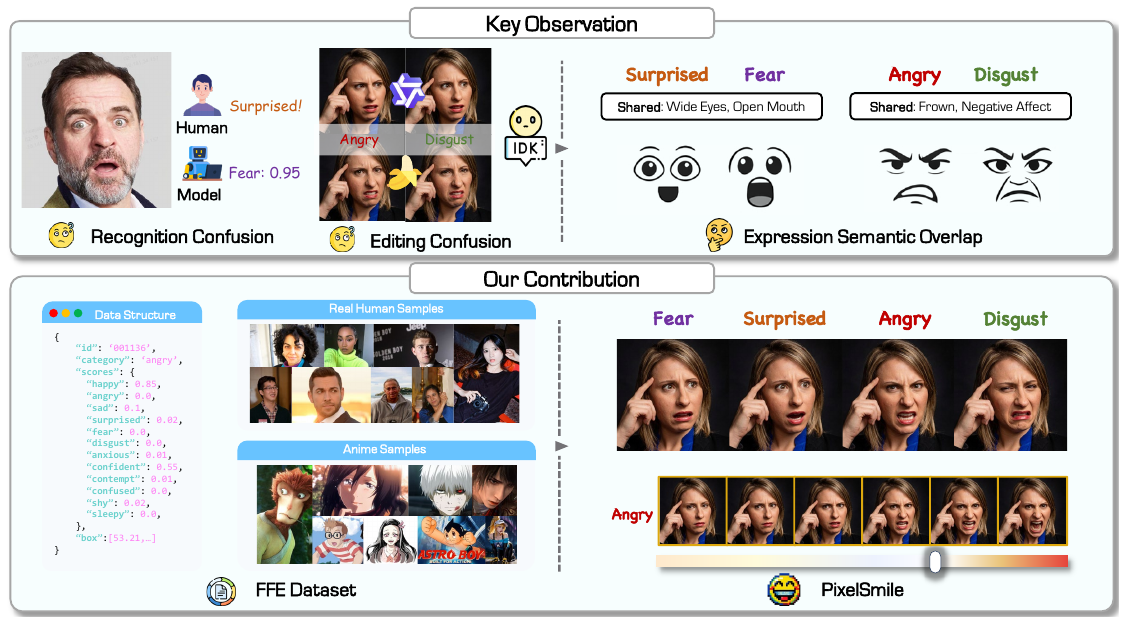
FFEは、表現の多様性、クロスドメインの網羅性、および信頼性の高いアノテーションを確保するために設計された、4段階の「収集–構成–生成–アノテーション」パイプラインによって構築されます。最終的なデータセットには、60,000枚の画像が含まれており、リアルとアニメのドメインをカバーしています。
従来の感情データセットは「幸せ」「怒り」のように単一ラベルを割り当てます。FFEでは代わりに12次元ベクトルを割り当て、各次元は[0, 1]の実数値です。例えば、ある顔は「幸せ度0.8・驚き度0.3」を同時に持てます。これによりモデルは硬い境界ではなく、滑らかな感情多様体(emotion manifold)を学習できます。
平均構造的混乱率
意味的に類似した表現間のカテゴリ間の混乱を定量化します。値が小さいほど良い。
調和編集スコア
HES = 2×SE×SID / (SE+SID)。 表情の強度とアイデンティティの保持のバランスを取ります。値が大きいほど良い。
制御線形スコア
αとVLMによって予測された強度との間のピアソン相関。 値が大きいほど、制御が予測しやすいことを示します。
表情編集の精度
生成された画像の、予測された主要な表情がターゲットの指示と一致する割合。
テキスト埋め込み空間において、線形補間を行います。
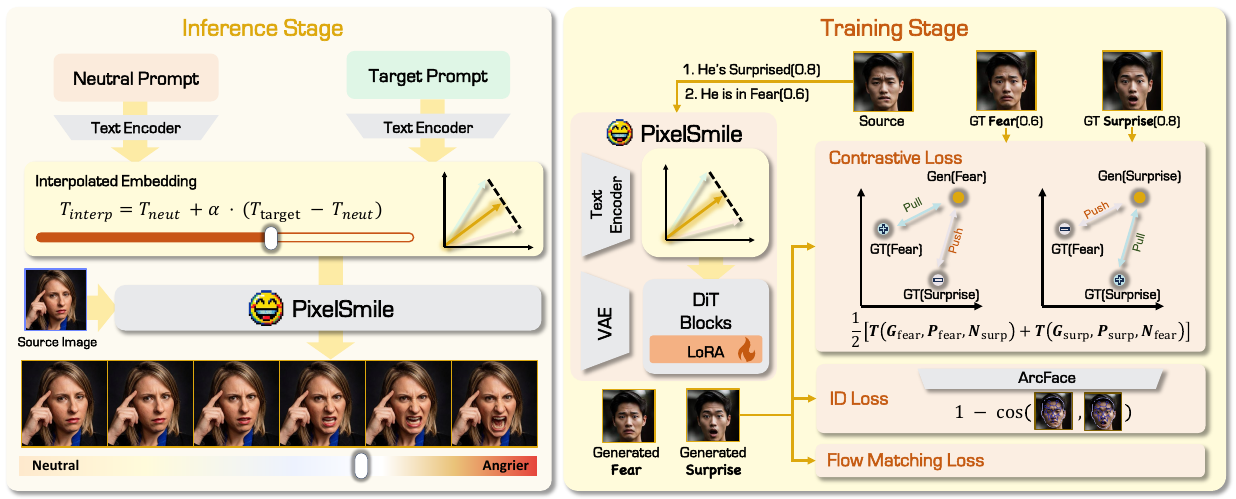
econd(α) = eneu + α · Δe, α ∈ [0, 1]
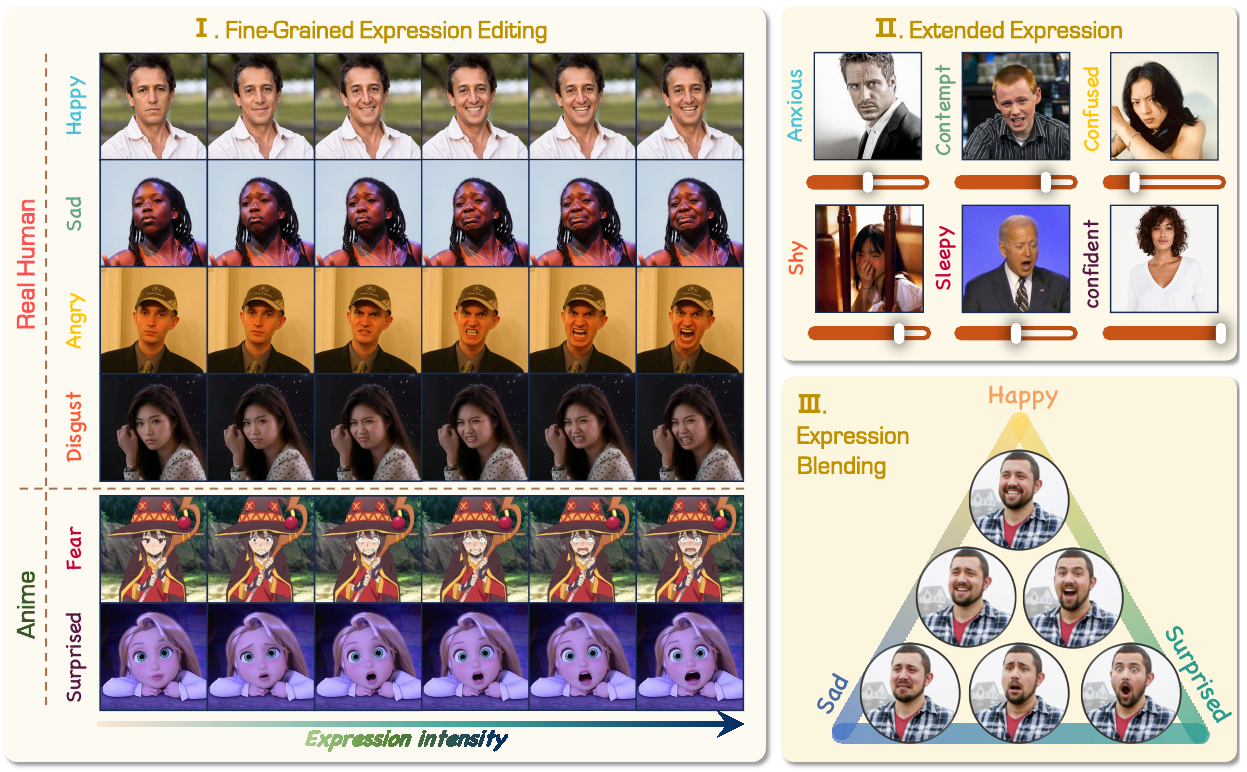
連続的な条件付き埋め込みにより、参照画像なしで、推論時に正確で滑らかな表情の操作を可能にします。 α > 1 を使用することで、より強い表情の転送を実現できます。
拡散モデルはテキスト埋め込みベクトル e で条件付けられます。PixelSmileは「中性」と「目標感情」の2つの埋め込みを計算し、条件付けベクトルを加重ブレンドします:e_neu + α × (e_target − e_neu)。α=0で表情なし、α=1で完全な目標表情、α=1.5で誇張表現になります。これはすべてモデル内部のテキスト埋め込み空間で行われるため、参照顔画像は不要です。
混乱しやすい表情ペア (Ea, Eb) をサンプリングします。対称的なコントラスティブ損失は以下の通りです。
ℒSC = ½[𝒯(Ga,Pa,Nsurp) + 𝒯(Gb,Pb,Nfear)]
InfoNCE スタイルの目的関数 (τ = 0.07) を用いて、重なり合う表情を双方向から分離します。
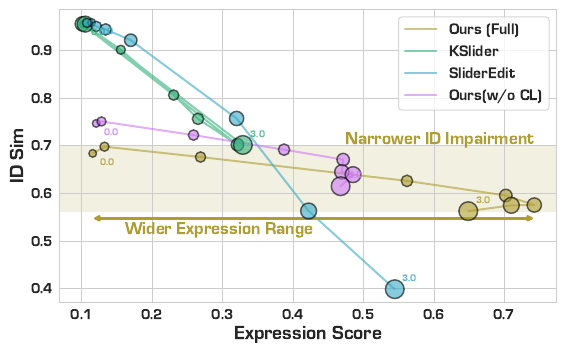
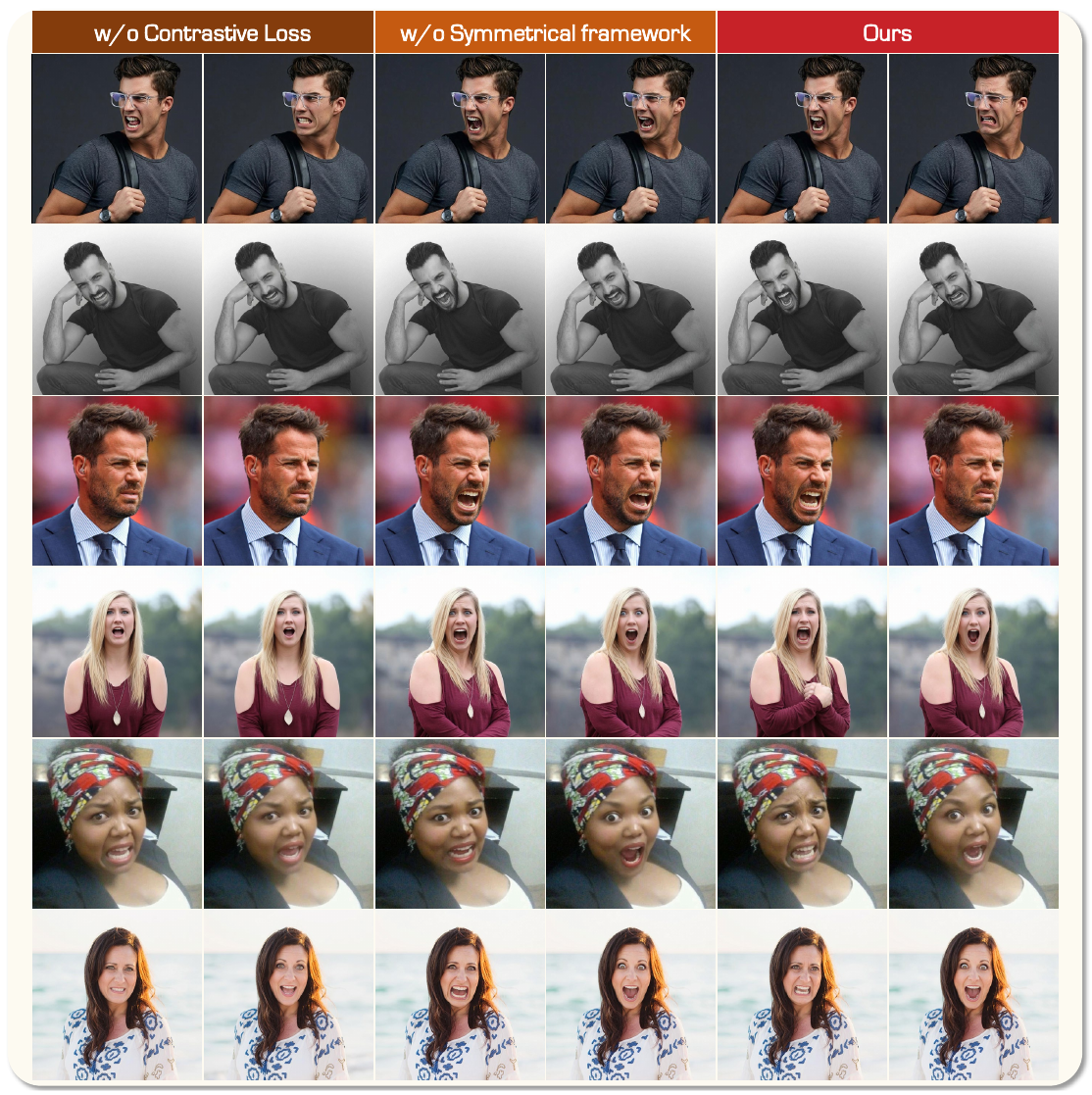
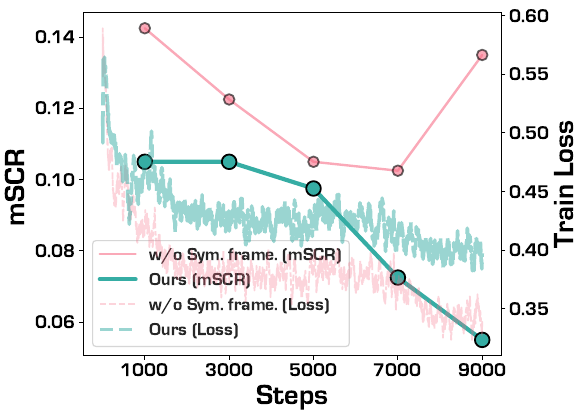
単純に「恐怖」を「驚き」から遠ざけるだけでは、恐怖の生成は改善しても驚きは恐怖と混同されたままになることがあります。対称学習では両方向を同時に最適化します:恐怖画像が驚きから離れ、かつ驚き画像も恐怖から離れるよう学習します。アブレーション実験(図8)では、対称性を除去するとコントラスティブ損失を維持していても表情の混乱が発生することが確認されています。
ArcFace を同一性エンコーダ Φarc として固定します。
ℒID = ½ Σ [1 − cos(Φarc(Gi), Φarc(Pi))]
強い表情の補間下での生体認証特徴量を安定させ、ヘアスタイルや肌のテクスチャの変化を防ぎます。
ArcFaceは顔認識モデルで、どんな顔画像も高次元埋め込みベクトルに変換し、表情に関わらず同一人物のベクトルが常に近くなるように設計されています。同一性損失は生成顔とターゲット顔のコサイン距離を最小化するため、「笑顔」への編集で意図せず髪色・肌のトーン・顔の形が変わることを防ぎます。
ℒtotal = ½(ℒaFM + ℒbFM) + λsc·ℒSC + λid·ℒID
λsc は、表情の分離と同一性の保持のトレードオフを制御します。4つの NVIDIA H200 GPU で、LoRA (rank 64, α 128) を用いて学習しました。
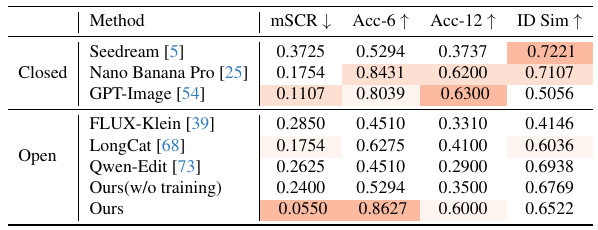
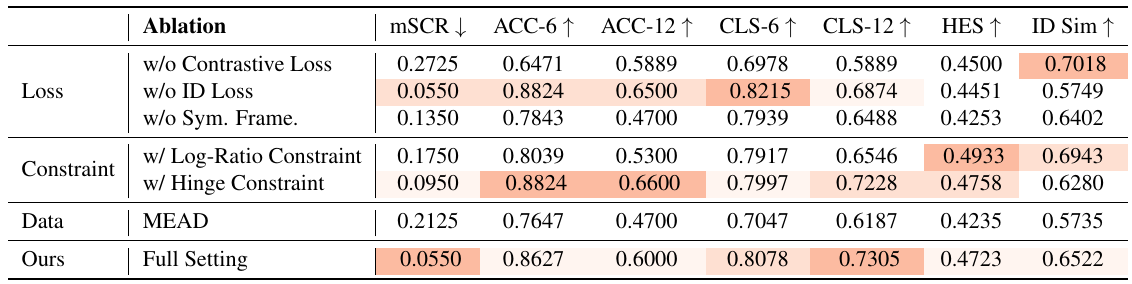
表1. 一般的な編集モデルの定量評価。PixelSmileは、mSCRが最も低く (0.0550)、Acc-6が最も高い (0.8627)。
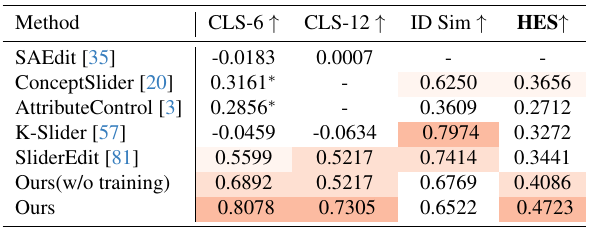
表2. 線形制御モデルの定量評価。PixelSmileは、CLS-6で最高値 (0.8078)、CLS-12で最高値 (0.7305)、HESで最高値 (0.4723) を達成。




6つの基本感情には15通りのペアがあります。「幸せ+驚き=興奮」のように意味的に整合する組み合わせは成功します。一方「嫌悪+幸せ」などは筋肉的・心理的に相反するため矛盾した結果になります。9/15が成功するという事実は、PixelSmileが幾何学的に意味のある感情多様体を学習した証拠であり、表情のブレンドは明示的に訓練されていない創発的な能力です。
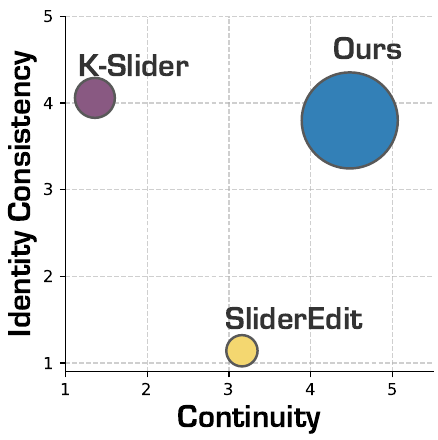
本論文では、顔の表情編集における意味的な複雑さを解決するためのフレームワークであるPixelSmileを提案します。本アプローチは、FFE(Face Expression Editing)によって定義される連続的な表情空間を用いて、離散的な教師あり学習から連続的な学習へと移行し、FFE-Benchを通じて評価することで、対称的な同時学習によって、精密で線形制御可能な編集を可能にします。広範な実験により、PixelSmileは構造的な混乱、表情の正確性、線形制御性、および同一性の維持という4つの側面において有効であることが示されています。全体として、本研究は、詳細な顔の表情編集のための標準化されたフレームワークを確立し、連続的で構成可能な顔の感情操作に関する研究を前進させます。