データ中心学習は、モデルパラメータだけでなく学習データの選択・構成・重み付けも最適化することで、大規模言語モデル(LLM)を改善する有望な方向性として注目されています。しかし既存手法は互換性のないコードベースに分散しており、再現性・公平な比較・実用的統合を阻んでいました。本論文では、LLaMA-Factory上に構築された統合データ中心動的学習フレームワークDataFlexを提案します。DataFlexは動的サンプル選択・ドメインミックス調整・サンプル重み付けの3大パラダイムをサポートし、DeepSpeed ZeRO-3を含む大規模設定にも対応しています。
従来のLLM学習は学習データを固定したままモデルパラメータを最適化します。データ中心学習はこの視点を逆転させ、データパイプライン自体を最適化の対象とします。現在のモデル状態において最も情報量の多いサンプルは何か?汎化を最大化するドメイン比率は?どの学習例により大きな勾配重みが必要か?DataFlexはこれら3つの問いを単一の学習ランの中で自動化します。
互換性のない3つのデータ中心パラダイムを単一フレームワークに統合。
YAMLの設定追加だけでLLaMA-Factoryに統合。学習コードの変更不要。
DeepSpeed ZeRO-3およびFSDP分散学習に完全対応。大規模設定でも動作。
Mistral-7BとLlama-3.2-3Bの双方でMMLU静的ベースラインを安定して上回ることを実験で確認。
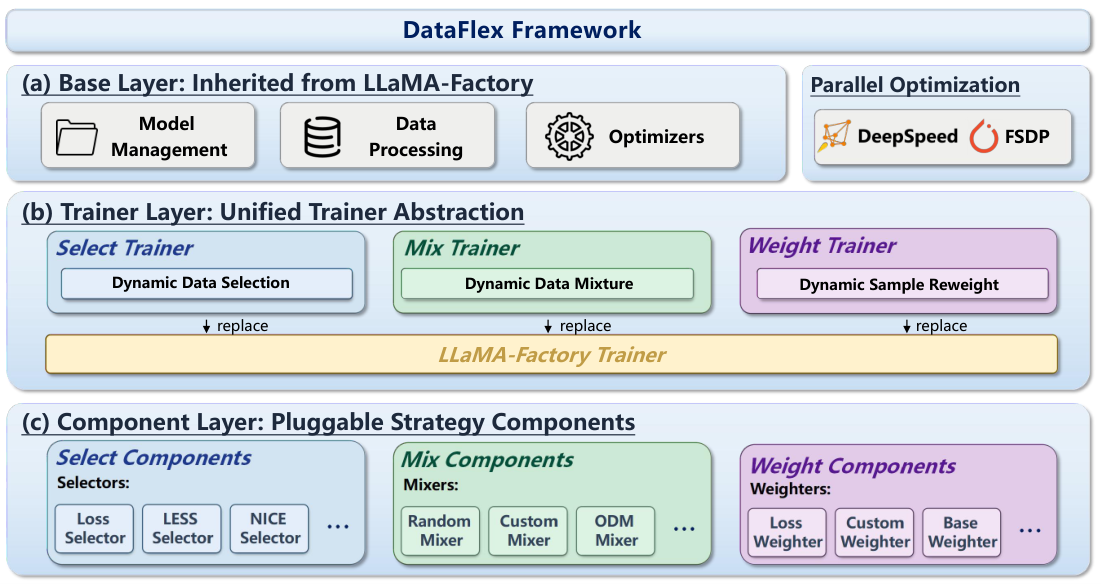
DataFlexは3層構造で設計されています:Base層はLLaMA-Factoryのモデル管理・データ処理・オプティマイザをDeepSpeed/FSPDサポートと共に継承し、Trainer層はSelectTrainer・MixTrainer・WeightTrainerの3種統合トレーナーを提供し、Component層は差し替え可能なアルゴリズムモジュールを提供します。
LLaMA-Factoryは大規模言語モデルの効率的なファインチューニングと事前学習のために広く使用されるオープンソースフレームワークです。分散学習・データセット読み込み・オプティマイザ設定のボイラープレートを抽象化し、LLaMA・Mistral・Qwen・Phiなど多数のモデルアーキテクチャをサポートします。DataFlexはLLaMA-Factoryのトレーナー基盤の上に直接構築され、その全機能を継承しつつデータ中心最適化層を追加します。
各ステップで最も情報量の多い学習サンプルを反復的に特定・選択します。DataFlexはLESS・TSDS・カスタムセレクタをサポートし、スコアリングとフィルタリングの統一インターフェースを共有します。
事前学習中にデータドメイン(例:SlimPajamaサブセット)のサンプリング比率を動的に調整します。DoReMiとODMが組み込みアルゴリズムとして利用可能です。
モデル依存の品質シグナルに基づき、勾配更新時のサンプルごとの損失重みを割り当てます。プラガブルなweighterコンポーネントでカスタム戦略を実装できます。
統合フレームワーク以前は、各研究グループが独自の学習コードベースの上にデータ中心手法を構築していました。PyTorch Lightningで構築された手法AとHugging Face Trainerで構築された手法Bを比較するには、一方を他方のコードベースに移植する(実装バグが混入する)か、インフラストラクチャの違いによって比較が交絡することを受け入れるしかありませんでした。DataFlexのプラガブルなアーキテクチャにより、すべての手法がまったく同じ学習ループ・分散学習セットアップ・データ読み込みパイプラインを共有します。結果が異なる場合、それはアルゴリズムが異なるためであり、インフラストラクチャが異なるためではありません。
DataFlexはLLaMA-Factory標準設定に追加するYAML設定ブロックで統合されます。train_type・component_name・コンポーネント固有のハイパーパラメータを設定するだけで動的データ最適化が有効になり、学習コードの変更は不要です。この例ではQwen2.5-0.5BのwikiとC4データセットへの事前学習にDoReMiドメインミックスを適用しています。
### model
model_name_or_path: Qwen2.5-0.5B
### method
stage: pt
finetuning_type: full
deepspeed: ds_z3_config.json
### dataset
dataset: wiki_demo, c4_demo
template: qwen
### train
learning_rate: 5.0e-5
num_train_epochs: 1.0
### dataflex
train_type: dynamic_mix
component_name: doremi
mixture_sample_rule: mixture
init_mixture_proportions: [0.5, 0.5]
warmup_step: 100
update_step: 200
update_times: 3
DoReMiとは?なぜドメイン比率が重要なのか?

### dataflexブロックを追加するだけで動的データ最適化が有効になります。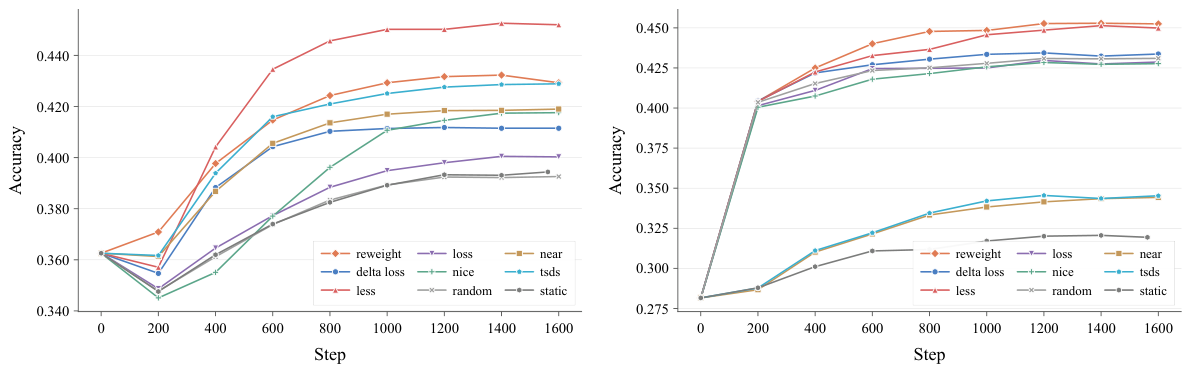
7種類の動的データ選択アルゴリズムの包括的な実験により、データ中心動的学習が静的ベースラインに対して測定可能な安定した改善をもたらすことが確認されました。7Bと3Bの両モデルスケールで改善が持続し、統合DataFlexインフラがスタンドアロン実装と比較して性能劣化を引き起こさないことを示しています。
静的学習では、その学習ステップでの実際の有用性に関わらず、データセットのすべてのサンプルが均等にモデルに影響する機会を得ます。動的選択は現在のモデル状態を使って各サンプルの期待学習価値をスコアリングします。例えばサンプルに対するモデルの内部表現の変化量や勾配シグナルの大きさを測定します。有用性の高いサンプルはより頻繁に選択され、低いものはより少なく選択されます。これは学生がすでに知っているページを再読するのではなく、まだ習得していない問題に勉強時間をより多く集中するようなものです。
MMLU(Massive Multitask Language Understanding)は、初等数学から専門的な法律・医学まで57の学術分野をカバーするベンチマークです。選択式問題でドメインをまたいだ事実知識と推論能力を評価します。包括性(57科目)・標準化(固定された評価プロトコル)・実世界の有用性との相関の高さから広く使用されています。DataFlexの実験では、ファインチューニング中のよりスマートなデータ選択がより多くを知り、より良く推論するモデルにつながるかどうかをMMLUで測定します。
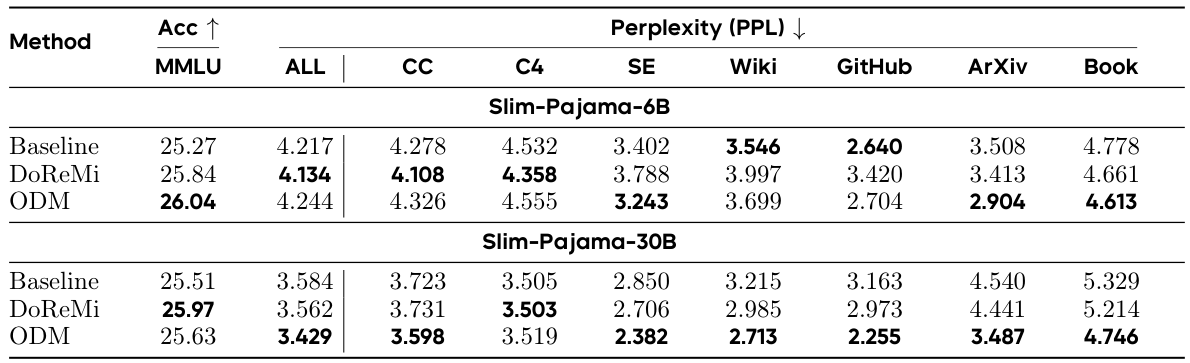
ドメインミックス最適化において、DoReMiとODMの両方がSlimPajamaデータセットでQwen2.5-1.5Bを事前学習する際に固定デフォルト比率を上回ります。6Bから30Bトークンにスケールしても効果が持続し、実用的な事前学習スケールでのアプローチの有効性を実証しています。
SlimPajamaのような言語モデル事前学習データセットは、ウィキペディア・GitHubコード・C4ウェブテキスト・書籍・ArXiv論文など複数のテキストドメインを組み合わせています。各学習バッチでの各ドメインの比率は重要なハイパーパラメータです。コードが多すぎるとモデルの自然言語能力が低下し、ウィキペディアが少なすぎると事実想起が損なわれます。DoReMi(Domain Reweighting with Minimax Optimization)は均一な比率で学習した参照モデルをベースラインとして使用し、メインモデルが最大の超過損失を持つドメインを上重みするよう学習します。これによりデータ量が少ないが重要なドメインがより多くの学習シグナルを得られます。ODM(Online Domain Mixing)は参照モデルなしで同様の適応的アプローチを実現します。
SlimPajamaはRedPajamaデータセットのクリーニング・重複排除版で、Commoncrawl・C4・GitHub・Books・ArXiv・Wikipedia・Stackexchangeの7つのドメインにわたる約6270億トークンのテキストを含みます。標準化された高品質のマルチドメインデータセットを提供することで、言語モデル事前学習戦略の公平な比較を可能にするために特別に作成されました。ドメインミックス実験では、7つの異なるドメインが異なる固有の特性とサイズを持ち、ドメイン比率の選択が非自明であるため、SlimPajamaは理想的です。以前の研究(DoReMi、ODM)もSlimPajamaを使用しており、直接比較が可能です。
パープレキシティは言語モデルが与えられたテキストにどれほど驚くかを測定します。数学的には、トークンごとの平均負の対数尤度の指数であり、スコアが低いほどモデルが実際の次のトークンに高い確率を割り当てていることを意味します。事前学習評価では、コーパスレベルのパープレキシティは学習データと同じドメインの保留テキストで測定されます。パープレキシティが低いほど、モデルが言語の統計的構造をより良く学習していることを示します。ドメインミックス実験では、パープレキシティはドメインごとに測定され(例:Wikipedia パープレキシティ、コード パープレキシティ)、ミックス最適化がすべてのドメインを改善したか、それとも一方を他方とトレードオフしたかを確認できます。
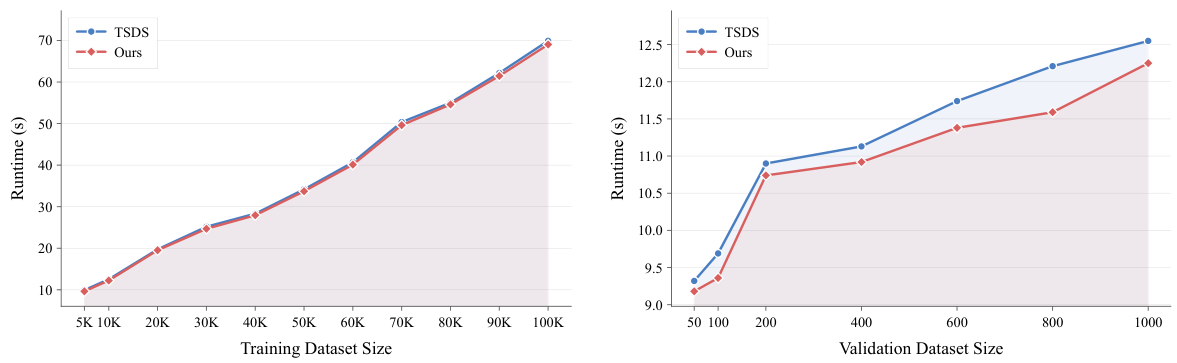
複数のアルゴリズムを単一フレームワークに統合しているにもかかわらず、DataFlexは実質的な計算オーバーヘッドを引き起こしません。TSDS元実装との比較ベンチマークでは、DataFlexはすべてのデータセットスケールでスタンドアロンの実行時間と同等か優れた結果を示しています。統合抽象化層はアルゴリズムごとのセットアップコストを分散させ、コンポーネント間でのバッファ再利用を可能にすることで、観察された効率改善をもたらします。
数十億パラメータを持つ大規模言語モデルの学習には、単一のアクセラレータが保持できる以上のGPUメモリが必要です。DeepSpeedのZeRO(Zero Redundancy Optimizer)アルゴリズムは、オプティマイザ状態・勾配・モデルパラメータをデバイス間でシャーディングすることでモデルを複数のGPUに分散します。ZeRO-3は最も積極的な分割で、3つすべてが分散され、単一のGPUには収まらないモデルをクラスタで効率的に学習できます。DataFlexのZeRO-3サポートにより、埋め込み抽出やモデル推論などの補助操作を必要とするデータ中心手法が現代のマルチGPU学習セットアップと完全に互換性を持ちます。
一部のデータ選択アルゴリズム(LESSなど)は、各サンプルの勾配がターゲットタスクのモデル性能にどれだけ影響するかを計算することで学習サンプルをスコアリングします。これは候補サンプルの勾配計算を必要とする高コストな操作です。DataFlexはこの操作をこれを必要とするすべてのアルゴリズム間で統一し、可能な限り勾配計算をキャッシュして再利用します。また、モデルパラメータが複数のGPUに分散し勾配計算前に収集が必要なDeepSpeed ZeRO-3コンテキスト内でこれを実行するエンジニアリングの複雑さも処理します。これは勾配ベースのデータ選択をスケールで実現可能にする重要なエンジニアリング貢献です。
データ中心学習は、データ品質と構成をモデルパラメータと並ぶ第一級の最適化ターゲットとして扱う新興パラダイムです。DataFlexは、この分野を阻んできた断片化(互換性のない実装を公開する異なるグループ)を取り除き、コミュニティが構築できる再現性の高い拡張可能なプラットフォームを提供します。LLaMA-Factoryの本番品質のインフラ上に構築されたDataFlexは、研究と実用的なLLM学習パイプラインの両方に対応しています。
モデル中心AIは学習データセットを固定し、モデルアーキテクチャ・損失関数・最適化アルゴリズムの改善に焦点を当てます。データ中心AIは「固定されたモデルアーキテクチャを前提として、データを改善することでパフォーマンスを向上させるにはどうすればよいか?」という問いを立てます。これにはラベルのクリーニング・重複の除去・多様なサンプルのキュレーション、そしてDataFlexのように各ステップで学習に影響するデータを動的に調整することが含まれます。モデルアーキテクチャが成熟した後は特に、データ品質の改善がアーキテクチャの調整よりも大きな効果をもたらすことが多いため、データ中心の視点が注目されています。
DataFlexは各パラダイムに抽象基底クラスを提供します:BaseSelector・BaseMixer・BaseWeighter。新しいアルゴリズムを追加するには、研究者は適切な基底クラスをサブクラス化し、必要なメソッド(通常はスコアリング関数と更新ステップ)を実装し、名前文字列でコンポーネントを登録します。YAML設定がこの名前文字列を参照してカスタムアルゴリズムを有効化します。基底クラスは分散学習・チェックポイント互換性・デバイス配置・学習ループへのフック注入など、すべてのインフラストラクチャの懸念事項を処理するため、研究者はアルゴリズムロジック自体のみを実装すればよく、通常50〜200行のPythonで実装できます。
