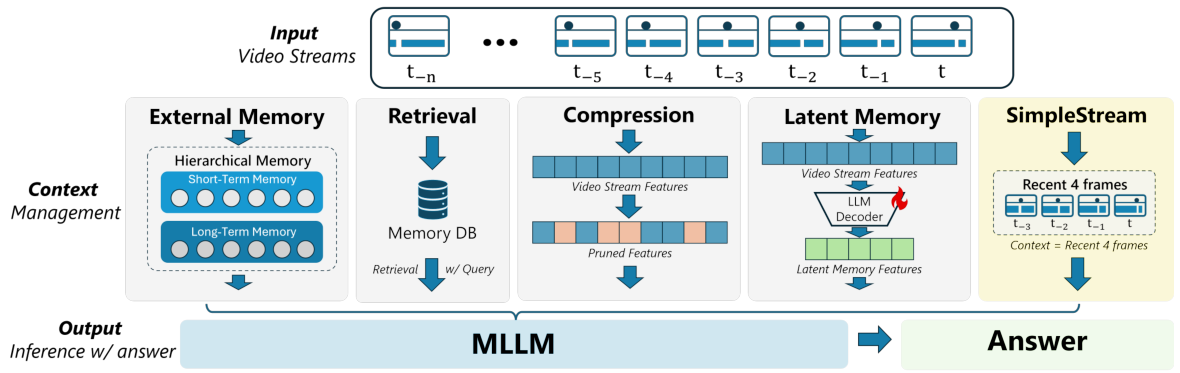
SimpleStreamとは何か?
意図的なミニマリスト設計
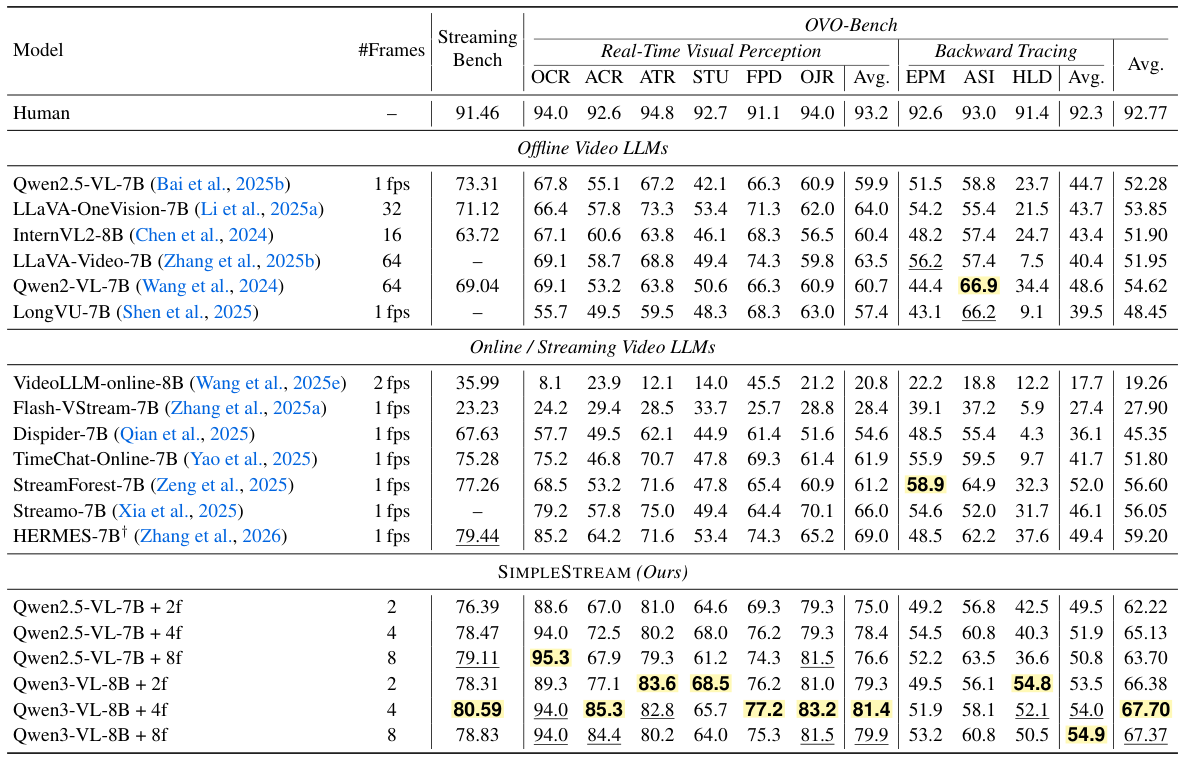
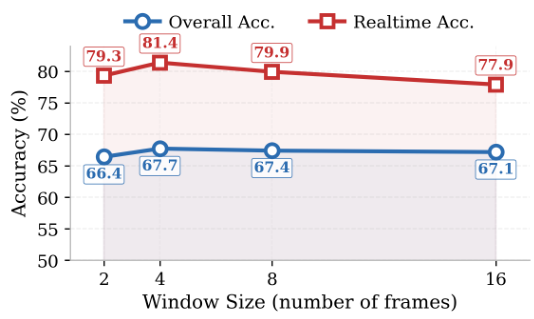
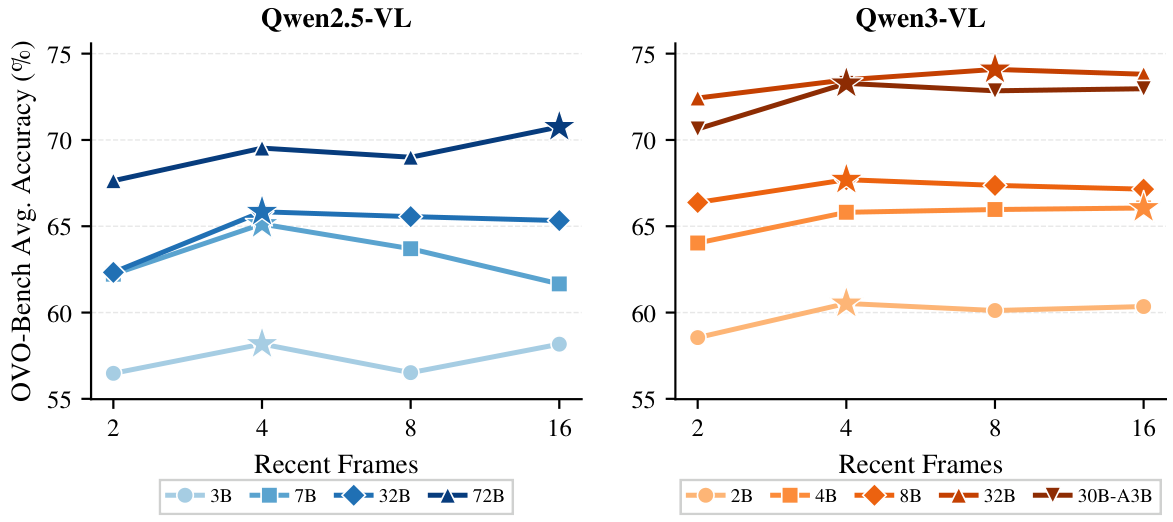
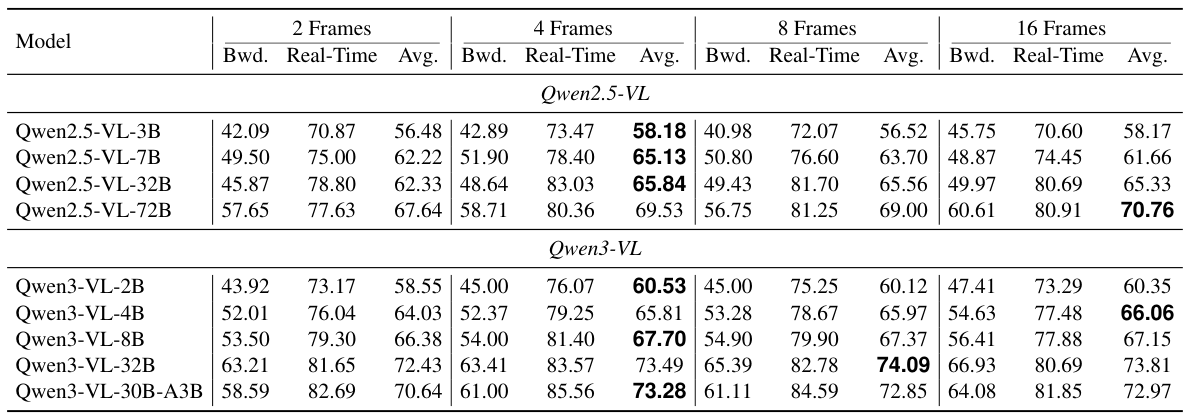
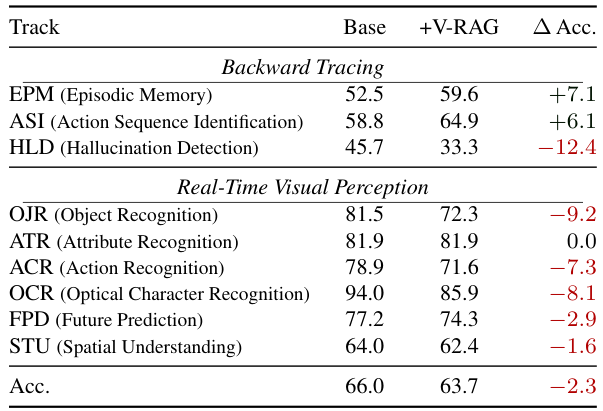
時刻tでのクエリに対して、SIMPLESTREAMは最後のNフレームとクエリテキストを基盤となるVLMに直接入力するだけです。設計は意図的に最小限:短い最近ウィンドウのみを保持し、強力なバックボーンが明確で非圧縮の直近証拠を処理します。
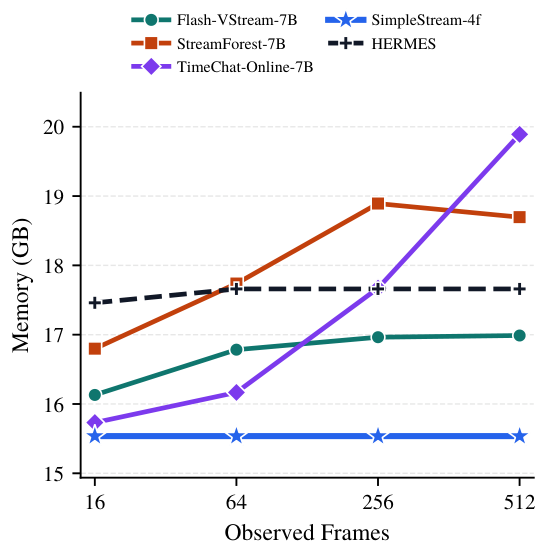
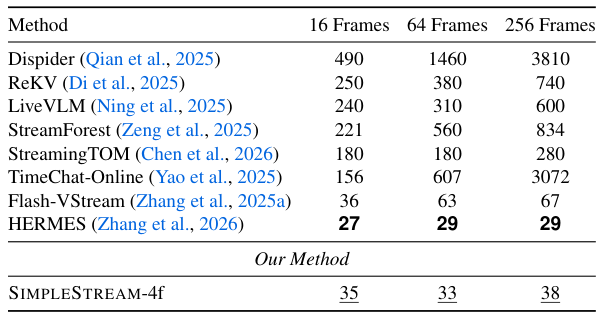
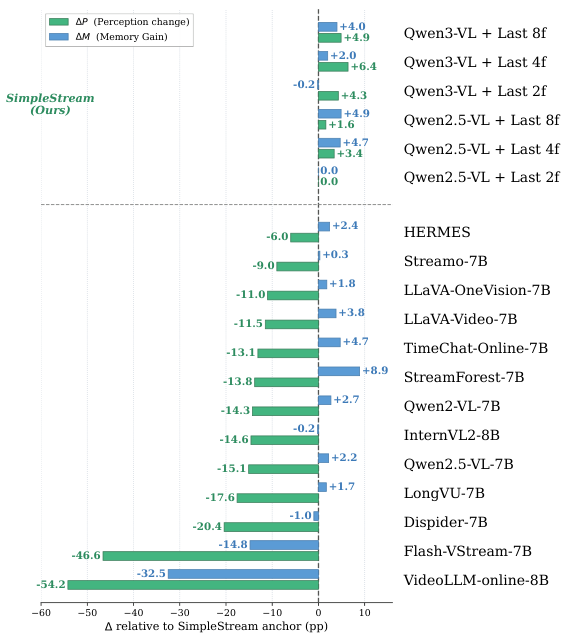
SIMPLESTREAMは、従来のストリーミングシステムが使用する追加メモリ機構を意図的に省略しています。スライディングウィンドウ外のフレームは破棄されるため、クエリごとのメモリと計算量はストリームの長さに関わらず一定に保たれます。
過去の観測を蓄積するメモリデータベースを維持する手法とは異なり、SimpleStreamは直近Nフレームより古いものを単純に忘れます。これがキーとなる洞察です:現代のVLMは既に十分強力であり、小さな窓の最近の非圧縮フレームが、大きな窓の圧縮・検索済みコンテキストを上回ります。