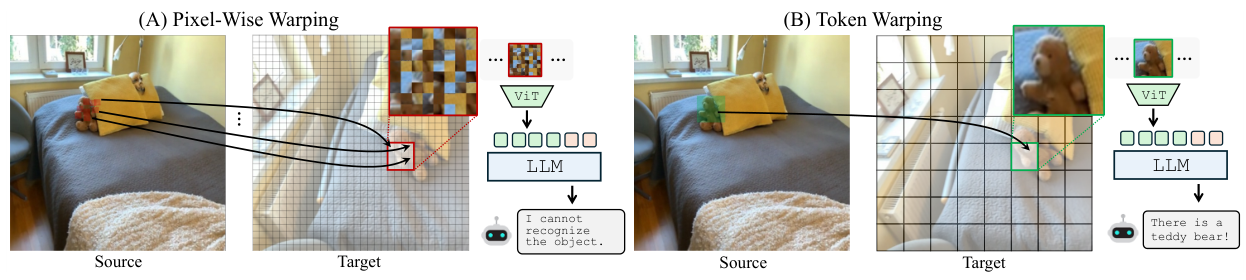
深度推定とカメラ姿勢を使用して、ソースビューからターゲット視点への画像トークン(ピクセルではない)をワーピングするトレーニング不要な手法。ピクセルレベルの手法を壊滅的に歪める深度誤差に対してロバストです。
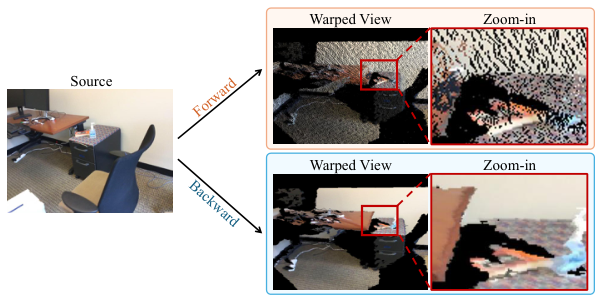
前向きと後ろ向きトークンワーピングの系統的比較により、後ろ向きワーピング(密なターゲットビューグリッドを定義してソーストークンを取得)がより高い安定性と意味的一貫性を達成することが明らかになりました。
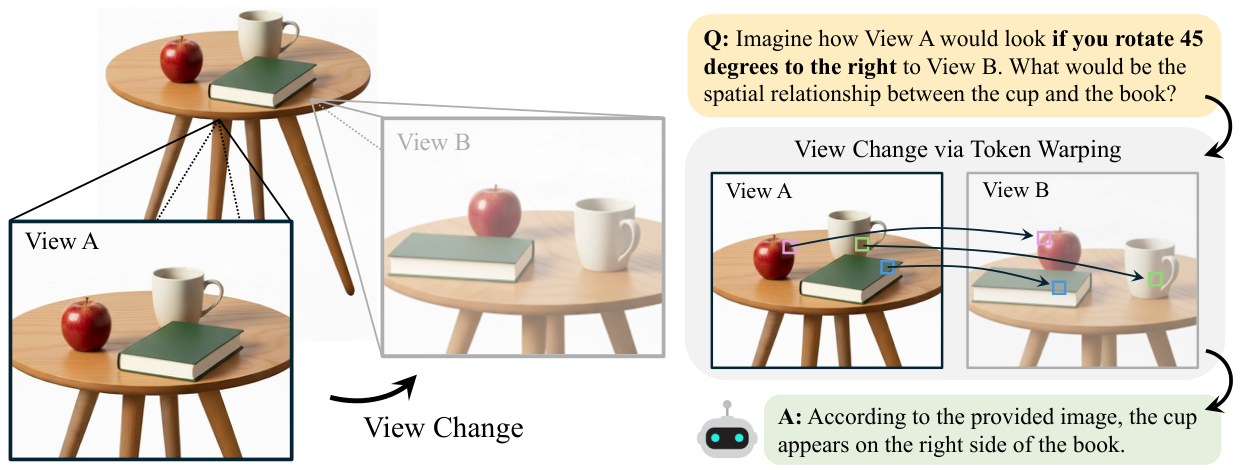
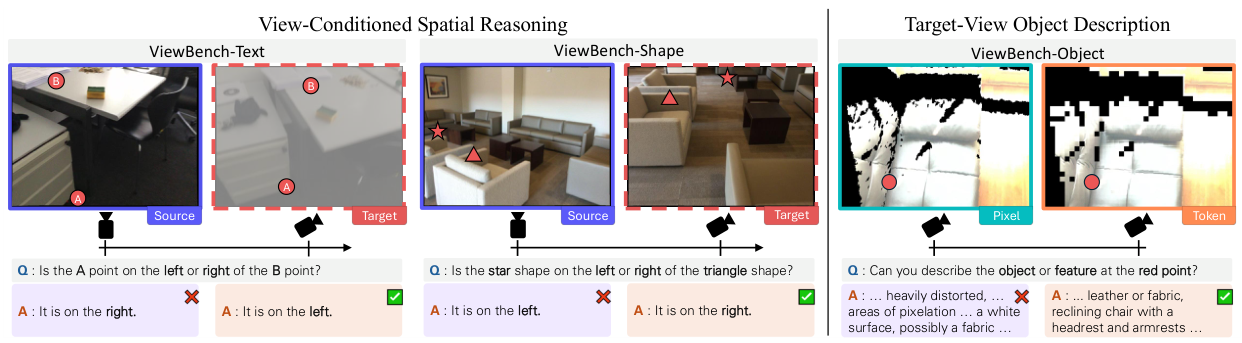
5°〜35°の回転範囲にわたるMLLM視点推論を評価する3つのサブタスク(空間推論、形状推論、物体記述)を持つ新しいベンチマーク。
ピクセルではなくトークンをワーピングすることで、マルチモーダル大規模言語モデル(MLLM)が近傍の視点からシーンがどのように見えるかを理解できるようになるのでしょうか?MLLMは視覚推論において優れたパフォーマンスを発揮しますが、ピクセル単位のワーピングはわずかな深度誤差に非常に敏感で、幾何学的な歪みをもたらすため、視点変化に対して脆弱です。人間の視点変換の基礎として部位レベルの構造的表現を仮定する心像理論に基づき、ViTベースのMLLMにおける画像トークンが視点変化の効果的な基盤として機能するかを検討します。前向きワーピングと後ろ向きワーピングを比較した結果、ターゲットビューに密なグリッドを定義し、各グリッドポイントに対応するソースビュートークンを取得する後ろ向きトークンワーピングが、より高い安定性を達成し、視点シフト下での意味的一貫性をより良く保つことがわかりました。提案するViewBenchベンチマークでの実験により、トークンレベルのワーピングがMLLMを近傍視点から確実に推論できるようにすることが実証され、ピクセル単位のワーピングアプローチ、空間的にファインチューンされたMLLM、生成的ワーピング手法を含むすべてのベースラインを一貫して上回りました。
画像からの空間推論の核心は、シーンの3次元構造を理解することです。深度推定はほぼ完璧な精度を達成していますが、予測された深度をMLLMに組み込んでも、真の3D理解は得られません。異なる視点から同じシーンを説明するような単純なタスクでさえ、明示的な3D教師あり学習でファインチューンされたMLLMはほとんど改善を示しません。3D認識特徴を組み込んだモデルにも同様の限界があり、依然として視点変換についての推論に苦労しています。
Shepard、Minsky、Pylyshyn、Hintonに至る心像の古典的研究は、心像が部位レベルで定義された構造的記述に依存していることを提唱しています。この観点から、Transformerアーキテクチャが使用する画像トークンは、機械が知覚できる部位レベルの表現を表しています。したがって、心像の概念をオブジェクトレベルの抽象化ではなく、これらの知覚的な原子単位に拡張することは自然なことです。
ViTベースのMLLMにおける画像トークンは視点変化の効果的な基盤として機能します。トークンに適用された変換は視点シフト下で一貫した内部表現を生成し、空間推論を改善します。また、トークンレベルの変換は、ピクセルレベルのワーピングを壊滅的に劣化させる幾何学的ノイズに対してロバストです。
パッチ摂動実験でこれを検証します。パッチを取得する際の位置オフセットを徐々に増加させると、MLLMは摂動されたトークンに対して驚くほど安定したままであることが示される一方、ピクセルレベルの摂動は深刻な精度低下を引き起こします。これは、不完全な深度マップを使用して異なる視点からトークンを構築する際に導入される幾何学的ノイズが、MLLMの視覚的理解を著しく損なわないという強力なエビデンスを提供します。
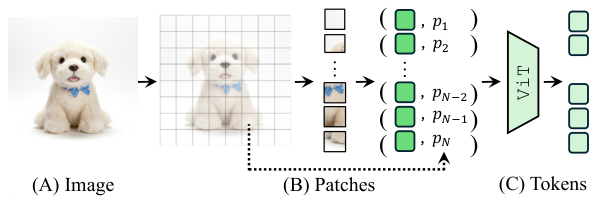
深度推定とカメラ姿勢を使用して、MLLMの視点条件付き画像トークンを構築するトレーニング不要なアプローチ。
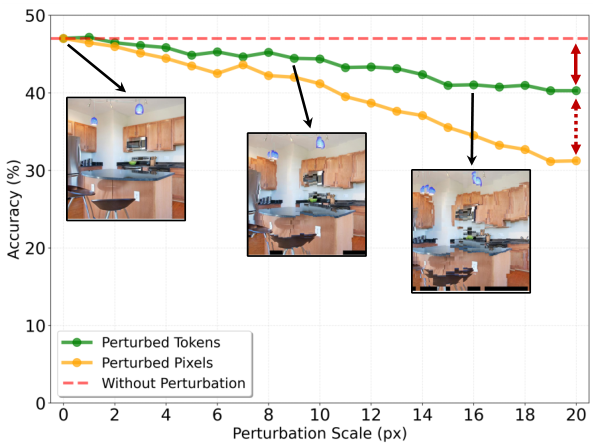
パッチを取得する際の位置オフセットを0から20pxまで段階的に増加させることでMLLMのロバスト性をテストしました。パッチサイズに近い摂動でさえ、摂動されたトークンではMLLMはわずかな精度低下しか示しませんでした。一方、同じスケールのピクセルレベルの摂動は深刻な劣化を引き起こしました。これは、不完全な深度推定によって導入される幾何学的ノイズがトークンレベルの視覚的理解を著しく損なわないことを確認します。
ソース画像にオフザシェルフの単眼深度推定器を適用します。得られた深度マップは、ターゲットカメラ姿勢とともに、トークンワーピングの3D幾何学を定義します。
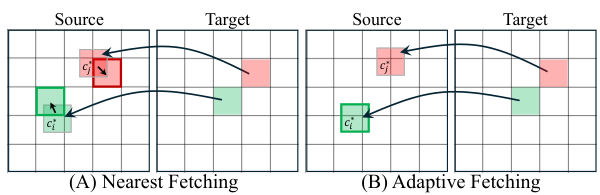
ターゲットビューに密なグリッドを定義します。各ターゲットグリッドポイントについて、深度マップを使用して3Dに投影し、ターゲットカメラフレームに変換し、対応するソースビューパッチ(最近傍または適応的取得)を取得します。
ワープされたトークンシーケンス(ターゲット視点からシーンを表す)を視点条件付き質問とともにMLLMに供給します。ファインチューニングは不要で、ViTベースのMLLMはそのまま動作します。
MLLMが近傍視点からシーンを推論する能力を評価するために特別に設計されたベンチマーク、ViewBenchを紹介します。3つの補完的なサブタスクと3つの回転範囲(5°〜15°、15°〜25°、25°〜35°)をカバーしています。
視点条件付き空間推論:ターゲット視点からの物体の空間的関係についての二値左右質問。MLLMが空間推論を回転した視点に正しく向けることができるかをテストします。
ターゲットビューからの形状識別:モデルは回転した視点から見た物体の正しい形状を識別する必要があり、幾何学的視点理解をテストします。
ターゲットビュー物体記述:ターゲット視点から物体がどのように見えるかのオープンエンド記述。実際のターゲットビューの外観に一致する記述を報酬として、LLMジャッジによって-10から+10の類似度スケールで評価されます。
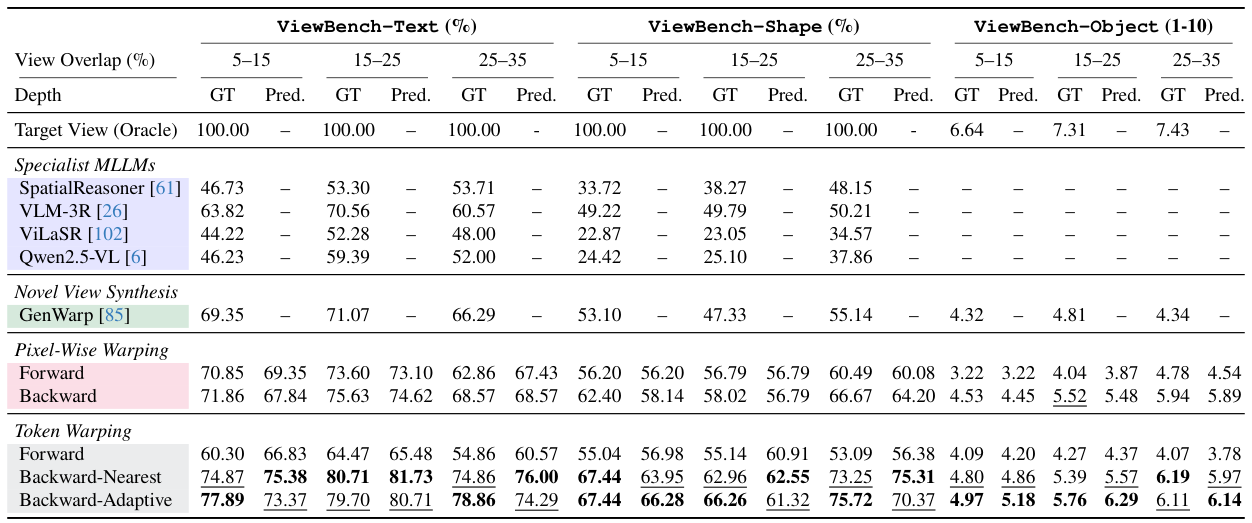
トークンワーピング(後ろ向き-適応的)は、すべての3つのViewBenchサブタスクとすべての回転範囲(5°〜35°)にわたってすべてのベースラインを一貫して上回ります。トレーニングなしで、ピクセル単位のワーピング、空間的にファインチューンされたMLLM、新規ビュー合成、生成的ワーピング手法を超えます。


本論文では、MLLMにおける視点条件付き視覚推論を可能にするトレーニング不要なアプローチとして、トークンワーピングを紹介します。主要な発見は以下の通りです:
トークンレベルの心像 — ピクセル操作や明示的な3D再構築ではなく — は、マルチモーダルAIシステムにおけるロバストな空間推論への有望で実践的な道です。
@article{lee2026tokenwarping,
title={Token Warping Helps MLLMs Look from Nearby Viewpoints},
author={Lee, Phillip Y. and Park, Chanho and Park, Mingue
and Yoo, Seungwoo and Koo, Juil and Sung, Minhyuk},
journal={arXiv preprint arXiv:2604.02870},
year={2026}
}