1. はじめに
マルチモーダル大規模言語モデルは、受動的な観察者から能動的な調査者へと急速に進化している。静的なスナップショットから回答するのではなく、現代のシステムはインタラクションによって問題を解決するようになっている。すなわち、画像を操作して細粒度の証拠を浮かび上がらせ、視覚的に存在しない事実を検証するために外部リソースを参照する。この変化はマルチモーダルエージェント能力を体現しており、2つのコア次元に分解できる。(1)Visual Expansion:入力を能動的に変換・分析(例:クロッピング、回転、拡張)して潜在的な手がかりを発見することでモデルが画像を使って思考できるようにする;(2)Knowledge Expansion:オープンエンドのウェブ検索を通じてパラメトリックメモリを超え、実世界の事実を検証して曖昧さを解消できるようにする。
Visual ExpansionとKnowledge Expansionとは何か?
探偵に例えてみよう:Visual Expansionとは画像に虫眼鏡をあてること(クロップ、ズーム、回転、OCR)で隠れた証拠を浮かび上がらせることを意味する。Knowledge Expansionとは図書館(ウェブ検索)に行って画像に存在しない事実を検証することを意味する。Agentic-MMEはAIが両方をどれだけ組み合わせられるかを測定する — 実世界の複雑なタスクは順次ではなく、両方を同時に要求するからだ。
このアクティブなパラダイムは複雑な実世界の問題解決を約束するものの、マルチモーダルエージェント能力の現在の評価は断片的で不十分なままである。既存のベンチマークのほとんどはツール使用の特定の側面を捉えているが、3つの重要な次元で失敗している — 真のマルチモーダルエージェントベンチマークはこれら3つすべてに同時に対処しなければならない。
既存ベンチマークの3つの重大な欠陥
- 柔軟性のないツール統合:現在の評価では、ビジュアルツールの使用とオープンウェブ検索を切り離し、独立したモジュールとして扱っている。エージェントが任意のビジュアルツールと検索ツールを流動的に選択・切り替えられる統一フレームワークが存在しない。
- 未開拓の相乗効果:Visual ExpansionとKnowledge Expansionの相互作用はほとんど未検証である。真のマルチモーダルエージェントは、単純なVisual Expansionや単独のKnowledge Expansionだけでは解決できない「絡み合った」タスクに優れなければならない。
- プロセス検証の欠如:既存の評価は最終回答の正解に焦点を当てており、ツールが呼び出されたか、正しく適用されたか、効率的に使用されたかについて何の洞察も提供しない。不忠実なツール実行は見えないままである。
Agentic-MMEはこれら3つのギャップすべてに対処する。418件の実世界タスク、Code(Gen)とAtomic(Atm)の両ツールインターフェースをサポートする統一実行ハーネス、そして細粒度のプロセスレベル検証を可能にする2,000以上の人間によるアノテーション付きステップごとのチェックポイントを備えた、慎重に設計されたベンチマークがその答えだ。
プロセス検証が重要な理由
作業をせずに試験の正解を推測した学生は、最終回答採点では正しく推論した学生と区別がつかない。AIシステムの実際の運用(医用画像解析、法的分析)では、この違いが重要だ。Agentic-MMEのプロセス検証は、各中間状態を監査することでこれを捉える:正しい領域がクロップされたか?検索は関連する結果を返したか?計算は忠実だったか?これはパイロットのフライトログをテストするのと、着陸だけを確認するのとの違いだ。

2. Agentic-MMEベンチマーク
2.1 概要
Agentic-MMEは、エージェントがビジュアルツールを能動的に活用して画像コンテンツを変換・知覚し、タスク要件に応じてオープンウェブ検索と連携して必要な外部知識を取得するリアルなシナリオでマルチモーダルエージェント能力を評価するよう設計されている。ビジュアル操作やウェブ検索を単独でテストするベンチマークとは異なり、Agentic-MMEはこれら2つの能力の深い相乗効果を対象とする。ベンチマーク比較(表1)は、Agentic-MMEが異種ツールインターフェースのサポート、ツール相乗効果のテスト、プロセス検証の実現、効率測定、難易度レベルの定義をすべて同時に満たす唯一のベンチマークであることを示している。
表1:既存のマルチモーダルエージェントベンチマークとの比較
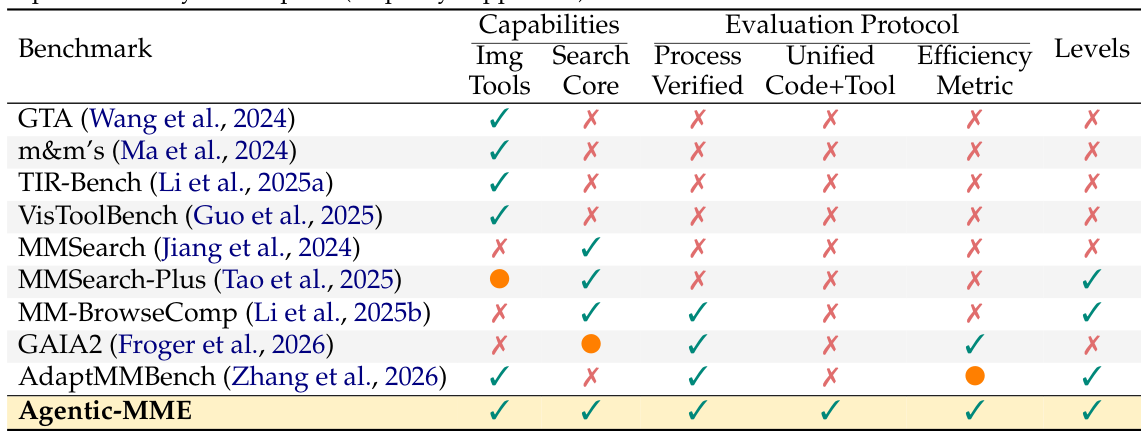
主要な能力と評価プロトコルの次元における比較。Agentic-MME(最下行)は、画像ツール、検索コア、プロセス検証、統合コード+ツールインターフェース、効率メトリクス、難易度レベルのすべての次元をカバーする唯一のベンチマークである。
2.2 タスク設定、難易度、メトリクス
各インスタンスは1枚以上の画像と質問を提供する。エージェントは、Visual Expansionのための13種類のビジュアル操作とKnowledge Expansionのための4つのオープンウェブ検索ツールを備えた統一ツール拡張インターフェース内で画像を能動的に操作することでタスクを解決する。タスクは、合理的な解答経路に沿ったインタラクションの複雑さに基づいて3つの難易度レベルに体系的に層別化されている。
易しい — 単一操作
単一のビジュアル操作(例:1回のクロップまたは回転)を要求する。平均チェックポイント数2.89、タスクあたりツール数1.21。
中程度 — マルチステップワークフロー
画像操作とオプションのウェブ検索を組み合わせたマルチステップワークフローを要求する。平均チェックポイント数4.64、タスクあたりツール数2.42。
難しい — 高度な相乗効果
ビジュアル操作とウェブ検索の絡み合った複数ラウンドのインタラクションを要求する。単純な順次ツールチェーンでは解決できない。平均チェックポイント数6.67、タスクあたりツール数4.07。

表2:タスク難易度の分布。Level 3タスクはベンチマークの19.4%を占め、平均4.07のツールと6.67のチェックポイントを必要とする — Level 1より大幅に複雑である。
評価メトリクス
S軸とV軸とは何か?
最終回答のみを確認するベンチマークとは異なり、Agentic-MMEは2つの評価軸を使用する。S軸(戦略とツール実行):各中間ツール呼び出しを採点する — モデルは適切なツールを選択し、正しく適用し、有用な証拠を抽出したか?V軸(視覚的証拠の検証):モデルが発見したと主張する視覚的成果物が実際に画像に存在することを確認する — 偶然に正しい回答に到達する捏造された推論チェーンを防ぐ。
2.3 データ収集とアノテーション
データ収集パイプラインはバックワードドラフティングアプローチを採用する。質問を先に書くのではなく、アノテーターはビジュアルツールで知覚する必要がある高解像度の視覚的に複雑な画像から始め、各ステップをツールアクションと視覚的グラウンドトゥルースに基づいたマルチステップの軌跡を構築する。これにより、ツールの呼び出しが省略可能ではなく必須であることが保証される。パイプラインは4つのステージを経る:画像収集、バックワードドラフティング、粒度の細かいアノテーション、品質保証。
なぜBackward Draftingを使うのか?
ほとんどのデータセットは質問から始めて画像を探す — 誤ってツール使用を省略可能にしてしまう。Backward Draftingはこれを逆転させる:アノテーターは視覚的に複雑な画像から始め、内部に埋もれた証拠を特定し、それを抽出するツール軌跡を構築し、その後質問を書く。これにより、すべてのタスクが本当にツール使用を必要とすることが保証される。脱出ゲームの設計方法と似ている:まずパズルを構築し、次に説明書を書く。

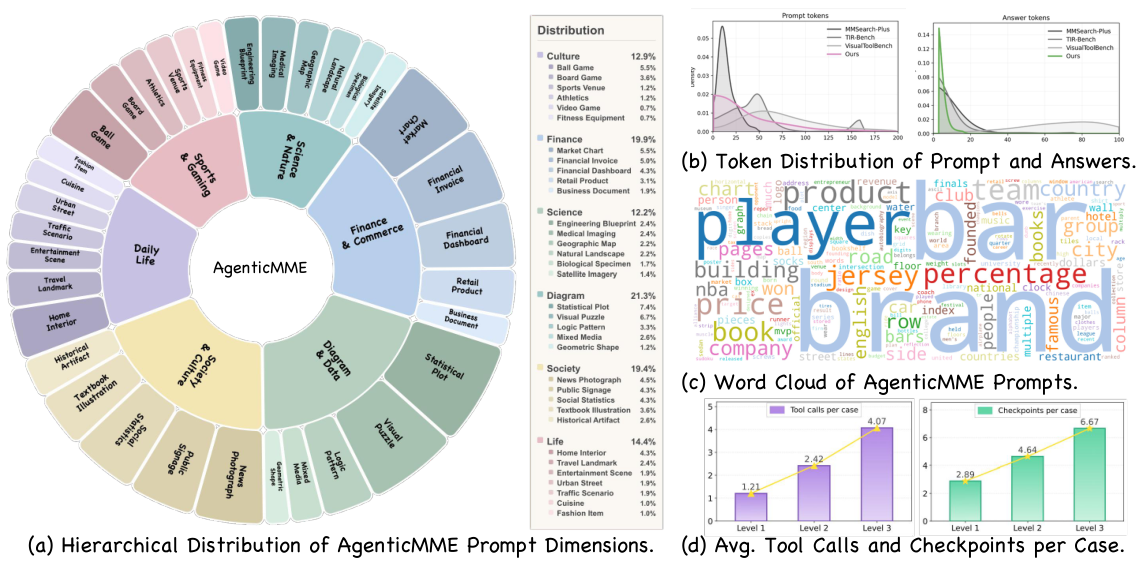
表3:データセットの主要特性

430枚の画像、899ツール、6ドメイン / 35サブドメイン。平均画像解像度:1952×1747 px。43.1%のタスクに小さな視覚的手がかりがある(画像領域の10%未満)。29.4%のタスクが外部ウェブ検索を必要とする。
2.4 品質管理と保証
アノテーションされた各タスクは複数ラウンドの独立した検証を経る。品質管理には、エッジケースと失敗モードを体系的に調査するステップごとのオラクルテスト、そして複数の専門家がグラウンドトゥルース軌跡に合意しなければならないコンセンサス監査が含まれる。一貫性の閾値を満たさないタスクは修正または廃棄される。この厳格なプロセスにより、2,000以上のステップごとのチェックポイントが根拠に基づき、再現可能で、人間レベルの推論軌跡を忠実に表現することが保証される。
各タスクは平均10人時以上の手動アノテーションを要する — これは忠実なステップごとの推論軌跡を捉えるために必要なプロセスレベル検証の深さを反映している。
2.5 統一ツールインターフェースと実行ハーネス
Agentic-MMEの中心的な設計目標は、異種ツール実装にわたってエージェント能力をベンチマークすることである。統一実行ハーネスは2つのインターフェースをサポートする:Codeモード(Gen)(モデルがサンドボックス化されたPythonを書いてビジュアル変換を実行する)とAtomicモード(Atm)(モデルがOpenAI互換のJSONスキーマに従った構造化された関数呼び出しを通じてインタラクションする)。この管理された比較により、ツール能力が1つのトレーニング形式に縛られるのではなく、インターフェースを超えて汎化するかどうかをテストする。
Visual Expansion(13ツール)
隠れた証拠を浮かび上がらせ、細粒度の詳細を抽出し、または空間変換を適用するために画像を変換する能動的な画像操作ツール。
Knowledge Expansion(4ツール)
パラメトリックメモリを超えて実世界の事実を検証し、外部検索を通じて曖昧さを解消するオープンウェブ検索ツール。
3. 実験
3.1 実験設定
Agentic-MMEで多様なモデルセットを評価する。オープンソースモデル(Thyme-rl、DeepeEyes-V2、Qwen3-VL-235B、Qwen3-VL-8B-thinking、Qwen3-VL-32B-thinking)とクローズドソースモデル(Gemini 3ファミリー、Kimi-k2.5、GPT-5.2、Qwen3.5-plus)を含む。人間のリファレンスベースラインは、検索エンジンと知覚ツールの使用を許可された3名の独立した人間の解答者の平均値から得る。
各モデルは両方のツールインターフェースで評価される:サンドボックス化されたPython実行のためのCodeモード(Gen)と構造化された関数呼び出しのためのAtomicモード(Atm)。この管理された比較により、ツール能力がインターフェースを超えて汎化するかどうかを直接テストする。すべての評価は完全にログ記録された再現可能なトレースで実行され、GPT-5-miniが主要な判定者として使用される — 人間の専門家による検証では、判定者の選択を超えて一貫した結果が示されている(表8)。
3.2 Agentic-MMEの主要結果
すべてのモデルが人間のパフォーマンスを大幅に下回り、Level-3では精度が急落する。人間の解答者は総合93.8%に達し、最難関の分割でも高い精度を維持する(L3: 82.3%)。最高モデルのGemini 3 Pro(Atm)は総合56.3%を達成するが、Level-3ではわずか33.3%にとどまる。ツールなしではGemini 3 ProのL3スコアは7.5%まで低下し、ツールへのアクセスで33.3%へと4.4倍の改善をもたらすが、人間(82.3%)とのギャップは依然として大きい。
オープンソースモデルはクローズドソースに遅れを取っており、主に検索と計画立案の面で差がある。そのギャップはLevel-3で最も顕著だ:Qwen3 VL-235Bは10.1%に低下し、Thyme-rlは2.5%まで崩壊する。S軸がそのメカニズムを明らかにしている — 現在のオープンソースモデルはツールを呼び出せるが、マルチステップワークフローを確実にチェーンするために必要な検索と計画立案の洗練さをまだ習得していない。
Atomic(Atm)モードはモデル全体でCode(Gen)モードよりも精度を向上させることが多い。これは、構造化された関数呼び出しインターフェースが実装エラーを減らし、ツール使用の境界をより明確にすることで、より信頼性の高いステップごとの実行を可能にすることを示唆している。
表4:Agentic-MMEの主要結果
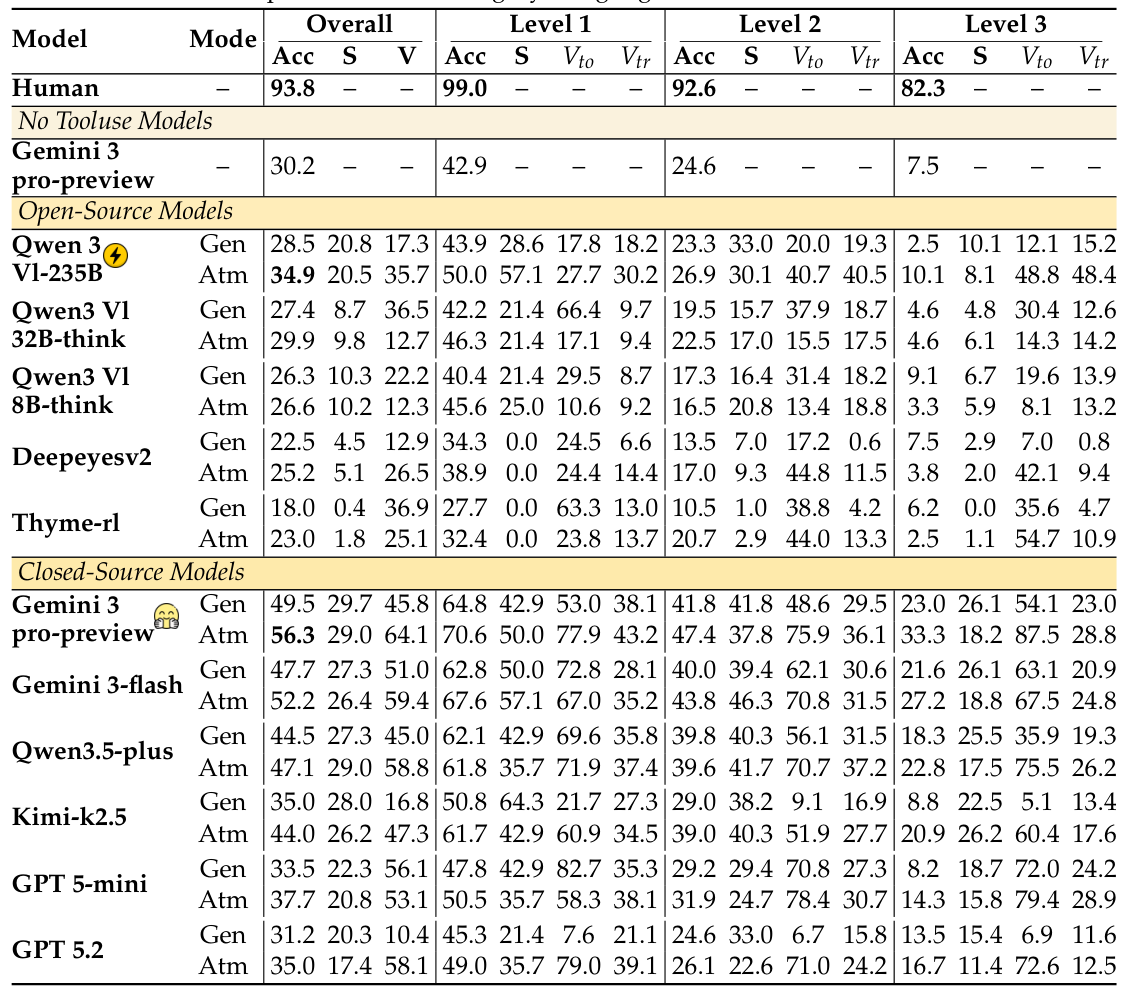
Gen・Atmモードにおける全評価モデルの総合・Level 1(L1)・Level 2(L2)・Level 3(L3)にわたる結果。メトリクス:Acc = 精度、S = S軸スコア、V = V軸有効性、VIT/VFT = 意図/忠実度トラッキング。人間の総合精度93.8%に対し、最高モデルは56.3%。
3.3 詳細分析
パフォーマンスギャップの原因を理解するために2つの分析を行う:(1)各ツールカテゴリの貢献を分離するアブレーション研究、および(2)より良いツール実行によって達成可能な潜在的な改善を定量化するために視覚的手がかりとステップごとのガイダンスを提供する上限分析。
表5:ツールアブレーション研究
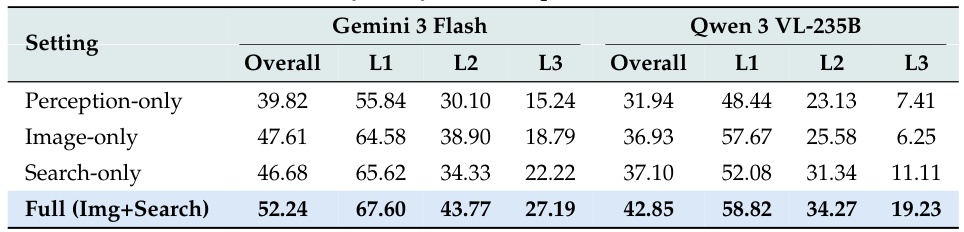
Gemini 3 FlashとQwen3 VL-235Bのアブレーション結果。設定:知覚のみ(ツールなし)、画像のみ(ビジュアルツールのみ)、検索のみ(ウェブ検索のみ)、フル(両方)。フル統合が最高パフォーマンスを達成 — ビジュアルツールと検索ツールは補完的であり、冗長ではない。
表6:上限分析
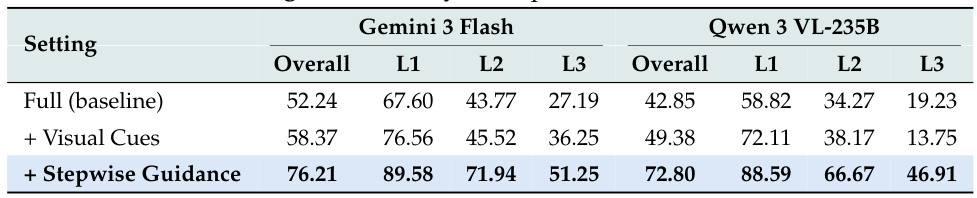
視覚的手がかり(+Visual Cues)とステップごとのガイダンス(+Stepwise Guidance)を提供したときのパフォーマンス。ステップごとのガイダンスによりGemini 3 Flashは52.24%から76.21%に向上 — より良い計画立案で上限が達成可能であることを示している。現在の自律的パフォーマンスとガイド付きパフォーマンスのギャップは、エージェント推論の改善のフロンティアを表す。
ステップごとのガイダンスを追加することでパフォーマンスが52.24%から76.21%に向上 — 24ポイントの上昇は、現在のモデルが根本的な知覚能力ではなく、主に計画立案と実行の信頼性で失敗していることを示している。
3.4 細粒度エラー分析
モデルがどのように失敗するかを理解するために、3つの難易度レベル全体にわたって細粒度のエラー分析を行う。ヒートマップ(図4)はL1、L2、L3、および総合のエラーカテゴリ分布を示し、エラーパターンが難易度とともに大幅に変化することを明らかにしている。L3タスクでは、マルチホップ推論の失敗、検索統合エラー、視覚的曖昧さの管理ミスの割合が大幅に高く — これらは高度な相乗的ワークフローに固有のコアな課題である。
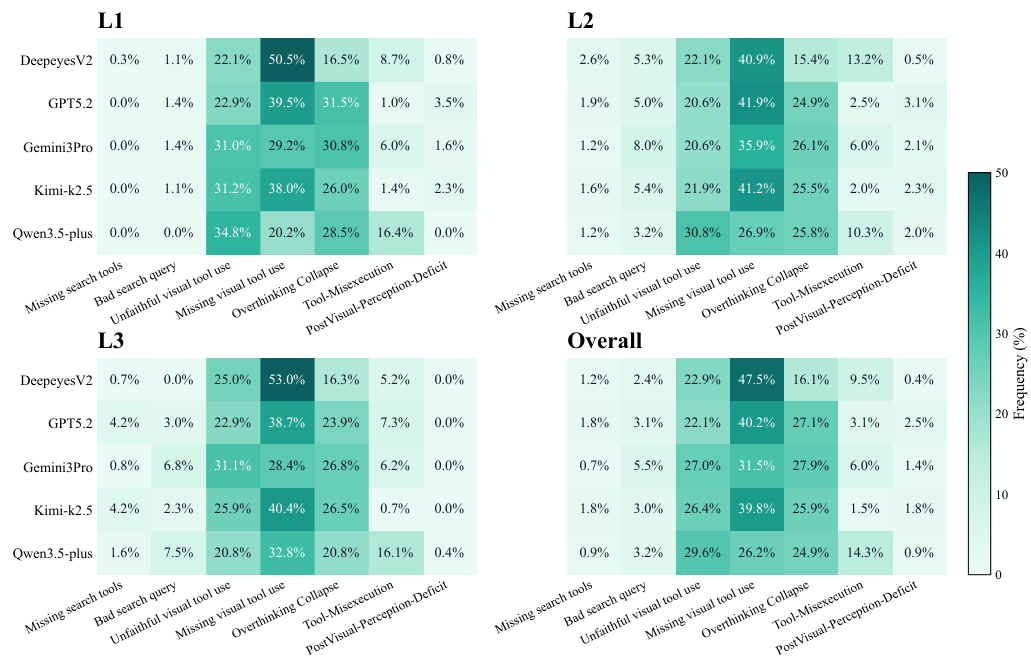
表7:ツール呼び出し効率(呼び出し回数とOverthinking)
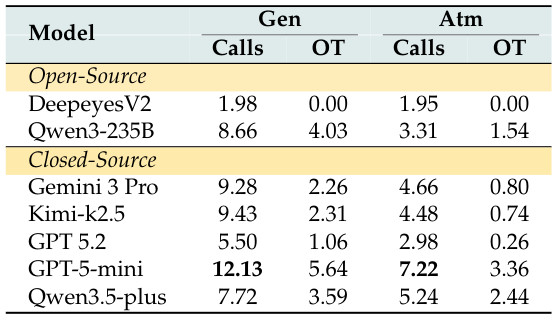
GenおよびAtmモードにおけるモデルごとの平均ツール呼び出し回数とOverthinking(OT)スコア。GPT-5-miniが最も多くのツール呼び出しを行う(Gen: 12.13、Atm: 7.22)。高いOTは人間の参照軌跡に対して冗長なツール使用を示す。
Overthinking(OT)メトリクスとは何か?
人間が3つのツールで足りる場面でAIが12のツールを呼び出すのは非効率であり、本番環境ではコストがかかる。OTメトリクスは人間の参照軌跡に対する過剰なツール呼び出しを測定する。低OT = 効率的で集中したツール使用。高OT = モデルが「スピン」している — 収束しないまま繰り返しクエリを実行する。GPT-5-miniが最も高いOTを示し(Gen: 12.13回の呼び出し)、十分な証拠が集まったときに判断することが困難であることを示唆している。
表8:判定者一貫性の検証
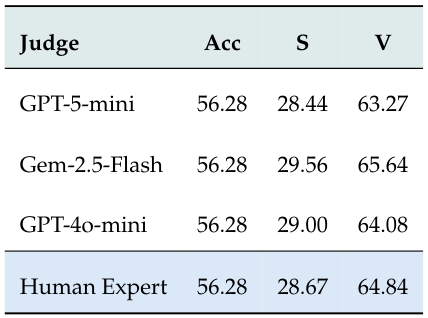
異なる判定者(GPT-5-mini、Gemini-2.5-Flash、GPT-4o-mini、人間の専門家)を使用した評価結果。すべての判定者が同一のAcc(56.28)を示し、判定者の選択に関わらず評価の安定性が確認された。
5. 結論
我々はAgentic-MMEを提案する。これは、マルチモーダルエージェントにおける能動的なビジュアル操作(Visual Expansion)とオープンウェブ検索(Knowledge Expansion)の深い相乗効果を体系的に評価するために設計されたプロセス検証済みベンチマークである。不透明な最終回答採点を超え、2,000以上の人間によるアノテーション付きステップごとのチェックポイントに基づいた異種ツールインターフェースをサポートする統一実行ハーネスを貢献する。この二軸フレームワークにより、中間ツールの意図、視覚的成果物の忠実度、および実行効率の細粒度な監査が可能になる。
我々の評価は、特に複雑なワークフローにおけるフロンティアモデルと人間のパフォーマンスとの重大なギャップを明らかにする。現在のモデルは単純な順次ツールチェーンを実行できるが、高度な相乗的タスク — ファジー検索による視覚的曖昧さの解消、モダリティをまたいだ反復的な仮説検証 — には深刻な困難を抱えている。不忠実なツール実行と冗長な「overthinking」ループというボトルネックを特定することで、Agentic-MMEは堅牢で長期的なマルチモーダルエージェントを開発するための厳格な診断ロードマップを提供する。
実践者のための主要な示唆
マルチモーダルAIシステムを構築している場合、Agentic-MMEはボトルネックが知覚ではなく、曖昧さの下での計画立案と忠実なマルチツールオーケストレーションであることを明らかにする。静的なベンチマークで高スコアを獲得するモデルも、反復的なビジュアル検索とクロスモーダル検証を必要とするLevel-3タスクで崩壊する可能性がある。Agentic-MMEはこれらのギャップを特定して修正するための診断ツールである。
参考文献(39件)
- Bai, J., et al. (2025). Qwen3-VL Technical Report.
- Chen, J., et al. (2025). Knowledge Expansion in Multimodal Agents.
- Deng, G., et al. (2023). Mind2Web: Towards a Generalist Agent for the Web. NeurIPS.
- Froger, A., et al. (2026). Process-Verified Evaluation for Agentic AI. ICLR.
- Fu, C., et al. (2023). MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models.
- Guo, T., et al. (2025). VisualBench: Systematic Evaluation of Visual Tool Use. CVPR.
- Hong, M., et al. (2025). DeepeEyes: Deep Visual Reasoning in MLLMs. ICLR.
- Hou, X., et al. (2025). CodeV: Process-Level Evaluation of Code-Augmented Visual Agents. ICML.
- Huang, T., et al. (2026a). Deep Research with Multimodal Agents. NAACL.
- Huang, T., et al. (2026b). Vision-in-the-Loop Web Research. ACL.
- Jiang, Z., et al. (2024). Open-World Information Seeking with Multimodal Agents.
- Kimi Team. (2026). Kimi-k2.5: Frontier Multimodal Reasoning. Technical Report.
- Lai, S., et al. (2025). Active Visual Manipulation for MLLMs. CVPR.
- Li, J., et al. (2023). BLIP-2: Bootstrapping Language-Image Pre-training. ICML.
- Li, P., et al. (2025a). GTA: Tool-Augmented Multimodal Benchmark. NeurIPS.
- Li, W., et al. (2025b). MM-BrowseComp: Browser-based Multimodal Completion. ACL.
- Ma, Y., et al. (2024). VisualAgent: Multi-tool Visual Reasoning. ECCV.
- Narayan, A., et al. (2025). Fact Verification via Multimodal Search. SIGIR.
- OpenAI. (2025). GPT-5.2 Technical Report.
- Shen, Y., et al. (2023). HuggingGPT: Solving AI Tasks with ChatGPT and its Friends.
- Shi, K., et al. (2025a). Vision-Language Agents for Scientific Discovery. Nature MI.
- Shi, K., et al. (2025b). MMSPHy-Plus: Physical Scene Understanding Benchmark. CVPR.
- Shi, K., et al. (2025c). Visual Tool Selection and Execution. ICLR.
- Su, D., et al. (2025). Image Transformation for Evidence Extraction.
- Tao, R., et al. (2025). MMSearch: Multimodal Web Search Evaluation. ACL.
- Team, G., et al. (2023). Gemini: A Family of Highly Capable Multimodal Models.
- Team, G., et al. (2026). Gemini 3: Frontier Multimodal Model. Technical Report.
- Team, Q. (2026). Qwen3.5-plus Technical Report.
- Wang, J., et al. (2024). ToolBench: Benchmarking Tool Use in Language Models. NeurIPS.
- Wang, L., et al. (2025). Agentic Visual Perception Systems. CVPR.
- Wei, Q., et al. (2026). Visual Expansion for Multimodal Agents.
- Yu, W., et al. (2023). MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities.
- Yue, X., et al. (2024). MMMU: A Massive Multi-discipline Multimodal Understanding. CVPR.
- Zeng, Z., et al. (2026). Knowledge Retrieval in Multimodal Settings. ACL.
- Zhang, M., et al. (2025a). Multimodal Scientific Agents. Science AI.
- Zhang, Q., et al. (2025b). Thyme-rl: Temporal Reasoning with Visual Tools. NeurIPS.
- Zhang, T., et al. (2026). AgentMME: Process-Verified Multimodal Benchmark.
- Zheng, H., et al. (2025). Fine-grained Visual Manipulation. ECCV.
- Tao, R., et al. (2025). TIR-Bench: Tool-Interactive Reasoning Benchmark.