背景と、OSPDの問題点について.
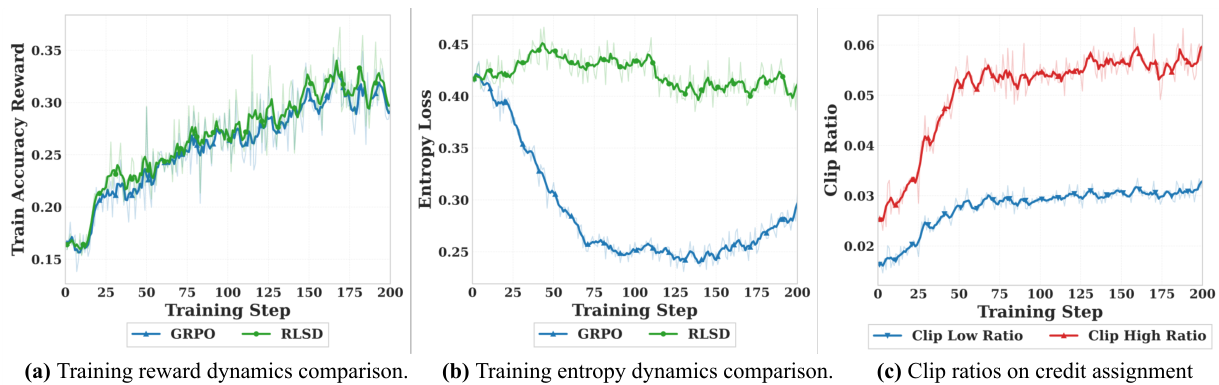
検証可能な報酬を用いた強化学習 (RLVR) 手法、例えば GRPO は、大規模な推論モデルの学習において中心的な役割を果たすようになりました。各軌道は、検証者から単一のスカラー報酬のみを受け取り—これは スパースな信号 です—そして、応答内のすべてのトークンは同じアドバンテージ推定値を使用するため、トークンレベルでの区別がありません。
LLMにおける強化学習における「スパース報酬」とは?
LLM(大規模言語モデル)のための強化学習において、「スパース報酬」とは、モデルが応答全体に対して1つのフィードバック信号しか受け取らないことを意味します。具体的には、正解であれば✓、不正解であれば✗という、単一の評価です。応答に含まれるすべてのトークン(潜在的に数百個)が同じアドバンテージスコアを共有するため、モデルはどの特定のトークンが正解または不正解の原因となったのかを特定できません。これは、エッセイを最終的なスコアだけで評価し、文単位でのフィードバックを与えないのと似ています。
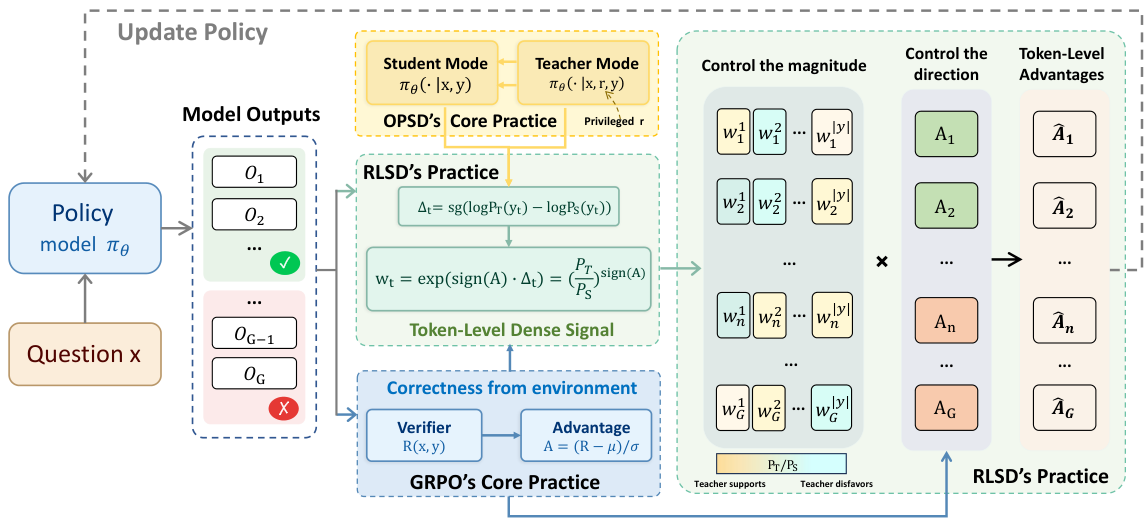
On-Policy Self-Distillation (OPSD)は、この問題を解決しようとする手法であり、教師(参照解答を受け取る)と生徒(独立して解答を生成する)の両方に同じモデルを使用します。しかし、これにより、根本的な非対称性が生じます。教師は生徒が推論時にアクセスできない、特権的な情報を持っているからです。
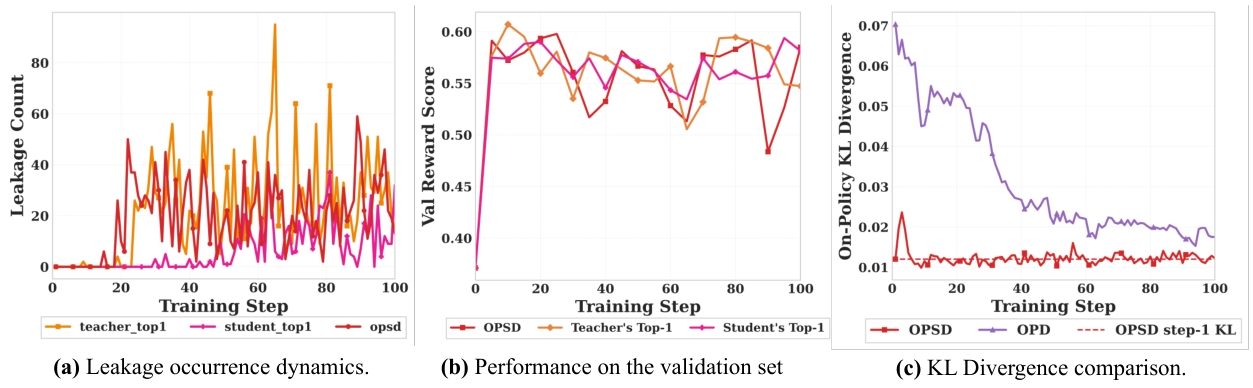
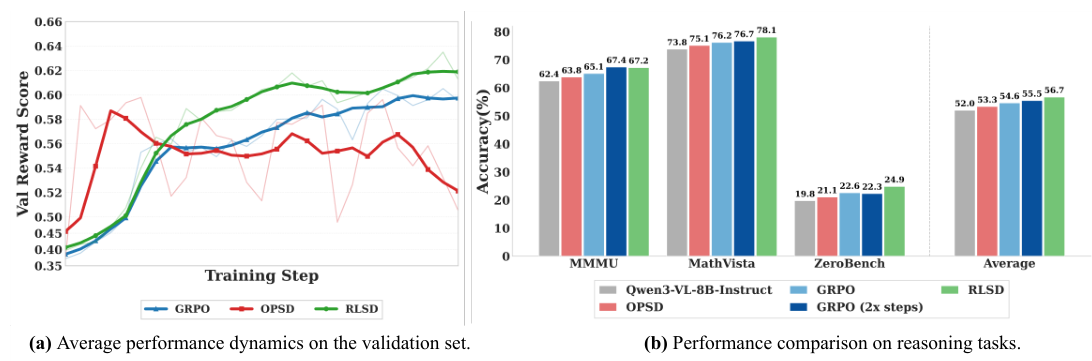
OPSDでトレーニングされたモデルは、推論時に利用できない特権情報に体系的に参照することがあります。 例えば、OPSDでトレーニングされたモデルは、次のような出力を生成する可能性があります: "標本平均が母集団平均から$1以内にあるかどうかを判断する必要があります...参照ソリューションが9つの値を使用しているという情報が与えられている..." — これは、モデルが知るべきではない参照解答を明示的に使用しています。 この情報漏洩は、トレーニング中に単調に増加し、その結果、パフォーマンスは10〜20ステップでピークに達し、その後低下します。
自己蒸留における「情報の非対称性」とは?
OPSDでは、同じモデルが同時に2つの役割を果たします。
- 教師モード: 質問と、参照解答rを同時に受け取ります。これは、教科書を参照できる試験のようなものです。
- 生徒モード: 質問のみを受け取ります。これは、教科書を参照できない試験のようなものです。
これが「情報の非対称性」です。教師と生徒が異なる情報を持っています。問題点は、学習の目的が、生徒が教師のトークンごとの確率分布と一致するようにすることであることです。しかし、教師の分布には解答が含まれています。生徒が解答パターンを密かに暗記せずに、この一致を達成することはできません。これが「漏洩」を引き起こします。
トレーニングパラダイムの比較
| Method | Trajectory | Efficiency | Leakage Risk | Signal | Direction Anchoring |
|---|---|---|---|---|---|
| SFT | Off-policy | High | N/A | Rich | Teacher |
| RLVR (GRPO) | On-policy | High | N/A | Weak | Environment |
| OPD | On-policy | Low | N/A | Rich | Teacher |
| OPSD | On-policy | High | Severe | Rich | Teacher |
| RLSD (Ours) | On-policy | High | N/A | Rich | Environment |