1. 導入
産業コードの格差.
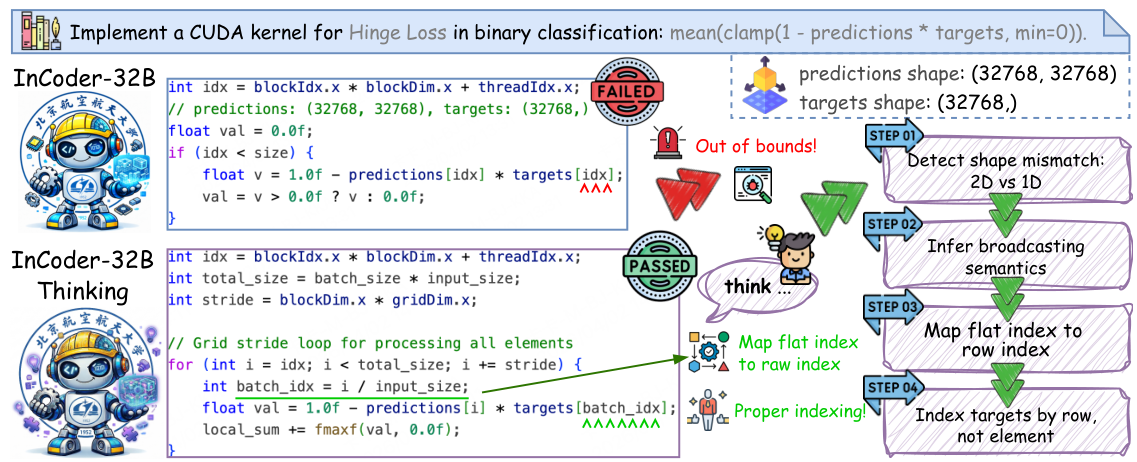
大規模言語モデルは、ソフトウェア工学の分野において目覚ましい進歩を遂げており、関数作成、スクリプトのデバッグ、および競争プログラミングのベンチマークのクリアなど、様々なタスクをこなせるようになりました。しかし、実際の産業界で使用されるコードの領域においては、状況は大きく異なります。最先端のモデルであっても、Tritonカーネルの生成やVerilogの等価性チェックといったタスクにおいては、その汎用的な性能とは裏腹に、限定的な成果しか得られていません。
根本原因は、データ不足です。産業分野には、エンジニアがハードウェアの制約、タイミングの意味、および分野固有の実行フィードバックについてどのように考え、判断しているかを示す、専門的な推論の記録が不足しています。Verilogの修正は、単に構文の問題ではなく、RTLがゲートレベルのロジックとタイミングパスにどのように対応するかを理解する必要があります。Tritonカーネルの開発には、GPUのメモリ階層、warpスケジューリング、および数値精度について考慮する必要があります。
私たちの取り組み
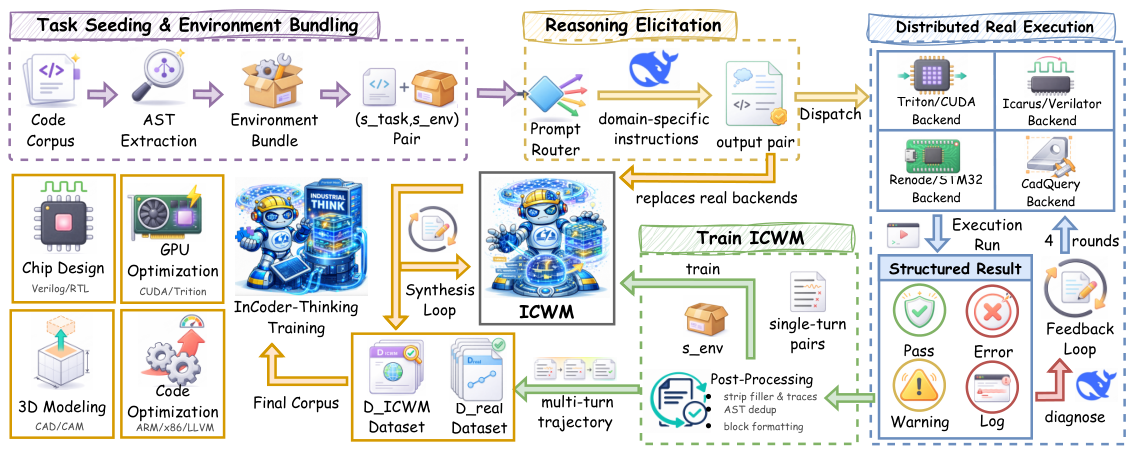
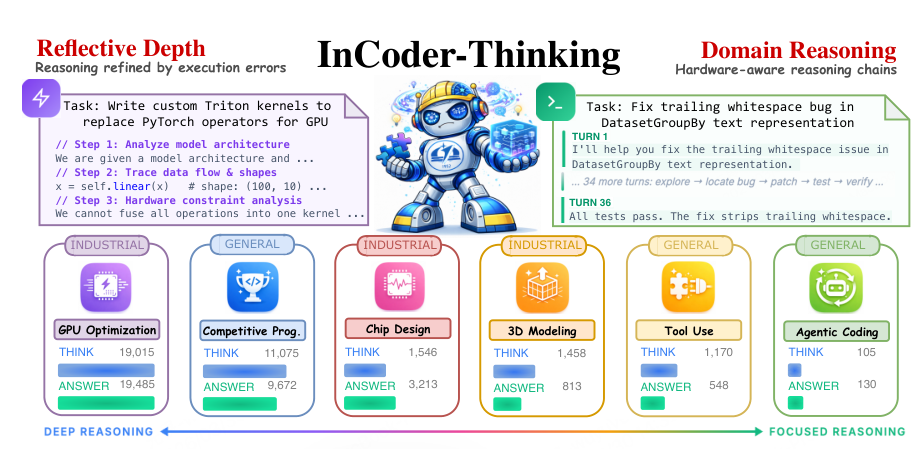
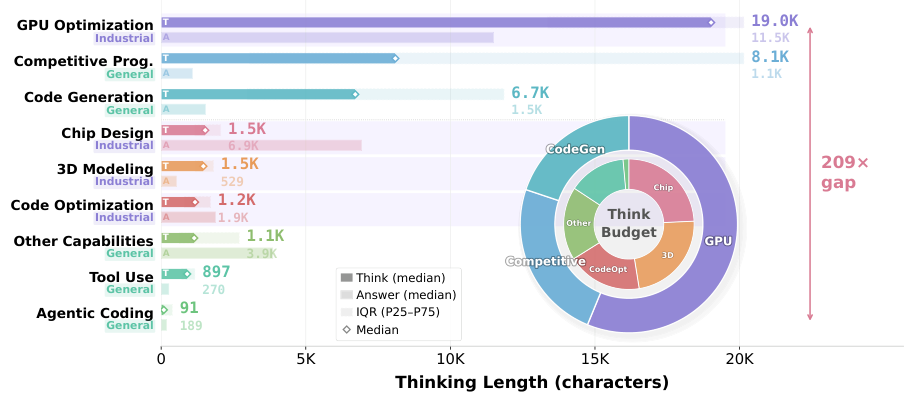
InCoder-32B-Thinkingは、思考モデルの機能(慎重で、エラーを修正する、複数回の推論)と、産業用コードの世界モデルの知識(コードがハードウェアの動作に与える因果関係)を組み合わせたものです。このモデルは、ECoT合成フレームワークによって生成されたデータで学習され、ICWMによって検証されており、実行に基づいた推論の好循環を生み出しています。
主要な貢献
ECoT 合成
Error-driven Chain-of-Thoughtは、実際の実行環境との複数回の対話を通じて、推論の過程を生成します。GPUコンパイラの誤り、RTLシミュレータ、およびCADエンジンのエラーが、学習信号となります。
産業コード世界モデル
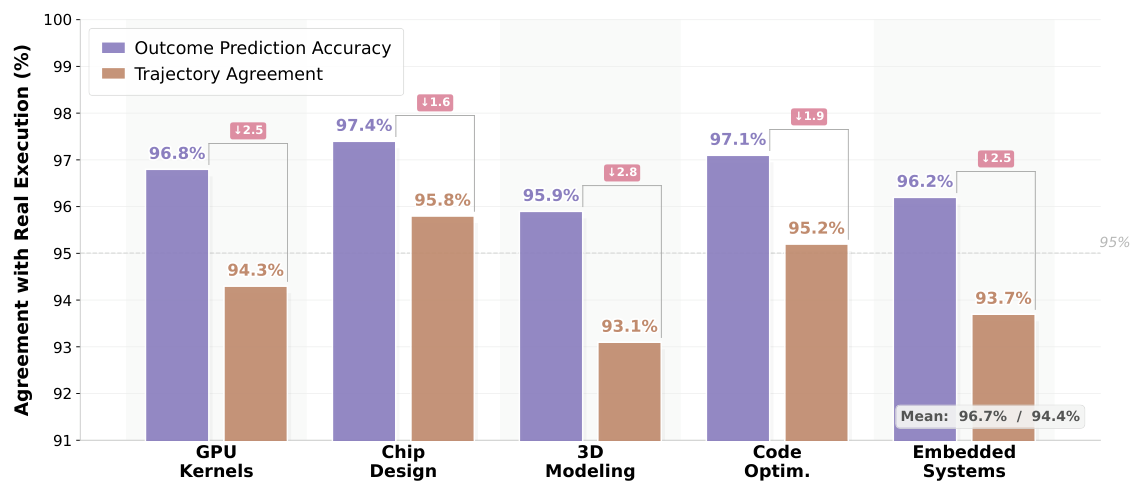
ICWMは、コードからハードウェアへの動作に関する因果関係を、実行トレースから学習します。大規模なデータ生成時に、高価な実環境のバックエンドを置き換えることで、96.7%の予測精度を達成します。
最高レベルのパフォーマンス.
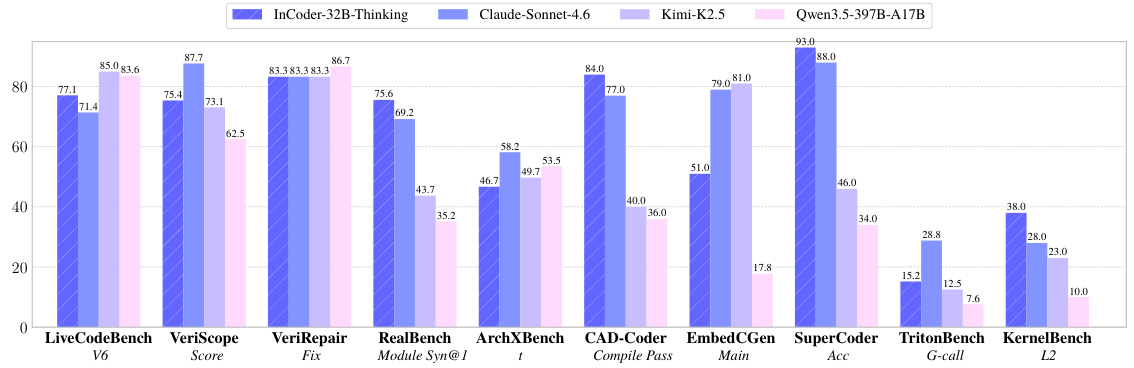
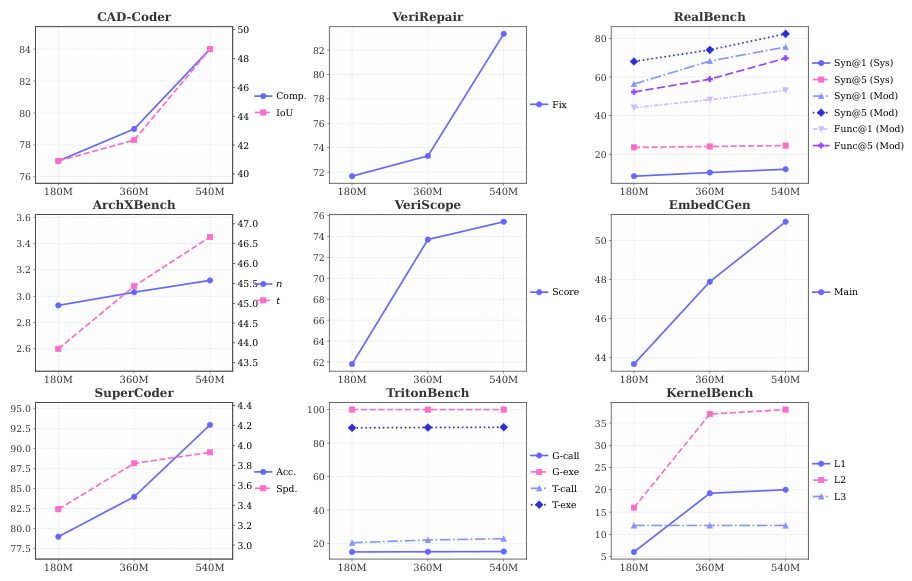
14種類の一般的なベンチマーク(81.3% LiveCodeBench V5)および9種類の産業用ベンチマーク(84.0% CAD-Coder, 38.0% KernelBench L2)において、最高レベルのオープンソースの結果を達成し、産業用タスクにおいてClaude-Sonnet-4.6およびKimi-K2.5を上回る性能を発揮。